챕터 2 : 대규모 데이터 처리 입문
대규모 데이터는 최소 GB 단위이므로 메모리에 올려서 수행하기엔 무리다.
메모리와 디스크 속도 차
메모리의 경우 탐색 속도가 디스크의 탐색 속도보다 10^5배 ~ 10^6배 차이난다.
디스크 관련 OS 지식 참고 링크
https://studyandwrite.tistory.com/24
https://jhnyang.tistory.com/105
전송 속도, 버스 속도 차이
전송 속도에서도 디스크가 메모리보다 100배 이상 느리다.
규모 조정의 요소
대부분의 웹 어플리케이션은 요청이 오면, 프록시 서버 -> 어플리케이션 서버 -> DB로 진행이 되고 응답은 프록시 서버 <- 어플리케이션 서버 <- DB로 역순 진행을 한다.
여기서 비즈니스 로직을 수행하는 어플리케이션 서버는 CPU Bound 작업을, DB는 I/O Bound 작업을 수행한다.
만약 CPU 작업이 많은 영역 (어플리케이션 서버)에 부하가 걸리면 어떻게 해야할까?
간단하게 서버를 스케일 아웃하고 로드 밸런서를 이용해 작업을 분산하면 된다. 왜냐하면 단순히 비즈니스 로직만 수행하면 되고 DB 내 데이터 동기화를 할 필요가 없기 때문이다.
하지만 I/O 작업이 많은 영역인 DB에 부하가 걸리면, 단순히 서버를 늘리는 방식으로는 해결할 수가 없다. 이유는 다음과 같다.
1.DB의 개수를 늘렸다는 가정하에, 한 DB에 I/O 쓰기 작업이 일어났다고 하자. 그러면 다른 DB들에게도 해당 데이터를 동기화할 필요가 있다. 그런데 DB 동기화는 쉬운 작업이 아니다.
2.I/O는 읽기와 쓰기 작업 모두 느린 작업이다.
챕터 4 : 분산을 고려한 MySQL 운용
인덱스의 중요성
B+ Tree
이미지 출처
https://potatoggg.tistory.com/174
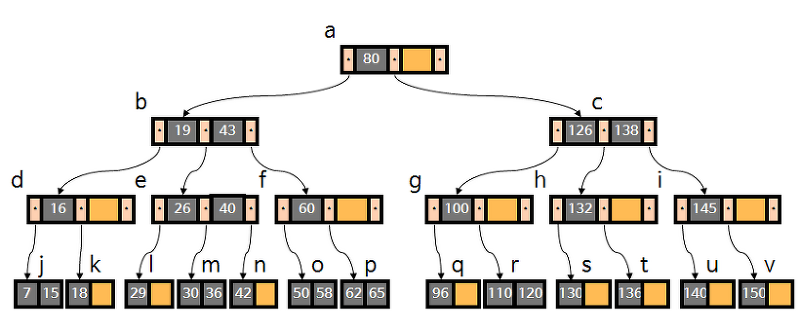
먼저, 인덱스는 B+ 트리로 구현이 된다. 왜 이분 탐색 트리가 아니라 B+ 트리로 구현하는 것일까?
B+ 트리의 경우 각 노드 1개에 대해 노드에 있는 데이터들을 모아서 디스크의 1블록 (섹터)씩 할당해준다고 한다. 위 그림을 예로 들면, 노드 a,b,c,... 모두 디스크의 1블록 (섹터)씩 할당이 되는 것이다.
디스크 형태

이미지 출처
https://studyandwrite.tistory.com/24
위 디스크 형태 그림을 보면, 트랙 내 분할된 영역들을 블록 또는 섹터라고 한다.
그리고 디스크 읽기를 할 때 가장 오래는 걸리는 작업이 SEEK인데, 이 작업은 디스크의 헤드 암을 움직여서 원하는 트랙으로 이동하는 작업이다.
즉, B+ 트리는 각 노드의 데이터들을 모아서 하나의 블록으로 모아 저장할 수 있기 때문에, 한 노드 내 데이터를 알아내기 위해서 다른 트랙으로 움직일 필요가 없으므로 SEEK 작업이 필요없다.
위 그림을 예로 들면, 노드 c로 이동한 상황에서 c 내 데이터들을 읽을 때는 다른 트랙으로 움직이지 않아도 된다.
B+ 트리에서 SEEK 작업이 일어나는 것은 한 노드에서 다른 노드로 아예 이동할 때 발생한다고 한다.
반면 이분 탐색 트리의 경우는 노드 내 데이터들이 1개의 블록으로 모여있지 않다. 따라서 이분 탐색 트리의 경우는 다음 깊이의 노드로 움직일 때의 SEEK 연산 뿐만 아니라, 흩어진 노드 데이터들을 찾기 위해 추가적인 SEEK 작업이 필요해서 더 느리다.
즉, 노드 내 데이터를 기준으로 디스크 작업의 소요 시간을 대략적으로 요약하면 다음과 같다.
B+ 트리 : O(노드에서 다른 노드로 움직이는 SEEK 작업)
이분 탐색 트리 : O(노드에서 다른 노드로 움직이는 SEEK 작업) + O(노드 내 데이터를 찾기 위해 움직이는 SEEK 작업)MySQL 분산
레플리케이션
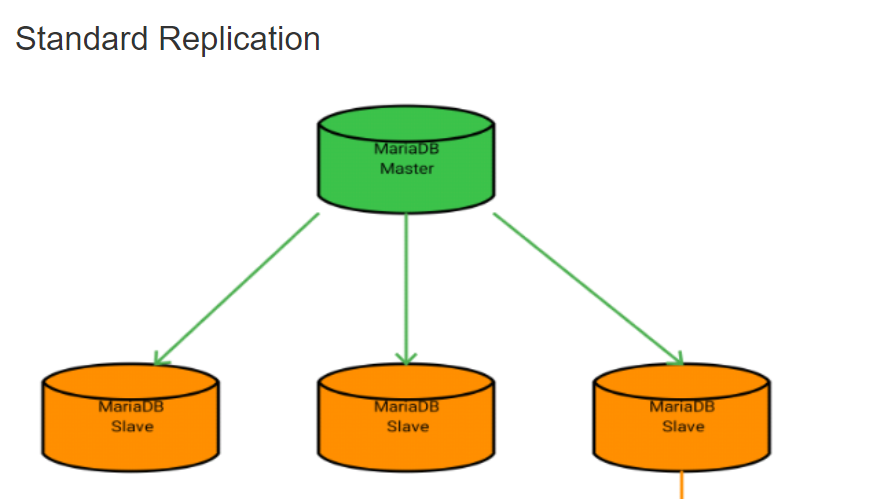
이미지 출처 및 레플리케이션 참고 링크
https://velog.io/@emawlrdl/MariaDB-%EC%9D%B4%EC%A4%91%ED%99%94-%EA%B5%AC%EC%84%B1
레플리케이션은 DB를 여러 대 두되, 역할을 마스터와 슬레이브로 나누는 전략이다.
마스터 DB의 경우 갱신 작업을 처리하고 슬레이브 DB는 읽기(참조)작업을 처리해준다. 각 슬레이브 DB들은 마스터 DB에 쓰인 내용을 일정 시간마다 폴링해서 동기화한다.
어플리케이션 서버에서 DB로 가는 작업이 있다고 하자. 이 때 어플리케이션 서버는 로드 밸런서를 경유한다. 그리고 로드 밸런서는 읽기 작업인 경우 슬레이브 DB로 쿼리를 날리고 쓰기 작업인 경우 마스터 DB에 날려주는 것이다.
마스터 / 슬레이브의 특징
슬레이브 DB의 경우 SELECT만 담당하므로 서버 확장이 수월하고, 성능 향상에 효과가 있다. 반면 마스터 DB는 갱신을 담당하기 때문에 서버 확장이 어렵다.
다행인 것은 웹 어플리케이션의 경우 요청의 90%가 SELECT이기 때문에 마스터 DB 확장이 많이 필요하지는 않다는 것이다.
파티셔닝 참고 링크
https://gmlwjd9405.github.io/2018/09/24/db-partitioning.html
