
Summary
-
Background
: 기존 NLP task들 task에 특화된 dataset을 가지고 supervised learning 방식으로 모델을 훈련시켰다. -
Research Goal
: To build general systems
-
Approach
: GPT-2; 1.5B parameter Transformer
- sufficiently large language model
- zeroshot setting
- Byte pair encoding (BPE) -
Results & Findings
- zeroshot setting에서 진행된 8개 테스트에서 7개 부분에서 SOTA 달성
- GPT-2는 Supervised learning 없이도 (e.g., transfer learning) Task를 학습할 수 있었다 (e.g., zeroshot setting).
Paper: Language Models are Unsupervised Multitask Learners
Github: https://github.com/openai/gpt-2
Introduction
Background
- ML의 발전으로 많은 system들이 특정 task에서 우수한 성능을 보이고 있다. 하지만 특정 task에 국한되어 있기 때문에 data distribution이 조금이라도 바뀌면 System은 제 기능을 못한다.
-> NotGeneralizedbutCharaterized! - 특정 task에 맞춰진 대부분의 ML system들은 narrow experts로서 제기능을 하지만, captioning models, reading comprehension systems, image classifier처럼 input이 다양한 task에는 밑바닥을 보이고 만다 ㅎㅎ.
- Robust system을 만들기 위한 일환으로 다양한 도메인에서의 성능을 측정할 수 있도록 GLUE, decaNLP 등의 metric들이 제안되기도 하였다.
Research Goal
- 훈련을 위한 데이터셋 구축을 하지 않아도 Many task를 수행할 수 있는 General systems를 만들자!
Language models can perform down-stream tasks in a zero-shot setting - without any parameter or architecture modification.
Approach
-
Multitask learning (MTL) :MTL은 여러 task를 함께 학습하여 general한 feaute를 뽑게 해 general performance 향상에 도움이 되는 framewrok이지만, NLP 분야에서는 아직 발전이 덜 되었다. 여기서는 MTL 방식으로 gpt-2를 학습시킨다는 게 아니고, Multitask에서 general하게 작동한다는 의미로 multitask 용어를 사용한 것 같다.
-
Meta-learnig : 기존의 ML 모델은 generalize하기 위해서 수많은 데이터셋이 필요하다. 더군다나 MTL을 하려면 너무 많은 수의 데이터셋이 필요한데, 만약 데이터가 적다면? Meta-learning 방식은 unseen task에 대해 적은 양의 데이터(few or zero shot)를 보여줬을 때에도 빠르게 학습할 수 있다.
reference : https://simpling.tistory.com/41
Method
Unsupervised MTL (~> zeroshot setting)
- Language modeling은 이론적으로 unsupervied learning 방식임. (언어 모델링(Language Modeling)은 주어진 단어들로부터 아직 모르는 단어를 예측하는 작업. 즉, 언어 모델이 이전 단어들로부터 다음 단어를 예측하는 일은 언어 모델링.) 기존 연구에 따르면 sufficiently large language model들은 supervised 방식보다 속도는 느리지만 MTL을 수행할 수 있다고 함.
- 본 연구자들은 언어모델이 충분히 크다면 데이터를 대화데이터를 가져오든, 인터넷에 있는 데이터를 가져오든 조달 방법과는 상관없이 자연어 시퀀스에서 수행된 태스크들을 잘 infer하고 perform할 것이라고 예상함.
reference : https://wikidocs.net/21668
Training Dataset
- Goal : 다양한 도메인에서 자연어 demonstrations of tasks를 수행하기 위해서 할 수 있는 한 다양하고 방대한 양의 데이터셋을 구축하고자 함.
- WebText 구축 : reddit data, 40GB
Input Representation (BPE)
- Byte Pair Encoding (BPE) : subword 기반 인코딩 방식. character 단위로 단어를 분해해서 vocab 생성하고, greedy하게 빈도수가 높은 문자 쌍을 vocab에 추가 (장: out of vocab (OOV)에 강함)

referecne : https://supkoon.tistory.com/25 - 한계
- 기존의 대규모 LM들은 공간 확보를 위해 전처리 과정을 포함하고 있다. 그런데, 이때 UTF-8 시퀀스로 유니코드 string을 처리하기 때문에 byte-level (LM)을 사용하면, word-level LM사용했을 때보다 성능이 떨어진다.
Unicode : 유니코드는 글자와 코드가 1:1매핑되어 있는 ‘코드표'
UTF-8은 유니코드를 인코딩(encoding)하는 방식
reference: reference - 기존 Byte paire encoding (BPE) 바이트 시퀀스가 아니라 유니코드 시퀀스에서 주로 작동하기 때문에 모든 unicode string을 모델링 하기 위해선 많은 space가 필요하게 된다.
- Byte-level의 BPE를 사용하려고 하면 greedy 방식으로 빈도수에 기반하여 word를 만드는데, 이때 같은 단어라도 다양한 변주로 만들어지게 되어버림 (e.g., dog? / dog. / dog!). 그럼 불필요한 공간을 잡아먹음.
- 기존의 대규모 LM들은 공간 확보를 위해 전처리 과정을 포함하고 있다. 그런데, 이때 UTF-8 시퀀스로 유니코드 string을 처리하기 때문에 byte-level (LM)을 사용하면, word-level LM사용했을 때보다 성능이 떨어진다.
- 해결
- 여러 vocab에서 공통적으로 나타나는 최소한의 단어 조각들만 추가함으로써 BPE가 byte sequence에서 아무 character categories끼리 merging하는 것을 막는다.
- 장점
- any Unicode string에 probablility를 assign할 수 있기 때문에 토크나이제이션이나 vocab size에 상관없이 어떠한 데이터셋에서도 작동할 수 있도록 해준다.
- GPT-2를 학습하고 Byte-level BPE를 사용하였기 때문에 UNK 토큰 발생 가능성 낮음 (40조 바이트 중 26번 정도 UNK 발생)
BERT 는 WordPiece Tokenizer 사용. (BPE 변형 알고리즘으로 빈도 수로 쌍을 만드는 게 아니고, 병합했을 때 corpus의 likelihood를 가장 높이는 쌍끼리 결합.)
reference: https://wikidocs.net/22592
Model
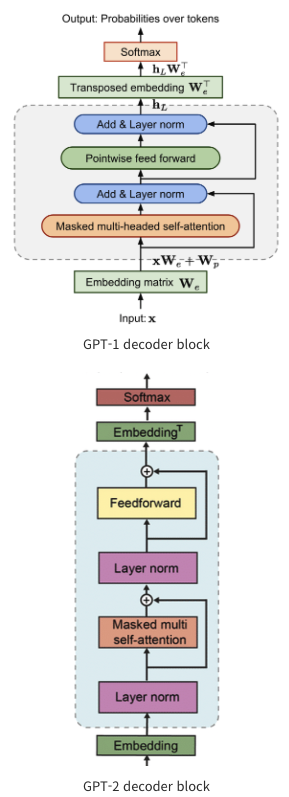
reference : https://supkoon.tistory.com/25
- GPT-1과 거의 비슷한 구조를 가지고 있음.
- 달라진 점
- Layer normalization
- 위치 : a pre-activation residual network랑 비슷하게 layer normalization이 input의 sub-block으로 옮겨짐 ( LayerNorm을 Attention과 Feedforward 출력부에 두는 것보다 입력부에 두는 것이 학습 시 레이어별 Gradient의 정도가 상대적으로 고른 편이라 합니다.)
reference : https://modulabs-hub.oopy.io/db1871c6-75b1-4229-a86b-72516d4b735f
- 추가 Layer : 마지막 self-attention block 이후에 layer normalization이 하나 추가되었다.
- 위치 : a pre-activation residual network랑 비슷하게 layer normalization이 input의 sub-block으로 옮겨짐 ( LayerNorm을 Attention과 Feedforward 출력부에 두는 것보다 입력부에 두는 것이 학습 시 레이어별 Gradient의 정도가 상대적으로 고른 편이라 합니다.)
- weights of residual layers at initialization : (the accumulation on the residual path with model depth)
- `# of Vocab : 50,257
- context size : 512 -> 1024
- batch size : 512
- Layer normalization
Results
- zeroshot setting에서 진행된 8개 테스트에서 7개 부분에서 SOTA 달성
- BPE 사용해서 UNK 잘 없음
Test
- Children's book test
- Lambda
- Winograd Schema Challenge
- Reading Comprehension
- Summarization => 좋은 성능 안나옴
- Translation
- Question Answering
- Generalization vs Memorization
Implementation
-
gpt2
-
Kogpt2
https://huggingface.co/skt/kogpt2-base-v2
https://github.com/SKT-AI/KoGPT2 -
Kogpt2 를 활용한 심리상담 챗봇
https://github.com/nawnoes/WellnessConversation-LanguageModel
-
Kogpt2 를 활용한 법률 상담 챗봇 아직 제대로 하진 않은듯..?)
마무리
GPT-2는 Finetuning 없이 어떠한 task에서도 general하게 잘 작동할 수 있도록 Unsupervised pre-training작업을 극대화시킨 pretrained language model이다. 이를 위해서 1) 충분히 큰 데이터로 학습을 하고 2) Byte pair encoding을 사용해서 어떠한 데이터에서도 robust한 tokenization을 할 수 있도록하였다. 결과적으로 zeroshot setting에서도 8개 중 7개의 task에서 SOTA를 보였다.
