
Iris(붓꽃) 종류 예측 모델
2일차로는 붓꽃 종류 예측하는 모델링을 진행했다. 어제와 다른 점이 있다면 어제는 의료보험료를 예측하는 회귀형(수치형) 모델로 값을 예측했다면, 오늘은 분류형으로 어떤 분류를 갖고 있는지 예측했다.
전날에는 데이터 크기가 컸는데 이번에는 200개가 안되는 데이터고, 컬럼도 많지 않았다. 다른 해야 할 것도 많기도 해서 쉬어가는 느낌으로 했다.
https://www.kaggle.com/datasets/uciml/iris
데이터는 이번에도 마찬가지로 캐글에서 찾아서 진행했다. 데이터를 찾을 때는 주로 Chat GPT로 들어가서 데이터를 추천해달라고 한다. 이번에는 그렇게 좋은 추천을 받은 거 같지 않다.
컬럼
컬럼 종류는 총 6가지 종류다.
ID, 꽃받침 길이, 꽃받침 폭, 꽃잎 길이, 꽃잎 폭, 종류
이렇게 나뉜다. 나는 ID와 종류를 제외한 4가지 컬럼의 데이터를 가지고 종류가 어떤 종류를 가질 지 예측하는 AI모델을 만들었다.
종류
여기서 Iris의 종은 3가지로 나뉜다.
setosa / versicolor / virginica
앞 서 말한 컬럼의 데이터를 파악해서 위의 3종 중 어떤 종의 Iris인지 예측할 것이다.
시작
데이터 파악
가장 처음에는 어떤 데이터를 갖고 있는지 파악하는 것이 우선이다.
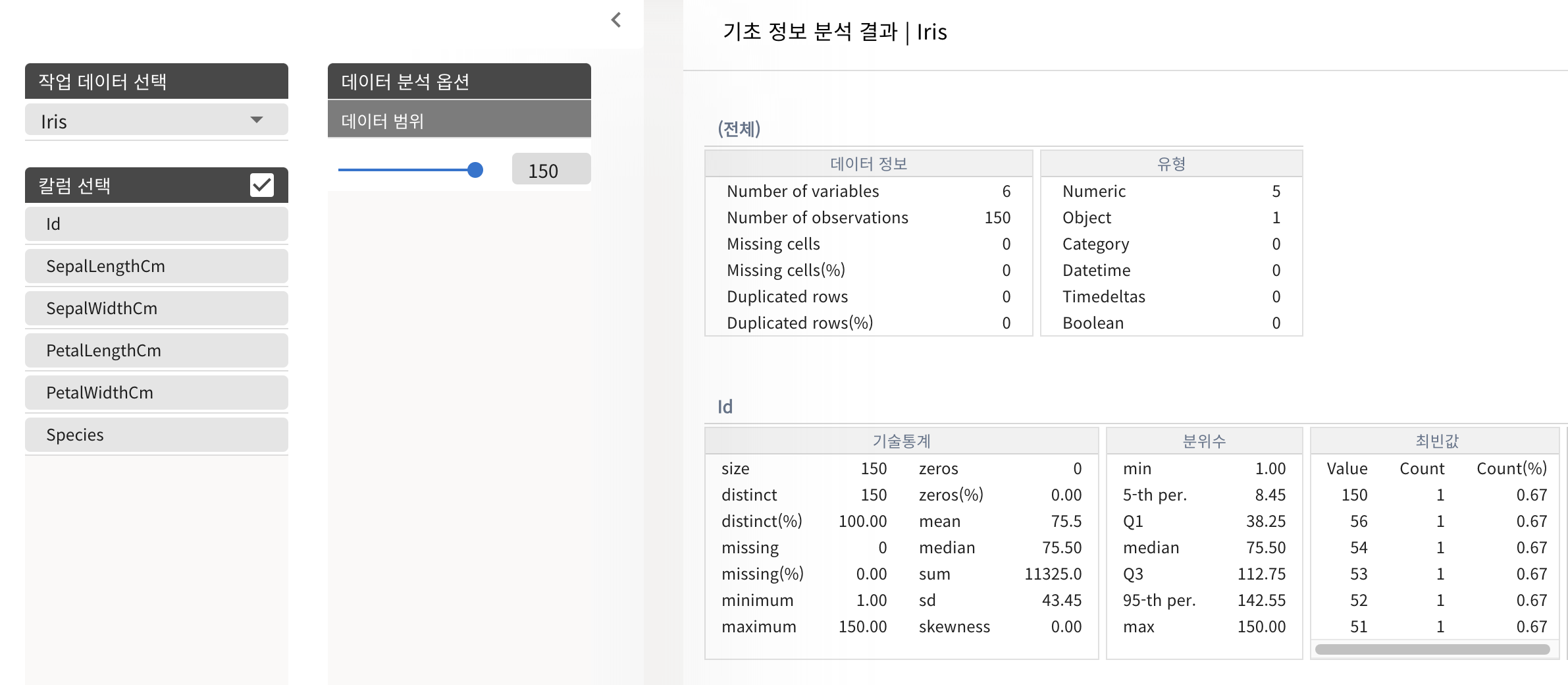
총 150개의 데이터를 갖고 있고 결측치는 존재하지 않는다. 시각화를 통해 박스차트를 진행했을 때에도 이상치는 존재하지 않았다. 그렇기 때문에 따로 데이터 가공을 할 필요가 없는 정제된 데이터이다.
하지만, 데이터의 크기가 너무 작기 때문에 좋은 데이터라 할 수는 없다고 생각한다.
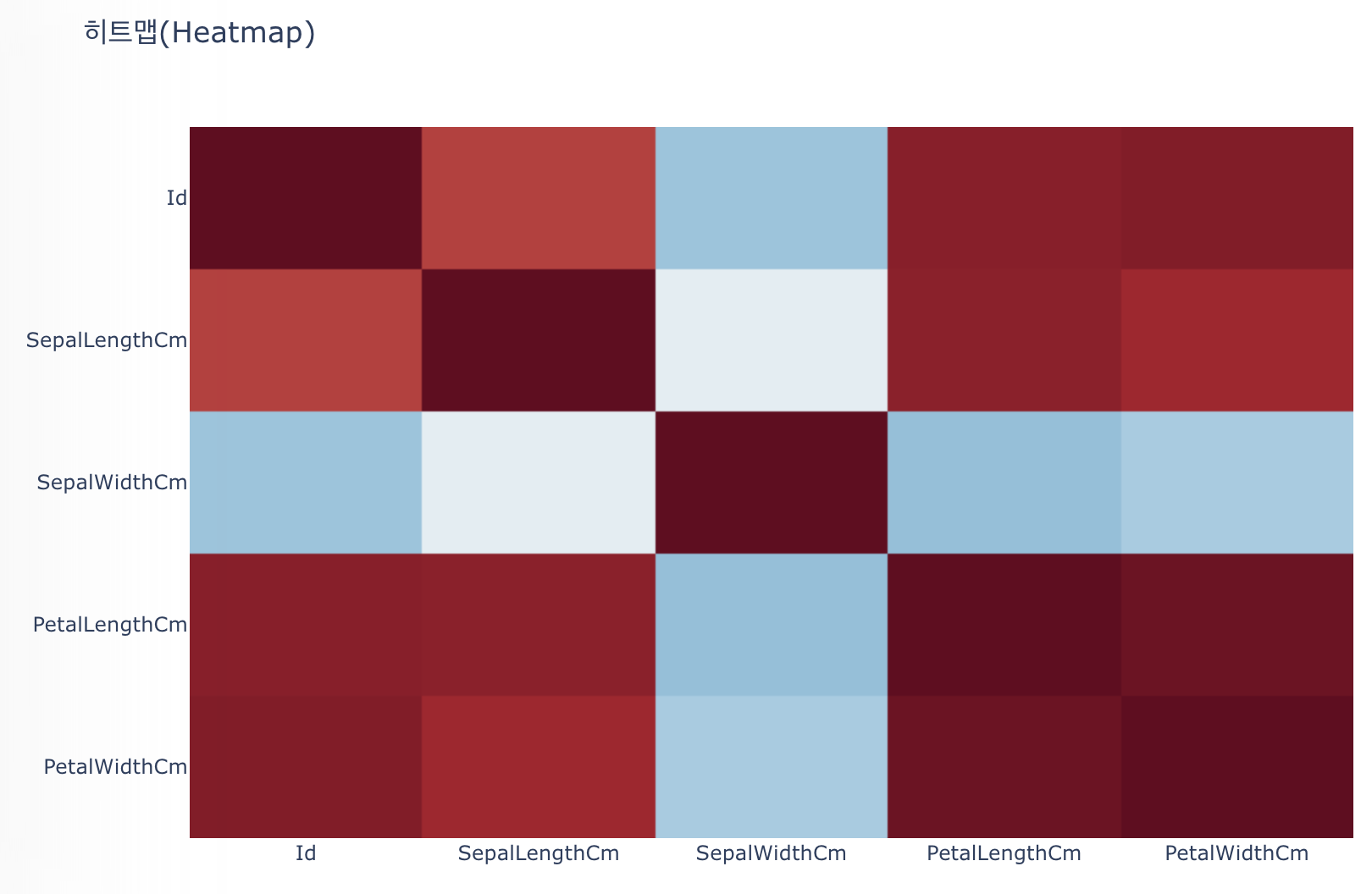
히트맵을 통해 컬럼 간의 상관관계를 보았다. 컬럼끼리 대부분 양의 관계를 갖고 있지만, 꽃받침 폭만이 다른 컬럼과의 음의 관계를 갖고 있다. 꽃잎과 꽃받침은 서로 반비례한다는 것을 알 수 있다.
AI 모델링
Iris의 종류를 예측하는 AI를 만들려고 한다.
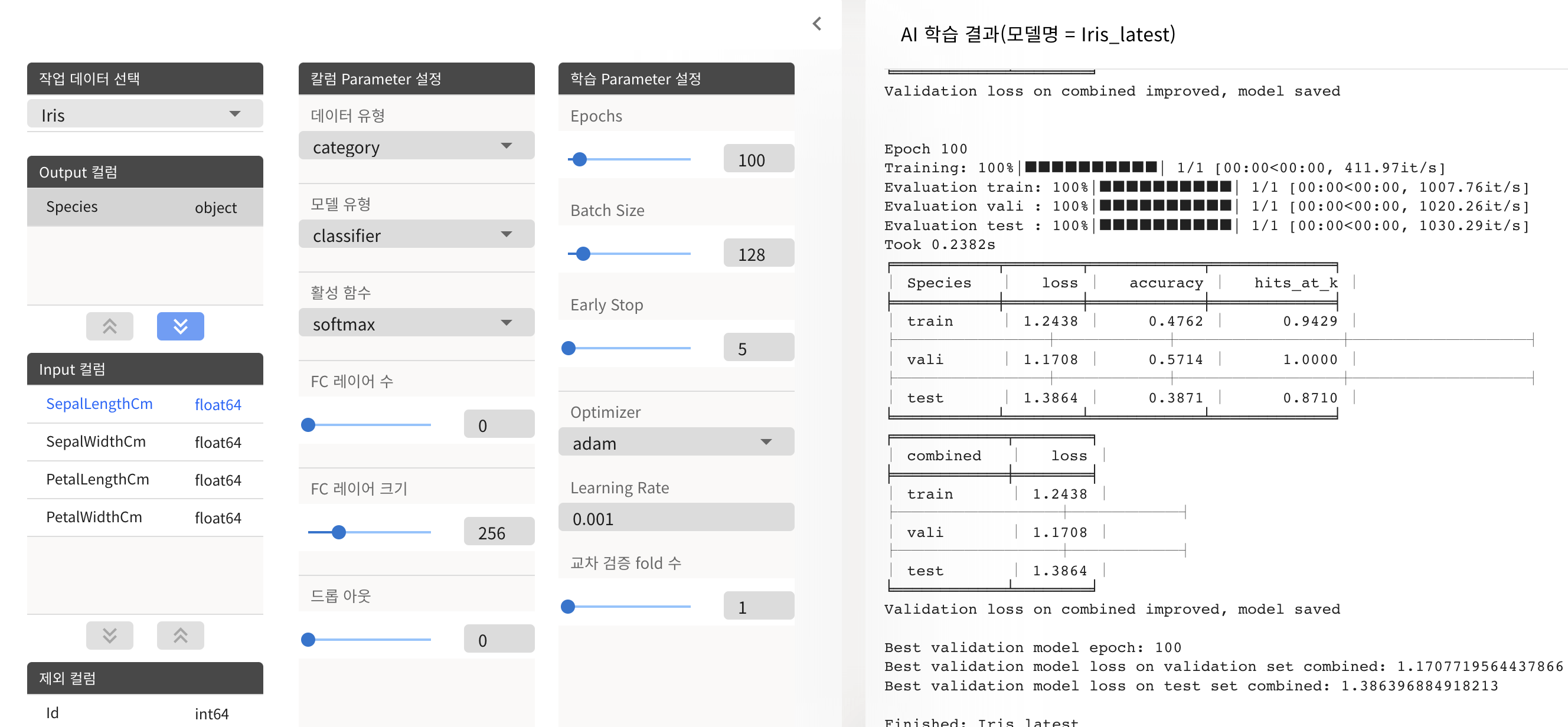
그렇기 때문에 Output의 데이터 유형을 카테고리로 설정하고, 활성 함수를 softmax로 했다. 이렇게 설정하고 실시한 결과 epoch가 문제 없이 100회를 수행했다.
AI 활용
이렇게 나온 결과로 데이터를 활용하면 다음과 같다.
1. 변수 영향도 파악
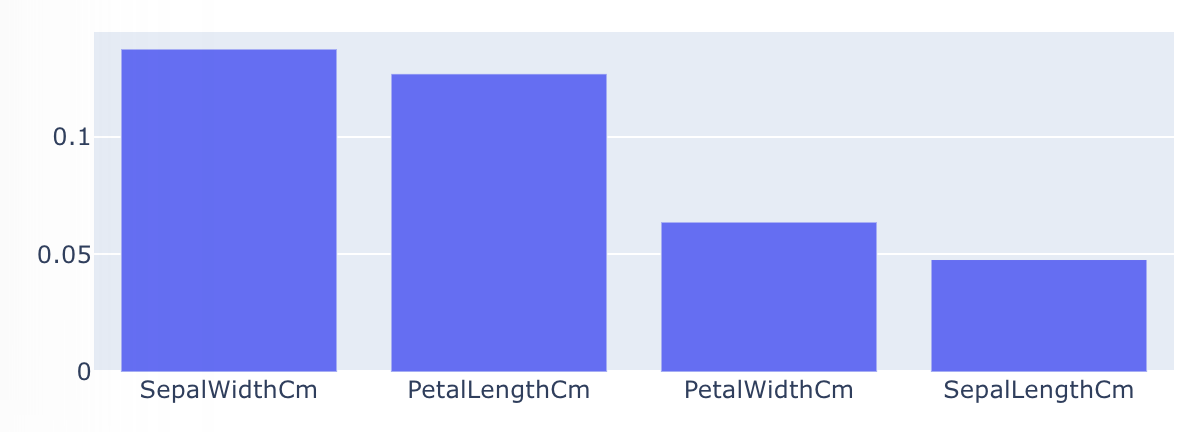
종류에 따른 변수 영향도 파악의 결과이다. 꽃받침 폭과 꽃잎의 길이가 가장 큰 영향도를 갖고 있다.
2. 예측하기

기존의 갖고 있던 데이터로 테스트한 결과 ID마다 갖고 있는 데이터로 종류를 유추할 수 있었다.
정리하기
더욱 다양한 데이터로 공부하자💪
이번에는 데이터가 부실한 점도 있지만, 너무 널리 알려진 부분이었다. 그래서 예측하기 쉬웠다. 아직 비기너라고는 하지만 성장시키기에는 아쉬웠다. AIDU ez를 잊지 않고 익히고 있다는 것에 도움을 준 오늘이라 생각해야겠다.

음악을 좋아하는 사람이 음악을 만들 듯, 개발을 좋아하게 될 사람이 쓰는 개발이야기