[논문리뷰] ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision

Abstract
VLP task는 다양한 joint vision-language downstream task의 성능을 많이 올렸음.
여태까지의 VLP approach는 이미지 feature extraction에 의존을 많이 함. 근데 이 과정에서 obj det과 같은 region supervision이나 convolutional 아키텍처를 요구함.
이런 어프로치는 성능과 속도, 그리고 표현력에 한계가 있음. (feature extractor(=visual embedder), predefined visual vocabulary를 가지고 그 뒤 학습이 진행되니까)
이 논문에서는 minimal VLP model인 ViLT를 소개함.
visual input을 처리하는 과정이 극적으로 간소화되었고, convolution-free manner로 visual/text input을 처리한다.
ViLT는 이전으 ㅣVLP 모델보다 약 10배 가량 빠르고, downstream task 적용에 견줄만하거나 그 이상의 성능을 보인다.
Introduction
traditional VLP
- embed image pixels in a dense form alongside language tokens
- use deep conv network for visual embedding
- employ obj-detector pre-trained
여태까지는 visual embedder가 heavy해지더라도, 이 부분의 power를 키워서 성능을 올리는 연구들이 대부분이었음. 근데 이렇게 하면 feature extraction이 real-world 상황에서 너무 cost가 큼.
그래서 이 연구에서는 경량&빠른 visual input embedding에 주목함.
최근의 연구에 따르면, simple linear projection of a patch를 사용하는 것이 트랜스포머에 먹이기 전에 픽셀을 임베딩 하는데에 충분하다고 함.
이 연구에서는 VLP model의 modality interaction에 쓰인 트랜스포머 모듈이 convolutional visual embedder이 하던 역할 (visual feature processing)도 할 수 있다고 가정한다.
Previous works와의 차이점 정리
- shallow
- convolution-free embedding of pixel-level inputs
- 10 times faster than VLP w/ region features
- 4 times faster than VLP w/ grid features
- similar/better performance on downstream task
deep embedder를 제거함으로써 모델 크기, 러닝타임을 줄일 수 있었음.
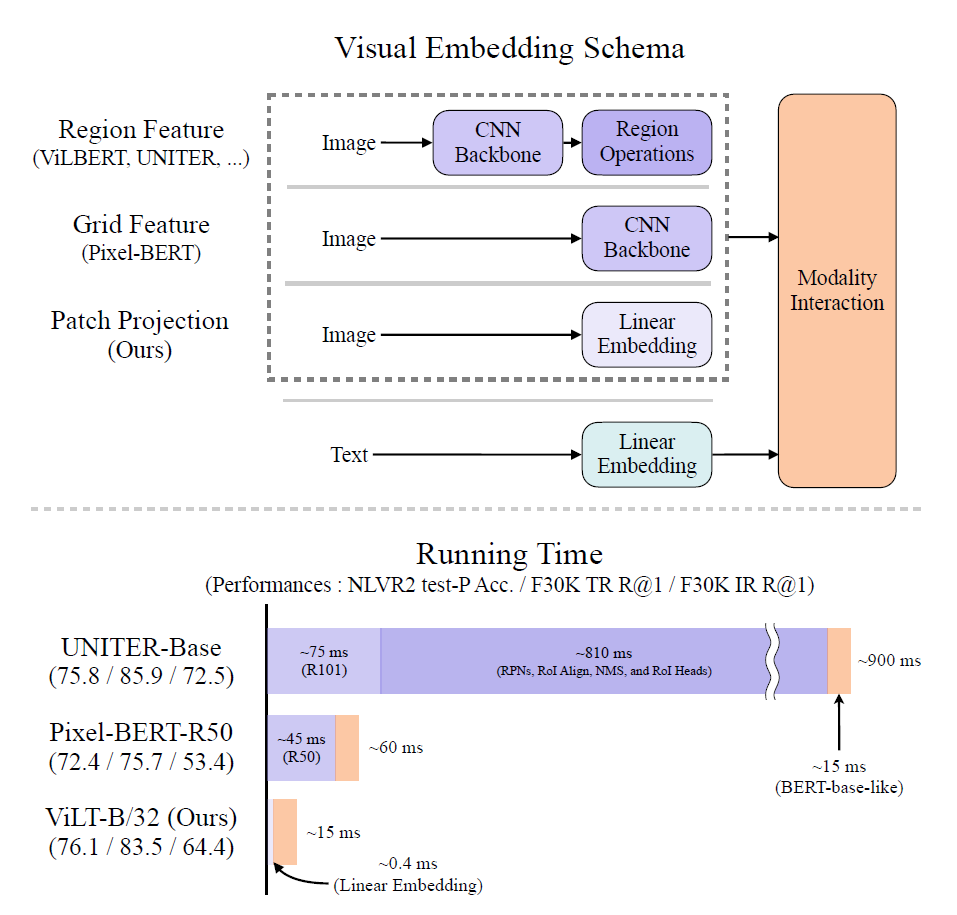
Contributions
- simplest architecture by far for VL model. visual feature extracting+processing을 분리된 visual embedder로 처리하는게 아니라 transformer module로 처리하기에 runtime, parameter efficiency 향상됨.
- 최초로 region feature나 convolutional vision embedder 사용 없이도 그에 준하는 퍼포먼스를 냄.
- 최초로 whole word masking, image augmentation을 시도하고, 이 방법이 downstream task에 더 좋은 성능을 낸다는걸 입증함.
Background
Vision-Language model 톺아보기
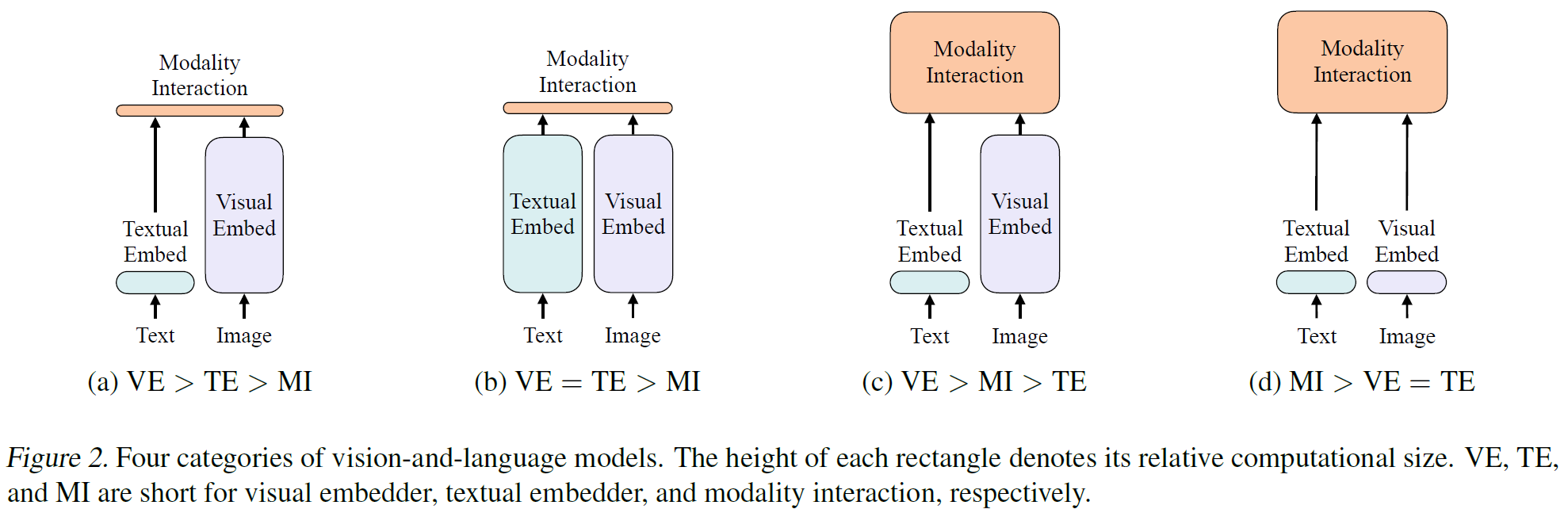
(a) VSE, VSE++, SCAN.
- represent the similarity of the embedded features from 2 modalities with simple dot products or shallow attention layers
(b) CLIP
- dot product btw pooled image vector and text vector
- useful for zero-shot, but not good at VL downstream tasks
(c) 요즘 가장 흔한 형태. use deep transformer for interaction btw image/text features
- conv networks still involved at extracting/embedding image feature → high computation cost
(d) ViLT
- embedding layers of raw pixels are shallow, computationally light
- concentrate on modeling modality interaction
암튼 저자들은 modality interaction이 지금까진 너무 shallow하게 이루어졌다고 말하고 있음.
그리고 visual embedding 과정이 너무 heavy 하다고 말함.
그래서 ViLT는 embedding cost를 줄이고, 대신에 modality interaction 모델링에 집중한다고 함.
Modality Interaction Schema
오늘날의 VLP 모델의 중심엔 트랜스포머가 자리함.
- input: visual, textual embedding sequence를
- layer: inter-modal, (optionally) intra-modal
- output: contextualized feature sequence
Single-stream approaches
- Visual-BERT, UNITER
- layers collectively operate on a concat of image, text inputs
Dual-stream approaches
- ViLBERT, LXMERT
- modalities not concat at the input level
이 논문에서는 single stream appraoch를 따름. 왜냐면 dual-stream은 extra parameter가 필요함.
Textual Embedding Schema
대부분의 VLP 모델이 pre-trained BERT tokenizer, word and position embedding resembling BERT를 사용하고있음. 그래서 논문에서는 따로 언급하지 않음.
Visual Embedding Schema
대부분의 VLP 모델에서 visual embedding 부분이 bottleneck임. 그 이유는 region/grid feature를 사용함으로 인해서 무거운 extraction module를 사용해야 하기 때문임.
이 논문에서는 region/grid feature를 사용하는게 아닌, patch projection을 도입함으로써 이 부분의 부하를 줄여보려고 함.
Region Feature
기존 VLP 모델은 Faster R-CNN과 같은 obj det 모델을 사용해서 region feature를 뽑아냄.
region feature를 만들어내는 파이프라인은 다음과 같음.
- RPN이 CNN backbone에서 pool된 grid feature를 베이스로 하여 RoI를 뽑아냄
- NMS 적용하여 RoI의 개수를 1000 단위로 줄임.
- RoI Align등의 방식을 이용하여 풀링 후에, RoI head에 RoI를 태우면 region feature가 나온다.
- 다시 모든 클래스에 NMS를 적용하여, region feature의 개수를 100 단위로 줄인다.
이 프로세스에 포함된 backbone, NMS style, RoI head 성능이 VLP 모델의 performance와 runtime에 영향을 준다. 그럼에도 불구하고, 이전 연구들은 이 요소들을 여러가지로 실험해보면서 성능을 비교하는 데에 그친다. 그렇지만 obj det이라는 접근 자체가 아무리 가볍다고 하더라도 backbone이나 single-layer convolution보다는 빠를 수가 없다. visual backbone을 freeze하고, region feature를 미리 캐싱하여 사용하는것만이 training시 속도를 높여주지만, inference시에는 그럴 수가 없기에 결국은 느릴 수 밖에 없다.
Patch Projection
visual embedding의 오버헤드를 줄이기 위해, linear projection이라는 심플한 scheme을 적용한다. linear projection은 image patches에 적용된다.
논문에서는 32x32 patch projection을 사용한다. 자세한건 나중에 설명.
Vision-and-Language Transformer
Model Overview
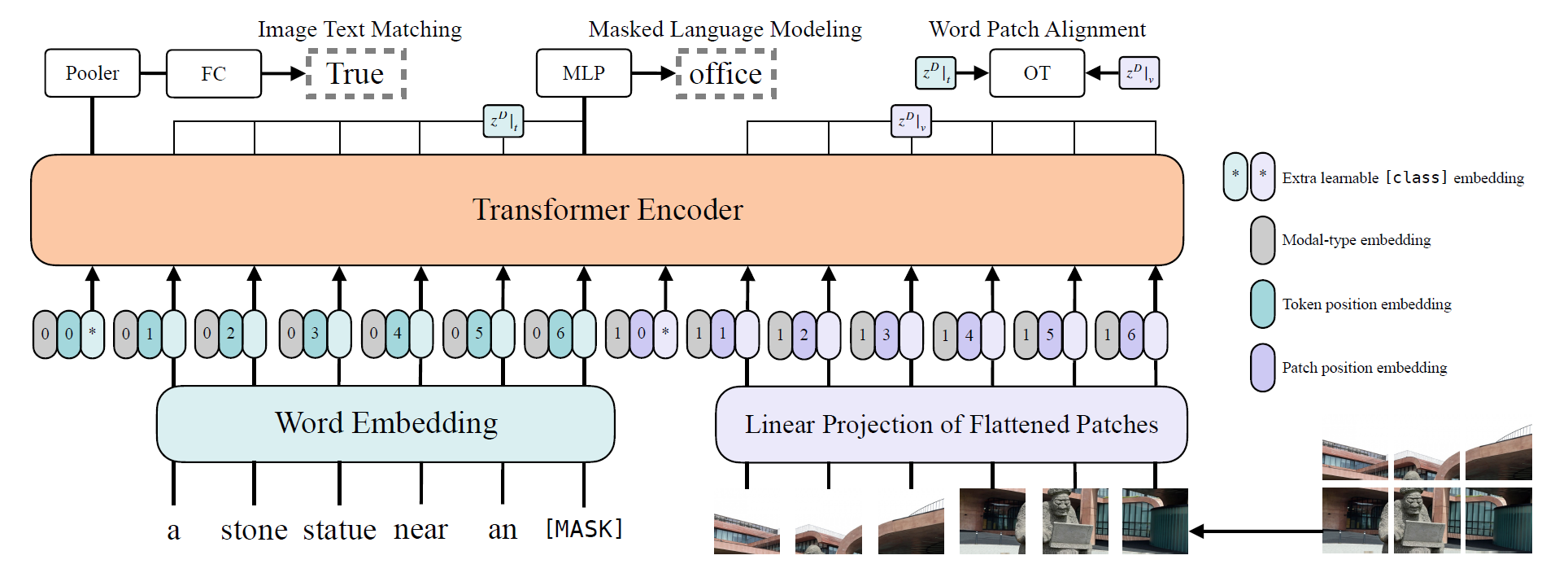
모델 구조는 ViT를 베이스로 하고, pre-trained ViT의 가중치로 초기화한다. 이렇게 초기화하면, 별도의 visual embedder가 없더라도 interaction layer에서의 visual processing 능력을 키울 수 있다고 한다.
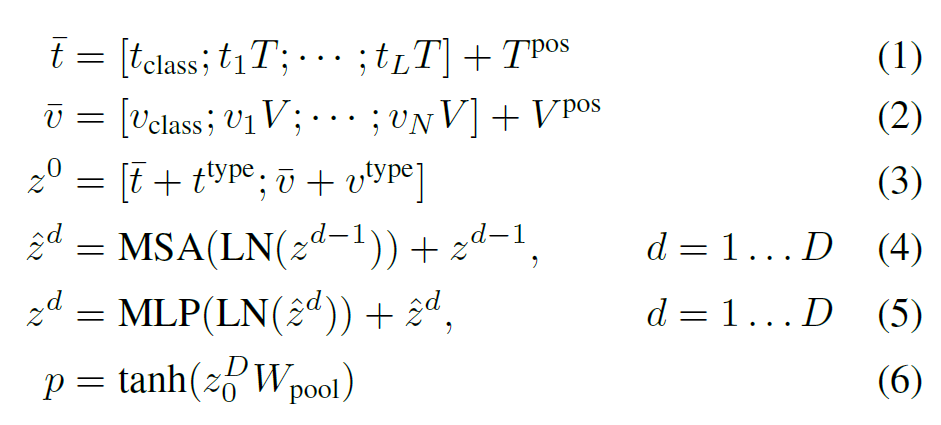
(1) input text가 word embedding matrix 와 position embedding 를 통해 로 임베딩됨.
(2) input image는 patch 단위로 쪼개지고 flatten된 뒤, linear projection 와 position embedding 를 통해 로 임베딩됨.
(3) (1), (2)에 modal-type embedding vector 가 각각 더해지고 concat되어 이라는 combined sequence가 됨.
(4), (5) 벡터는 의 트랜스포머를 거치며 iterative하게 업데이트 됨.
(6) 트랜스포머를 모두 거치고 나온 첫번째 인덱스(개인적인 생각: BERT에서의 [CLS] 토큰의 역할과 유사함. input embeddibg 전체에 대한 정보를 담고 있음)를 linear projection과 tanh를 거쳐 라는 pooled representation을 만든다.
Pre-training Objectives
Image Text Matching
50% 확률로 aligned image를 랜덤하게 다른 이미지로 바꾸고, 텍스트와 매칭되는지를 classify하는 task.
모델 뒤에 single linear layer를 붙이고(=ITM head), output feature 를 이용해 binary하게 분류, logit 값을 뽑아냄. log-likelihood loss 이용해서 학습.
Masked Language Modeling
15% 확률로 text token을 마스킹하고, 마스킹된 text token의 GT label을 predict하는 task.
모델 뒤에 two-layer MLP를 붙이고(=MLM head), contextualized vector 를 입력받아 vocabulary에 대한 logit값을 뽑아냄. log-likelihood loss 이용해서 학습.
Whole Word Masking
15% 확률로 전체 텍스트를 마스킹하는 task.
토큰 일부만 마스킹할 때, 다른 modality의 정보를 활용하는게 아니라 마스킹된 토큰 주변 토큰들의 text context만 활용하는 방향으로 학습된다는 문제점에서 출발. 그래서 텍스트 전체를 마스킹하고, 다른 modality(여기서는 visual)의 정보를 활용하여 예측하도록 함.
Image Augmentation
image augmentation은 vision model의 generalization power를 키운다고 알려져 있음.
여지껏 VLP 모델에는 augmentation의 영향에 대해 연구가 이루어지지 않음. 왜냐면 여태까지는 visual feature를 캐싱해서 사용했어야 했기 때문. 그리고 pixel-BERT는 적용 가능했음에도 불구하고 적용해보지 않았음.
그래서 저자들은 fine-tuning 단계에서 RandAugment를 적용해봄.
단, color inversion과 cutout은 textual information에 포함된 정보를 손상시키거나 없앨 수 있으므로 적용하지 않음.
Conclusion
non-convolutional, lightweight, fast한 VLP architecture인 ViLT 제안
향후 VLP 연구는 unimodal embedder의 성능 향상보다는, modality interaction의 힘을 키우는 데에 집중해야 할 것을 시사함.
