우리가 기계학습에서 흔히 사용하는 MSE, CrossEntropy의 개념은 어디서 왔을까?에 대한 답을 조금이나마 할 수 있는 통계학기반의 글이다.
우리가 "기계 학습"이라 부르는 기술들(classification and regression models)은 거의 대부분 통계를 기반으로 하고 있다. 때문에 용어들이 두 분야에서 혼용되고 있다.
대부분의 용어가 새로 만들어진 것이 아니다.
기본 용어 정리
Random Variable
Probability Distribution
Entropy
H(p)=−∑i=1npilogpi
엔트로피는 가능한 이벤트들에 대한 weighted-average log probability이고, (이는 수식에서 더 명백히 알 수 있는데) 분포에 내재한 불확실성을 측정하는 방법이라 할 수 있다. 즉, 어떤 이벤트에 대해 엔트로피가 높다는 것은 해당 결과값을 얻을 것이라는 믿음에 대한 확실성이 덜하다는 것을 뜻한다.
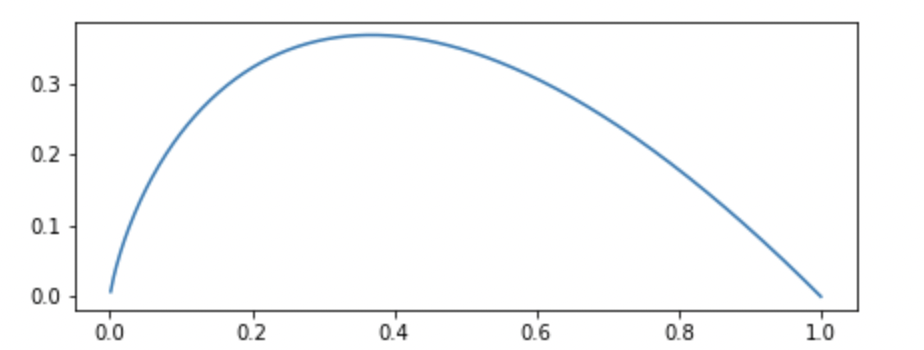
plogp 에 대한 그래프는 다음과 같다.
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure(figsize =(7,7))
ax = fig.add_subplot(111,aspect=1)
x = np.linspace(0,1,1000)
y =-x*np.log(x)
ax.plot(x,y)
plt.show()
즉, 확률이 0이나 1에 가까우면 해당하는 Random Variable에 대해 그만큼 확신할 수 있기 때문에, '불확실성'이 낮아진다고 생각할 수 있다.
Response variable
모델들은 예측해야 하는 response variable 즉 y 의 종류에 따라 바뀌게 된다.
Linear regression은 연속된 실수 값을 예측.
Logistic regression은 이진 값을 예측.
Softmax regression은 multi-class label을 예측.
Linear Regression은 true mean μ∈(−∞,∞) 와 true variance σ2∈(−∞,∞) 를 갖 는다.
Logistic Regression은 0 또는 1을 값으로 값는다.
red or green or blue는 빨강, 초록, 파랑 중 하나의 값을 갖는다.
Maximum Entropy Distribution
우리는 관측값을 뽑았을 때 그 샘플이 진짜 모집단의 Probability distribution을 정확하게 나타내는지에 대해 확신할 수 없다. 따라서 가장 불확실한 형태의 분포를 가정하는 방법이 Maximum Entropy Distribution이다.(가장 보수적인 분포 라고도 한다.)
이 때, 우리는 실수 집합에서는 Gaussian, 이진 집합에서는 Binomial, 다중 집합에 대해서는 Multinomial Distribution을 MAP로 지정할 수 있다.
Functional Form
딥러닝 모델의 활성화 함수
우리는 딥러닝에서 각 레이어에서 활성화 함수를 통해 output을 만들어 내는데, 이 때 우리는 y라는 response variable의 분포에 따라 다음과 같은 방식의 Keras modeling을 할 수 있다.
위와 마찬가지로 특정 클래스가 나올 확률을 πk라 할 때, P(y∣π)=k=1∏Kπkyk=exp(k=1∑Kyklogπk)=exp(k=1∑K−1yklogπk+(1−k=1∑K−1yk)log(1−k=1∑K−1πk))=exp(k=1∑K−1yklogπk−(k=1∑K−1yk)log(πK)+log(πK)), where πK=1−k=1∑K−1πk=exp(k=1∑K−1log(πKπk)yk+log(πK))
로 변환할 수 있고 이 때
πk=∑k=1Keηkeηk
이다.
위를 종합해보면, 각 분포의 모수는 η에 대한 함수의 형태로 표현이 가능한데,
Linear regression (Gaussian distribution): μ=η
Logistic regression (Binomial distribution): ϕ=1+e−η1
Softmax regression (Multinomial distribution): πk=∑k=1Keηkeηk
위에서부터 각각 Identity, Sigmoid, Softmax 함수를 의미한다.
Generalize Model
각 모델은 Response Variable에 따라 그 분포가 결정되고, 각 분포의 Canonical Parameterη는 관측값에 따라 달라진다. 다르게 이야기하면, 관측되는 Input Data X에 따라서 분포를 결정하는 모수,(Exponential Family로 변환했을 때) η가 달라지게 되는 것이다. 우리는 이를 다음과 같이 선형 결합으로 나타낼 수 있다. θ는 선형결합을 위한 임의의 행렬, x는 관측 데이터라고 할 때, η=θTx 로 표현할 수 있다.
왜 하필 linear model, η=θTx 이어야 했을까?
앤드류 응 교수에 따르면 이는 "모델 디자인" 혹은 "선택"의 문제다.
여기서 선형 조합이 자주 사용되 는 이유를 굳이 꼽자면:
아마도 선형 조합(linear combination)이 canonical parameter에 대한 각 feature에 영 향을 줄 수 있는 가장 쉬운 방법일 것이기 때문이다.
선형 조합이 단순히 x 뿐만 아니라 x 에 대한 함수에 대해서도 η 에 대해 선형으로 변화한다고 하면 좀 더 복잡한 형태를 만들 수 있다. 즉, 우리는 모델을 η=θTΦ(x) 와 같이 쓸 수 있 고, 여기서 Φ 는 우리의 feature에 대한 복잡한 변형(transformation)을 주는 operator 를 의미한다. 이 부분이 선형 조합의 단순함을 조금은 덜하게 만들어준다고 할 수 있다.
따라서 우리는 η=θTx에서 관측값을 통해 η를 결정하게 되면, 위와 같은 분포를 결정하게 될 것이다.
우리의 최종 목표를 다시 한 번 상기시켜보자. 우리는 관측 데이터를 통해 특정 분포를 예측할 것이다. 다시 말하면, 실제 데이터가 가지는 Population의 Parameter가 우리가 예측한 Parameter와 같아지도록, 최대한 비슷하도록 노력하는 과정이다. 이는 MLE를 통해 Likelihood가 최대가 되도록 결정하는 것과 같다. 수식으로 표현하면 다음과 같다.
argmaxθP(y∣x;θ)
관측 데이터 x에 대해 어떤 Parameter θ에 의존하는 y( Response Variable)의 가능도가 최대가 되는 θ를 찾는 것이라고 풀어서 설명할 수 있다.
따라서 우리는 각 분포에 대해서 MLE를 구해보도록 한다. 대표적인 MLE Technique 중 하나인 Log-likelihood를 사용하자.
위의 수식에서 우리가 알 수 있는 것은, LL(log-likelihood)를 최대로 하는 것은 MSE(Mean Squared Error)를 최소화하는 것과 같다. 따라서 우리는 MSE를 최소화하는 기계학습의 대표적인 방식이 NLL(Negative Log-Likelihood)를 최소화하는 것과 동치라는 것을 알 수 있다.
Logistic regression
Bionomial distribution에 대해 위와 똑같은 방식으로 Negative log-likelihood를 적용해보자.
따라서 데이터와 θ 에 대해 negative log-likelihood를 최소화 하는 것은 관측된 y 값과 우리가 예측한 값 사이의 categorical cross-entropy (i.e. multi-class log loss)를 최소화 하는 것과 동치이다.
Maximum a posteriori estimation(최대사후확률)
추가적으로 덧붙이자면 위의 MLE방식은 θ에 대한 어떠한 제약도 없는 형태이다. 실제로는 이런 가정은 좀 비현실적이기도 하고 군더더기인 부분이기도 한데, 보통은 θ (weights)가 유한범위 안에서 값을 갖기를 바라기 때문이다. 따라서 이를 위해 θ에 prior 를 두곤 한다. 이를 maximum a posteriori estimate (MAP)라 부르며, argmaxθP(y∣x;θ)P(θ)를 계산한다.
앞서와 마찬가지로 log 를 씌운 다음 prior와 함께 joint likelihood를 풀면:
와 같이 되는데, 우리의 목표는 log-likelihood와 함께 위의 항을 같이 θ 에 대하여 최대화하는 것이다. θ 를 포함하지 않 는 항을 정리하고 나면 다음과 같고:
logC1−C2θ2∝−C2θ2∝C∥θ∥22
이것이 바로 L2 regularization라는 것을 알 수 있다. 게다가 θ 에 대해 prior distribution을 바꾸면 또다른 regularization이 가능해진다.(e.g. Laplace prior는 L1 regularization을 하는 것과 동치)
따라서 정리해보면, 기계학습에서 weights를 regularize한다고 함은 "no weight becomes too large" 하겠다는 것고, 다르게 말하면 y를 예측할 때 너무 큰 영향을 미치지 못하게 만드는 것이다. 통계적인 관점에서도 똑같이 이런 prior 항이 주어진 범위 내에서 값이 나오도록 제한하는 역할을 한다고 말할 수 있다. 이 범위가 scaling constant C로 표현되고 prior distribution 자체를 매계변수화한다. 예를 들어 L2 regularization에서는 이 scaling constant가 Gaussian의 분산을 정하게 된다.
Going fully Bayesian(수정 중)
예측 모델의 주요 목표는 다음 분포를 계산하는 것이다:
P(y∣x,D)=∫P(y∣x,D,θ)P(θ∣x,D)dθ
각 항을 설명해보자면:
P(y∣x,D): 학습 데이터 D=((x(i),y(i)),⋯,(x(m),y(m))) 와 새로운 관측값 x
가 주어졌을 때, response y 의 값에 대한 분포를 계산하는 것.
기계학습에서는 보통 해당 분포의 expected 값을 고르게 된다 (i.e. a single value, or point estimate).
P(y∣x,D,θ): 학습 데이터 D, 새로운 관측값 x, 임의의 가능한 θ 값이 주어졌을때 (굳이 optimal이 아니더라도) y 를 계산하는 것.
보통 주어진 모델에 대한 함수로 나타내지고 linear regression의 경우 y=θTx 와 같이 나타낼 수 있다.
P(θ∣x,D): 학습 데이터 D 와 새로운 관측값 x 가 주어졌을 때 우리의 데이터를 설명할 수 있는 θ 값에 대한 분포를 계산하는 것.
ㅇ 여기서 x 는 아무런 역할을 하지 않는다. 그저 적분을 할 때 수식적 표현이 맞도 록 들어가 있을 뿐이다.
기계학습에서는 MLE 혹은 MAP estimate을 고른다. (i.e. a single value, or point estimate).
모든 것이 완벽하다면,
θ 에 대한 full distribution 을 계산하고,
이 분포의 값들과 새로운 관측값 x 를 가지고 y 를 계산할 수 있다.
NB: 여기서 θ 가 weights이므로 10 -feature linear regression에서는 10 개의 원소를 갖는 벡터가 된다. 신경망에서는 수백만까지도...
이로부터 가능한 모든 response y 에 대한 full distribution을 얻을 수 있다.
마치며
이 글의 한국 번역을 다시 리뷰해보는 시간을 가졌는데, 통계학과 기계 학습의 접점을 잘 설명할 수 있는 것 같아 놀랍고 새로웠다. 해당 글에서 아직 100% 이해가 된 부분이 아닌 것도 꽤 있지만, 전체적인 느낌을 살려보는데 좋은 시간이었다고 생각한다.
우리는 이 글을 통해 MSE는 정규분포, CE는 이항분포와 다항분포으로부터 유도할 수 있다는 사실을 알 수 있다.