Optimization
- Gradient Descent
First-order iterative optimization algorithm for finding a local minimum of a differentiable function
Important Concepts
Generalization
일반화 성능을 높이려고 보통 노력한다.
우리가 학습하는데 있어서 Training error는 낮아질수록 좋은 것만은 아니다. Test error에 좋은 성능을 내지 못하게 과적합되어있을 수 있기 때문. 이 때 Generalization Gap은 Test Error와 Training Error의 차이를 의미한다.
Cross-validation
model validation techinique for assessing how the model will generalize to an independent data set
- K-fold(cross-validation)
K로 나눈 뒤 각 fold들에 대해서 validation을 계산한다.
NN에서는 많은 파라미터, 하이퍼 파라미터에 대해서 많은 단서가 없기 때문에 cross validation을 통해 성능이 좋은 파라미터를 고정하고, 그 뒤에 전체 데이터를 통해 학습한다.
Bias and Variance
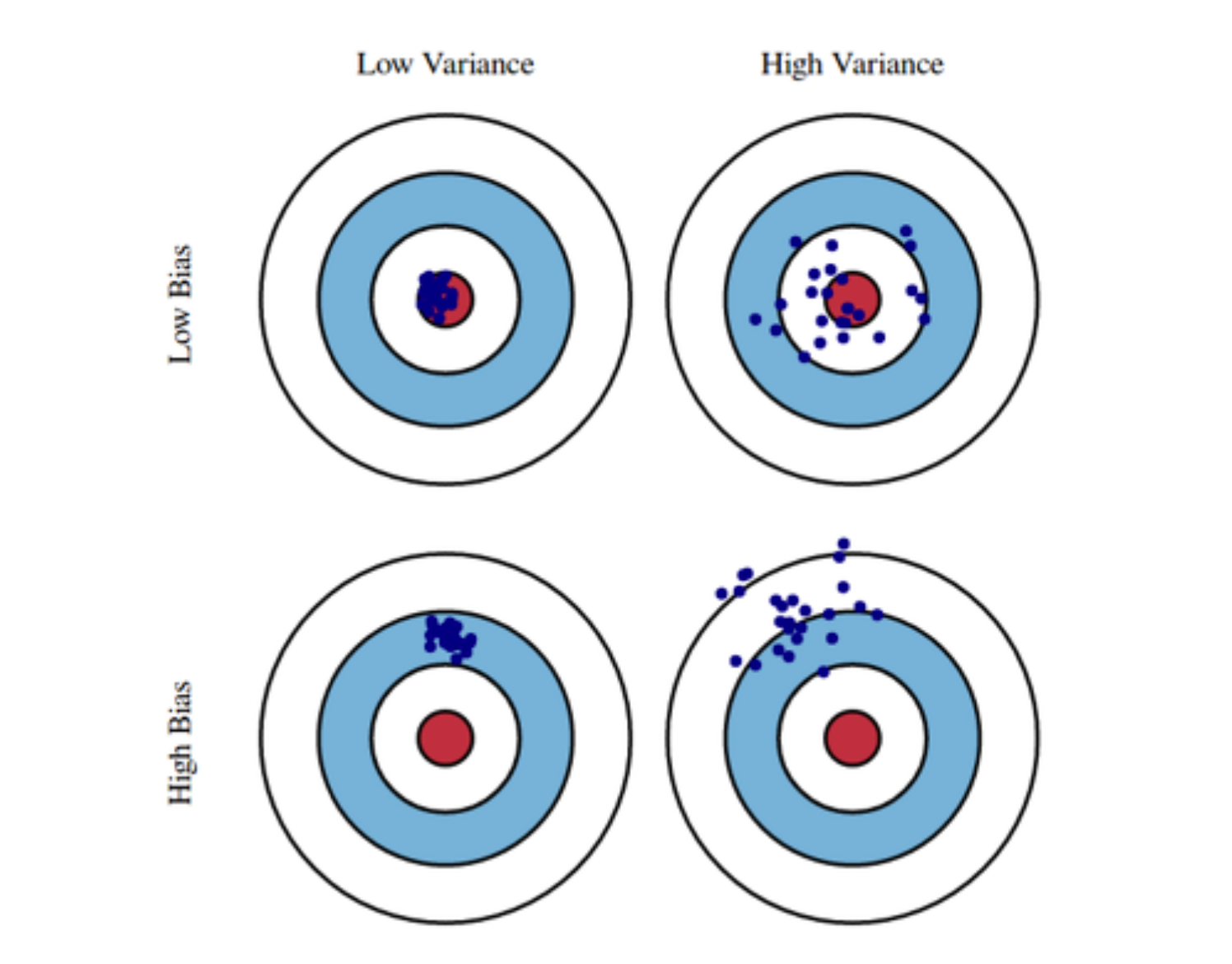
bias는 전체 데이터의 평균의 위치 정보 정도로 이해하면 될 듯하다.
- Bias and Variance Tradeoff
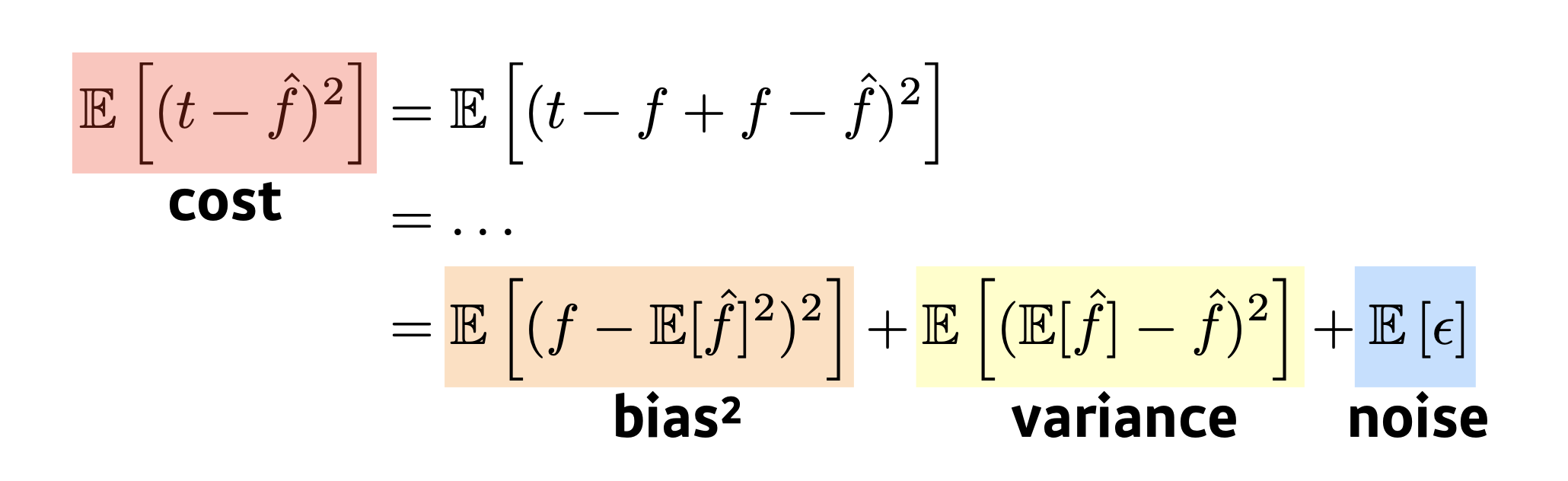
는 예측값, t는 True Target에 noise 가 추가된 데이터라고 할 때 우리는 cost의 기댓값을 bias와 variance, noise에 관한 식으로 나타낼 수 있으며 이는 Trade-off의 형태를 가진다.
Fundamental한 정보로 알아두자.
Bootstrapping
통계학에서 많이 활용되는 이야기로,
any test or metric that uses random sampling with replacement
-
Bagging
multiple models are being trained with bootstrapping. (Ensemble) -
Boosting
focuses on those specific training samples that are hard to classify.
A strong model is built by combining weak learners in sequence where each learner learns from the mistakes of the previous weak learner. 또한, 잘못 예측된 결과에 대해 가중치를 줘서 최적의 모형을 찾아내는 방법이다. -
엄밀히 말하면 Ensemble 기법의 종류에 Sampling과 Variable방법이 있는데, Sampling 방법 안에는 Bagging과 Boosting이 있고, Variable방법으로는 RandomForest가 있다.
Practical Gradient Descent Methods
Gradient Descent Methods
- Stochastic Gradient Descent
update with the gradient computed from a single sample - Mini-batch
compute from a subset of data - Batch Gradient Descnet
compute from the whole data.
Batch-size Matters
large batch methods tend to converge to sharp minimizers, small batch methods tend to converge to flat minimizers.
Flat minimizers are better than Sharp minimizers.
generalization performance를 높이는 방법이다.
Optimizers
MSE를 loss로 하는 경우 Loss값이 square 증폭되기 때문에 많이 차이나는 곳에 더 잘 맞추게 되고 적게 차이나는 곳에는 덜 맞추게 된다. 따라서 Outlier에 취약한 단점이 있다.
-
GD
learning rate을 정하기가 까다롭기 때문에 최적점을 찾는데 상대적으로 어려움이 있다. -
Momentum
( : gradient)
이전에 움직이던 방향의 정보를 가지고 관성을 가지고 업데이트하는 것을 의미한다. Accumulated Gradient라고 부를 수 있다. -
NAG, Nesterov Accelerated Gradient
현재 정보에서 이동한 다음 업데이트된 가중치 정보를 바탕으로 accumulation을 진행하는 것.
Local minimum에 좀 더 빨리 접근이 가능하다. -
AdaGrad
adapts the learning rate, performing larger updates for infrequent and smaller updates for frequent parameters.
( : sum of gradient squares)
NN의 파라미터가 얼마나 변해왔는지를 확인하며 최적화하는 방법. 파라미터를 적게 변화시킨 것에는 더 많이 변화시키도록, 많이 변화시킨 것에는 더 적게 변화시키도록 한다.
G는 뒤로 갈수록 학습이 멈춰버리는 현상이 발생한다. 이러한 문제를 해결하기 위한 방법론들이 등장한다. -
Adadelta
가 커지는 것을 막기위한 방법으로 나온 Extension of Adagrad.
Extend Adagrad to reduce its monotonically decresing the learning rate by restricting the accumulation window.
:EMA(Exponential Moving Average) of gradient squares
: EMA of difference squares
를 통해 monotonically decreasing problem을 막을 수 있는 방법이다.(Learning rate이 없다) -
RMSprop
RMSprop is an unpublished, adaptive learning rate method proposed by Geoff Hinton in his lecture(Not paper). -
Adam
EMA of Gradient squares와 momentum을 같이 활용하는 것.
Adaptive Moment Estimation (Adam) leverages both past gradients and squared gradients.
: momentum
: EMA gradient squaresAdam effectively combines momentum with adaptive learning rate approach.
Regularization
Generalization을 잘 되게 하려는 것. 즉, 학습데이터 뿐만 아니라 테스트 데이터에서도 잘 예측할 수 있도록 만드는 것.
Early stopping
validation data를 통해 val_loss와 loss를 비교해준다. 이 때 추가적인 학습이 gerneralize하지 않게 나온다면 학습을 멈춘다.
Parameter Norm Penalty
(= Weight Decay)
L2 norm의 제곱이기도 한 인자를 추가해준다.
(부드러운 함수)
Data Augmentation
데이터가 무한히 많으면 웬만하면 잘 된다. 데이터가 작을 때는 Traditional ML이 DL보다 효과가 좋다. 그러나 데이터가 많으면 ML이 그것을 다 표현할 수 없다.
더 많은 데이터를 위해서 데이터의 라벨이 변하지 않는 한도 내에서 데이터에 변환를 주는 것이다.
Noise Robustness
왜 잘 되는가에 대해서 아직 의문인 점이 있다. 입력 데이터, Weight에 노이즈를 집어넣는다. Weight가 학습될 때, 성능이 더 잘 나온다는 연구 결과가 있다.
Label Smoothing
Mix-up constructs augmented training examples by mixing both input and output of two randomly selected training data. Train data의 데이터 두개를 뽑아서 섞는 것.
분류에서, Decision Boundary를 부드럽게 만들어주는 효과.
CutMix constructs augmented training examples by mixing inputs with cut and paste and outputs with soft labels of two randomly selected training data.

Dropout
과적합을 막기위해 randomly하게 neuron을 0으로 만든다.
Batch Normalization
internal covariate shift에 대한 논란이 있는 논문이다. 학습을 진행하면서 내부 입력 데이터가 각 층별로 다른 분포를 가지게 된다는 의미이다.
Further Question
올바른 Cross-validation을 위해서는 어떤 방법들이 존재할까?
Time Series의 경우 k-fold cv를 사용해도 될까?
Time Series Nested Cross-validation
도메인 특강
- NLP 일정
- NLP 이론
- 강의 & KLUE 대회- MRC, QA
Computer Vision 소개
NLP 소개
documents를 이해하는 것이 목적이다. 이 documents에서 정보나 인사이트를 도출, 분류, 정리하는 것 등을 모두 포함한다.
- NLP Applications
- Search- Voice Assistant
- Translation
- 세 가지 트렌드
- 언어 모델을 사용한다.- Retrieval-based model(DPR)
라지 모델은 암기력 좋고 똑똑한 애한테 도서관에 가서 다 내용을 외우라고 하는 것.
Retrieval 모델은 차라리 그 애한테 어떤 질문이 주어졌을 때 관련된 책을 찾고 그 책 안에서 정보를 찾는 법을 가르쳐주는게 어떨까 - Multimodality
결국에는 다양한 형식의 데이터가 들어오고, CV/NLP 기술을 사용한다.
DALL E Open AI
NLU, SLU 등 multimodality는 중요
- Retrieval-based model(DPR)
질문
NLP 논문 : attention is all you need
