Seq2Seq
시퀀스-투-시퀀스(Sequence-to-Sequence)는 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에서 사용되는 모델이다. 예를 들어 챗봇(Chatbot)과 기계 번역(Machine Translation)이 그러한 대표적인 예인데, 입력 시퀀스와 출력 시퀀스를 각각 질문과 대답으로 구성하면 챗봇으로 만들 수 있고, 입력 시퀀스와 출력 시퀀스를 각각 입력 문장과 번역 문장으로 만들면 번역기로 만들 수 있다. 그 외에도 내용 요약(Text Summarization), STT(Speech to Text) 등에서 쓰인다.
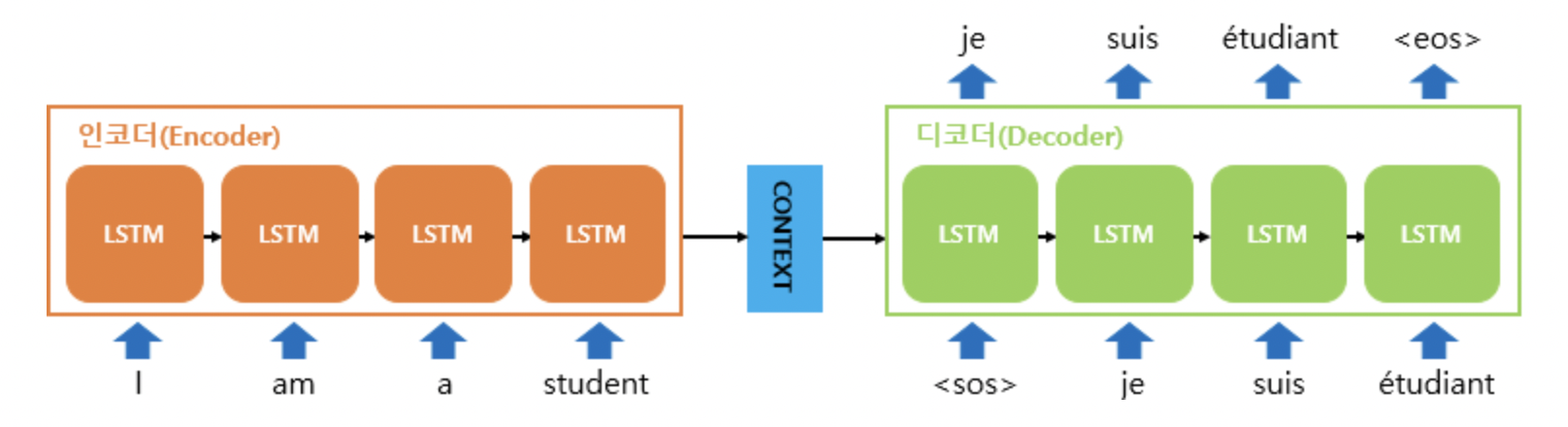
Seq2Seq 논문
Seq2Seq의 기본적인 구조는 위 그림과 같다. RNN계열 중 Many-to-One과 One-to-Many의 구조가 결합된 형태로 볼 수 있다. LSTM으로 구성된(RNN계열) Encoder를 지나 Sequence데이터는 최종 Hidden State를 출력하는데, 이를 우리는 문장의 문맥 정보를 담고 있다고해서 Context Vector라고 부른다.
이 Context Vector는 Decoder의 첫 번째 시점의 input SOS(Start of Sequnce)와 Concatenate되어 입력으로 들어가게 되고, EOS(End of Sequence)가 나올 때까지 각 시점마다 출력값을 통해 우리는 어떠한 일련의 시퀀스 데이터를 출력하게 된다.
이 방식은 Context vector의 Dimension이 제한적이여서 결국 Input Data의 크기가 커지면 정보를 잘 나타내지 못한다는 단점이 있었다. 또한 RNN계열을 사용했기에 여전히 기울기 소실/증폭 문제가 남아있었다.
이 문제를 해결하기 위해 도입된 Attention이라는 개념에 대해서 알아보자.
Attention
어텐션의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점(time step)마다 인코더에서의 전체 입력 문장을 다시 한 번 참고한다는 점이다. 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보게 된다.
이 때, Query, Key, Value 라는 것이 등장하게 된다.
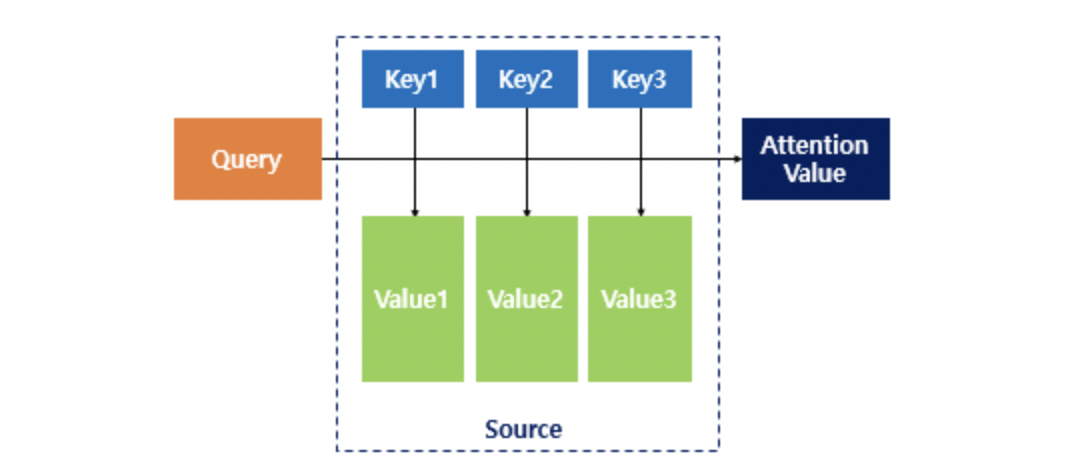
각각의 의미는 다음과 같다.
Query : t 시점의 디코더 셀에서의 은닉 상태,
Keys : 모든 시점의 인코더 셀의 은닉 상태들,
Values : 모든 시점의 인코더 셀의 은닉 상태들
Attention을 포함한 Seq2Seq의 진행과정은 다음과 같다.
-
Attention Score
먼저 처음 Encoder에서 입력값이 들어온다. RNN계열을 거치면서 각 시점에서의 Hidden State와 마지막 출력값 Hidden State(Query)를 포함한 Fully Connected Layer를 거쳐서 나온 값들을 Attention Score라고 한다. 이는 나중에 Decoder에 입력이 들어가는 시점에, 첫 시점의 Decoder의 출력을 다시 Query로 받아 decoder를 진행하게 된다.참고로 여기서 FC단계에서는 여러가지 방법이 있다. 대표적으로는 Dot product를 사용하는 Luong 방법이 있고, Concatenation을 사용하는 Bahdanau 방법이 있다.
-
Softmax(Attention Distribution)
위의 과정에서 나온 Attention Score들을 Softmax를 통해 확률값으로 나타낸다. 이를 해석하면, decoder로부터 전해받은 Query를 통해 특정 Hidden state에 가중치를 둬서 좀 더 관심(Attention)을 주겠다는 의미이다. 여기까지의 진행을 도식화하면 다음과 같다.
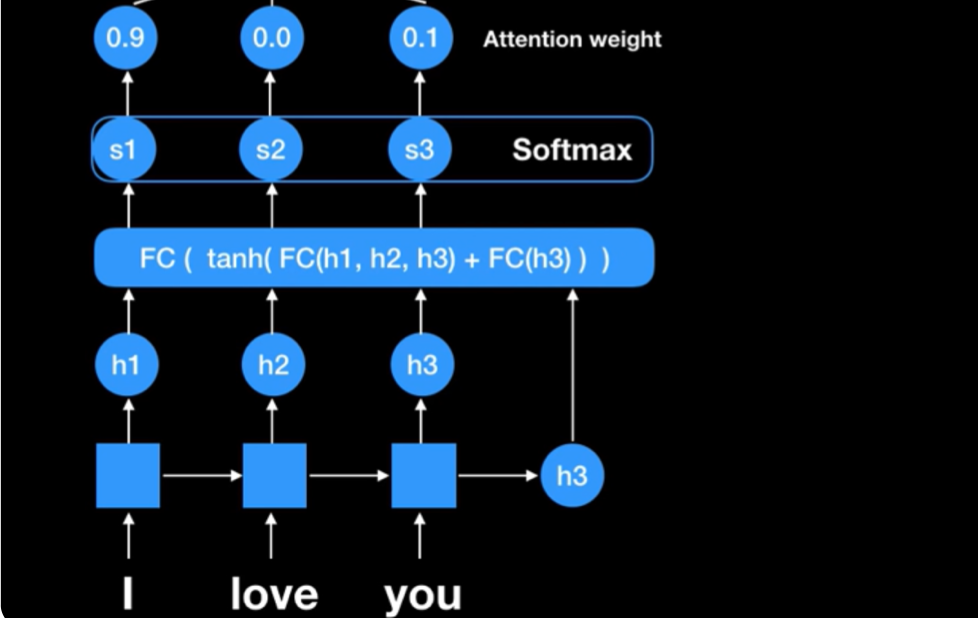
-
Attention Value
softmax로 나온 값들과 value들을 각각 곱해줘서 해당하는 Attention Value를 구하게된다. 그리고 이 값은 현재 시점의 Decoder로 들어간다. -
Concatenate
Decoder의 hidden state와 Attention value를 Concatenate하여 decoder에게 전달하게 되고, 이는 다음에 올 단어를 예측하게 될 것이다.
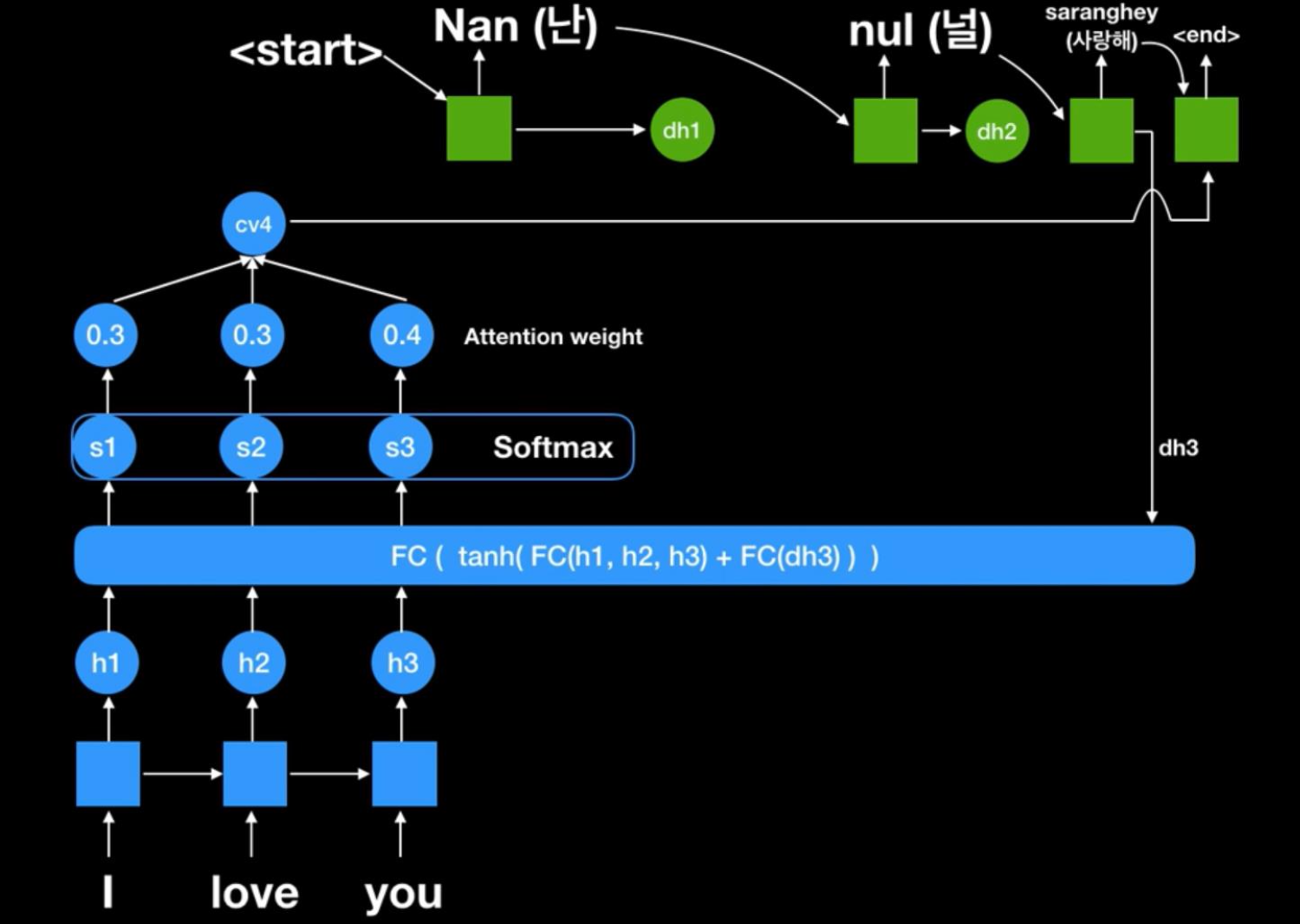
-
Additional Activation Function
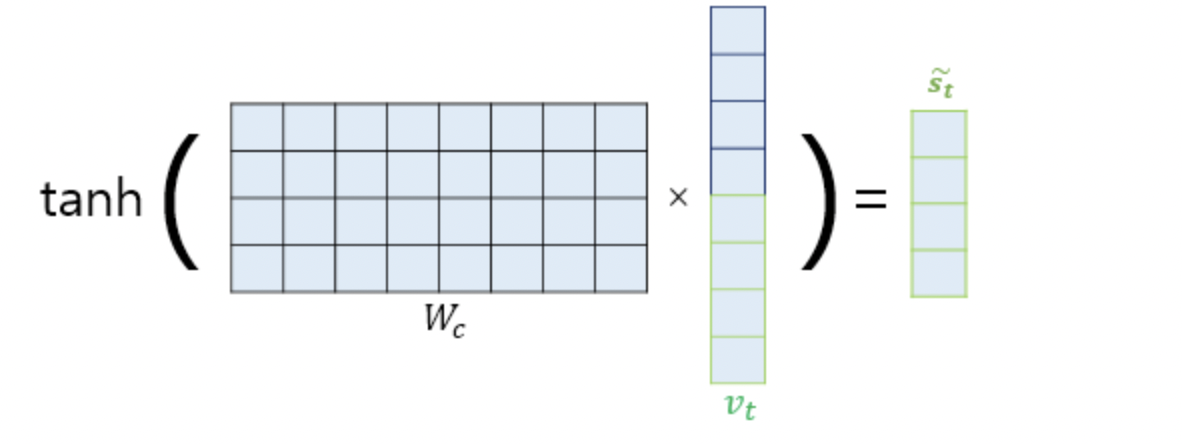
추가적으로 논문에서는 위의 Concatenate한 벡터를 그대로 사용하지 않고 다시 Layer를 거쳐 tanh를 씌워준 형태로 변환하여 decoder에 입력하고 있다.
Self-Attention
이제 트랜스포머에서 활용되는 Self-Attention에 대해서 알아보자. 기존의 seq2seq 모델은 인코더-디코더 구조로 구성되어, 인코더는 입력 시퀀스를 하나의 벡터 표현으로 압축하고, 디코더는 이 벡터 표현을 통해서 출력 시퀀스를 만들어냈다. 여기서 입력 시퀀스의 정보가 일부 손실된다는 단점이 있었고, 이를 보정하기 위해 어텐션이 사용되었다. 그런데 어텐션을 RNN의 보정을 위한 용도가 아니라 아예 어텐션으로 인코더와 디코더를 만들어보면 어떨까?
위에서 봤던 어텐션 함수는 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와의 유사도를 각각 구한다. 그리고 구해낸 이 유사도를 가중치로 하여 키와 맵핑되어있는 각각의 '값(Value)'에 반영해줍니다. 그리고 유사도가 반영된 '값(Value)'을 모두 가중합하여 리턴한다.
기존에는 디코더 셀의 은닉 상태가 Q이고 인코더 셀의 은닉 상태가 K라는 점에서 Q와 K가 서로 다른 값을 가지고 있었다. 하지만 Self-Attention에서는 Q, K, V가 전부 동일하다. 트랜스포머의 셀프 어텐션에서의 Q, K, V는 아래와 같다.
Q : 입력 문장의 모든 단어 벡터들
K : 입력 문장의 모든 단어 벡터들
V : 입력 문장의 모든 단어 벡터들
위와 같이 나눠주어 기존에는 Decoder가 해석하기에 적합한 Attention을 출력했다면, input값인 자기 자신을 가장 잘 해석하도록 만들어주는 것이다.
Query, Key, Value
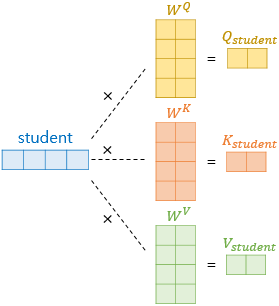
Self-Attention에서는 기존의 의 차원 수가 512라면, 64차원의 저차원 Q,K,V를 생성해낸다. Q,K,V의 dim 수는 나중에 Multi Head Attention에서 다루겠지만 입력 데이터의 차원 수 512를 로 나눠준 값으로 결정한다. 따라서, 입력 데이터에 512X64의 가중치 행렬을 곱해주는 것으로 생각하면 된다.
Attention Value
위와 같이 구한 Q,K,V에 대해서 앞서 Attention의 메커니즘과 똑같이 Attention Score, Weight과 Values를 곱해주어 결과를 도출한다. 트랜스포머에서는 Attention Score를 구할 때 Scaled Dot-Product Attention을 사용한다.
이전에는 Hidden State를 Key로 하여 dot-product를 진행했다. 그러나 Self-Attention은 RNN을 삭제한 상태이기 때문에 여기서는 각 input 단어들을 Key로 하여 진행한다.
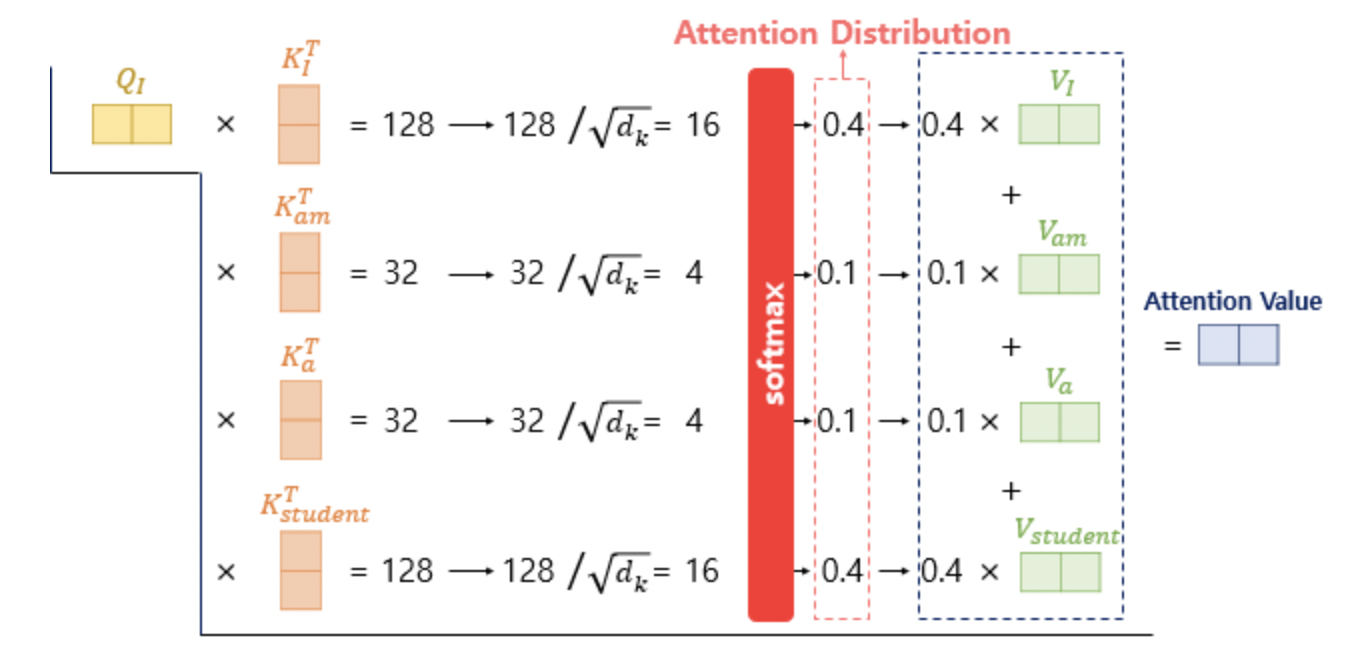
어떤 단어 의 Query값과 다른 Input 단어들의 Key값을 기준으로 dot -product를 진행하고, 로 Scaling을 해주는 작업을 거친다. 나온 결과값에 대하여 Softmax함수를 취해준 뒤 각 단어의 Value vector를 곱해줘서 Attention Value가 나오게 된다.
위의 과정은 각 단어들에 대한 행렬들의 곱으로 한 번에 정리할 수 있다. 다시 말하면, 주어진 문장에 대해서 바로 Qs, Ks, Vs의 행렬을 만들어내는 것이다.
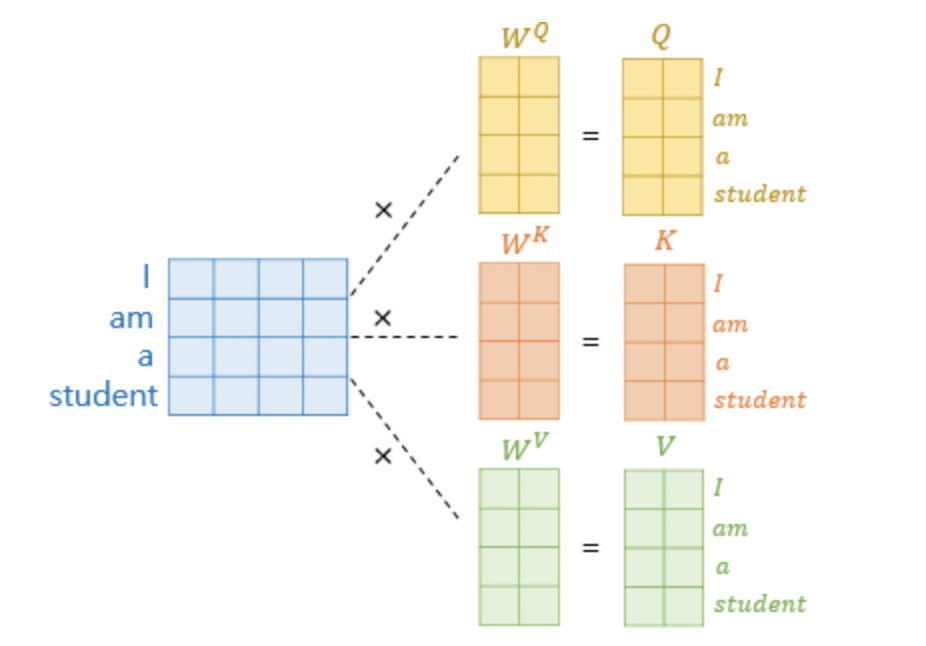
그리고 나서 scaling된 값의 Softmax함수 결과에 대해 Value 행렬을 곱해서 Attention Value Matrix를 만들어내게 된다.
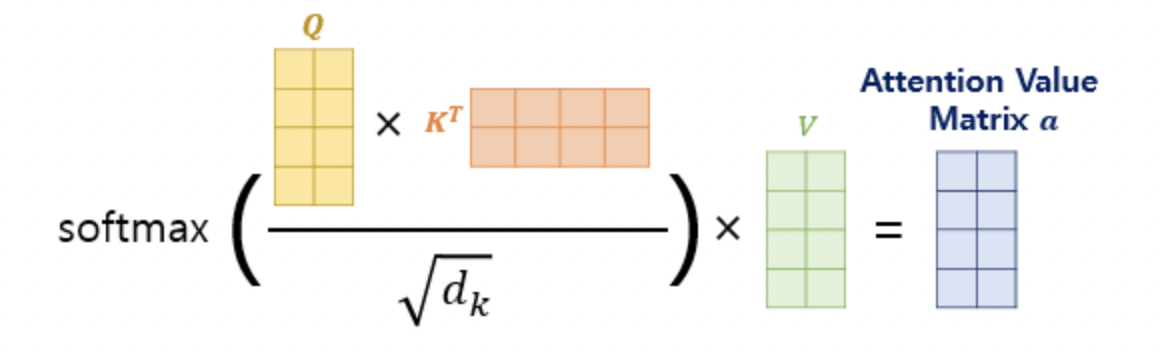
우리는 이를
라고 간단하게 만들 수 있다.
Multi Head Attention
Transformer에는 Self-Attention을 여러개 이어붙인 형태의 Multi Head Attention을 실시한다. 앞에서 말했듯, 현재 데이터의 dim인 을 인 값으로 나눠줘서 Self-Attention을 각각 실시하는 형태이다. 이를 그림으로 표현하면 아래와 같다.

Multi Head (Self-)Attention의 이유
(딥 러닝을 이용한 자연어 처리 입문 中 )
...
트랜스포머 연구진은 한 번의 어텐션을 하는 것보다 여러번의 어텐션을 병렬로 사용하는 것이 더 효과적이라고 판단하였습니다. 그래서 의 차원을 개로 나누어 의 차원을 가지는 Q, K, V에 대해서 개의 병렬 어텐션을 수행합니다. 논문에서는 하이퍼파라미터인 의 값을 8로 지정하였고, 8개의 병렬 어텐션이 이루어지게 됩니다. 다시 말해 위에서 설명한 어텐션이 8개로 병렬로 이루어지게 되는데, 이때 각각의 어텐션 값 행렬을 어텐션 헤드라고 부릅니다. 이때 가중치 행렬
의 값은 8개의 어텐션 헤드마다 전부 다릅니다.병렬 어텐션으로 얻을 수 있는 효과는 무엇일까요? 그리스로마신화에는 머리가 여러 개인 괴물 히드라나 케로베로스가 나옵니다. 이 괴물들의 특징은 머리가 여러 개이기 때문에 여러 시점에서 상대방을 볼 수 있다는 겁니다. 이렇게 되면 시각에서 놓치는 게 별로 없을테니까 이런 괴물들에게 기습을 하는 것이 굉장히 힘이 들겁니다. 멀티 헤드 어텐션도 똑같습니다. 어텐션을 병렬로 수행하여 다른 시각으로 정보들을 수집하겠다는 겁니다.
예를 들어보겠습니다. 앞서 사용한 예문 '그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다.'를 상기해봅시다. 단어 그것(it)이 쿼리였다고 해봅시다. 즉, it에 대한 Q벡터로부터 다른 단어와의 연관도를 구하였을 때 첫번째 어텐션 헤드는 '그것(it)'과 '동물(animal)'의 연관도를 높게 본다면, 두번째 어텐션 헤드는 '그것(it)'과 '피곤하였기 때문이다(tired)'의 연관도를 높게 볼 수 있습니다. 각 어텐션 헤드는 전부 다른 시각에서 보고있기 때문입니다.
...
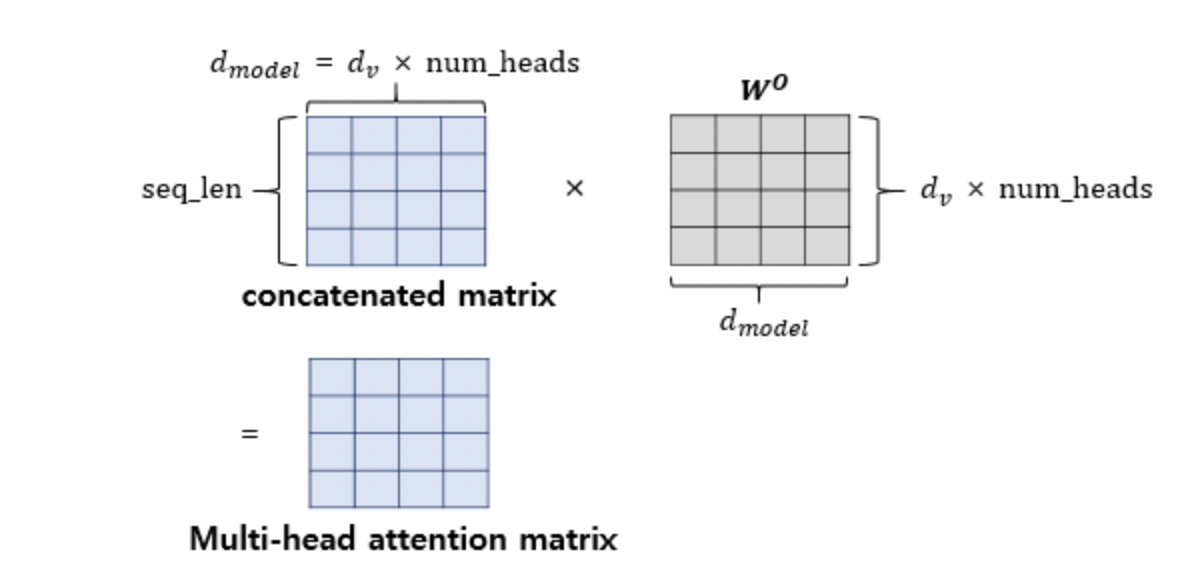
위와 같이 개의 결과물에 대해 각각 Attention Head라고 부르며, 마지막으로 Attention Head를 Concatenate해주게 된다.
어텐션 헤드를 모두 연결한 행렬은 또 다른 가중치 행렬 을 곱하게 되는데, 이렇게 나온 결과 행렬이 멀티-헤드 어텐션의 최종 결과물이다. 위의 그림은 어텐션 헤드를 모두 연결한 행렬이 가중치 행렬 과 곱해지는 과정을 보여준다. 이때 결과물인 멀티-헤드 어텐션 행렬은 인코더의 입력이었던 문장 행렬의 크기와 동일하다.
Transformer의 구조는 다음과 같다.
인코더의 첫번째 서브층인 멀티-헤드 어텐션 단계를 끝마쳤을 때, 인코더의 입력으로 들어왔던 행렬의 크기가 아직 유지되고 있음을 기억해두자. 첫번째 서브층인 멀티-헤드 어텐션과 두번째 서브층인 포지션 와이즈 피드 포워드 신경망을 지나면서 인코더의 입력으로 들어올 때의 행렬의 크기는 계속 유지되어야 한다. 트랜스포머는 다수의 인코더를 쌓은 형태인데(논문에서는 인코더가 6개), 인코더에서의 입력의 크기가 출력에서도 동일 크기로 계속 유지되어야만 다음 인코더에서도 다시 입력이 될 수 있기 때문이다.
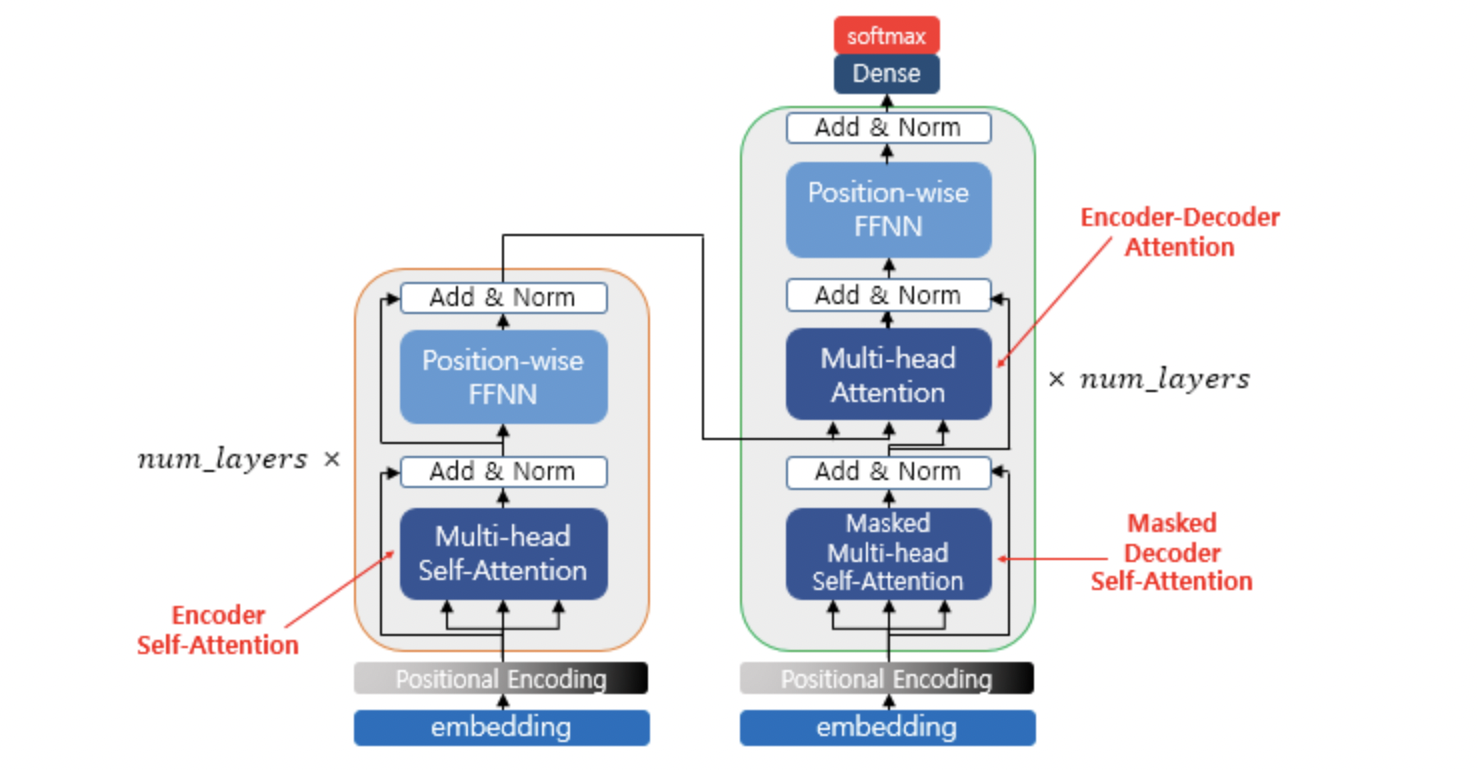
여기까지 RNN에서 Transformer의 핵심 기능인 MHA까지 알아보는 시간을 가졌다. 다음 글에서는 Transformer의 전체 구조에 대해서 알아보겠다.
참고
Seq2Seq
Attention
seq2seq, attention
Transformer
transformer동빈나
transformer
Transformer 논문
