
중간 점검
웹 스크래핑에 대해서 여러가지 시도가 있었다. 하지만 제대로 완성하지 못했다. 구조적으로나 기능적으로나 새로운 시도였고, 첫번째 시도에서는 너무 직관적으로 코드를 구성하는 바람에 다른 오류나 확장에 대해서 대비를 할 수 없엇다. 두번째 시도에서는 너무나 많은 기능과 구성으로 어느 부분에서 오류가 발생할지 가늠을 할 수 없는 코드가 되어 버렸다.
그래서 이번 블로그 포스팅을 빌미로 다시 한번 기획을 제대로 해야겠다.🤨
💡첫번째 시도
- 클래스 구조
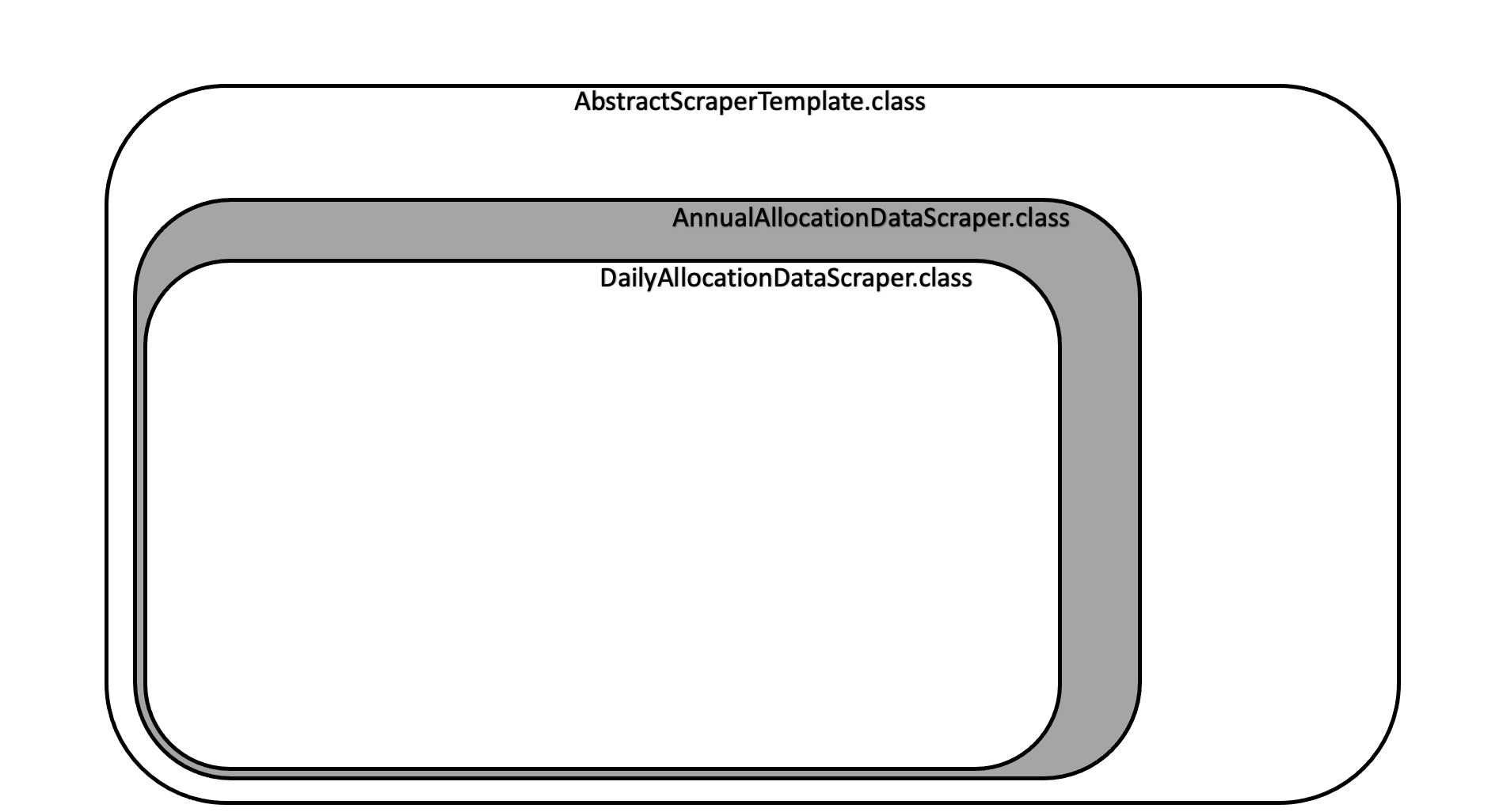
AnnualAllocationDataScraper와 DailyAllocationDataScraper는 각각 연간데이터와 일일 데이터를 불러오는 스크래퍼이다.
첫번째 시도는 템플릿 메서드 패턴을 사용하는 것이었다.
페이지의 접근과 로그인, 페이지 이동, 페이지의 로그아웃 등 스크래핑을 하는 동작 중 공통된 부분을 정의하고 일일 데이터, 연간 데이터 스크래핑 메서드를 추상화한 클래스를 만드는 방법으로 접근을 하였다. 처음은 순조롭게 분리가 되었지만, 두 로직은 중복이 꽤 많았다. 내 실력이 부족한 탓일 수도 있지만 두 로직의 공통된 부분과 회색지대의 분리가 매우 어려웠다. 결과는 완전 떡처럼 완성이 되어버렸다.
떡코딩은 지양하기에 템플릿 메서드 패턴에 대해서 적용하지 않기로 하였다.
💡두번째 시도
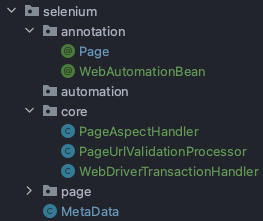
두번째에서는 POM이라는 Selenium WebDriver의 디자인 패턴을 사용하게 되었다. 첫번째 시도를 할 때에도 찾아본 개념 중 하나였다. 하지만 적용하지 않았던건 웹 페이지에 특정 데이터만을 가져오는 작업을 수행하는데 있어서 비즈니스 레이어를 나누어서 수행할 필요를 느끼지 못하였던거 같다. 첫번째 시행착오를 겪고나서 Page객체를 나누어서 웹 스크래퍼를 구성하는게 더 유연한 코드가 나올거 같아 진행하였다.
하지만 POM이라는 개념은 생소하기도 하고, 불편한 점이 많아 Spring AOP를 사용해서 좀 과하다 싶을 정도로 분리를 하였다. Page 객체를 만들 때, "좀 더 비즈니스 로직에 집중할 수 없을까?"하고 이것저것 분리하였다.
열심히는 만들긴 했는데.. 테스트를 했을 때 오류가 끝도 없이 발생했다.😕
욕심이 너무 많았다.. 코드가 너무 산으로 가버렸다..😕😕😕😕😕😕
😤 다시 한번 더
이번에는 똑바로 기획하고 어떤식으로 구조를 짜야할지 생각을 해봐야 할거 같다.
내가 저지른 잘못은 다음과 같다.
- 구체적인 설계와 계획 없이 프로젝트를 수행했다.
- 구체적인 설계의 부재로 기능에 대해서 정확히 나누지 못하였다.
- 많은 기술을 도입하려 프로젝트의 본질을 잊었다.
프로젝트를 좀 더 구체적으로 설계하고 기준을 설정하여 사용할 기술에 대해서 전체적인 맥락을 구성해야겠다. 생각의 흐름대로 프로젝트를 수행을 했을 때 계속해서 길을 잃고 해매는거 같다.
