
시작
예전에 웹 크롤링에 관한 블로그글을 본 적이 있는데, 웹 크롤링은 단순히 스크립트를 짜는 게 아니라, 변경에 대비하고 있어야 한다고 했다. 나도 그 점을 살려서 개발했다
프로젝트 기간은 약 5개월 정도 걸린 거 같다. spring boot, selenium 색깔이 진한 두 프레임워크를 조율하는데 가장 많은 시간을 할애한 거 같다. 두 프레임워크로 웹 스크래퍼, 크롤러를 만드는 글을 몇몇 보았지만, 도움은 별로 안되었다.
그리고, 스프링과 각종 기술들에 대하여 백지상태였기 때문에 공부하는 시간도 필요하였다.
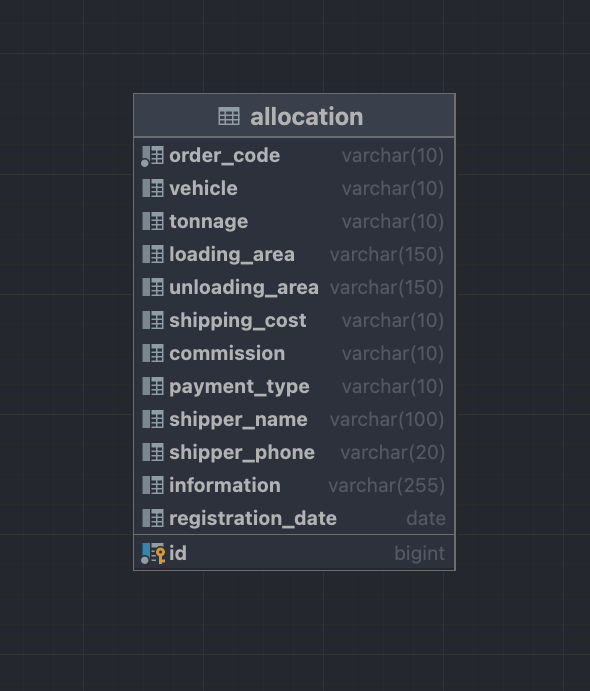
ERD
황당하지만 이게 전부이다
아직은 이게 전부이다 딱히 들은 요구사항도 없고 해당 데이터를 엑셀 함수로 데이터 집계를 하고 계셨던지라
1차적으로 이렇게 테이블 하나 정의해 보았다.
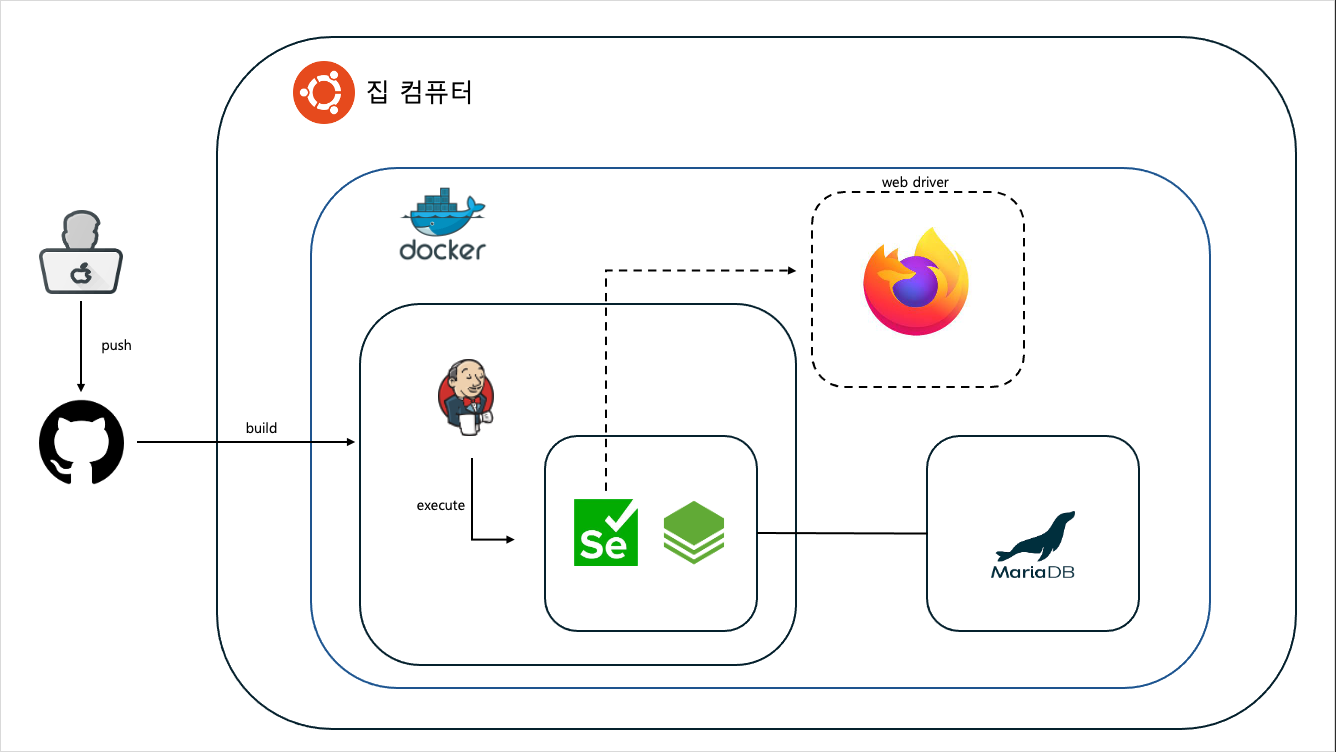
구조
-
우분투(서버 컴퓨터)
스케줄링 배치 작업을 돌리려면 서버가 필요했다. 당근에서 컴퓨터를 구해서 홈 서버를 구축했다.
(개발은 맥북)제원 : 삼보 i5 CPU, RAM 8GB, SSD 256GB
-
도커
도커는 솔직히spring boot의 docker-compose-support를 시도했기도 하였고, 도커를 사용하면서 로컬, 프로덕션 환경을 맞추고 작업하기 수월하다는 장점이 있었다. 그리고 각 컨테이너마다 격리된 환경을 가지고 있어서 관리하기가 용이했다.도커를 알아가는데 시간이 걸릴 뿐 -
젠킨스 & 깃헙
젠킨스로 웹훅을 사용하여CI구축하고, 젠킨스 크론을 사용하여 특정 시간마다 실행하는 스케줄러를 만들어보았다. 초기에는 스프링 스케줄러를 사용하려 했으나, CI환경도 구축할 겸 스케줄러로도 사용하기로 하였다. 젠킨스는 수많은 플러그인을 지원하고 입맛에 맞게 사용가능하다. 스프링 배치의Job Parameter와 젠킨스의Date Parameter,Parameterized Trigger조합이 꽤 좋았다. -
마리아 디.비
뭐.. MySQL로 대체되어도 무방할 거 같다. 선정한 이유는 다른 RDBS도 사용해보고 싶었다. -
스프링 배치
대용량 데이터를 다루지 않아도로깅/추적,트랜잭션 관리,작업 처리 통계,작업 재시작,건너뛰기,리소스 관리충분히 스케줄러와 같이 사용하면 유용한 기능도 있기에 사용했다.
그중 사용하면서리소스 관리,트랜잭션 관리측면에서 웹 스크래퍼와 잘 맞았다. 이는 추후 포스트로 다루겠습니다. -
셀레니움
본 기능인 웹 스크래퍼다. 핵심은 웹 드라이버와 코드의 싱크를 맞추기다. 그게 나한테는 복병이었다. 뻑하면 에러가 발생한다.
셀레니움은 POM패턴이 존재한다. 이를 활용하였고,변경에 대비할 수 있게 나름 객체지향적으로 설계했다. 또한, 브라우저 컨테이너를 활용하여 도커 환경에서 실행할 수 있게 했다. 나머지는 포스트로 다루겠습니다.
