https://ratsgo.github.io/speechbook/docs/decoding/viterbi
Evaluation
음성 인식 모델이 디코딩한 결과를 평가
Word Error Rate(WER)
WER은 모델 예측 결과와 정답 사이의 단어 수준 편집거리(edit distance)를 수치화.
예측과 정답이 같을 수록 그 값이 작아지고, 값이 작은 모델이 좋은 모델
WER 계산 예시
- Insertion(단어를 삽입해야 정답과 일치) : 1건(PHONE)
- Substitution(단어를 대체해야 정답과 일치) : 6건(TO>UM, FULLEST>IS, LOVE>LEFT, TO>THE, OF>PHONE, STORES>UPSTAIRS)
- Deletion(단어를 삭제해야 정답과 일치) : 3건(GOT, IT, FORM)
-> WER = 100×(1+6+3)/13=76.9

Sentence Error Rate(SER)
SER은 전체 문장 갯수 가운데 ‘단어 하나라도 틀린 문장 갯수’의 비율을 나타내는 지표

Matched-Pair Sentence Segment Word Error(MAPSSWE) test
두 개의 음성인식 시스템의 성능 차이를 통계적으로 유의한 차이가 있는지 검정
MAPSSWE 계산 예시
1. 모델 예측 결과 세그먼트(segment)로 나누기 (보통 음성인식 시스템 trigram 언어모델 사용, 정답 맞춘 phrase 앞뒤로 세그먼트)
2. 틀린거 계산
모델 I 영역 II 영역 III 영역 A모델 2(Substitution 1건, Insertion 1건) 0 1(Substitution) B모델 0 1(Insertion) 2(Substitution)
- 틀린거 평균 통계적 검정 (귀무가설 설정 0.05~~)

Viterbi Algorithm
방법
-
현재 상태로 전이할 확률이 가장 큰 직전 스테이트를 모든 시점, 모든 상태에 대해 구함 (중간에 사라지는 애들은 연결이 중간에 끊킨 건 볼필요 없다! 싶어서 없애는 것 같음)

-
backtrace 방식으로 최적 상태열 구함
- 예시: 만약 최대 확률을 내는 k+2 번째 시점의 상태가 θ0 라면, 최적 상태열은 == [θ0,θ2,θ2,θ1,θ0,θ1]

수식
1. Forward Computation/ 비터비 확률(Viterbi Probability) 구하기
-
t번째 시점에 j번째 상태인 비터비 확률 vt(j)는 전체 n개 직전 상태 각각에 해당하는 전방 확률들의 최댓값!

-
방출확률 B P(ot|qj)=bj(ot)

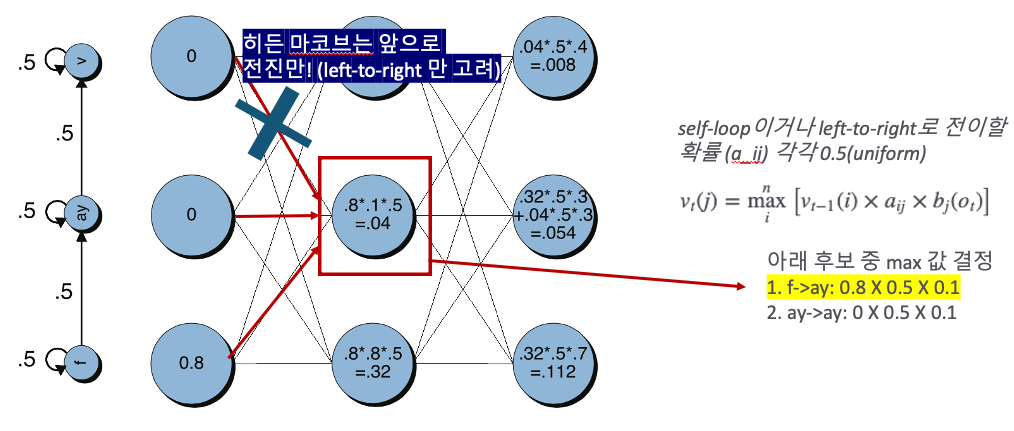
2. Viterbi Search
Forward Computation으로부터 베스트 경로 하나만 남겨서 비터비 경로(Viterbi Trellis) 탐색하는 과정

역추적을 하는 이유는 매순간 최선의 선택이 전체 최적을 보장하지 못할 수도 있기 때문. (???)
[chatgpt] 계산 효율성: 전체 계산 과정을 한 번에 앞으로 추적하려면 가능한 모든 상태 조합을 추적하고 저장해야 합니다. 이는 매우 비효율적이고 계산량이 많아질 수 있습니다. 반면, backtrace는 최종 시점에서 가장 가능성 높은 상태만을 선택하고, 이미 계산된 최적의 경로를 거슬러 올라가면서 필요한 정보만을 사용하여 효율적으로 최적의 시퀀스를 결정
단점
- 시퀀스 탐색 범위가 너무 넓음. 입력 음성 피처로 탐색 대상 음소 시퀀스 범위를 좁히더라도, 경우의 수 음소 수와 시퀀스 길이에 비례해 폭증
- 매 시간(time), 상태(state)에 대해 베스트 경로 하나만을 탐색해서 최적 시퀀스 도출 장담할 수 없음.
