[NLP] Story Generation - Genre-Controllable Story Generation via Supervised Contrastive Learning (WWW, 2022)
NLP
0. Summary
-
Challenge
: Pretraine language model 등의 발전으로 controllable text genration이 각광받고 있다. 하지만 story-specific controllability에 대한 연구는 아직 부족하다. -
Approach
: 특정 장르에 특화된 story를 generation할 수 있는 Story Control via Supervised Contrastive Learning model (SCSC) 제안- 서로 다른 장르 간에 intrinsic 차이를 캡쳐하기 위해 supervised contrastive objective + log-likelihood objective 사용
-
Results & Findings
: automated evaluation과 user study에서 genre-controlled story generation을 하는데 효과적인 것을 입증함.
Paper: Genre-Controllable Story Generation via Supervised Contrastive Learning
github : https://github.com/jucho2725/WWW2022_StoryControl
1. Introduction
1-1. Challenge
- 기존 language 모델들은 story generation 일관성 떨어짐.
- pre-trained neural models
- log-likelihood 사용해서 이전 문맥을 기반으로 다음에 어떤 token이 올 지 prediction할 때 사용
- (장점 1) one direction으로 쓰여진 컨텐츠를 생성할 때 잘 맞음.
- (장점 2) fine-tuned된 모델 사용하면 natural한 장점.
- (단점 1) 다은 think: 훈련이 필요
- language models
- 주어진 시퀀스를 가지고 probability distribution으로 text 생성
- (장점 1) 다은 think: general, finetuning 없어도 됌
- (단점 1) randomness로 인해 스타일이나 주제들의 일관성이 떨어짐.
- pre-trained neural models
** log-likelihood Vs. probability distribution ?
- probability (확률) : 확률분포가 고정되어 있을 때, 관측값이 분포 안에서 얼마의 확률로 존재할지?
- likeihood (가능도) : 관측값이 고정되어 있을 때, 이 값이 어느 분포에서 왔는지? 실재를 바탕으로 충분한 시행을 바탕으로 축적된 데이터를 가지고 앞으로 일어날 가능성을 추론(inference)
- reference: https://swjman.tistory.com/104
- 기존 연구들 한계
- consistent & coherent를 위해 "control code" 사용했지만 genre를 사용한 적 없음.
Control code
: 사전에 토픽이나 스타일 감정들을 control code로 정의하여, 그에 맞게 generation시 condition 지정. - log-likelihood objective만 사용하여 controllable text generation model 학습
- consistent & coherent를 위해 "control code" 사용했지만 genre를 사용한 적 없음.
1-2. Approach
- "Control code"
- 본 논문에서는 genre를 control code로 지정!
Genre (장르)
- 장르는 스토리생성에서 control factor임.
- 장르는 forms, styles, subject matters 등을 아우름.
- 본 논문에서는 genre를 control code로 지정!
- Story Control via Supervised Contrastive Learning model (SCSC)
- supervised contrastive objective 사용
- 장르간의 차이 modeling
- story generation process controlling
supervised contrastive objective
- 다른 장르의 스토리와 비교해서 같은 장르에 있는 비슷한 스토리를 capture할 수 있음.
- supervised contrastive objective 사용
- Automatic & human evaluation
1-3. Contribution
- genre를 스토리 생성 conditioned (control code)로 둔 건 첫 연구.
- SCSC 모델 제안 - supervised contrastive objective 사용
- genre-controlled story generation evaluation용 dataset 구축
- user study & emprirical analysis 통해서 SCSC가 효과적으로 controllable story generation하는 것 입증
2. Related Work
2-1. Controllability in Story Generation
- 기존 automatic story generation에서는 controllability를 얻기 위해서 스토리 구조나 attribute (topic, sentiment)등을 조건화하였음.
- Panning problem
- [44] : goal에 맞게 스토리 생성하는 강화학습 방법 제시.
- [10] : action plan, entities 고려해서 스토리 구조 생성
- Topic
- [37] : 결말의 감정가 (valence)를 control factor로 둬서 스토리라인은 같고 결말만 다르게.
- [9] : overall topic을 control factor로 둠. hierarchical framework를 제안해서 첫번째 스토리 생성 후 그 다음 스토리 생성할 수 있게 함.
- Panning problem
- 본 논문에서는 Genre를 control factor로 둠.
- 장르 자체는 스토리 구조나, 토픽 등을 어우르고 있어서 control factor로 더 적합.
2-2. Controllabel text Generation
- Fine-tuning
- [23] : transformer + control code
- [4] : transformer + interleave content-conditioner (CoCon) layer (raw text를 받아서 합친다)
- [7, 25, 32] : discriminator 추가
- controllable text generation에 맞는 objective function 사용한 연구 없음. 우리는 supervised contrastive objective 사용할 것임.
2-3. Contrastive Learning
refernece: https://daebaq27.tistory.com/97
- in CV
- 활용: img classification
- 장점: robustness, lower sensitivity
- in NLP
- 활용 : word representation, sentence representation, language modeling
- text generation에서 최근 contrastive objective 사용하고 있고, supervised 환경에서 쓰인 경우 한 번 있음 ([17]).
- controllable story generation을 위해서 supervised contrastive learning 쓰는 것은 이 논문이 최초.
3. Method
3-1. Conditional Language Models
-
기존 language model 수식
-
각 토큰 x_t가 vocab에 포함될 때, languge model은 text sequence에 대해서 확률분포를 구함. 이를 바탕으로, {x_1 ... x_t-1} text prompt가 주어졌을 때, 다음에 올 {x_t ... x_n}을 decode함.
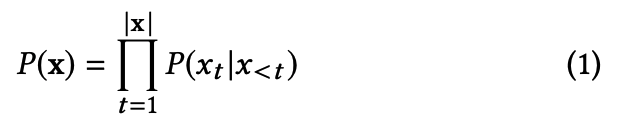
-
Loss : Dataset D에 대해 L_nll을 minimize하는 parameter를 찾도록 훈련
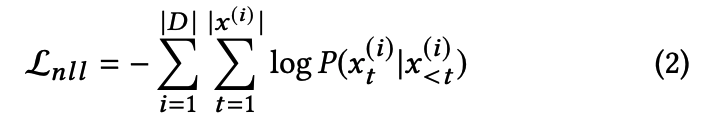
-
-
+ Control code "Genre"
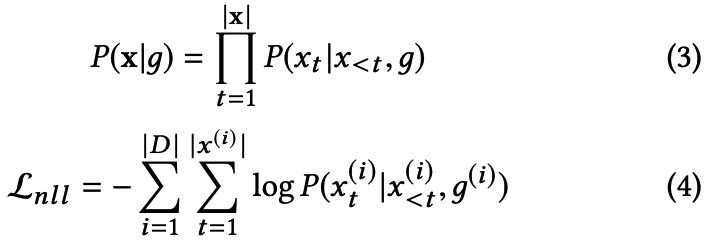
3-2. Model Architecture
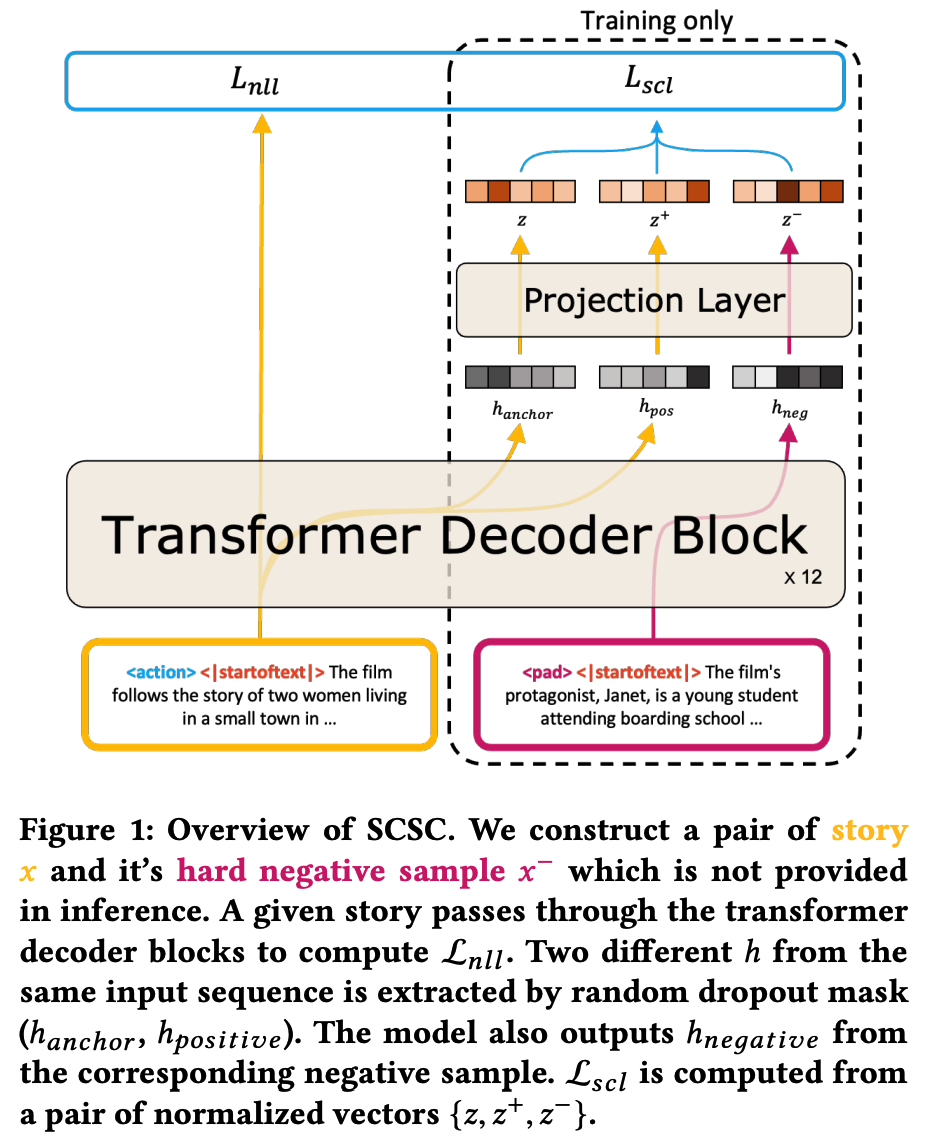
-
뼈대
- transformer, gpt2 117m, multiple transformer-decoder blocks with masked multi-head self-attention, layer normalization, positionwise feed forward.
-
next token의 conditional 확률분포 (노란색 네모)
- input : text prompt x_<t, genre code g
- output: o_t를 softmax 취해서 conditional probability distribution 구하기.
- o_t : LM의 last layer에 linear layer 적용해서 나온 the logit of the next token
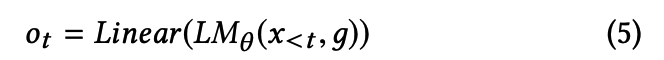
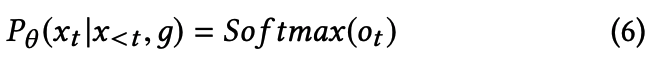
-
input sequence의 representation
- input: text prompt x_<t, genre code g
- output: h- LM의 last layer에 pooling한 값
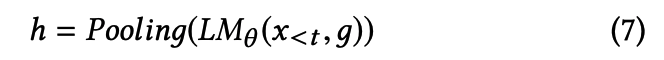
-
projection layer
- input: 2번에서 구한 h
- output: z
- 구조
- two linear layers with tanh non-linear activation func.
- z를 normalize해서 inner product가 가능하게 함으로써 projection space상에서 distance 구할 수 있도록 함.
3-3. Contrastive Learning
3.3.1 Loss function
- Contrastive learning 목적 : 비슷한 건 가깝게, 다른 건 멀리
-
사용된 loss func
- Cross entropy loss (제일 good)
- triplet loss
- contrastive loss
-
수식
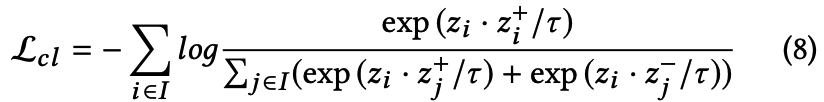
- {x, x+, x-}은 하나의 batch로 pair를 이룸. => normalize한 것이 {z, z+, z-}
- j는 어디서 나온 거지...?
-
3.3.2 Positive Sample Augmentation
- 기존의 delete, replacing 등의 방법으로 postive sample을 만들기엔 language data가 discrete함
- [15]의 방법을 착안하여, text input을 transformer layer에 넣은 후 random dropout mask를 적용해 forward pass를 두번 시행한다. (???) 그럼 2개의 서로 다른 output을 만들어 낸다.
- 여기서 나온 output을 postivie pair로 : (x, x+)
3.3.3 Negative Sample Mining
- 1) A라는 데이터셋이 story x, genre label y를 가지고 있다고 했을 때, y라벨이 아닌 데이터셋을 negative sample 후보로 뽑음.
- 2) 후보들을 SentenceTransformer package, "all-mpnet-base-v2"를 사용해서 representation을 뽑은 후 기준이 되는 스토리 x와 가장 유사한 top-k (여기선 1) 데이터를 뽑아서 hard negative sample로 지정.
3.3.4 In-batch Supervision
몰라....
-
In self-supervised learning, single batch 안에서 pos sample은 x+가 유일하다.
-
그러나, supervised contrastive learning에서, batch안에서 똑같은 라벨을 가지고 있는 다른 sample들도 positive로 취급된다.
-
따라서 sample pair를 {x, x+, x-}에서 {x, x+, x-, y(genre)}로 확장한다.
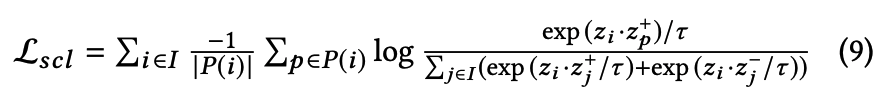
-
8번 수식이랑 비교해보면 앞에 P(i)가 생긴 것을 알 수 있음.
- P(i)는 index i에 상응하는 모든 postitive set
-
기존 문제점
- dropout augmentation을 사용했기 때문에 (z,z_p)는 easy positive pairs가 된다. (cosine sim of z,z_p = 1). (이게 왜 문제인지부터 모르겠음.)
- 이 문제를 supervised contrastive loss가 완화시켜줄 수 있다.
-
해결책
- x의 라벨은 알고 있기 때문에, label information은 batch안의 pos,neg sample을 구분해낼 수 있다. 따라서 우리는 batch안에 hard positive pairs (cosine sim of z,z_p = 0)가 하나 이상 있단 것을 예상할 수 있다.
- 그래서 eq 9는 같은 라벨을 가지고 있는 sample들 끼리 더 단단한 clustering을 만들 수 있게 해준다.
3-4. Proposed Training Objective
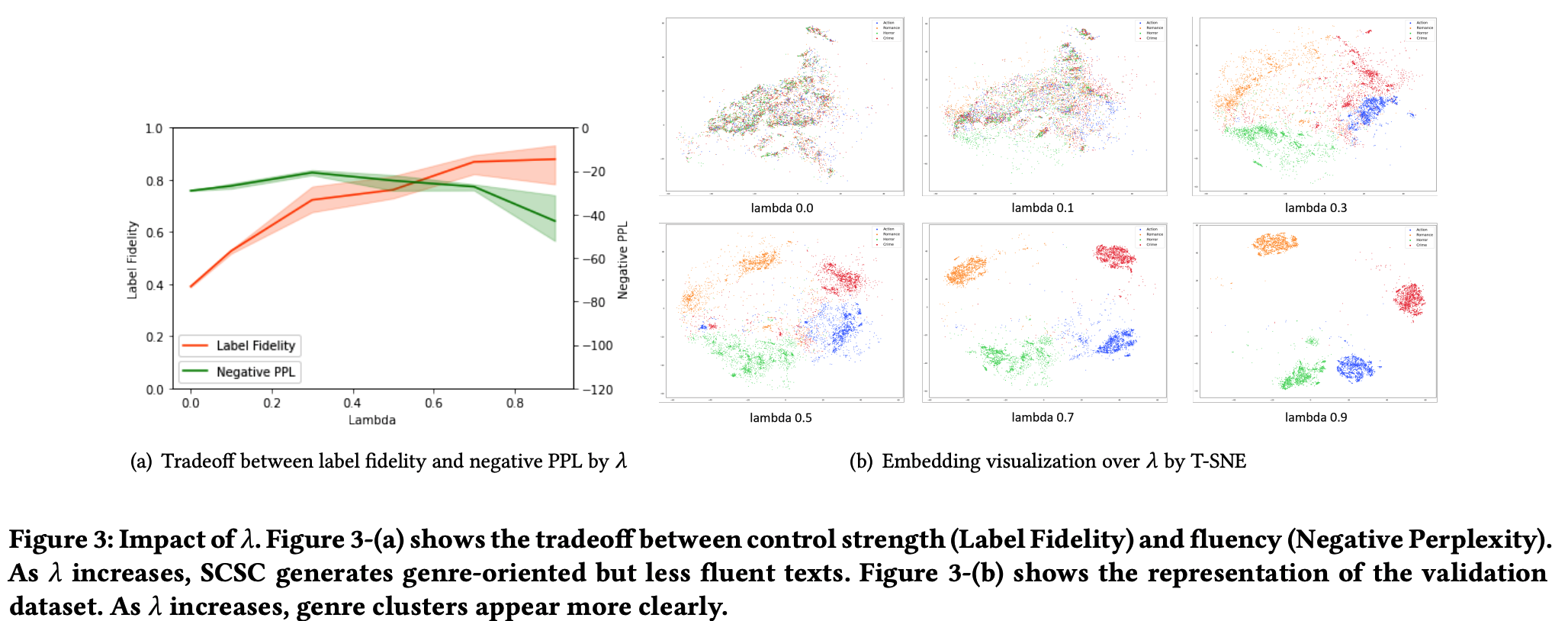
- genre controllability 는 향상시키는데 집중해서, text's fluency는 떨어질 수 있음.
- 그래서 두개 사이의 최적의 trade-off 찾는 것이 관건.
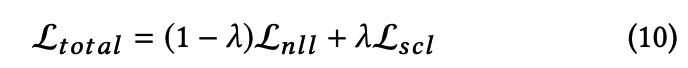
4. Evaluation
- 목표 : 우리가 생성한 스토리가 타겟 장르에 잘 속하도록 만들어졌는가?
4-1. Datasets
4.1.1 Data collection
- Combine 2 dataset
- WikiPlots
- CMU movie summary corpus
4.1.2 Genre Selection
- 데이터셋에 1191개의 장르태그가 있었는데, 효과적인 학습을 위해 재정비함
- 최종적으로 총 4개의 장르 선택
- Action, Romance, Horror, Crime
4.1.3 Data Split
- 훈련용 : 평가용 = 3:1
- generator : text 만들기
- classifier : genre 맞추기
4-2. Evaluation Methods
4.2.1 Baselines (자세한 설명 생략..)
- fine-tuned pretrained gpt-2, genre condition X
- Controlled generation language models
- CTRL, PPLM, CoCon
4.2.2 Automatic Evaluation Metrics
- label fidelity: genre label classifier가 예측한 값과 비교했을 때 얼마나 잘 맞췄는지.
- perplexity: fluency of the text - gpt2
- Dist-1,2,3 : diversity of the text - # of unique n-grams
4.2.3 Human Evaluation
-
평가항목
- fidelity: A와 B중 어느게 더 target genre와 맞나?
- readability: 어느 게 더 문법적으로 맞나?
- coherence: 어떤 게 더 coherent 한가?
- interestingness: movie plot으로서 어느 스토리가 더 흥미로운가?
-
평가방법
- 100개 random text prompts를 가지고 4개 모델 (SCSC, 3baselines)이 만든 story generation 결과물 비교.
- 58명 in AMT
5. Results & Analysis
5-1. Results
5.1.1 Automatic Evaluation Results
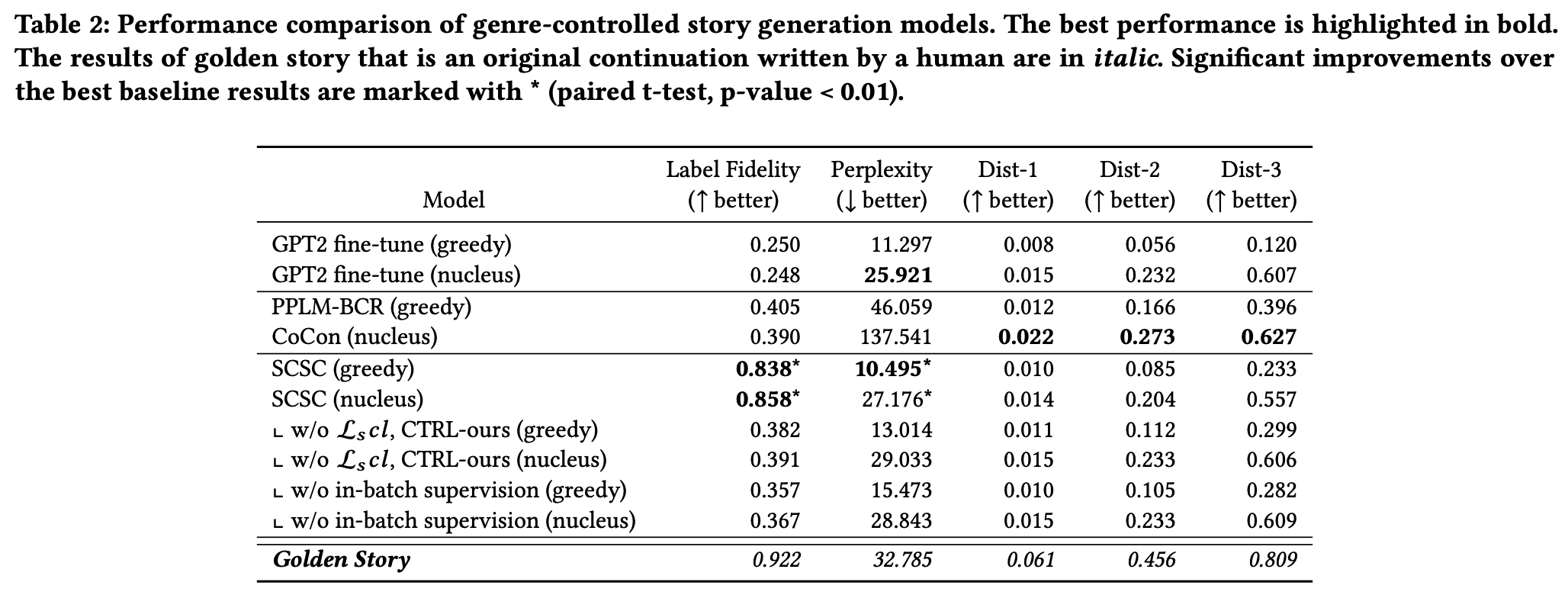
- Performance 비교
- gpt-2의 label fidelity가 가장 낮음
- 왜냐하면, 훈련시 gpt-2는 장르 control하지 않았기 때문.
- genre classifier가 잘 작동하는 것을 확인.
- SCSC label fidelity 최고
- perplexity에서도 좋은 성능 보이긴 했으나 dist-n은 좀 떨어짐
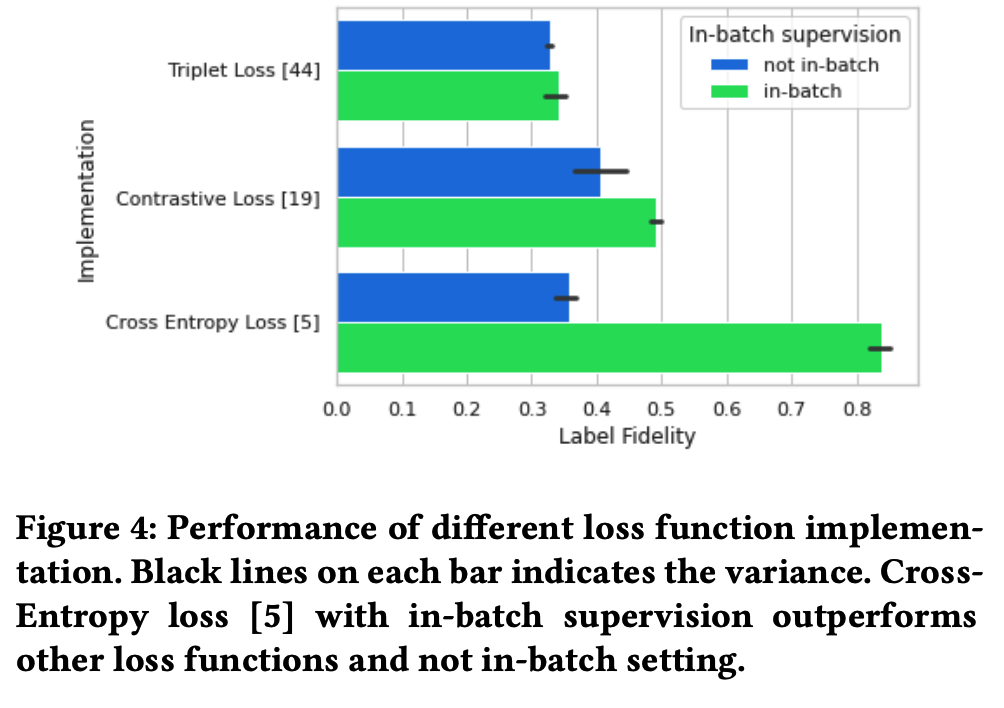
- Ablation stduy
- L_scl을 빼면 label fidelity가 급격하게 떨어짐 = 모델이 supervised contrastive learning을 통해 controlability가 제어되고 있음을 시사.
- without in-batch 에서 label fidelity 떨어짐
5.1.2 Human Evaluation Results
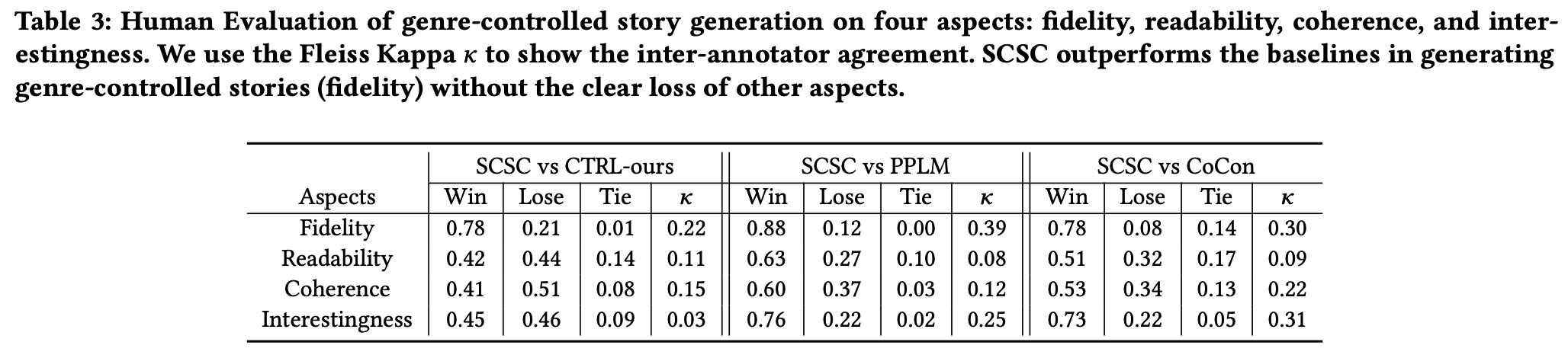
- SCSC가 fidelity, interestingness score 높음.
- discussion 에서 controllability가 fluency에 영향을 미칠 것이라는 주장에 뒷받침
5-2. Analysis of Genre Controllability
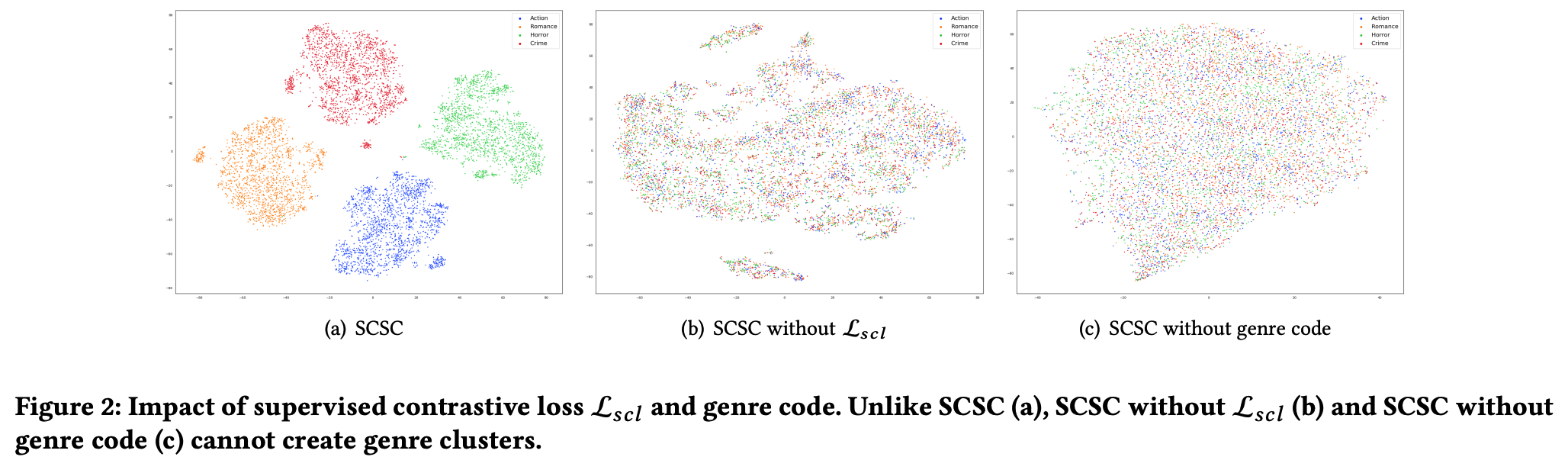
- 방법
- input sequence의 첫 32 token들을 사용해서 모델에 넣어 representation 구해서 t-SNE 해봄.
- 결과
- (a) : the supervised contrastive objective는 비슷한 장르들 가깝게 위치시킨다
- (b) : log-likelihood는 (a)에 비해 흩어져 있음.
- (c) : (a)랑 상황 같은데 genre code가 없을 때.
5-3. Analysis of Training Objective (생략)
마무리
- 요약 : 본 논문은 genre를 컨디션으로 두고 스토리 생성을 하는 연구를 진행함. 결과적으로 genre를 구분하여 스토리를 생성할 때 (1) genre code의 유무 (2) contrastive learning 방식이 중요한 역할을 하였음.
- future work : perplexity, fluency 향상
- 얻은 점
- pos, neg sampling 하는 방법.
- 예전에 empathy generation했을 때 reinforcement learning을 썼는데, contrastive learning도 써볼 수 있지 않을까?
