
태그 목록
- 전체보기(64)
- 99클럽(21)
- 코딩테스트준비(21)
- TIL(21)
- 개발자취업(21)
- 항해99(21)
- baekjoon(10)
- Spring(6)
- Spring boot(4)
- aop(3)
- http(3)
- 로그인(2)
- JWT(2)
- JPA(2)
- XSS(2)
- oauth2(2)
- IntelliJ(2)
- lucy-xss-servlet-filter(2)
- servlet(1)
- Java(1)
- algorithm(1)
- kotlin(1)
- session(1)
- lucy-xss-filter(1)
- 클린아키텍처(1)
- OOP(1)
- summernote(1)
- redis(1)
- 알고리즘(1)
- H2(1)
- network(1)
- 스터디(1)
- error(1)
- log4jdbc(1)
- dbeaver(1)
- Design Pattern(1)
- DevTools(1)
- log(1)
전체보기 (64)99클럽(21)코딩테스트준비(21)TIL(21)개발자취업(21)항해99(21)baekjoon(10)Spring(6)Spring boot(4)aop(3)http(3)로그인(2)JWT(2)JPA(2)XSS(2)oauth2(2)IntelliJ(2)lucy-xss-servlet-filter(2)servlet(1)Java(1)algorithm(1)kotlin(1)session(1)lucy-xss-filter(1)클린아키텍처(1)OOP(1)summernote(1)redis(1)알고리즘(1)H2(1)network(1)스터디(1)error(1)log4jdbc(1)dbeaver(1)Design Pattern(1)DevTools(1)log(1)
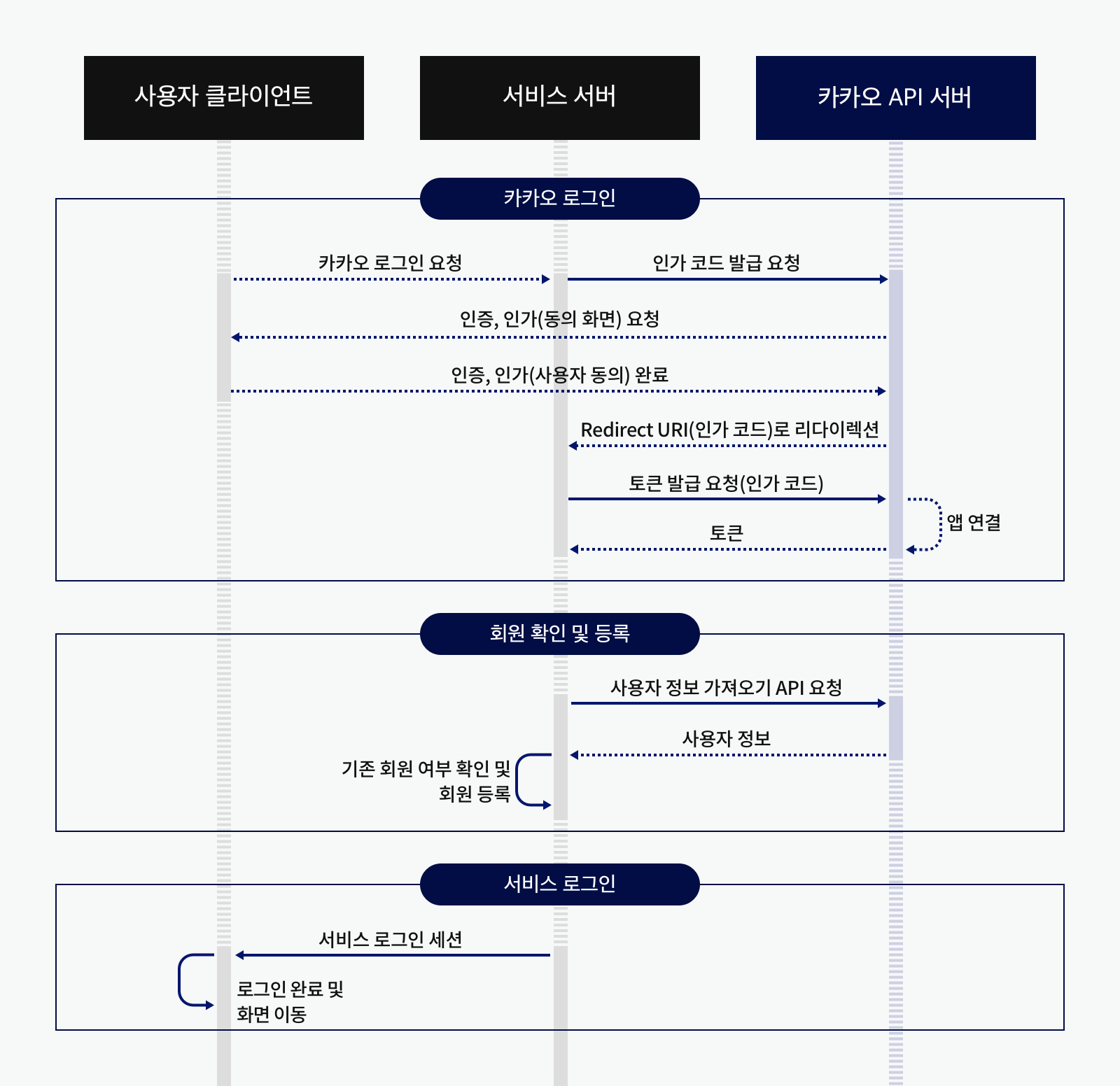
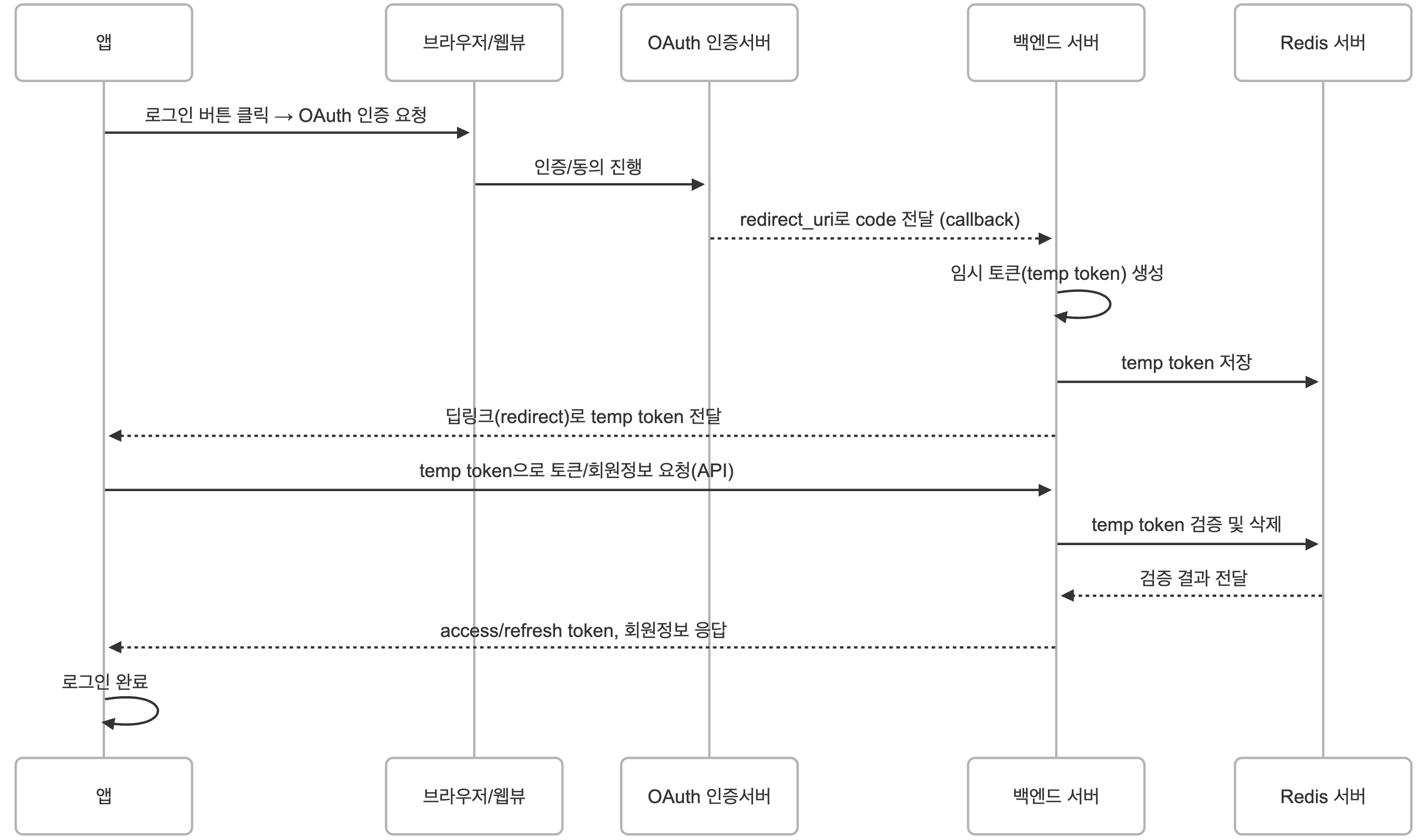
[Spring Boot] OAuth2 + JWT + Redis 기반 로그인 구현
OAuth 인증 후 모바일 앱에서 안전하게 사용자 식별 정보를 받아 JWT로 최종 로그인 처리
2025년 4월 28일
·
0개의 댓글·
0


[99클럽 코테 스터디 19일차 TIL] Greedy
문제 문제 설명 과일 장수가 사과 상자를 포장하고 있습니다. 사과는 상태에 따라 1점부터 k점까지의 점수로 분류하며, k점이 최상품의 사과이고 1점이 최하품의 사과입니다. 사과 한 상자의 가격은 다음과 같이 결정됩니다. 한 상자에 사과를 m개씩 담아 포장합니다.
2024년 8월 9일
·
0개의 댓글·
0


[99클럽 코테 스터디 16일차 TIL] 완전탐색
문제 문제 설명 명함 지갑을 만드는 회사에서 지갑의 크기를 정하려고 합니다. 다양한 모양과 크기의 명함들을 모두 수납할 수 있으면서, 작아서 들고 다니기 편한 지갑을 만들어야 합니다. 이러한 요건을 만족하는 지갑을 만들기 위해 디자인팀은 모든 명함의 가로 길이와 세로 길이를 조사했습니다. 아래 표는 4가지 명함의 가로 길이와 세로 길이를 나타냅니다. ...
2024년 8월 6일
·
0개의 댓글·
0










