Logstash!!
저번 글에서 AWS를 이용하여 ElasticSearch를 구축하는데 성공하였습니다.이번 글에서는 Logstash와 Kibana 활용법을 알아보고자 합니다.
먼저 Logstash를 위한 EC2를 하나 생성하고 EC2안에서 Docker를 통해서 Logstash를 띄웁니다.
- Docker image Pull
sudo docker pull docker.elastic.co/logstash/logstash-oss:7.10.2
- Docker Run
docker run --name logstash -p 5000:5000 -p 5044:5044 -d -e LS_JAVA_OPTS="-Xms512M -Xmx512M -XX:ParallelGCThreads=1" -v ~/pipeline/:/usr/share/logstash/pipeline/ docker.elastic.co/logstash/logstash-oss:7.10.2
위의 Docker 명령어를 통해 Logstash를 EC2환경에 띄우는데는 성공했습니다.
이제 우리는 kafka의 Consumer로써 Logstash를 활용해야하기에 pipeline template를 작성해 Logstash가 데이터들을 수집할 수 있게 만들어야합니다.
- Pipeline folder로 접속
cd pipeline
- logstash.conf 파일 작성
input { kafka { bootstrap_servers => ["Kafka End Point"] topics => ["토픽 이름"] consumer_threads => 1 } } filter{ json { source => "message" } } output { elasticsearch { hosts => ["ElasticSearch 엔드 포인트 및 URL 주소"] workers => 1 index => "토픽 이름" user => "생성시 설정한 유저이름" password => "생성시 설정한 비밀번호" ilm_enabled => false } }위의 conf 파일을 한 번 분석하고 넘어가겠습니다. 저번에 Logstash를 정리하던 글에서 봤던 pipeline template와 일치하는 형식인 것을 알 수 있습니다.
- input은 kafka 한테 정보를 읽어오기에 kafka plugin을 활용하여 작성합니다. 그리고 구독할 토픽과 kafka 서버의 url과 스레드 등을 설정합니다.
- filter는 json을 활용해 데이터를 가공합니다.
- output은 ES에 저장하고 활용할 것이기 때문에 ES로 설정을 진행합니다.
이제 Logstash를 사용할 수 있는 모든 설정을 마쳤습니다. 그러면 제대로 동작하는지 알아야하기에 Kafka를 통해 메세지를 하나 생성해 보고 아래의 명령어를 통해 확인해 봅니다.
docker logs -f imageId
제대로 동작한다면 아래와 같은 log를 볼 수 있습니다.
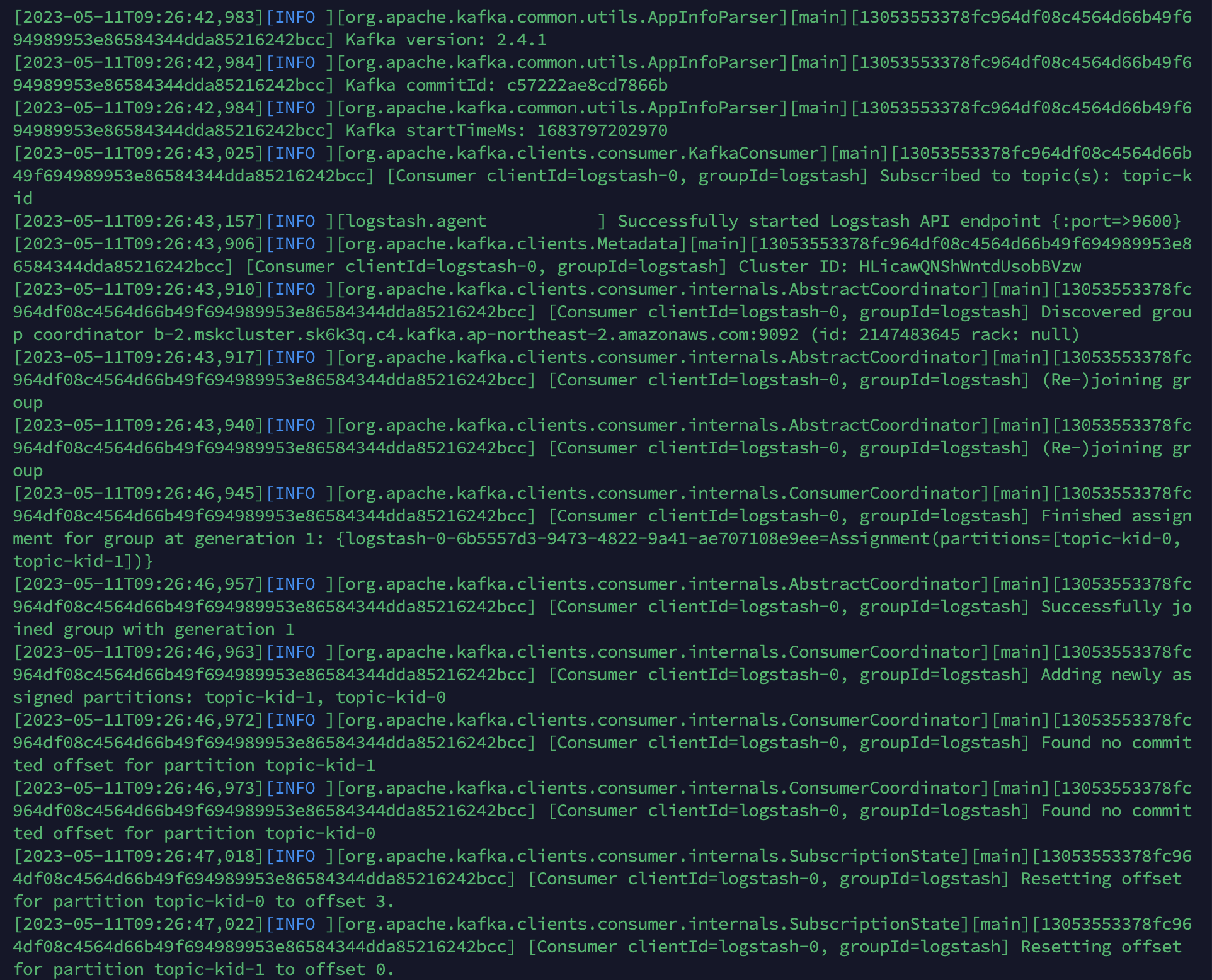
Kibana!!
Kibana 접속 URL은 AWS ElasticSearch 클러스터를 들어가보면 확인 할 수 있습니다.
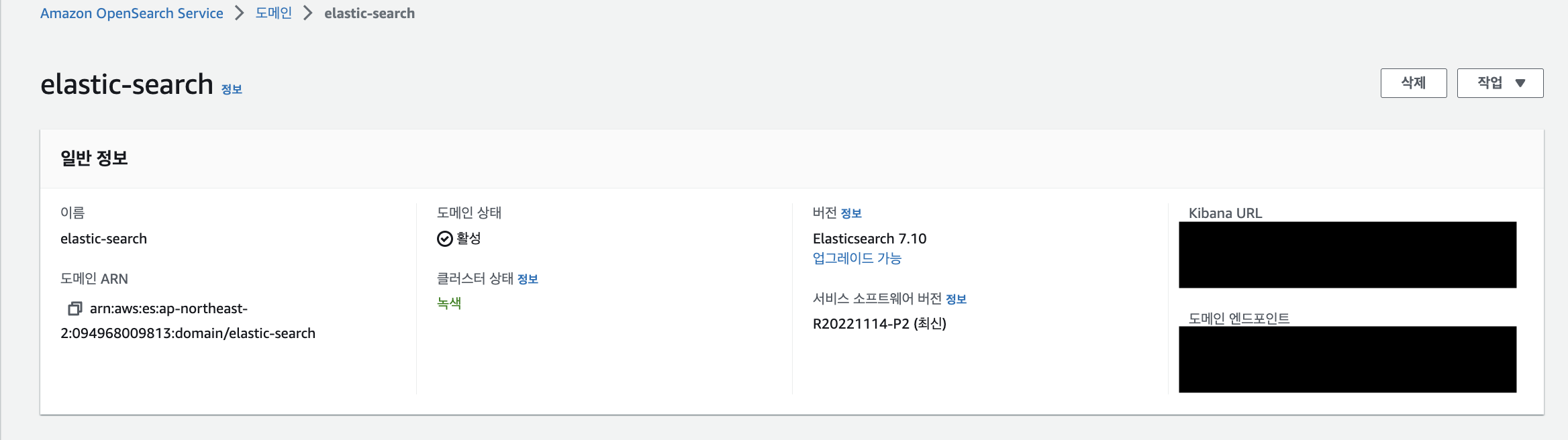
- URL을 접속하면 ID와 비밀번호를 쳐서 접속을 합니다. 그러면 아래와 같은 페이지가 보이실 겁니다.
- 그 다음 왼쪽 상단의 햄버거 바를 클릭하여 Management에서 stack management로 이동합니다.
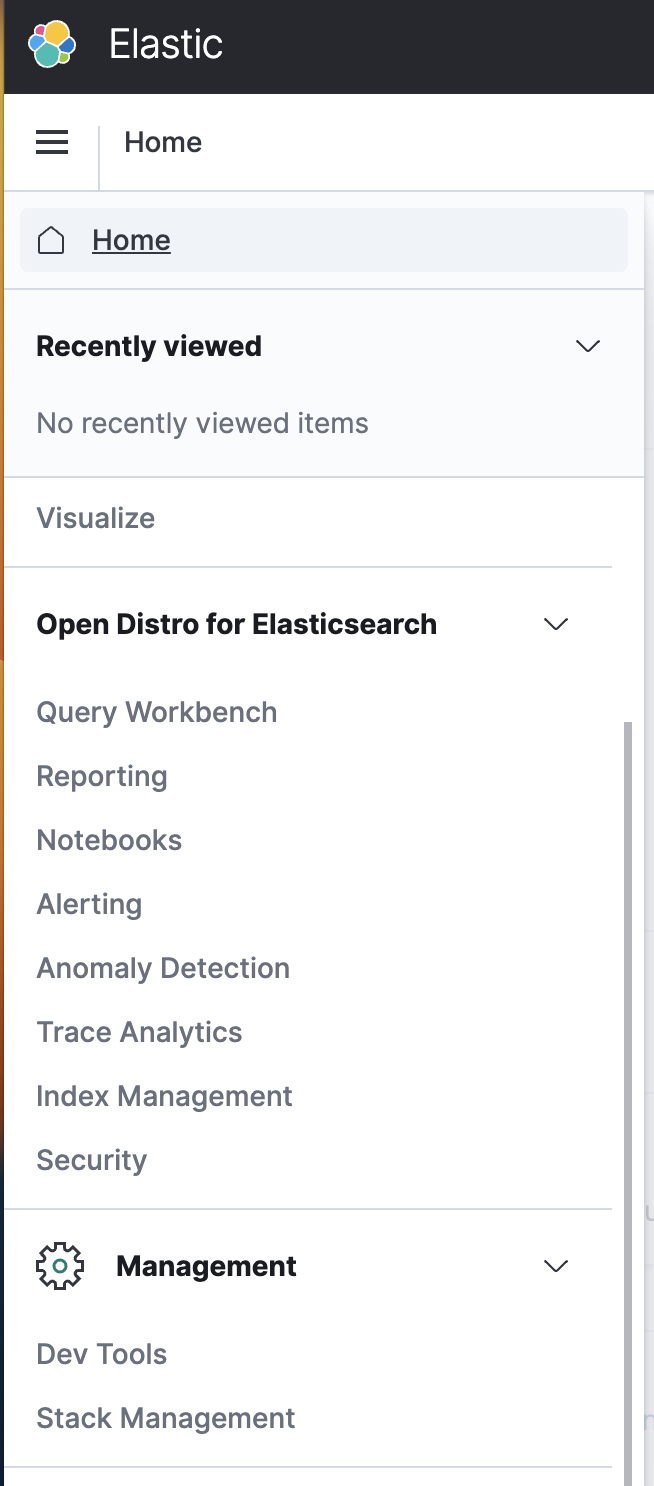
- 들어가셔서 Index patterns에서 Create IndexPattern으로 이동합니다.
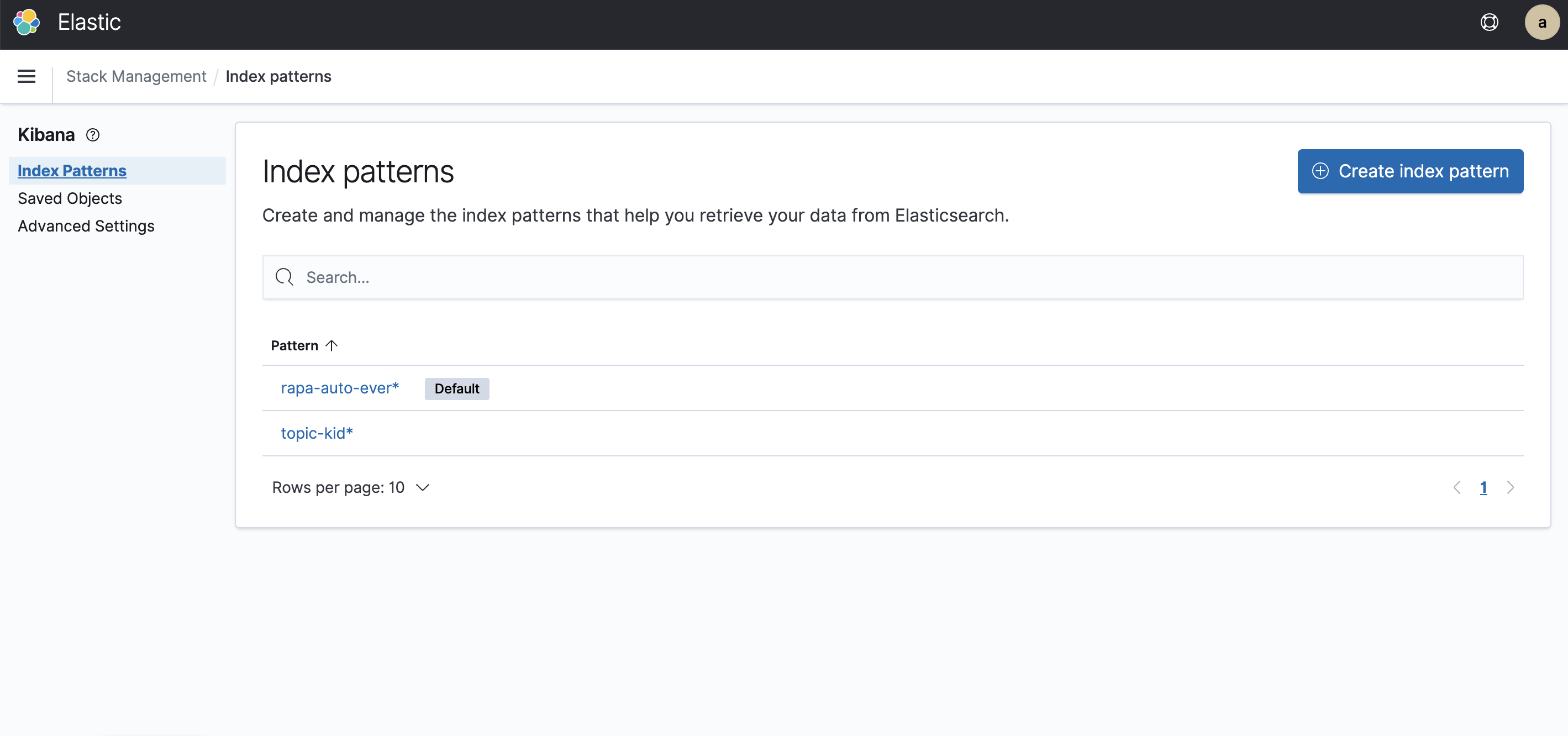
- 이제 Logstash.conf에서 설정한 index 네임으로 pattern을 생성합니다. 그 후 Discover로 이동해보면 ElasticSearch에 kafka에서 보낸 메세지가 제대로 저장되었는지 확인 할 수 있습니다.
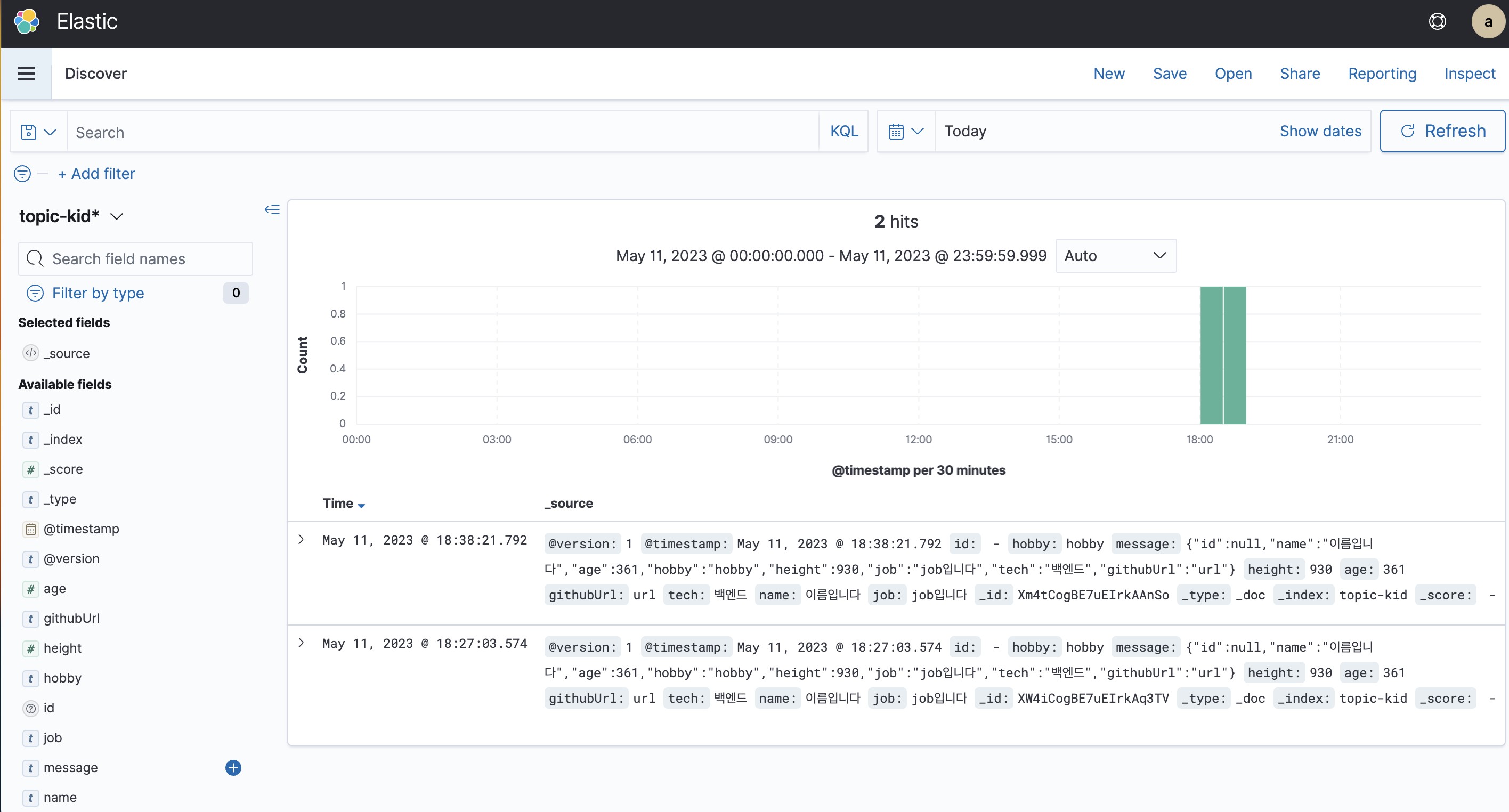
글을 마무리 지으며
이번 글은 ELK에서 Logstash와 Kibana를 어떻게 활용하고 구축하는지에 대해 알아 봤습니다!! 다음 글에서는 이제 Reading Server를 띄워 ElasticSearch에 대한 내용을 읽어오는 과정 전체를 보여드리고자 합니다!!!

성장하는것을 제일 즐깁니다.