시퀀스 다이어그램 (v1 백엔드)
일정, 인력 등을 고려해 v1에서는 다음 기능들만 구현하기로 결정했습니다.
면접 질문 출제
이전 서비스 모뷰와는 달리 실시간 질문 출제가 필요 없습니다. 따라서 리스폰스도 선택된 모든 질문을 보내기만 합니다. 질문의 개수는 10개로 정했습니다.
기술 영역
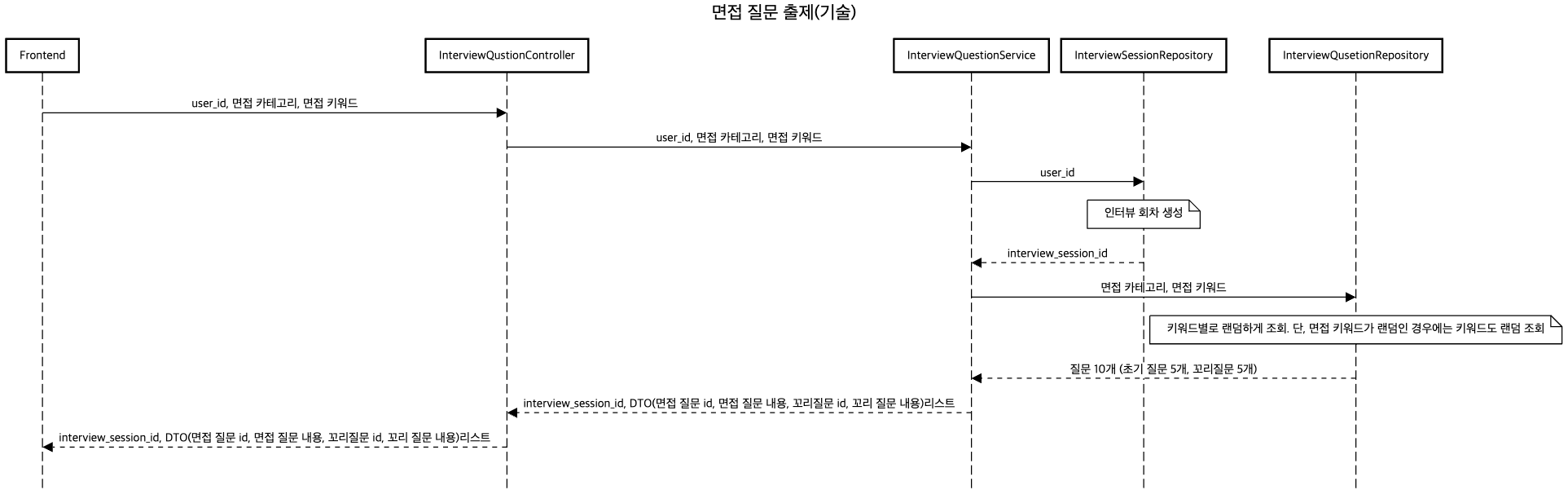
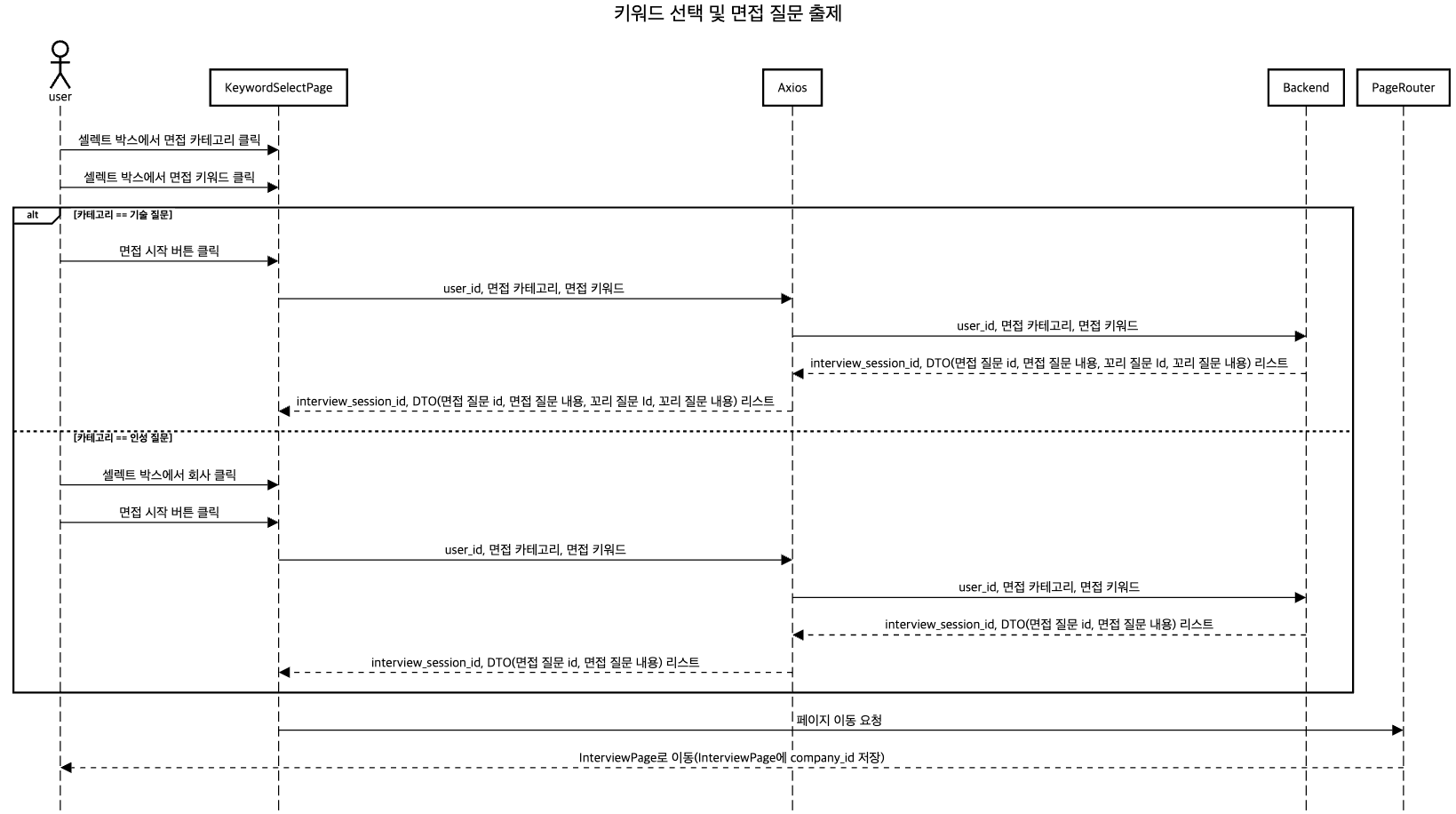
사용자는 면접 카테고리, 면접 키워드를 제출하면, 최종적으로 인터뷰 세션 id와 면접 질문 DTO 리스트를 받습니다.
DTO는 <면접 질문 , 해당 질문에 대한 꼬리 질문 1개> 쌍으로 이루어집니다.
인성 영역
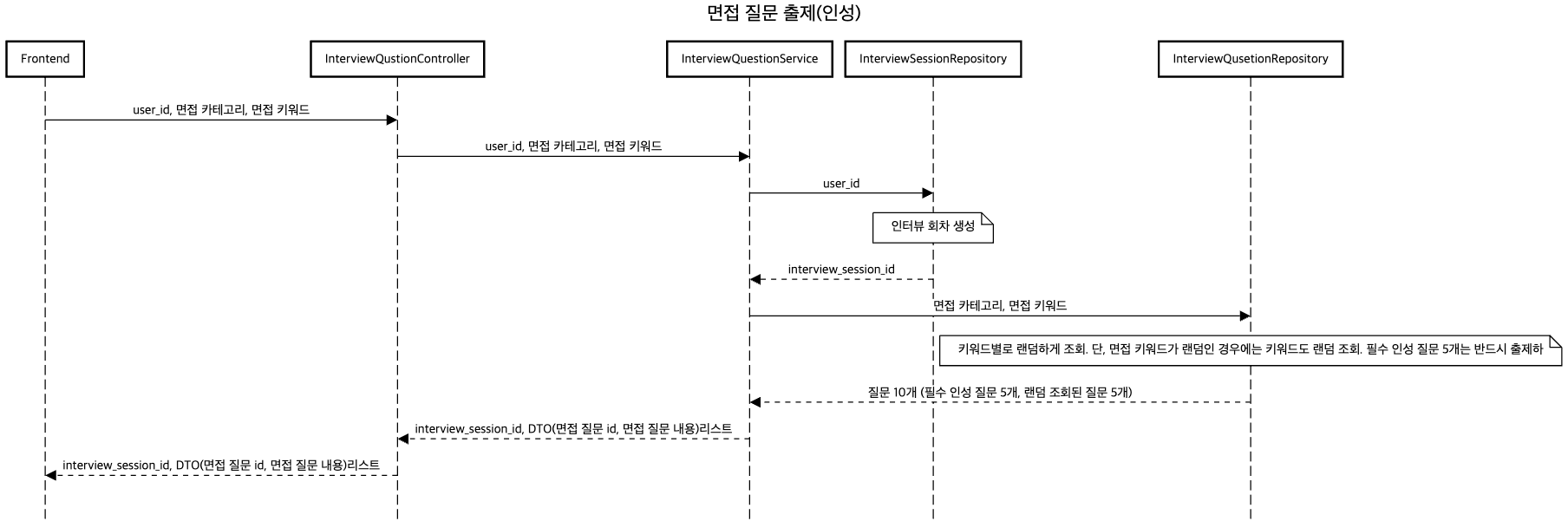
사용자는 회사, 면접 카테고리, 면접 키워드를 제출하면, 최종적으로 인터뷰 세션 id와 면접 질문 DTO 리스트를 받습니다. 인성 질문의 경우 필수 질문 5개는 반드시 출제됩니다.
사용자 답변 저장
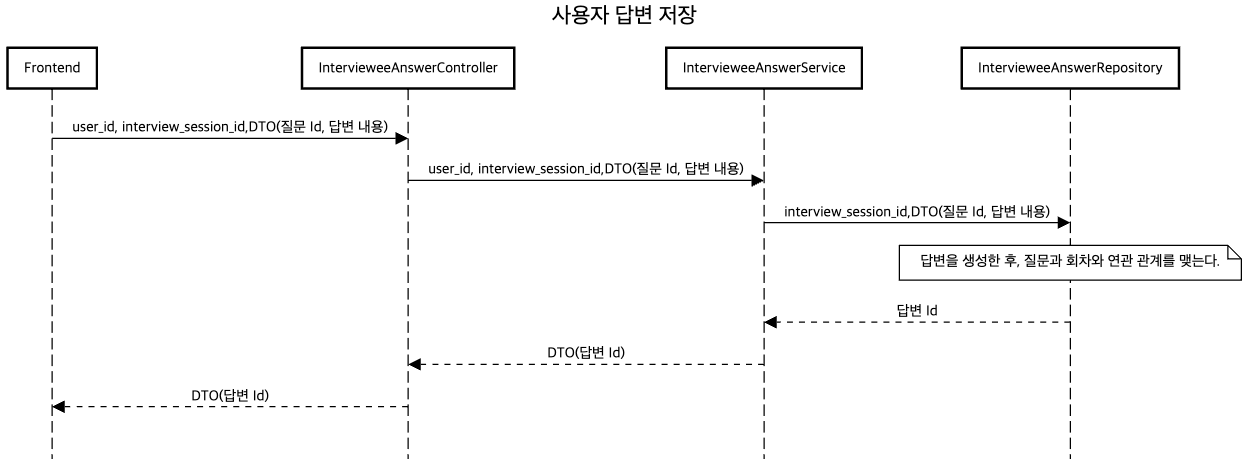
답변을 한꺼번에 백엔드로 보낸다면, 사용자가 중간에 피치 못한 상황으로 종료될 경우 작성한 답변이 다 날라가는 것은 아닌지를 고려해서 회차 내에서 답변마다 저장하게 구현합니다.
LLM 기술 면접 연관 질문(샷 프롬프트)
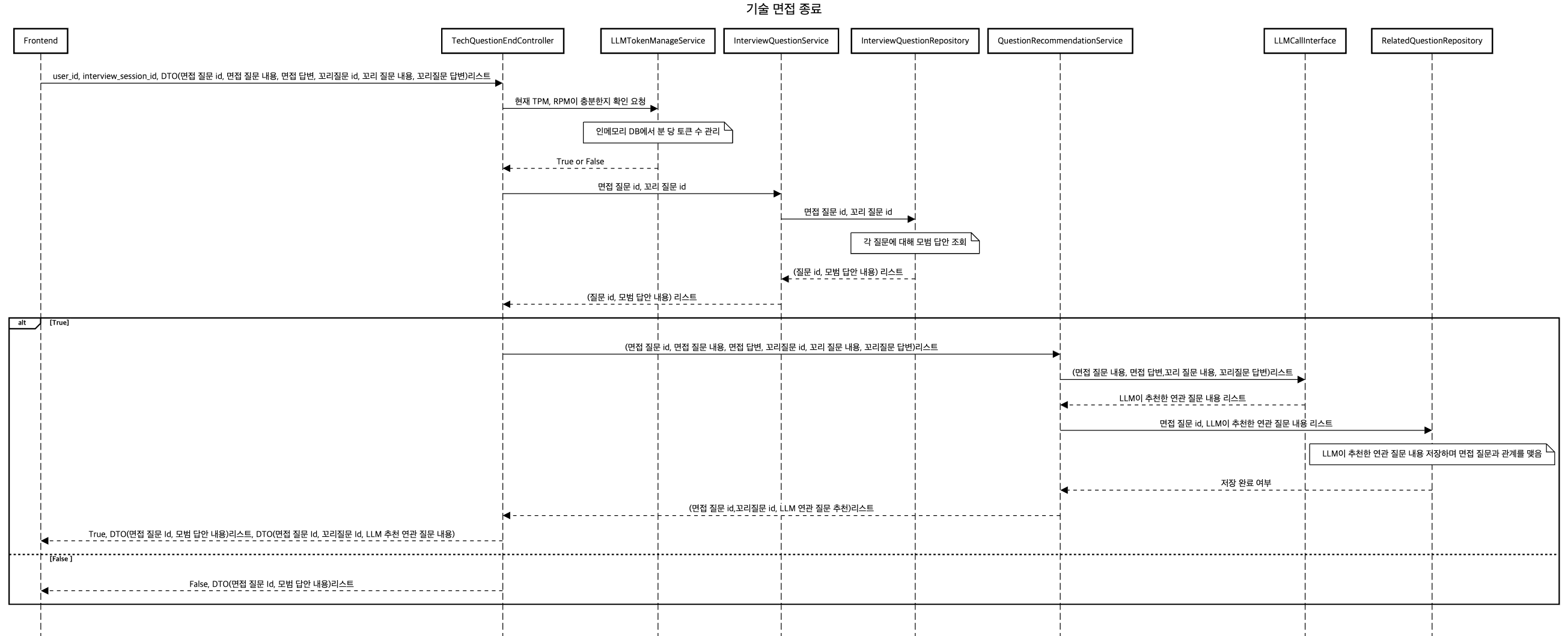
LLM 연관 질문 생성은 <질문 내용, 사용자 답변>을 기반으로 연관된 질문을 생성하는 기능입니다.
즉, 새로운 지식이나 비공개 정보가 아니기 때문에 벡터 DB 임베딩 + RAG는 아닙니다. (돈도 많이 듭니다.)
또한 특정한 말투 패턴이나 스타일이 필요 없으므로 파인튜닝도 아닙니다. (특히 파인튜닝은 AI 전문 지식이 필요합니다 ^^)
따라서 돈이 거의 안들고, 유사도 검색도 필요 없기에 제로샷 프롬프트 ~ 퓨샷 프롬프트를 활용합니다. (그런데 노동력은 들겠네요 ㅠ)
그리고 TPM / RPM이 모자랄 경우를 대비한 예외 처리를 미리 고려했습니다.
인성 면접 답변 첨삭
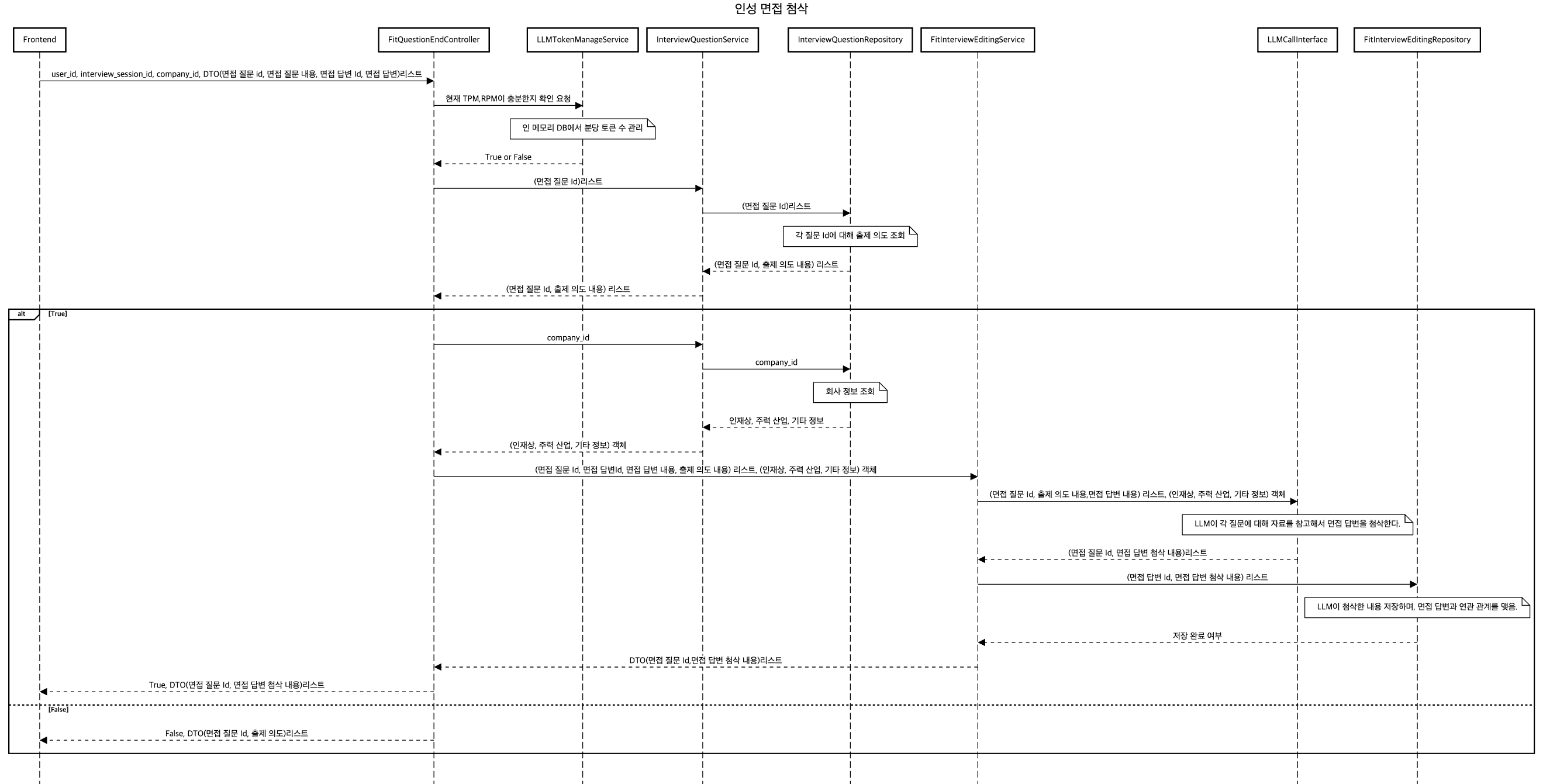
인성 면접 답변 첨삭은 <회사 정보, 인성 질문, 출제의도, 사용자 답변>을 기반으로 면접 답변을 첨삭해주는 기능입니다.
vector db가 LLM 서비스에 필요한지에 대한 참고 자료
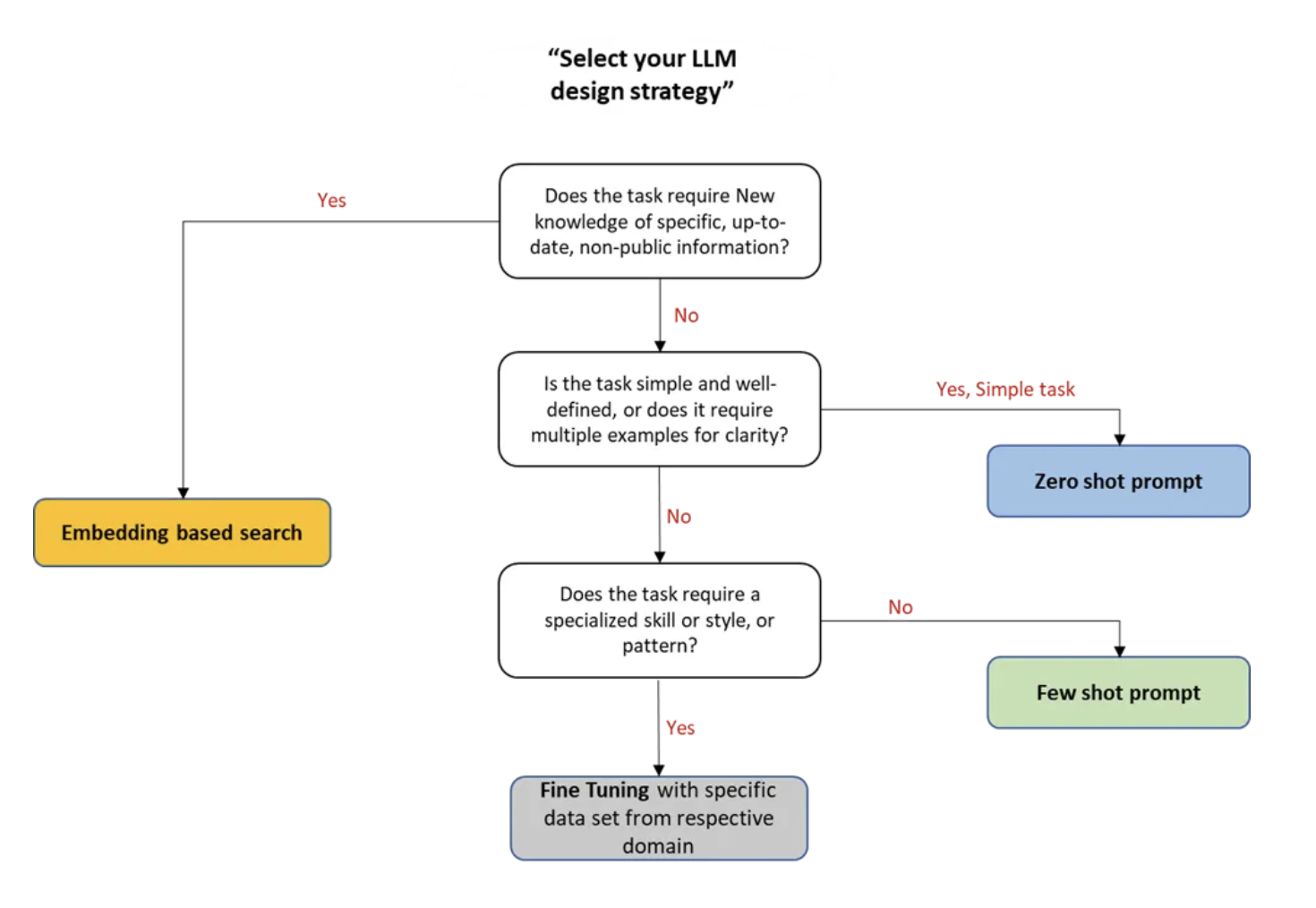
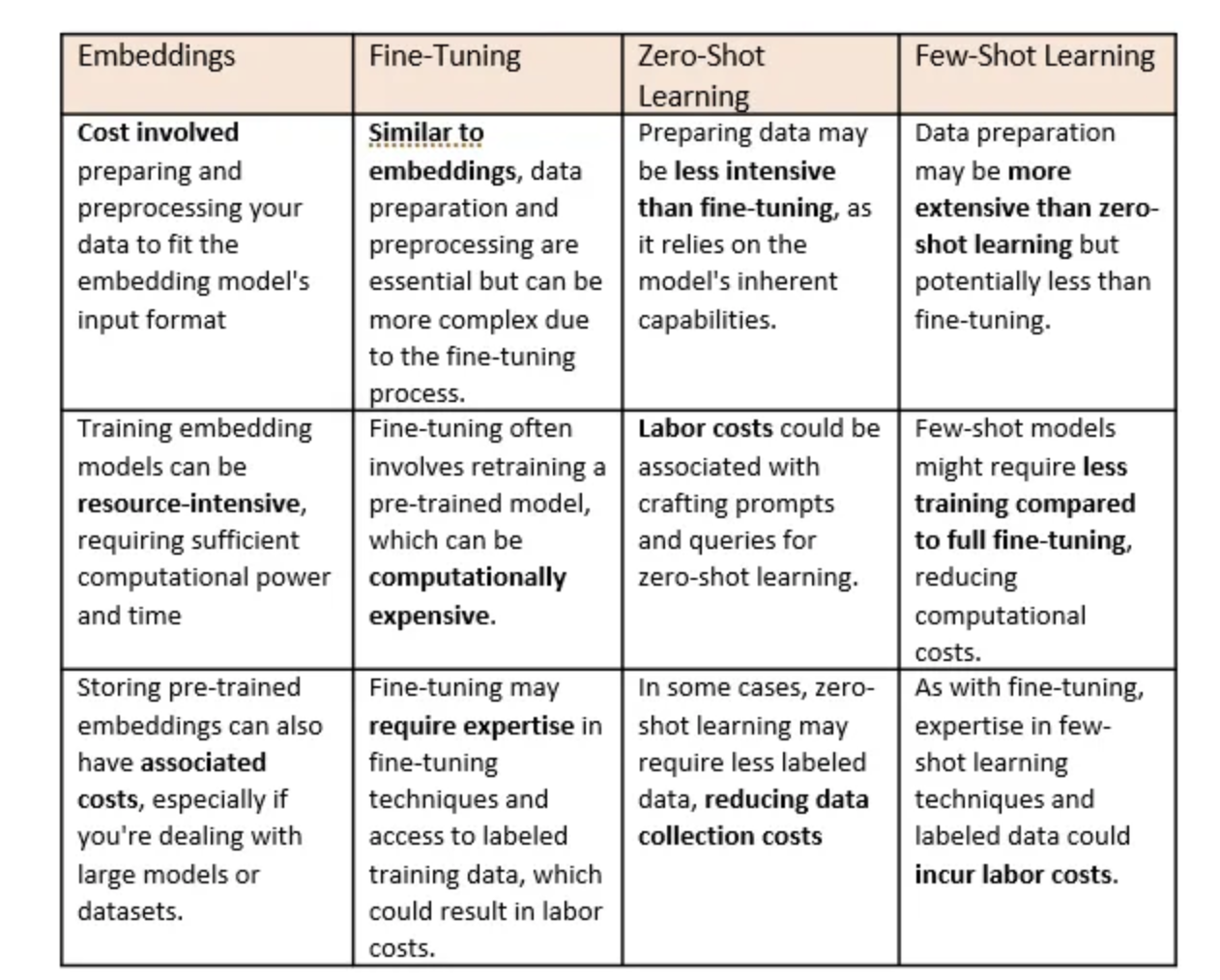
출처
시퀀스 다이어그램 (v1 프론트엔드)
키워드 선택 화면
면접 연습 화면
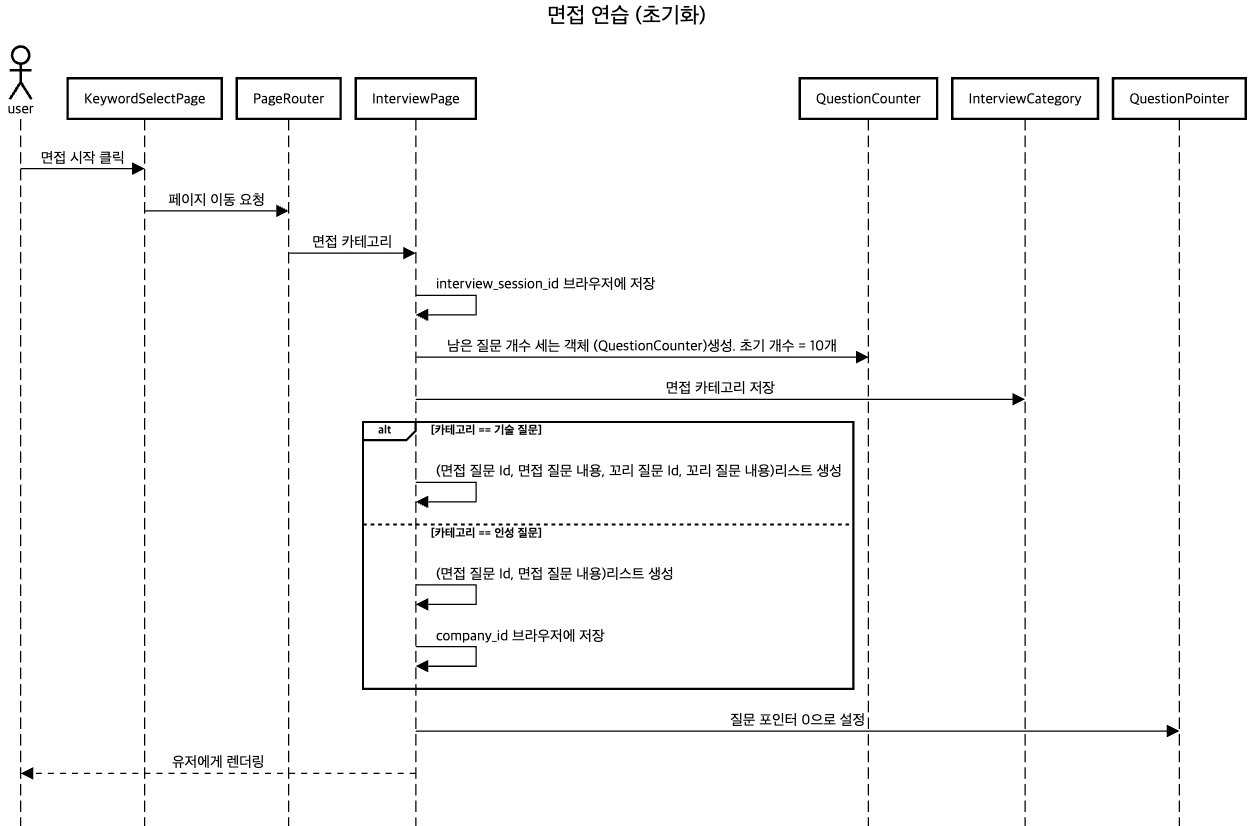
초기화 시나리오
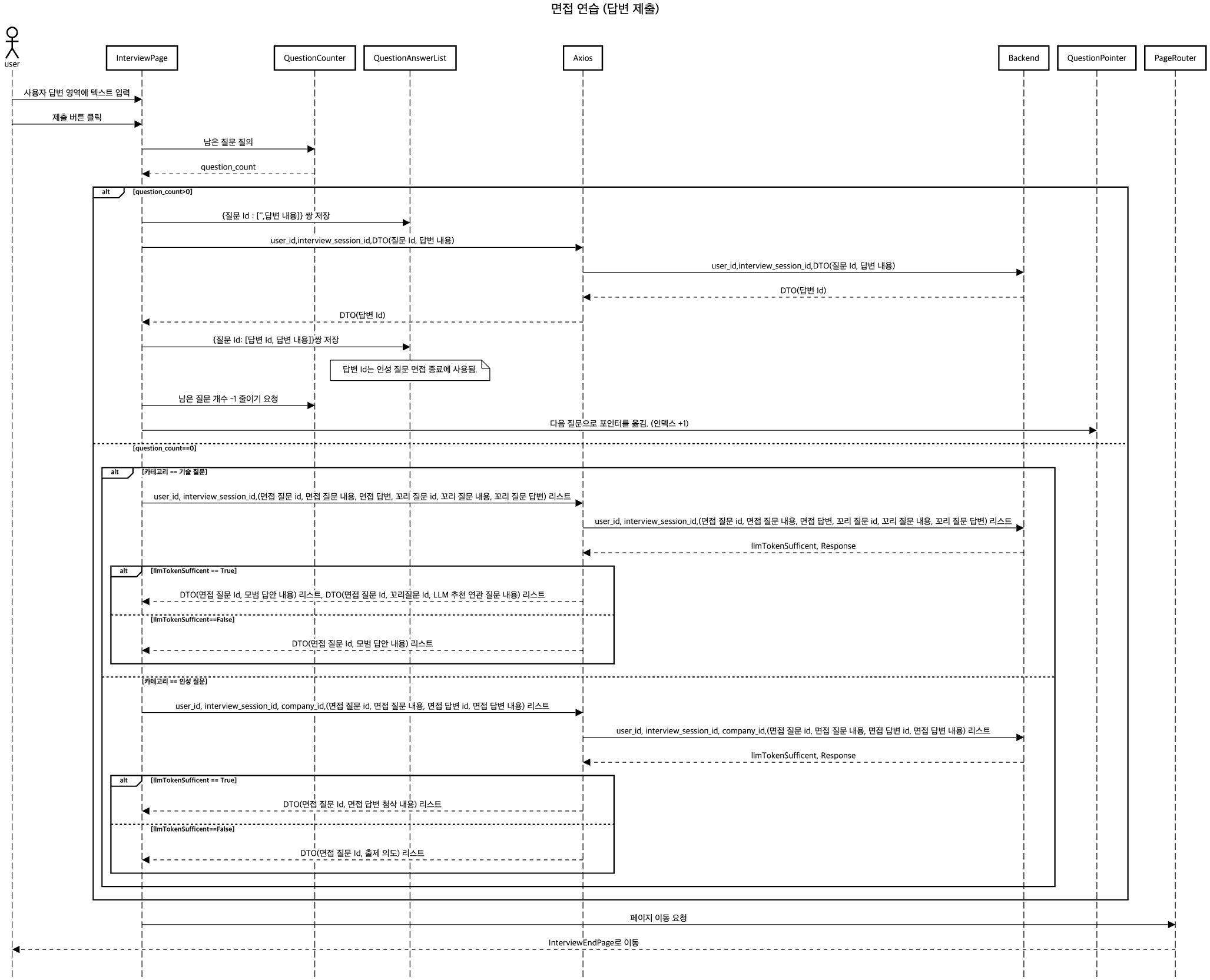
답변 제출 시나리오
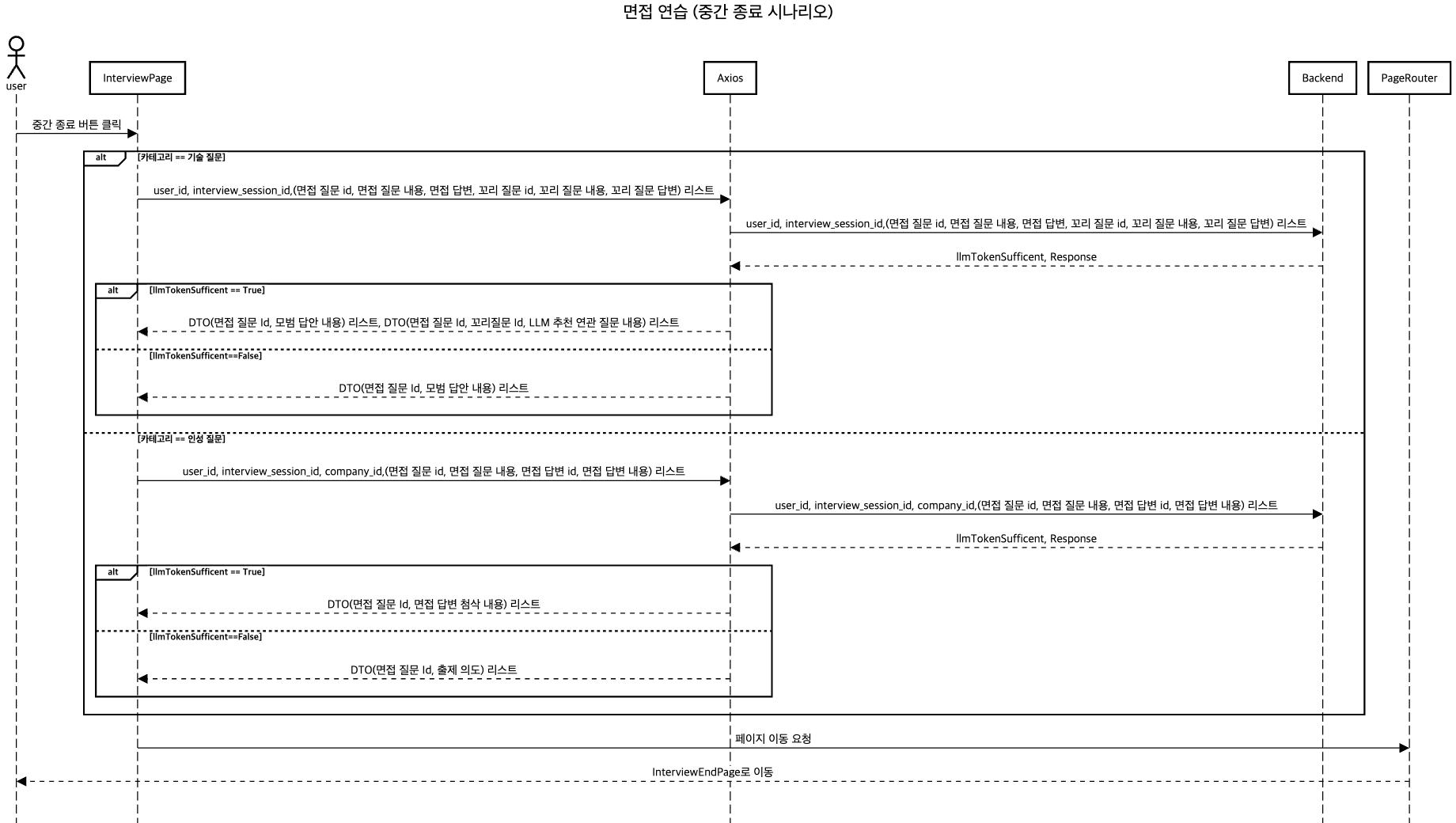
중간 종료 시나리오
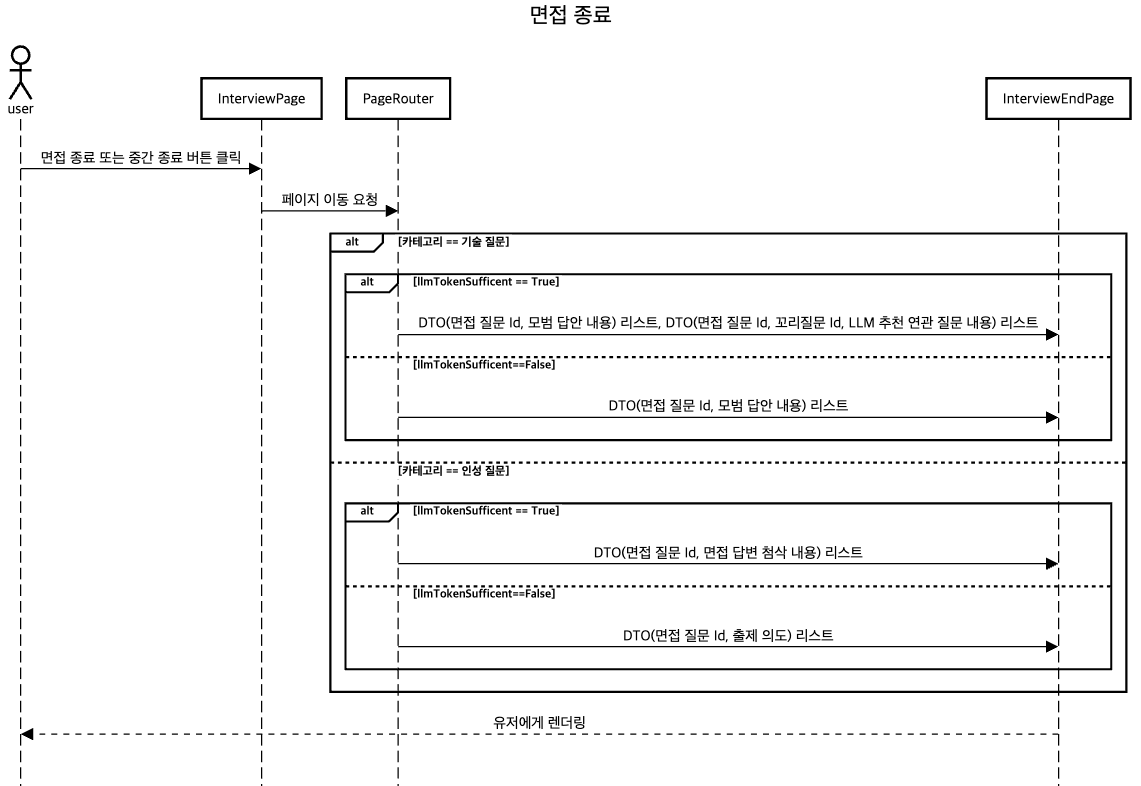
면접 종료 화면
API Endpoint 설계
면접 질문 출제
면접 질문 출제는 백엔드 내에 저장된 질문을 조회하는 것이므로 GET으로 했습니다.
기술 질문 출제의 경우
GET /interview-questions?category=tech&keyword=db
인성 질문 출제의 경우
GET /interview-questions?category=fit&keyword=leadership&company=velog상태 코드
200 : 클라이언트 요청 정상 수행
400 : 클라이언트 요청이 부적절할 경우
403 : 인증되지 않은 사용자가 사용했을 경우
500 : 서버 내 문제
사용자 답변 저장
서버 내에 사용자 답변을 새로이 저장하는 것이므로 POST로 했습니다.
또한 사용자와 면접 회차, 답변이 has 관계를 가지므로 /리소스명/리소스 id/ 관계가 있는 다른 리소스 명으로 지정했습니다.
POST /users/{userid}/interview-sessions/{interviewsessionid}/answer상태 코드
200 : 클라이언트 요청 정상 수행
400 : 클라이언트 요청이 부적절할 경우
403 : 인증되지 않은 사용자가 사용했을 경우
500 : 서버 내 문제
면접 종료
사용자의 면접이 종료되었음을 나타내는 이름으로 지었습니다.
토큰이 충분한 상황에서는 LLM에게 생성을 요청하고, 그렇지 않은 예외 상황에서는 서버 DB에서 조회하는 API입니다.
이 API는 HTTP 메서드를 무엇으로 할지 조금 고민이 되었습니다. 최종적으로는 POST로 결정했습니다.
일반적인 상황에서는 서버에게 데이터 처리 및 생성을 요청하기 때문입니다. 서비스를 정상 사용할 수 없는 경우에만 임시 방편으로 DB에서 조회해오는 것이기 때문입니다.
GET으로 먼저 토큰이 충분한 지 조회하고 나서 POST와 GET으로 나눠서 요청하는 방법도 있겠습니다만, 일반적인 상황에선 API Call을 2번이나 하게 되어 서버에 부하가 되지 않을까 싶었습니다.
POST /users/{userid}/interview-sessions/{interviewsessionid}/completion상태 코드
200 : 클라이언트 요청 정상 수행
400 : 클라이언트 요청이 부적절할 경우
403 : 인증되지 않은 사용자가 사용했을 경우
500 : 서버 내 문제
503 : LLM 토큰이 부족해서 기술 연관 질문 소개, 인성 면접 답변 첨삭 서비스를 사용할 수 없는 상황인 경우
참고 자료
https://url.kr/l1hdk3
https://url.kr/yhi6ar
https://developer.mozilla.org/ko/docs/Web/HTTP/Status
