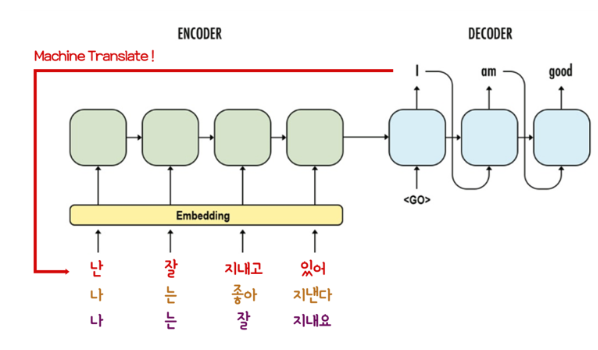
[NLP] Learning to Generalize to More: Continuous Semantic Augmentation for Neural Machine Translation (ACL, 2022)
NLP
Summary
-
Background:
- Neural Machine Translation (NMT) task에서는 training 데이터 수에 따라서 generaliation performance가 달라진다.
- 그래서 training data를 늘리기 위해 Augmentation기법이 사용되고 있는데, 기존의 discrete manipulation 방법은 diverse 하고 faithful한 sample을 만드는 데 실패했다.
-
Challenge:
- 1) diverse하게 augmentation하면서 2) original text의 의미는 살리기
-
Method:
- Continuous Semantic Augmentation (CSANMT):
- 1) augment할 수 있는 embedding 범위는 continuous하게 만들어서 다양성을 주되 (adjacency semantic region)
Tangential Contrastive Learning - 2)sampling 범위는 제한을 둬서 기존 의미는 살린다.
MGRC Sampling
- 1) augment할 수 있는 embedding 범위는 continuous하게 만들어서 다양성을 주되 (adjacency semantic region)
- Continuous Semantic Augmentation (CSANMT):
-
Experiment & Result:
- low resource setting에서도 실험
- SOTA 달성
-
목차만 봤을 때 느낀점! : method부분이 엄청 디테일하고, analysis도 분야를 나눠서 꼼꼼하게 분석했다. 까일 구석을 못만들겠다는 듯이. 그리고 수도코드도 있는데 실제 코드도 덧붙였다 ㅇ_ㅇ 와우~
method부분에서 이런게 novelty다 하는 걸 배워보자!!!!!!!
paper: https://aclanthology.org/2022.acl-long.546.pdf
github: https://github.com/pemywei/csanmt
1 Introduction
Background
- 기존 Data Augmentation (DA)
- Approach : To leverage abundant unlabeled data fro augmenting limited labeled data!
- Methods
- 참고: http://dsba.korea.ac.kr/seminar/?mod=document&uid=1328
- Back translation (BT)
- Adversarial inputs with perturbations
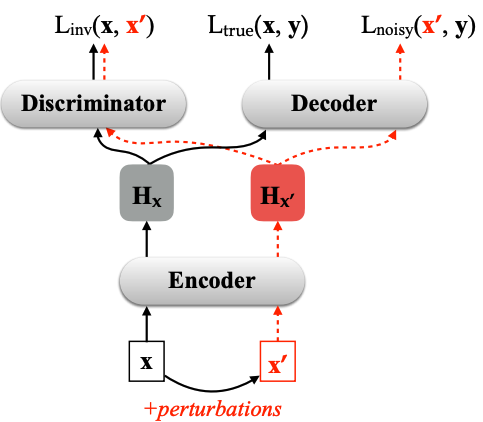
Cheng, Y., Tu, Z., Meng, F., Zhai, J., & Liu, Y. (2018, July). Towards Robust Neural Machine Translation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1756-1766).
- Limitation
- trainig 데이터를 discrete space에 augmenting하면 diversity가 떨어진다.
- EX1) BT: beam search, greedy search 방식은 approximate algorithms으로 the maximum a-posteriori (MAP) output을 identify하는 방식임. 그래서 ambiguity할 때 가장 자주 나타난 것 (frequent)을 선택함.
- EX2) 이후에 output distribution을 sampling해서 diversity를 높이려고 했는데 low quality가 문제였음.
- EX3) 하나의 문장을 여러 개 형태로 만드는 걸 시도했는데, 같은 의미 안에서 변주를 주는 데 실패.
- descrete space에서 original meaning을 유지하면서 augment하는 건 어렵다.
- 일반적으로 대부분의 discrete manipulation (adds, drops, reorders, replaces) 적용하면 text의 원래 의미를 바꿔버림.
- EX1) word들을 replace하는데 이때 language model 이용해서 embedding을
interpolating 해가지고같은 context를 가지고 있는 단어로 바꾼다.
=> But 얘네는 word-level에서만 작동하고 sentence 단위로 rephrasing 못함.
- trainig 데이터를 discrete space에 augmenting하면 diversity가 떨어진다.
Challenge
- Diversity 높이기
- Original meaning 유지하기
Approach
- 1) Vectors in continuous space can easily cover adequate variants under the same meaning.
계속 descrete한것의 단점을 말했음. 그래서 continuous한 작동이 필요하단거겠지? - 2) Vicinal Risk Minimization (VRM)
- Data augmentation를 공식화 할 수 있는 또다른 원리 중 하나; observed instance의 vicinal distribution에서 pseudo smaple을 추출
- vicinity of a training example: using dataset-dependent heuristics
- color augmentation in CV
- adversaria augmentation with manifold neighborhoods in NLP
in this paper, adjacency semantic region (the vicinity manifold)을 포함하고 있는 VRM 사용
Method
Continuous Semantic Augmentation (CSANMT):
descrete sentences들을 continuous space로 transforming 시켜서 data space를 augment하고 NMP 모델의 generalization capability를 개선!
- 1) tangential contrast 방식으로 semantic encoder 훈련; continuous space에서 각 trainig instance들이
adjacency semantic region을 support하고region의 tangent points를 semantic을 유지하는데 중요한 요소로 인식하게 함. - 2) Mixed Gaussian Recurrent Chain (MGRC) 알고리즘 사용해서 adjacency semantic region안의 vector cluster들 sampling;
- 3) sampling된 vector들은 decoder로 들어가서 broadcasting integration network 구축; asnostic to model architectures
Experiment & Result
- 다양한 translation benchmark dataset으로 eval하고 SOTA 달성
- low-resource에서도 좋은 성능 보여줌
2 Framework
Problem Definition
-
Notation
- (x,y) (X,Y)
- X,Y : source, target 데이터 spacese
- x,y : 같은 meaning 가지고 있는 pair sentences. 문장이니까 각각은 T개의 토큰들로 이루어져있음.
- (x,y) (X,Y)
-
Goal
-
Task 1 - NMT: to maximize the log-likelihood
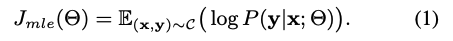
-
Task 2 - Augmentation
- Challenge
- Diversitiy
- 기존 meaning preservation
- generalizing to unseen instances
[Recap] 기존 seq2seq NMT 한계
- 기존의 supervised setting의 NMT 방식은 데이터 수에 의해 학습이 좌지우지 됌. 그래서 unseen data에 대해서는 성능이 하락해버림.
- 보통 seq2seq은 source space를 target space로 transformation하는 걸 학습함.
- Challenge
-
2.1 Continuous Semantic Augmentation (CSANMT)
- 기존 transformer 구조에 추가적으로 augmentation하는 component 삽입!
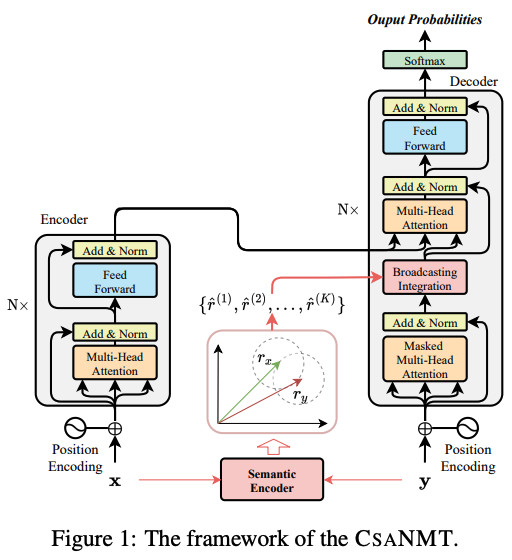
[Recap] 원래 transformer 구조
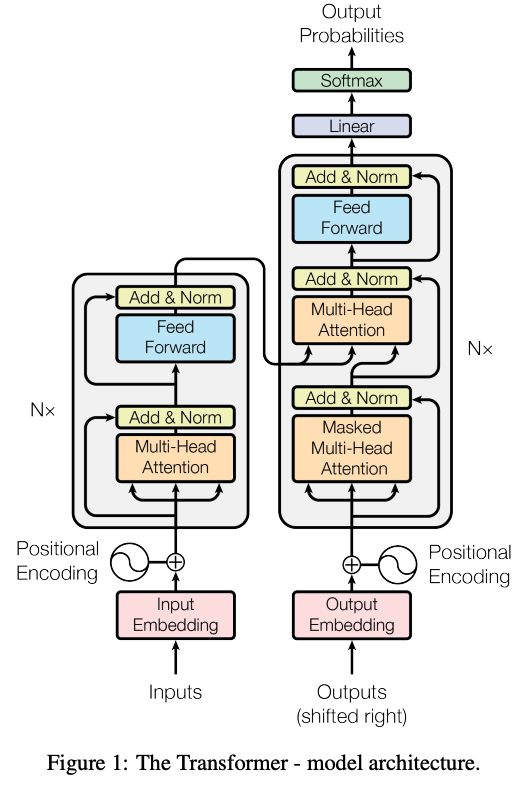
Semantic Encoder
x,y라는 discrete sentences들을 forward function 을 통해 continuous한 vector로 mapping 시켜버림. => source와 targe language들이 universal한 semantic space에 위하게 됨.
- : the forward function of the semantic encoder parameterized by
- : adjacency semantic region
- semantic space가 만들어지면, 각각 continous vector들은 adjacency semantic region이 생기게 된다. (그림의 점선 원형 부분)
- 이들은 기존의 sentence pair를 중심으로 생긴 literal expression의 adequate variants라고 정의 내릴 수 있다.
그럼 저 공간에 있는 애들 사용해서 새로 만드는 거겠지?
Broadcasting Integration
-
Process
-
1) adjacency semantic region이 생겼으면 거기서
K개 만큼 vector sample들을 뽑는다.-
x,y 상관없이 뽑는거구나?
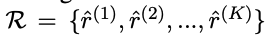
-
-
2) 그럼 각각의 sample들은 broadcasting integration network를 통해서 원래의 generation process (본래의 NMT 수행하러)로 통합된다.
- : the output of the self-attention at position t
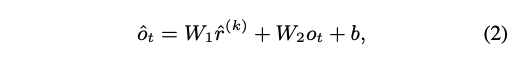
- : the output of the self-attention at position t
-
3) Final training objective
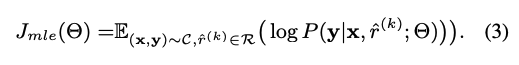
[Recap] 기존 NMT objective
-
-
Challenge
traininig instance 를 augmentation하는데 adjacency semantic region에서 다양한 sample들을 가져왔기 때문에 unseen instances에서도 generalize할 것이다!기존 방식들은 discrete한 방식이라서 pair를 이루며 새롭게 생성했지만 이건 distribution 차원에서 변주를 줬으니 더 다양한 sample이 나올 수 있겠지???BUT!
- 1) semantic encoder를 어떻게 optimize하면 좀 더 효율적인 adjacency semantic region을 만들 수 있을까?
Tangential Contrastive Learning - 2) adjacency semantic region에서 어떻게 sampling하는 게 효과적일까?
MGRC sampling
- 1) semantic encoder를 어떻게 optimize하면 좀 더 효율적인 adjacency semantic region을 만들 수 있을까?
Tangential Contrastive Learning
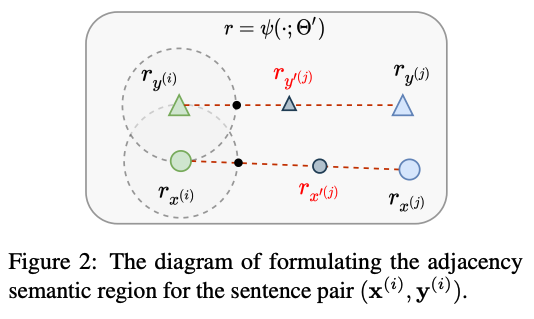
[Recap] adjacency semantic region
- 중심으로 펼쳐진 원 안에 있는 애들 랑 의미가 같다고 보는 겨.
- Process
- 1) negative sample 만들기 - 같은 training batch안에서 convex interpolation을 적용해 negative sample 뽑기.
- 2) tangent point (= the point on the boundary)를 semantic equivalance의 critical한 states로 취급한다 (
따지면 same meaning의 마지노선 이니까?)
- Objective
- 분자는 maximize ( 비슷한 건 가깝게), 분모는 minimize (다른 건 멀게)
- x,y는 가깝게, x-x' & y-y'는 멀게
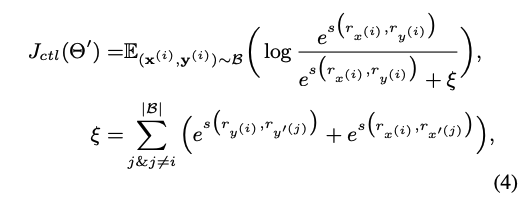
- : a batch of sentence pairs randomly selected from the training corpora
- : the score function that computes the cosine similarity between two vectors
- : negative saples
- (1) 가 보다 크거나, (2) and 일 때만 negative sample 쳐준다!!
그니까 적당히 멀어야 region안에 안들어오는 애들로 negative sample 만드는거군! 굳이 lambda 값을 만든 이유는 tuninig 해가지고 sample 여러개 만들려는 것이군!!
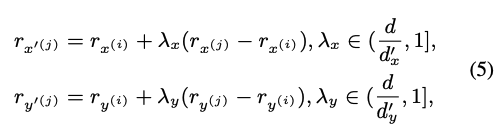
-
-
- 근데... 일때라는 건 계산해보니 일 때라는 건데 이게 말이 됩니까? negative sample이랑 orginal이랑 같을 때라니요..????
- 아하 vector 계산으로 해야 하는 구나?
그렇다면 이 뜻은 빨강색선과 초록색 선이 같아지는 때! 일 때 겠다.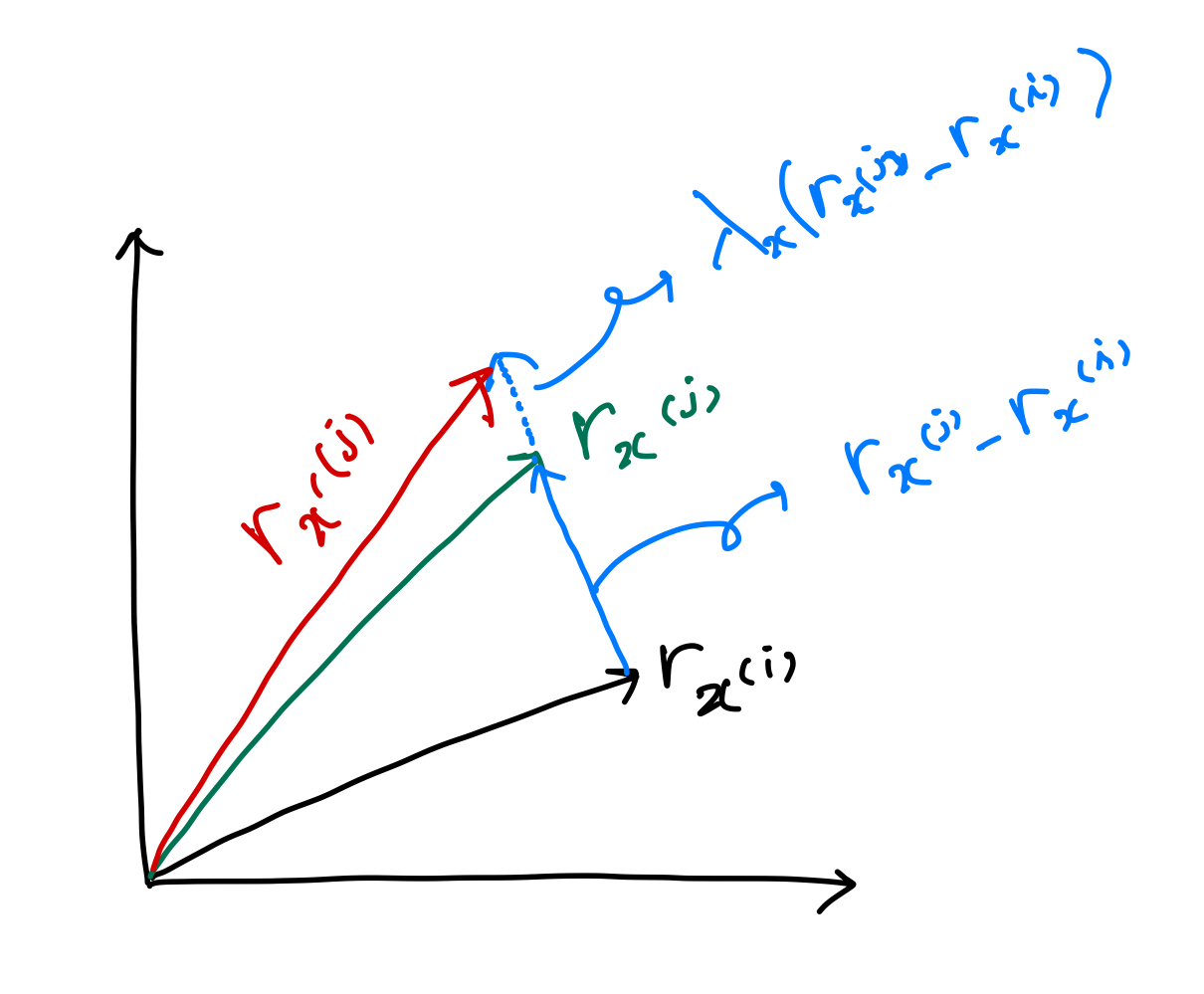
-
- (1) 가 보다 크거나, (2) and 일 때만 negative sample 쳐준다!!
MGRC Sampling (Mixed Gaussian Recurrent Chain)
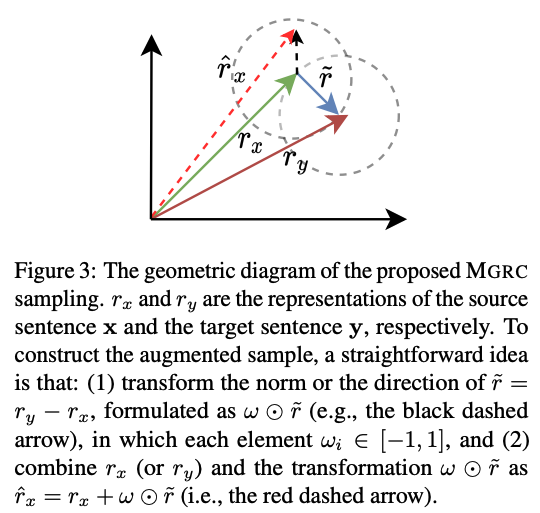
- Goal:semantic region이 만들어졌으면 이제 거기서 양질의 augmented sample들을 뽑아내야 함!
- New goal: to find a set of scale vectors
- novel sample :
- New goal: to find a set of scale vectors
- 구하기 (자세하게는 아래 알고리즘 참고)
- 존재하는 분포 는 두 가지 gaussian form으로 구성
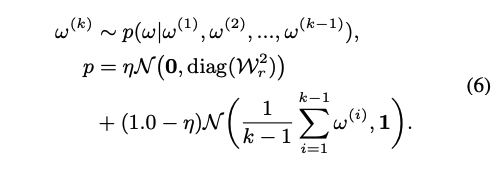
- 1) sampling하는 subspace 범위를 중요도가 높은 곳으로 제한해서 informative한 element들 안에서 sampling될 수 있도록 형성
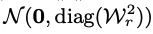
- 2) Recurrent Chain ~ : 전단계에서 나온 vector를 기반으로 reasonable한 vector sequence를 만들어냄
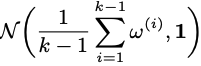
- : 두 분포의 importance 조절
- 는 sample의 수가 많아질 수록 stationary 한 distribution이 될 수 있고, 이는 training instance의 diversity가 유한하다는 것을 의미한다.
무슨소리래- 나의 짐작: sample 수가 충분히 많아지면 분포는 일정한 패턴으로 수렴한다. 그러니까 엄청난 변이는 없다는 것이지. 그러니 original meaninig에서 크게 안벗어날 수 있도록 장치를 썼다. 이런 거 아닐까?
- 얘네의 challenge가 1) Diversitiy 2)기존 meaning preservation 인데 1)은 tangent contrastive로 semantic region만들어서 달성하고, 2)는 sampling을 제한된 공간에서 하면서 원래에서 크게 벗어나지 않게 하는 것이지!
- 는 sample의 수가 많아질 수록 stationary 한 distribution이 될 수 있고, 이는 training instance의 diversity가 유한하다는 것을 의미한다.
- 존재하는 분포 는 두 가지 gaussian form으로 구성
- 알고리즘

- input : training instances
- output : augmented된 k개의 sample들
- process
- L1) 안에 있는 각 element들의 중요도를 구해서 normalizing 한다.
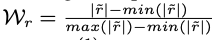
- 값이 클수록 중요하고 informative하단 뜻!
- sampling하는 subspace 범위를 제한해서 정보가 없는 공간에선 sampling하지 않는다!
- L2,3) 초기화
- L4) recurrent chain
- L1) 안에 있는 각 element들의 중요도를 구해서 normalizing 한다.
2.2 Traninig and Inference
- The trainig objective: eq3,4 둘다!
- 1) train the semantic encoder from scratch using the task-specific data ( )
- 2) optimize the encoder-decoder model by maximizing the log-likelihood ( )
- 3) fine-tune the semantic encoder with a small learning rate
- 1) train the semantic encoder from scratch using the task-specific data ( )
3 Experiments
3.1 settings
Datasets
| Task | Corpus | Val | Test |
|---|---|---|---|
| Zh -> En | LDC | NIST2006 | NIST2002,2003,2004,2005,2008 |
| En -> DE | WMT14 | newstest2013 | newstest2014 |
| En -> FR | WMT14 | newstest2012,2013 | newstest2014 |
*Zh: Zhōngguó
Training Details
논문 확인
Baselines
- Transformer
- BT
- SwitchOut
- SemAug
- AdvAgu: embedding space에서 word를 replace
3.2 Main Results
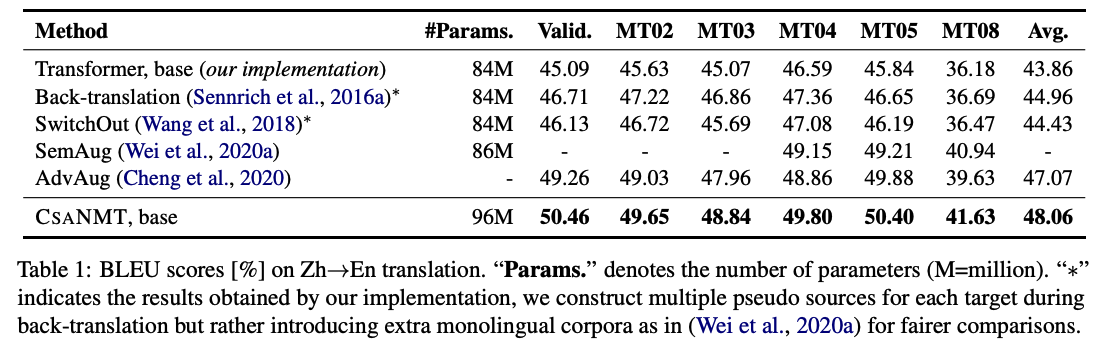
Results of Zh->En
- Ours > BT, SwtichOut: discrete manipulation 방식보다 continous space에서 augmentation한 것이 더 효과적이다.
- Ours > AdvAgu: word-level 보다 sentence-level augmentation이 더 좋다!
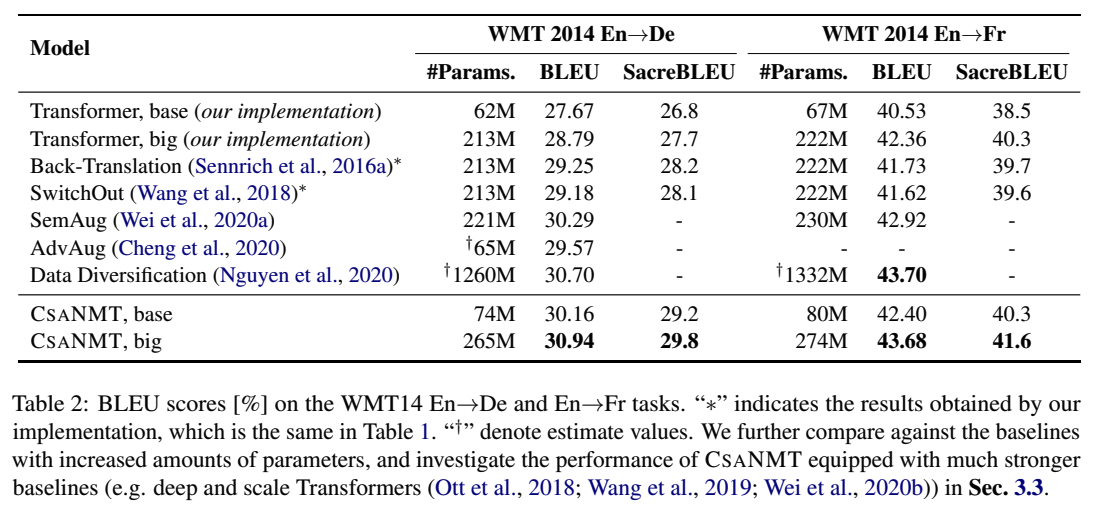
Results of En->De and En->Fr
- Data Diversification > Ours in En->Fr: 성능이 더 좋은데 forward, backward NMT모델 여러개 결합한 거여서 training efficiency 안 좋아~~
3.3 Analysis
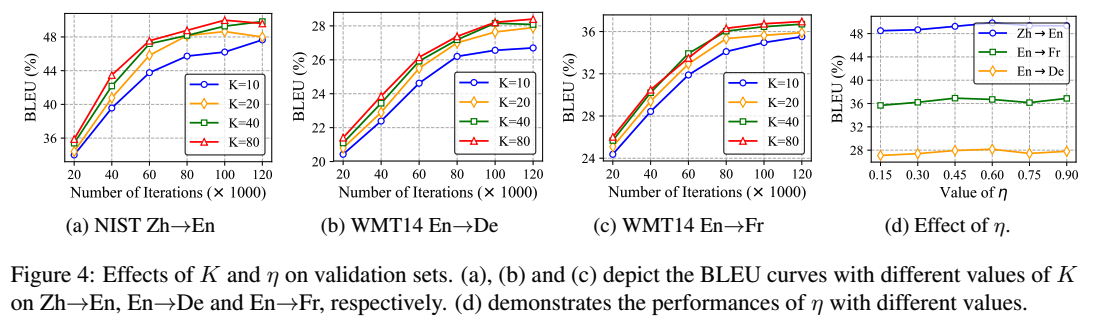
Effects of K and
- K 10 < K 80< K 40
- (1) training instance의 diversity는 유한해서 만들어지는데 한계가 있다! => MGRC gets saturated (=수렴하다)
- (2) scaled vector 사용해서 sampling하는 공간을 제한했는데, 이게 성능을 제한시켰을 수도 있다 (
많이 만드는 데 한계를 만들었다?!)
Lexical diversity and sementic faithfulness
- Metric
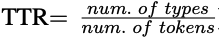
- BLEURT : BERT에 기반한 학습된 평가방법으로 수천 개 정도의 학습 예시만으로도 사람의 판단 방식 모델링
[REF]
- Result: good
Effect of the semantic encoder
- semantic encoder 없앴더니 성능이 낮아지더라

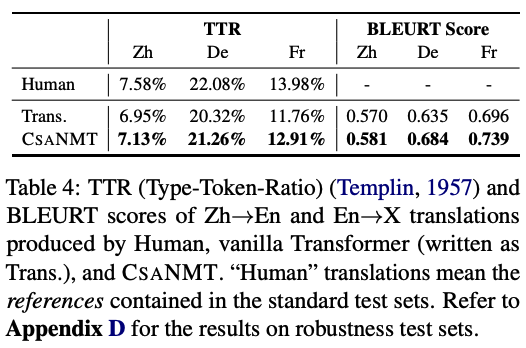
Comaprison between discrete and continuous augmentations
- discrete augmentation 방식들보다 좋더라
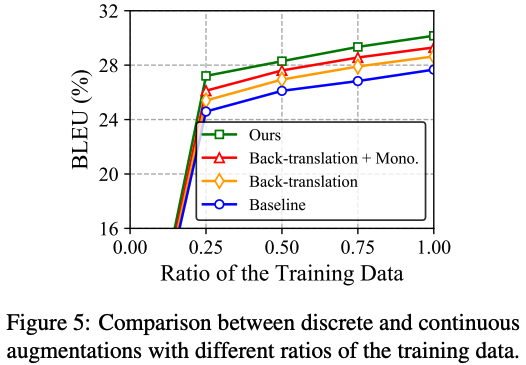
Effect of MGRC sampling and tangential constrative learning
- 우리 방식이 좋더라

Training Cost and Convergence
- iteration 적을 때도 우리 성능이 더 좋더라

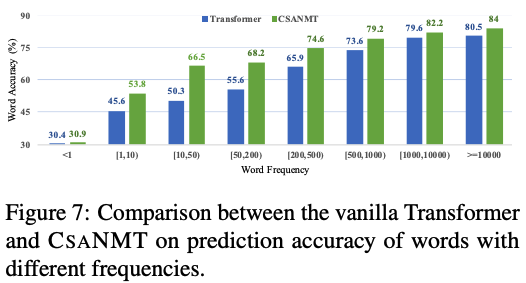
Word prediction accuracy
- rare한 word들도 잘 번역하는 지 봄 (unseen data에서 robust한지 보려고!)
- 우리가 더 잘하더라~
Effects of Additional Parameters and Strong Baselines
- 파라미터 수 비등비등할 때도 우리가 성능 더 좋게 나오더라.
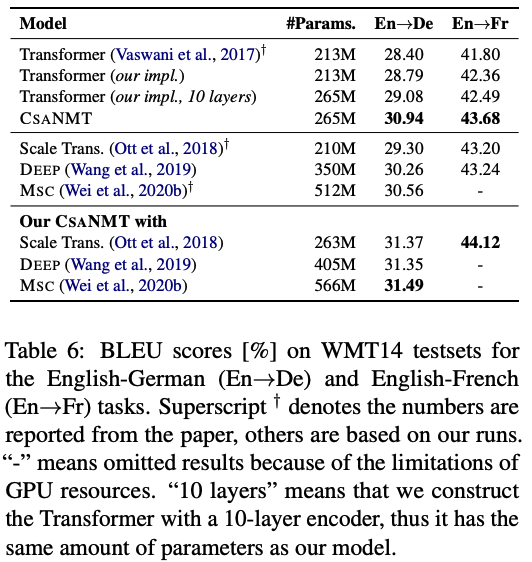
3.4 Low-Resource Machine Translation
- Dataset: IWSLT14 (En->De), IWSLT17 (En->Fn)
- IWSLT (The International Workshop on Spoken Language Translation) shared task:
- Goal: The Multilingual Task addresses text translation, including zero-shot translation
- https://workshop2014.iwslt.org/
- https://sites.google.com/site/iwsltevaluation2017/TED-tasks
- IWSLT (The International Workshop on Spoken Language Translation) shared task:
- Result: Ours good!
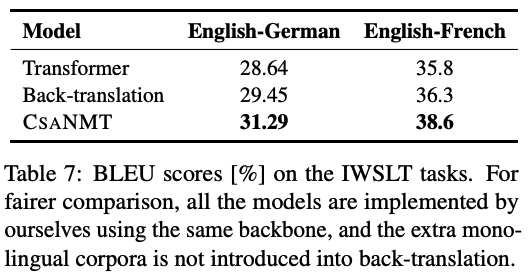
Conclusion
- 마지막 정리!
- CSANMT는 an adjacency semantic region as the vicinity manifold for each traning instance 를 가지고 있음.
- 이 방식은 good for making more unseen instances under generalization with very limited training data.
- Main component는 tangential contrastive learning, Mixed Gaussian Recurrent Chain (MGRC) sampling.
- rich-, low-resource setting 모두에서 좋은 성능을 거둠
- Future work
- To study the vicinal risk minimization with the combination of multilingual alighned scenarios and large-scale monolingual data
- To develop a pure data augmentator merged into the vanilla Transformer
Code review
tensorflow로 되어있어서 pytorch로 바꿈
Tangential Contrastive Learning
similarity 구하는 부분은 어디갔지? negative, positive 부분이 왜 src, tg로 되어있는거지..???
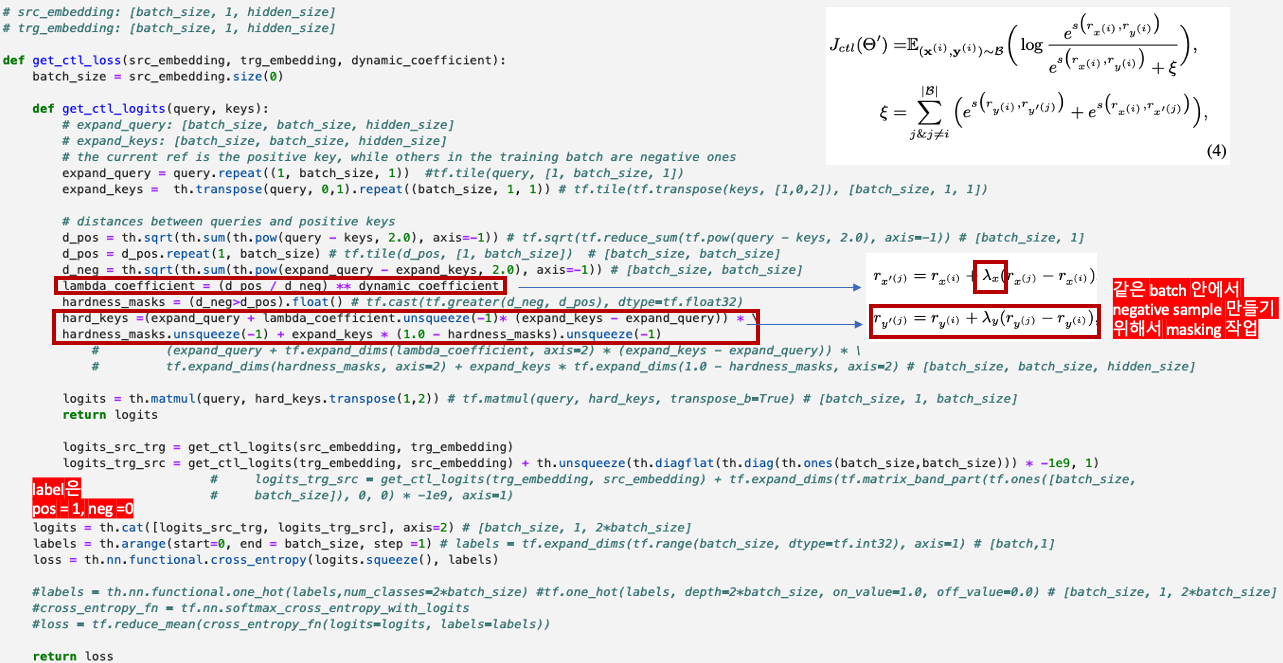
# src_embedding: [batch_size, 1, hidden_size]
# trg_embedding: [batch_size, 1, hidden_size]
def get_ctl_loss(src_embedding, trg_embedding, dynamic_coefficient):
batch_size = src_embedding.size(0)
def get_ctl_logits(query, keys):
# expand_query: [batch_size, batch_size, hidden_size]
# expand_keys: [batch_size, batch_size, hidden_size]
# the current ref is the positive key, while others in the training batch are negative ones
expand_query = query.repeat((1, batch_size, 1)) #tf.tile(query, [1, batch_size, 1])
expand_keys = th.transpose(query, 0,1).repeat((batch_size, 1, 1)) # tf.tile(tf.transpose(keys, [1,0,2]), [batch_size, 1, 1])
# distances between queries and positive keys
d_pos = th.sqrt(th.sum(th.pow(query - keys, 2.0), axis=-1)) # tf.sqrt(tf.reduce_sum(tf.pow(query - keys, 2.0), axis=-1)) # [batch_size, 1]
d_pos = d_pos.repeat(1, batch_size) # tf.tile(d_pos, [1, batch_size]) # [batch_size, batch_size]
d_neg = th.sqrt(th.sum(th.pow(expand_query - expand_keys, 2.0), axis=-1)) # [batch_size, batch_size]
lambda_coefficient = (d_pos / d_neg) ** dynamic_coefficient
hardness_masks = (d_neg>d_pos).float() # tf.cast(tf.greater(d_neg, d_pos), dtype=tf.float32)
hard_keys =(expand_query + lambda_coefficient.unsqueeze(-1)* (expand_keys - expand_query)) * \
hardness_masks.unsqueeze(-1) + expand_keys * (1.0 - hardness_masks).unsqueeze(-1)
# (expand_query + tf.expand_dims(lambda_coefficient, axis=2) * (expand_keys - expand_query)) * \
# tf.expand_dims(hardness_masks, axis=2) + expand_keys * tf.expand_dims(1.0 - hardness_masks, axis=2) # [batch_size, batch_size, hidden_size]
logits = th.matmul(query, hard_keys.transpose(1,2)) # tf.matmul(query, hard_keys, transpose_b=True) # [batch_size, 1, batch_size]
return logits
logits_src_trg = get_ctl_logits(src_embedding, trg_embedding)
logits_trg_src = get_ctl_logits(trg_embedding, src_embedding) + th.unsqueeze(th.diagflat(th.diag(th.ones(batch_size,batch_size))) * -1e9, 1)
# logits_trg_src = get_ctl_logits(trg_embedding, src_embedding) + tf.expand_dims(tf.matrix_band_part(tf.ones([batch_size,
# batch_size]), 0, 0) * -1e9, axis=1)
logits = th.cat([logits_src_trg, logits_trg_src], axis=2) # [batch_size, 1, 2*batch_size]
labels = th.arange(start=0, end = batch_size, step =1) # labels = tf.expand_dims(tf.range(batch_size, dtype=tf.int32), axis=1) # [batch,1]
loss = th.nn.functional.cross_entropy(logits.squeeze(), labels)
#labels = th.nn.functional.one_hot(labels,num_classes=2*batch_size) #tf.one_hot(labels, depth=2*batch_size, on_value=1.0, off_value=0.0) # [batch_size, 1, 2*batch_size]
#cross_entropy_fn = tf.nn.softmax_cross_entropy_with_logits
#loss = tf.reduce_mean(cross_entropy_fn(logits=logits, labels=labels))
return loss참고 - basic contrastive learning
https://jimmy-ai.tistory.com/312
MGRC Sampling
시간 없어서 못바꿈. 그런데 알고리즘이랑 아주 똑같이 코딩되어 있음

# src_embedding: [batch_size, hidden_size]
# trg_embedding: [batch_size, hidden_size]
# default: K=20 and eta = 0.6
def mgrc_sampling(src_embedding, trg_embedding, K, eta):
batch_size = tf.shape(src_embedding)[0]
def get_samples(x_vector, y_vector):
bias_vector = y_vector - x_vector
W_r = (tf.abs(bias_vector) - tf.reduce_min(tf.abs(bias_vector), axis=1, keep_dims=True)) / \
(tf.reduce_max(tf.abs(bias_vector), 1, keep_dims=True) - tf.reduce_min(tf.abs(bias_vector), 1, keep_dims=True))
# initializing the set of samples
R = []
omega = tf.random_normal(tf.shape(bias_vector), 0, W_r)
sample = x_vector + tf.multiply(omega, bias_vector)
R.append(sample)
for i in xrange(1, K):
chain = [tf.expand_dims(item, axis=1) for item in R[:i]]
average_omega = tf.reduce_mean(tf.concat(chain, axis=1), axis=1)
omega = eta * tf.random_normal(tf.shape(bias_vector), 0, W_r) + \
(1.0 - eta) * tf.random_normal(tf.shape(bias_vector), average_omega, 1.0)
sample = x_vector + tf.multiply(omega, bias_vector)
R.append(sample)
return R
x_sample = get_samples(src_embedding, trg_embedding)
y_sample = get_samples(trg_embedding, src_embedding)
return x_sample.extend(y_sample)What if I am a reviewer of this paper?
-
Strength
- 반복적으로 기존 연구에서 차별화된 점을 말하고 있고, 이게 어떻게 차별화될 수 있는지 증명까지 good
- 실험을 굉장히 다양하게 했는데, 각 실험마다 명확히 전달하고자 하는 게 있어서 좋고 결과까지 좋게나옴.
- 코드 제공을 이렇게 appendix로 간단하게 제공할 수 도 있구나!!
- 모델이 agnostic 하다는 것이 good
-
Weakness
- unclear한 notation들과 글 흐름 (=내용은 다 좋은데 설명이 좀 중구난방이네)
- 왜 problem definition이라면서 definition이 없어 이것들아. 왜 뒤에 나와~
- definition1은 있는데 왜 2는 없어! algorithm1은 있는데 왜 2는 없어! 왜 나 헷갈리게 해!
- 기존에 augmentation 방식이 엄청 많을텐데 네개만 가지고 옴. 이것들 선정 기준이 뭐였을까?
- augmented된 데이터들 숫자로는 증명 됐는데 예시도 비교해서 알려주면 더 재미있었겠다!
- unclear한 notation들과 글 흐름 (=내용은 다 좋은데 설명이 좀 중구난방이네)

4개의 댓글


좋은 논문 리뷰글 잘 보았습니다 !
1. 실제로 text augmentation을 할 때 미세한 변화에도 의미가 달라지는 경우가 있지 않을까 ? 의문이 든 적 있었는데 본 논문에서 Continuous Semantic Augmentation를 통해 이를 해결하고자 했던 점이 와닿았습니다! low resource data에 적용할 때 유용할 것이라 생각했는데, rich resource data에 적용했을 때도 좋았다는 점까지 있어서 무릎을 탁! 쳤답니다
2. 코드 리뷰까지 깔끔하게 해주셔서 어떻게 구현되었는지 확인하기 용이했습니다 tf -> pytorch 코드 바꾸는 게 손이 많이 갔을 텐데 정성이 느껴집니다 !

augmentation 관련한 좋은 본 논문 소개해주셔서 감사합니다 !! tangential contrastive 방법과 MGRC sampling 방법 알 수 있어 좋았습니다, 더불어 논문을 읽으시면서 느끼신 부분들에 대해서 알려주신 점들을 통해 논문 읽는 방법들을 함께 배운 것 같아 뜻 깊은 시간인 것 같습니다 !! What if I am a reviewer of this paper? 가 특히 인상깊었습니다. 좋은 논문 소개 감사합니다