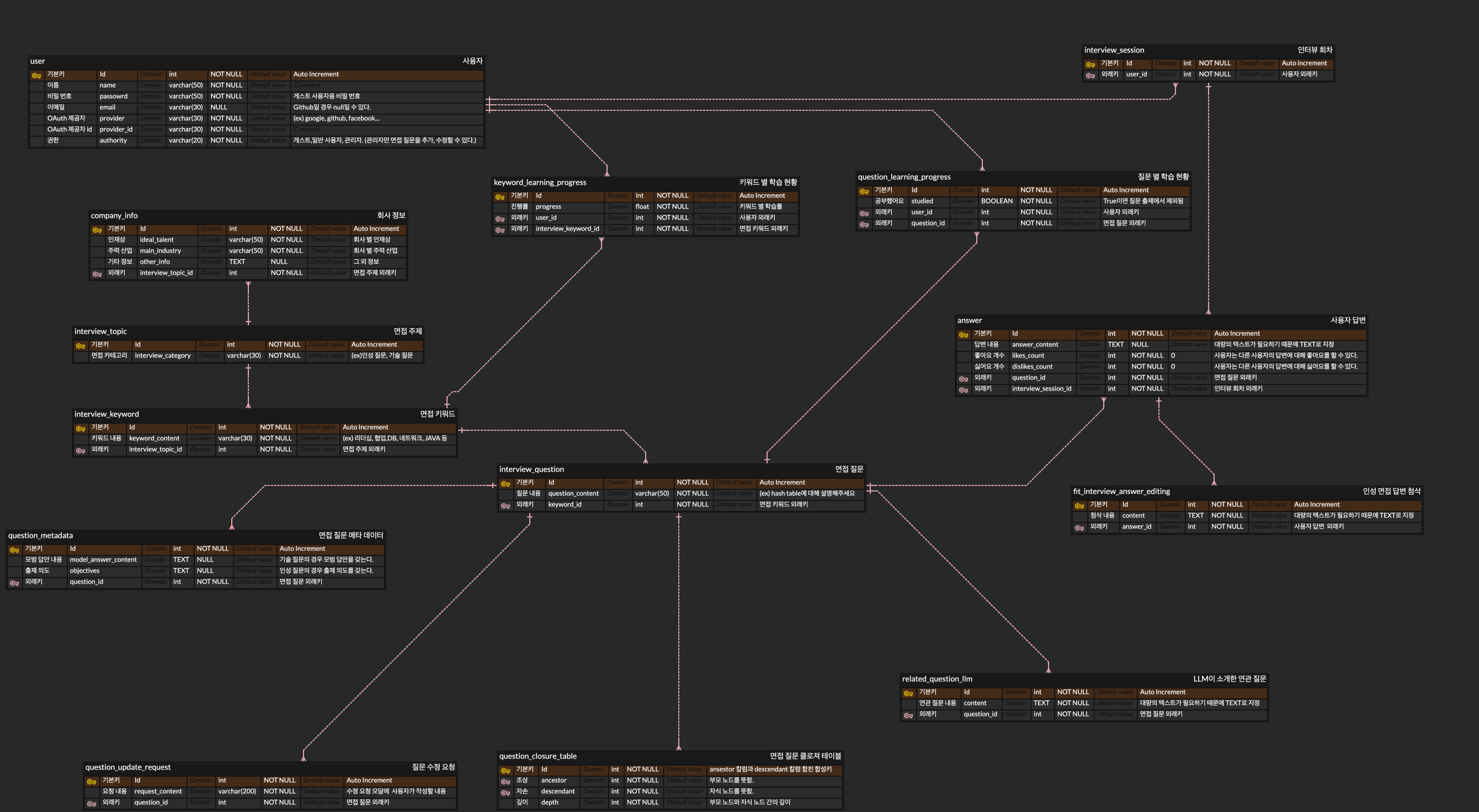
데이터 모델링(엔터티-관계 다이어그램 작성 + 정규화)
1차
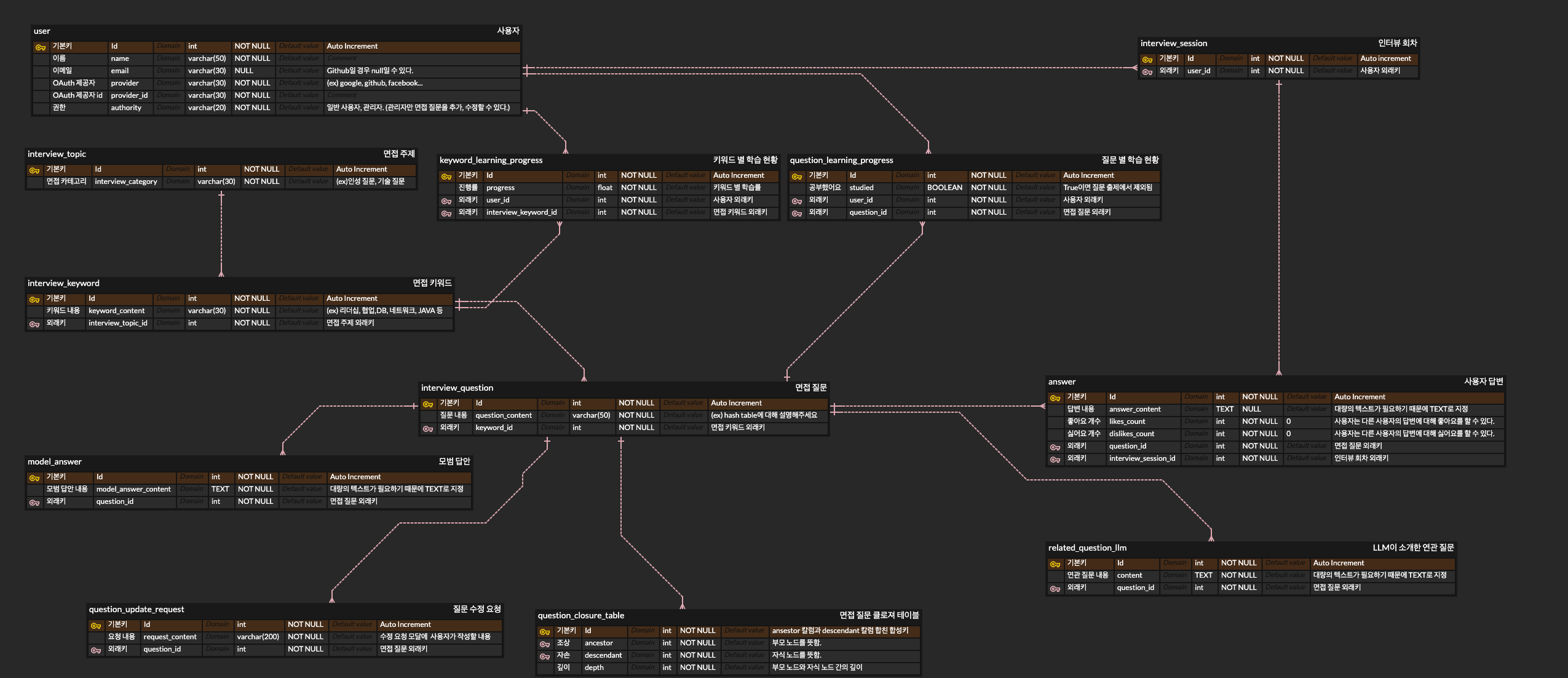
테이블 관계
- 사용자는 여러 개의 질문을 받을 수 있다.
- 면접 질문 역시 여러 명의 사용자에게 출제될 수 있다.
- 인터뷰 회차는 1.과 2.에 의해 다대다 테이블로 활용한다.
- 면접 주제는 여러 개의 면접 키워드를 가질 수 있다. (ex : 인성 질문은 리더십, 협업 등 여러가지 키워드를 가질 수 있다.)
- 면접 키워드는 여러 개의 면접 질문을 가질 수 있다.
- 면접 질문은 최대 깊이 2의 꼬리 질문을 가질 수 있다.
- 면접 질문은 여러 개의 면접 답변을 가질 수 있다.
- 면접 답변은 1개의 면접 평가를 가질 수 있다.
- 사용자는 여러 개의 면접 답변을 할 수 있다.
- 면접 질문은 여러 개의 수정 요청을 받을 수 있다.
varchar와 TEXT 중 선택하기
면접 카테고리, 면접 키워드 내용은 대체로 짧기 때문에 varchar를,
모범 답안, 답변 내용은 길다고 생각하여 TEXT를 선택했습니다.
그리고 면접 카테고리와 면접 키워드는 조회될 경우가 모범 답안, 답변 내용보다 많을 것이므로 조회 성능이 더 뛰어난 varchar를 선택했습니다.
식별 관계와 비식별 관계 중 선택하기
식별 관계는 부모 테이블의 기본키를 자식 테이블이 자신의 기본키로 사용하는 관계이기 때문에, 부모가 없으면 자식도 존재할 수 없습니다. 그래서 데이터의 정합성은 높아지지만, 요구사항이 변경될 경우 구조 변경이 어렵습니다.
반면 비식별 관계는 요구사항 변경에도 구조를 쉽게 바꿀 수 있지만 데이터 무결성을 보장하지 않습니다.
데이터 정합성을 애플리케이션 로직으로 강제하는 것과 요구 사항이 바뀌어서 ERD 구조를 뜯어고쳐야 하는 것중, 리스크가 더 큰 것은 식별관계입니다. 따라서 그런 리스크를 줄이기 위해 비식별 관계를 선택했습니다.
문제점 추측하기
그린 후에 바로 느껴지는 문제점은 2가지인 것 같습니다.
-
면접 주제, 면접 키워드, 면접 질문, 꼬리 질문은 계속 일대다 관계를 맺고 있습니다. 혹시 join이 많이 필요한 쿼리가 있을지 검증해봐야 할 것 같습니다. (외래키로 계속 연결되고 있기 때문)
-
면접 질문은 최대 깊이(레벨) 2의 꼬리질문을 가진다는 조건이 ERD로 제대로 표현이 안되는 것 같습니다. 그리고 위 ERD처럼 그리면 레벨이 추가될 때마다 수정 요청 테이블, 답변 테이블, 평가 테이블이 계속 추가됩니다. 뭔가 지저분해보이고, 확장성도 별로 안좋은 것 같습니다.
원하는 테이블 관계
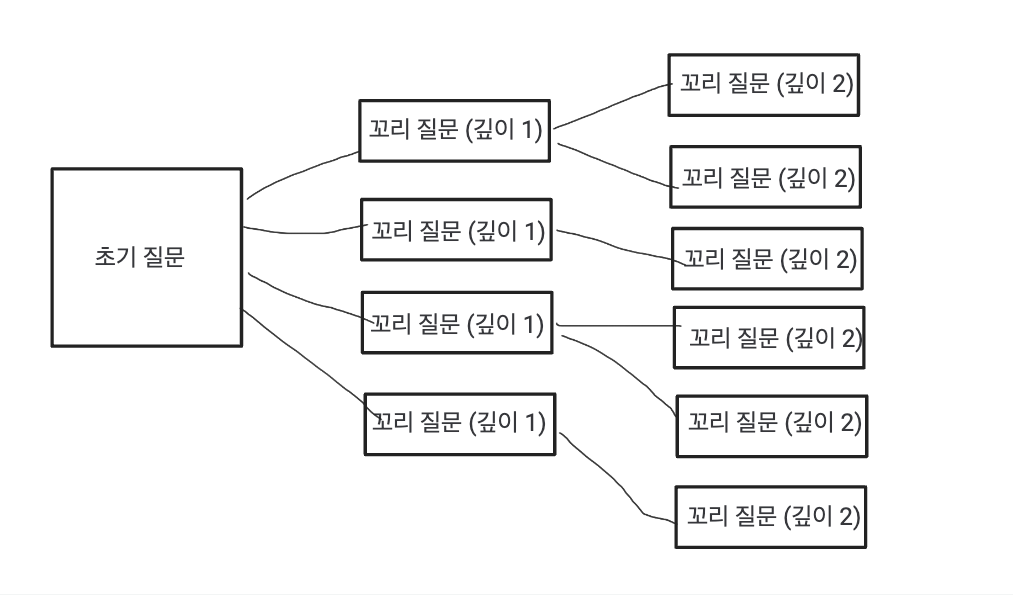
초기 질문은 여러 개의 꼬리 질문 레벨1을 갖고, 꼬리 질문 레벨 1은 여러 개의 꼬리 질문 2를 갖습니다.
딱 보았을 때, 트리와 같은 형태입니다.
계층형 데이터 구조 설계
트리와 같은 데이터 구조는 어떻게 설계해야 하는 지 검색하다가 계층형 데이터 구조로 불림을 알게 되었습니다.
찾다보니 4가지 방식이 있네요.
첫 째는 Adjacency List 방식으로 테이블 A에 단순히 parent_id를 넣어 테이블 A 내 다른 로우를 찾아내는 단순한 방법입니다. 그런데 이 방식은 트리의 깊이가 깊어질수록 join이 많아지고 성능이 떨어진다고 합니다. 그래서 해당 방식은 선택하지 않았습니다.
두 번째는 Path Enumeration 방식으로, path라는 칼럼에 1/2/3... 과 같이 /라는 구분자로 경로를 만드는 방식입니다. 이 방식은 계층 구조를 변경할 때 String parsing 후 고쳐내야 합니다. 그리고 잘못된 path가 발생할 경우 찾아내기 어렵습니다.
세 번째는 nested set 방식인데, 앞의 두방식보단 쿼리의 수가 줄어들지만 left와 right이라는 칼럼을 따로 두기 때문에 해당 칼럼에 잘못된 값이 들어가면 골치 아파진다고 합니다.
마지막은 closure table 방식입니다. 해당 방식은 anscetor, descendant 칼럼을 사용하는데 해당 칼럼이 실제 기본키를 참조하므로 잘못된 값이 들어갈 일이 없다고 합니다. 또한 트리의 깊이가 깊더라도 쿼리가 간결해집니다.
종합한 표를 보니, closure table이 전반적으로 우수해서 해당 방식을 이용하기로 했습니다. (물론, 테이블이 2개 필요하다는 단점이 있습니다.)
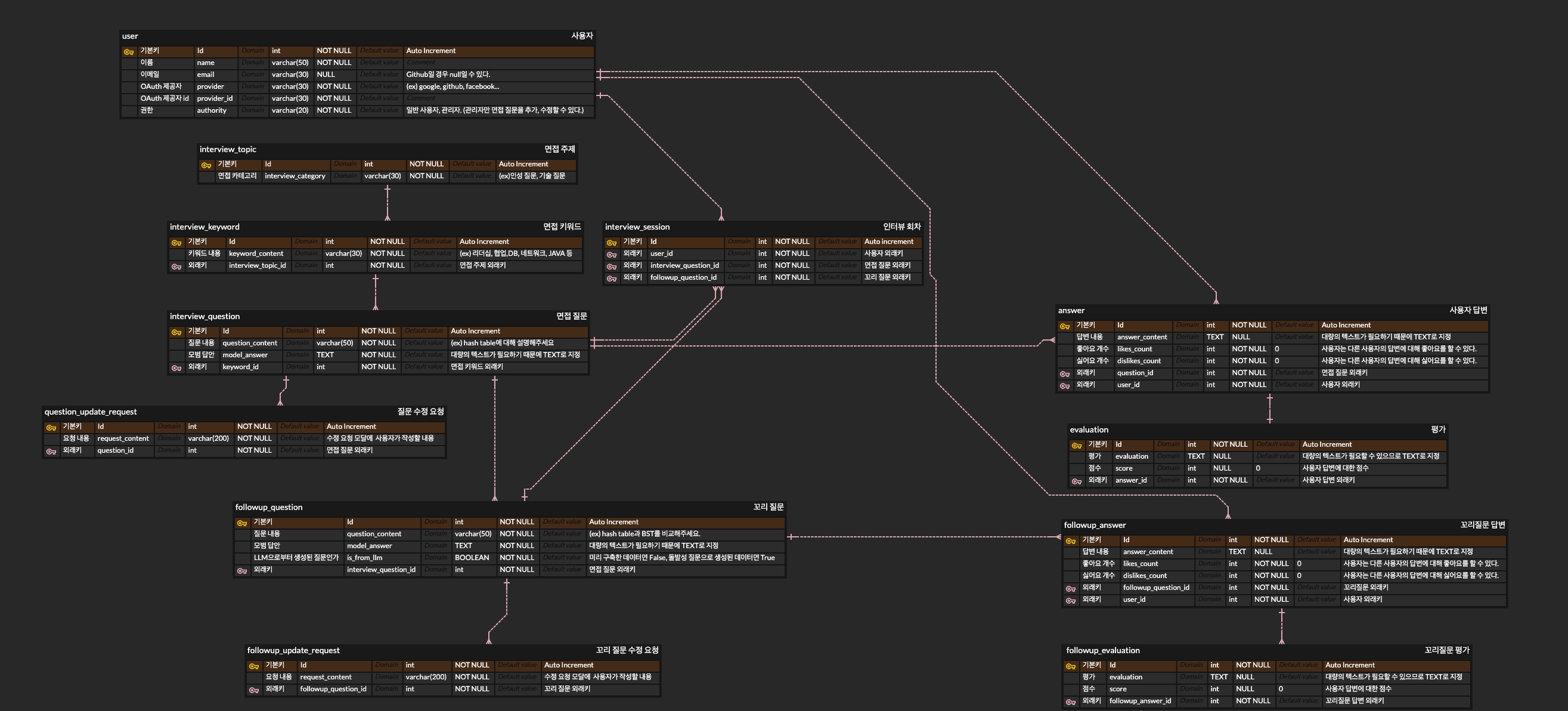
2차 (개선하기)
정규화 적용
꼼꼼히 짚어보니, 면접 질문 내 칼럼으로 모범 답안이 제3 정규형을 어기고 있었습니다. 기본키가 아닌 질문 내용이 바뀌면, 모범 답안도 바뀌어야 하기 때문입니다.
그리고 잘 생각해보니, 질문 하나에 대해 여러 가지 모범답안이 있을 수 있겠다 싶었습니다. 그래서 일대다 관계로 테이블을 하나 더 만들었습니다.
테이블 관계 수정
기존에는 회차마다 여러 개의 질문을 가졌었는데, 이는 질문이 회차에 대한 외래키를 가져야함을 뜻합니다. 즉 질문 내용은 같은데 회차만 다른 질문들이 생기게 되므로 지저분해집니다.
반면 바뀐 관계에선 사용자는 여러 회차를 가지고, 회차마다 여러 개의 답변을 합니다. 한 질문은 여러 개의 답변을 갖습니다. 즉, 답변 테이블이 다대다 테이블이 되었습니다.
클로져 테이블 추가
위에서 설명한대로, 계층형 데이터 구조를 위한 클로져 테이블을 추가했습니다.
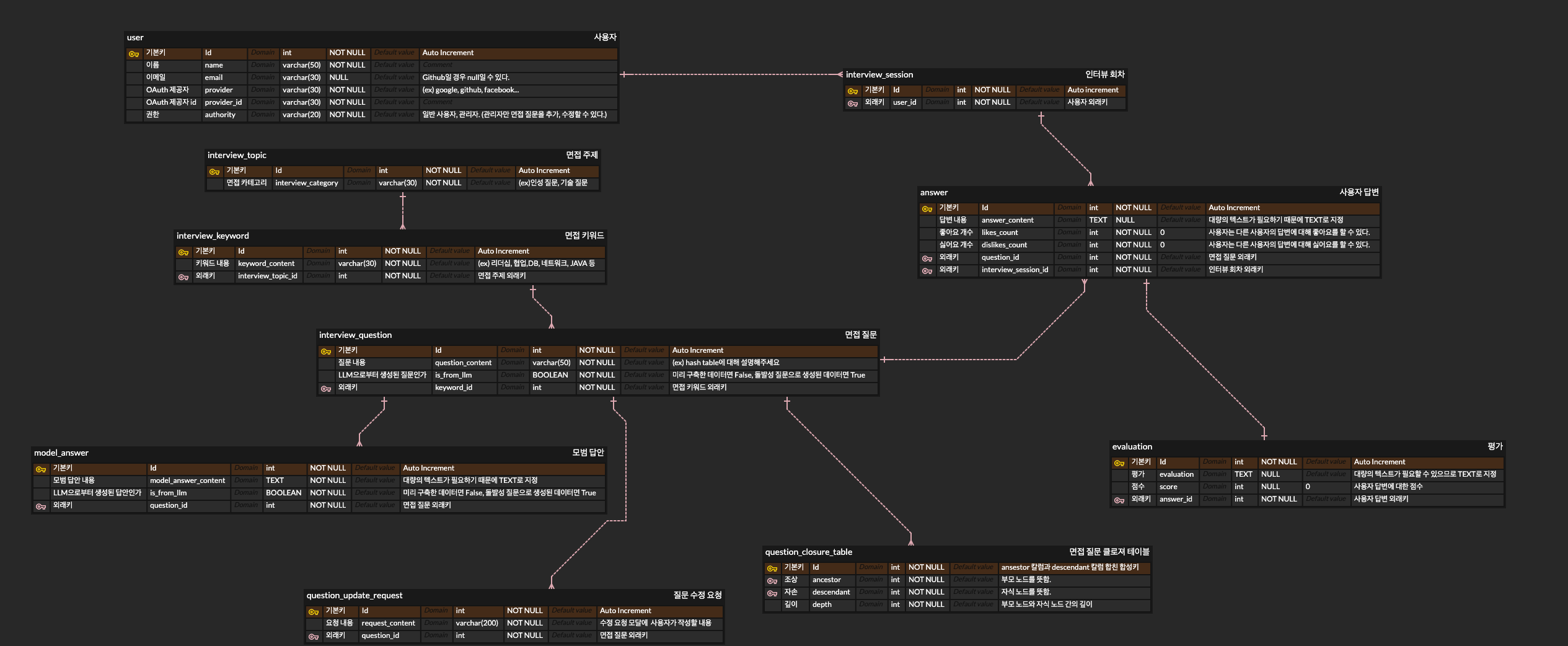
3차 (LLM 사용 방향 바꾸고 나서)
질문과 모범 답안에 대해 LLM이 개입하는 것은 폐기했습니다. 왜냐하면 제대로 출력 양식을 지킬지 의문이고, 검수가 되지 않은 채로 퀄리티가 떨어지는 텍스트가 실시간으로 출력될 수 있으며, 중복 질문이 현재 인터뷰 세션에 나올 경우 제외해야 하는 비즈니스 로직을 만들어야하기 때문입니다.
LLM은 창의적이지, 논리적이지 않습니다.
LLM을 규제하고 제어하려는 노력을 하기보다는, 생성과 창의성에 어울리는 일에 LLM을 활용하기로 결정했습니다. 그래서 면접 질문 데이터를 구축하거나, 출제되었던 질문들에 대해 나올 수 있는 질문들을 추천하는데 사용하기로 했습니다.
추가적으로 사용자는 키워드 별로 학습률을 확인할 수 있고, 질문 별로 학습 체크를 할 수 있게 ERD를 추가했습니다.
4차 (인성 면접 답변 첨삭 기능 추가)
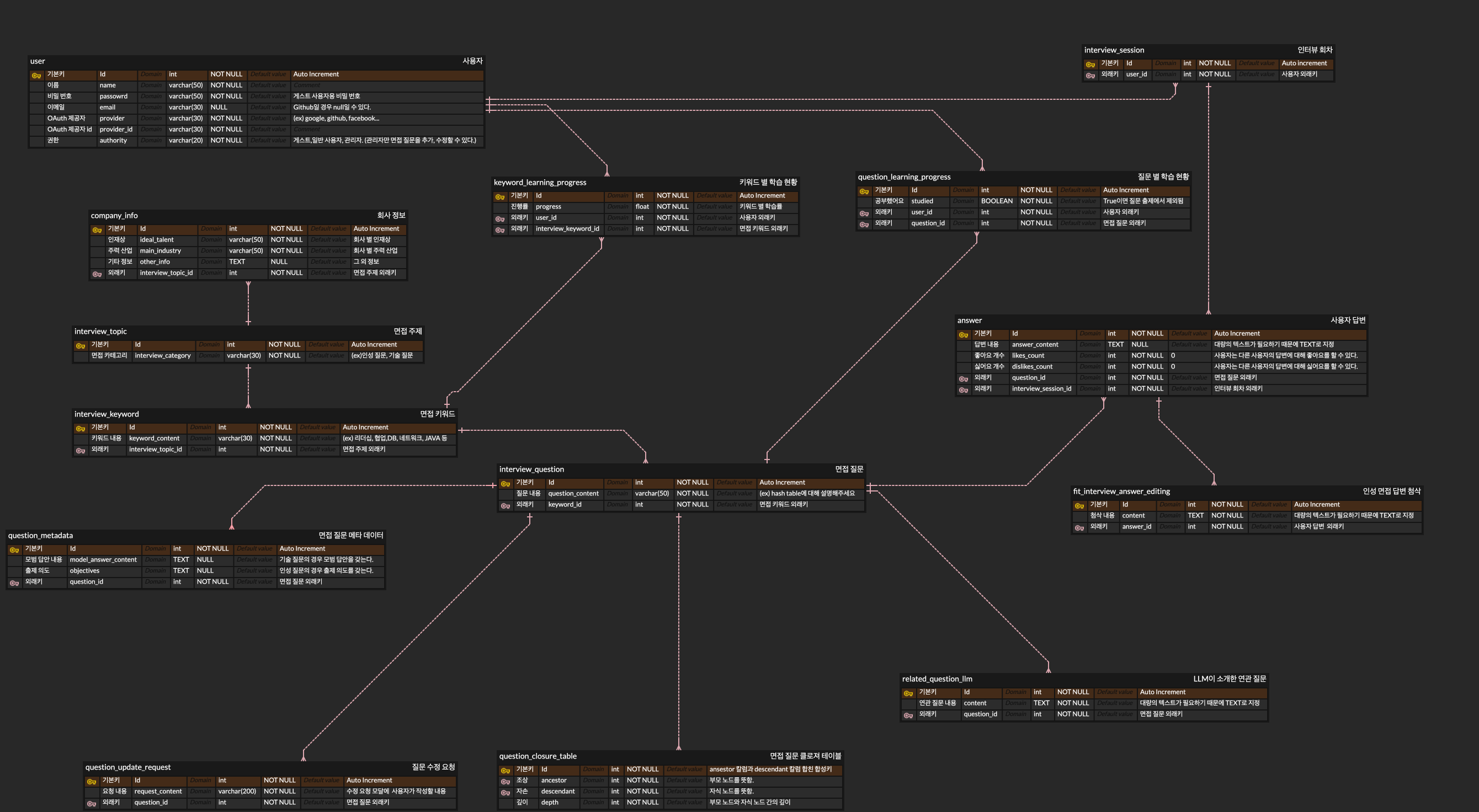
이전에 소마 연수생들이 모뷰에 피드백했던 것 중, 인성 면접만 대비할 수는 없겠느냐는 피드백도 있었습니다. 그래서 <회사 정보, 출제 의도, 인성 면접 질문, 사용자 답변>을 입력으로 LLM을 활용하면, 그럴듯한 면접 답변 첨삭이 될거라 생각했습니다. 그래서 관련 테이블들을 추가했습니다. (회사 정보 테이블, 인성 면접 답변 첨삭)
뿐만 아니라 빠른 비즈니스 로직 개발을 우선 구현하기 위해서 게스트 로그인을 추가했습니다.
도메인 규칙 정리
- 면접 키워드가 인성 질문이었던 답변에 대해서만 인성 질문 첨삭을 한다.
- 면접 키워드가 기술 질문인 질문에 대해서만 LLM이 연관 질문을 소개한다.
- 기술 질문에 대해서만 꼬리 질문을 출제한다. 인성 질문에 대해서는 꼬리 질문을 출제하지 않는다.
- 기술 질문에 대해 연관 질문을 소개할 때, 초기 질문과 꼬리질문 레벨 1 각각에 모두 적용한다.
- 기술 질문은 모범 답안을 가지며, 인성 질문은 출제의도를 가진다. (전자는 답이 어느 정도 정해져있지만, 후자는 사람의 경험마다 다르기 때문.)
참고
DB 명명 규칙
https://sabarada.tistory.com/49
varchar vs TEXT
https://cobook.tistory.com/60
https://www.scaler.com/topics/varchar-vs-text-mysql/
식별 관계 , 비식별 관계
https://deveric.tistory.com/108
계층형 구조 설계
https://www.slideshare.net/billkarwin/models-for-hierarchical-data
https://journey-to-serendipity.tistory.com/39
https://annahxxl.tistory.com/5
데이터 무결성
