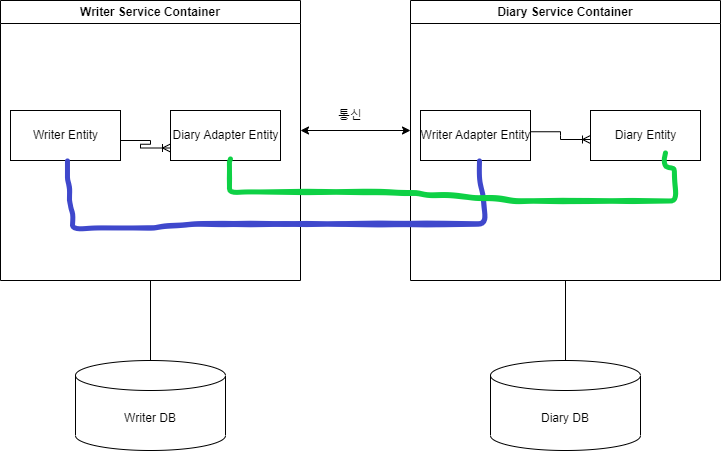
기존 모놀리식 안에서의 관계
Writer 1명이 Diary 여러 개를 가지는 일대다의 관계이다.
대략적인 코드
Writer
@Entity
@Table(name = "Writer", uniqueConstraints = @UniqueConstraint(columnNames = {"writer_id", "name"}))
public class Writer extends BaseTimeEntity {
@Id
@Column(name = "writer_id", columnDefinition = "bigint default 0", nullable = false, unique = true)
private Long writerId;
@OneToMany(mappedBy = "writer", cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private final Set<DiabetesDiary> diaries = new HashSet<>();
... 여러가지 프로퍼티들 ...
}Diary
@Entity
@Table(name = "DiabetesDiary", uniqueConstraints = @UniqueConstraint(columnNames = {"diary_id"}))
@IdClass(DiabetesDiaryId.class)
public class DiabetesDiary extends BaseTimeEntity {
@Id
@Column(name = "diary_id", columnDefinition = "bigint default 0")
private Long diaryId;
@Id
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "writer_id")
private Writer writer;
... 여러가지 프로퍼티들 ...
}시도하고자 하는 것
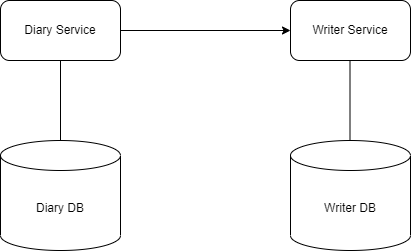
두 개의 마이크로 서비스로 분할하고 통신하는 것
예상되는 문제
JPA 연관 관계를 맺는 엔티티들을 각각의 마이크로 서비스에 분할한다고 하자. 단순히 복붙으로 넣는다면, 당연히 실행이 안될 것이다.
왜냐하면 컴파일러가 @OneToMany와 @ManyToOne에 해당하는 엔티티가 존재하지 않는다고 알릴 것이기 때문이다.
나름대로 생각해본 해결책
마이크로 서비스끼리 외래키와 관련된 통신을 할 수 있으면서도, 컴파일 타임 내에 뻗지 않는 방법은 무엇일까 고민해봤다.
생각난 것은 어댑터 엔티티를 만드는 것이었다.
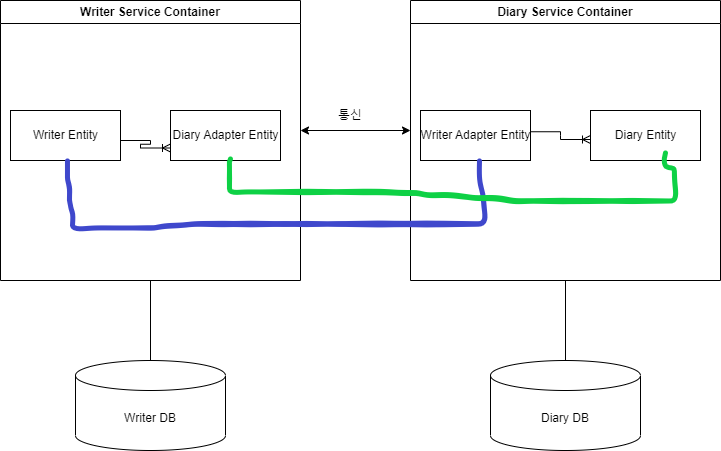
어댑터 엔티티는 원래 엔티티에서 다른 속성을 모두 제거하고 기본키, 외래키, 연관 관계 정보만 추출한 엔티티이다.
오로지 마이크로 서비스끼리의 통신을 위한 역할이므로 DTO라 비슷한 느낌인데 흠... 좀 찝찝한 느낌이 난다.
그리고 DB에 어댑터 엔티티 정보도 중복 저장해야 하는 문제점을 갖고 있다.
일단 이걸로 해보고 다른 방법은 없는지도 찾아봐야겠다.
다른 글도 참고해보다.
참고 링크
이 링크를 참고해보니, 엔티티 자체를 연관 관계로 맺지 않고 id 값으로 참조하고 있었다. 이렇게 한다면, 내가 생각했던 방법보다 공간 복잡도가 많이 줄어든다.
왜냐하면 내 방법의 경우 id가 Long 일 경우, 해당되는 개수에 따라 (8n+@)N 바이트가 든다.
반면 위 링크의 경우는 단순히 외래키 값인 id만 있으면 되므로 8*N 바이트가 들기 때문에 DB용 디스크 공간을 많이 절약할 수 있을 것이다. (n은 id 프로퍼티 개수, N은 로우의 개수, @는 id 이외의 프로퍼티 개수를 뜻한다.)
두 서비스간 상호작용 만들기
1. 서비스 디스커버리 구현
eureka-server.yml 구성
git 외부 저장소에 아래 yml 파일을 작성 및 푸시한다. 컨피그 서버는 아래 yml 파일을 읽고 유레카 서버 구성 정보를 로드한다.
server:
port: 8070
eureka:
instance:
hostname: eurekaserver
client:
# config server를 유레카 서비스에 등록하지 않게 설정
registerWithEureka: false
# config server가 캐시 레지스트리 정보를 로컬에 캐시하지 않게 설정
fetchRegistry: false
serviceUrl:
# 모든 클라이언트에 대한 서비스 url 제공
defaultZone:
http://${eureka.instance.hostname}:${server.port}/eureka/
server:
# 서버가 요청을 받기 전 초기 대기 시간 설정
waitTimeInMsWhenSyncEmpty: 5
management:
endpoints:
web:
exposure:
include: "*"유레카 서버 내 bootstrap.yml 작성
유레카 서버는 아래 구성 정보를 보고 컨피그 서버의 위치를 알아낼 수 있게 된다.
spring:
application:
name: eureka-server
cloud:
config:
uri: http://configserver:8071
loadbalancer:
ribbon:
enabled: false유레카 서버 관련 의존성 추가
클라이언트 측 로드밸런싱 의존성도 추가한다.
이 client-side loadbalancing을 활용하면, 서비스 클라이언트가 서비스를 호출 할 때 먼저 로컬 캐시에서 서비스 인스턴스 ip 주소를 확인한다.
이 방식을 활용하면 서비스 디스커버리에 전적으로 의존하지 않게 되서 단일 장애 지점문제에 대비가 된다. 그리고 서비스 디스커버리의 부하도 줄일 수 있다.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
유레카 서버 어노테이션 부착
@EnableEurekaServer
@SpringBootApplication
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
docker-compose.yml 에 유레카 서버 컨테이너 추가
유레카 서버는 컨피그 서버 이후에 시작되야 하므로 depends_on을 활용해서 선후 관계를 지정해줘야 한다.
eurekaserver:
image: msa/eureka-server:0.0.1-SNAPSHOT
ports:
- "8070:8070"
depends_on:
- configserver
networks:
backend:
aliases:
- "eurekaserver"2. 작성자 서비스 대략 구현
작성자 서비스에 msa 관련 의존성 추가
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>컨피그 서버와 통신하기 위한 의존성과 유레카 서버와 통신하기 위한 의존성을 추가한다. 참고로 후자는 일지 서비스에도 의존성을 추가해야 한다.
3. 두 서비스 간의 연결
각 마이크로 서비스들에 설정 추가.
외부 git 저장소에 있는 마이크로 서비스 properties들에 다음 내용들을 추가한다.
#서비스 이름 대신 서비스 ip 주소로 등록하겠다고 지정
eureka.instance.preferIpAddress = true
# 유레카 서비스의 위치 지정
eureka.client.serviceUrl.defaultZone = http://eurekaserver:8070/eureka/유레카 서버 등록 확인
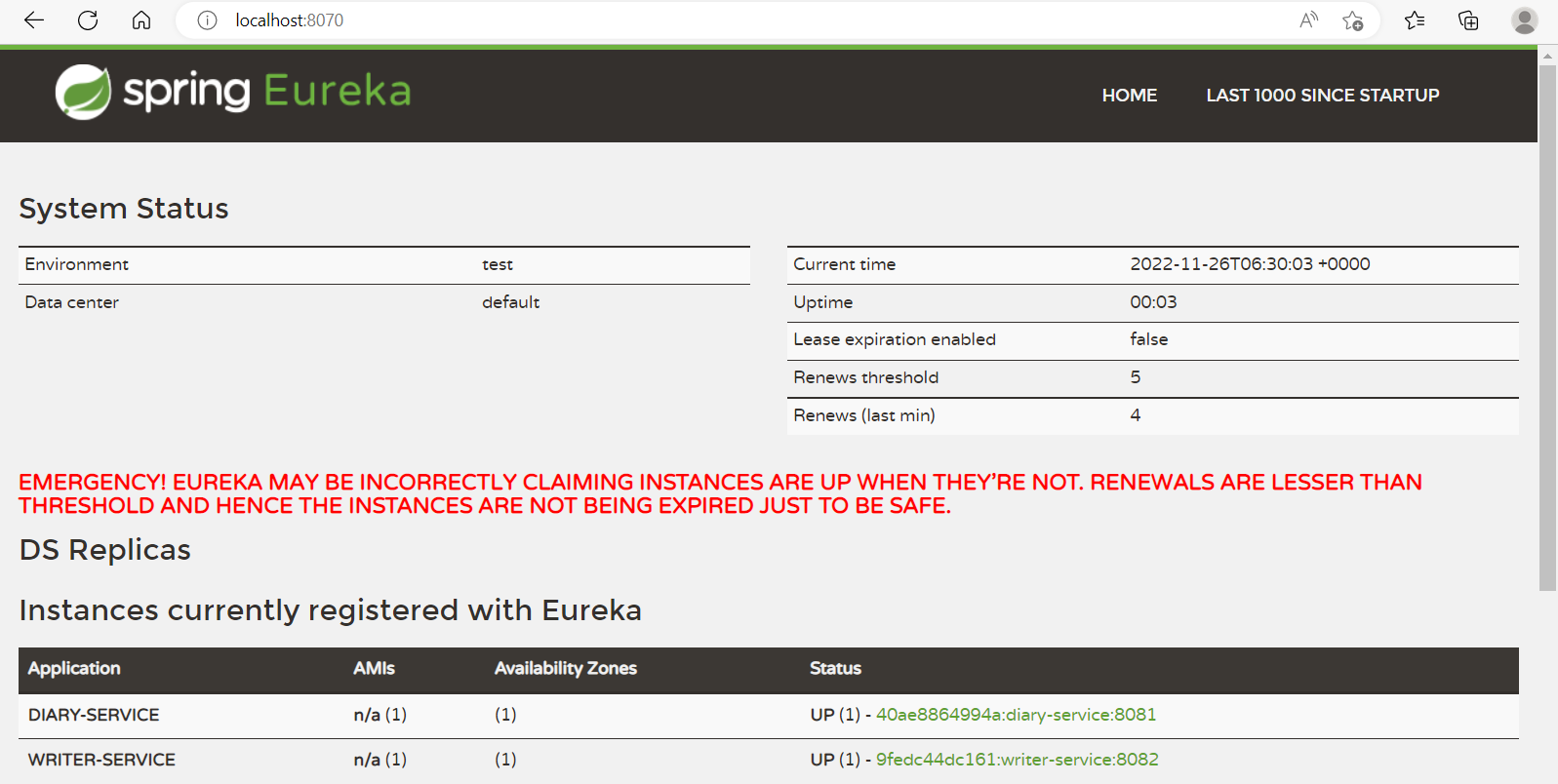
4.마이크로 서비스 간의 연결
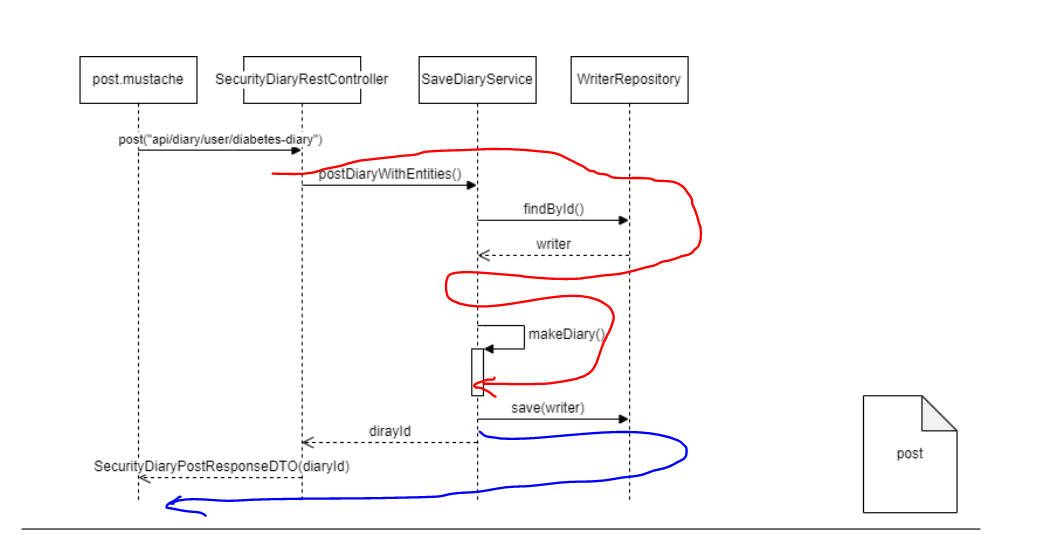
빨간 색 부분은 https://github.com/dasd412/DiabetesDiary-MSA/commit/d76bb7e7c6fbf068c8675ab24c4a14bc30370266 기준에서 테스트용 코드로 구현한 부분이다. 파란색 부분은 아직 구현 안했다. 나중에 마저 구현해야겠다.
일지 서비스에 의존성 및 어노테이션 추가
일지 저장 로직에서 일지 서비스는 작성자 서비스를 호출하는 클라이언트다.
다른 마이크로 서비스를 호출하는 도구로 넷플릭스 Feign 클라이언트를 사용했다.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>@EnableFeignClients
@SpringBootApplication
public class DiaryServiceApplication {
public static void main(String[] args) {
SpringApplication.run(DiaryServiceApplication.class, args);
}
}일지 엔티티에 작성자 외래키 추가
@Entity
@Table(name = "DiabetesDiary", uniqueConstraints = @UniqueConstraint(columnNames = {"diary_id"}))
public class DiabetesDiary extends BaseTimeEntity {
@Id
@GeneratedValue
@Column(name = "diary_id", columnDefinition = "bigint default 0")
private Long diaryId;
private Long writerId;
}모놀리식 프로젝트에서 JPA 다대일에 해당하는 관계였다.
작성자 마이크로 서비스에 컨트롤러 추가
@RestController
public class SecurityWriterController {
...
@GetMapping("/writer/{writerId}")
public ResponseEntity<Long> findWriterTest(@PathVariable("writerId") Long writerId) {
Writer found = findWriterService.findWriterById(writerId);
return ResponseEntity.ok(found.getId());
}
}작성자 마이크로 서비스가 받을 수 있는 url을 지정한다.
이 url은 일지 서비스의 feign 클라이언트의 url과 동일해야 한다.
나중에 writerId는 스프링 시큐리티 세션 식별자로 교체할 예정이다.
일지 서비스에 feign 클라이언트 추가
@FeignClient("writer-service")
public interface FindWriterFeignClient {
@RequestMapping(method= RequestMethod.GET,value="/writer/{writerId}",consumes = "application/json")
Long findWriterById(@PathVariable("writerId")Long writerId);
}일지 마이크로 서비스는 이 코드를 이용해 작성자 마이크로 서비스를 호출할 수 있다.
일지 서비스에 일지 저장 로직 작성
@Service
public class SaveDiaryService {
private final FindWriterFeignClient findWriterFeignClient;
@Transactional
public Long postDiaryWithEntities(SecurityDiaryPostRequestDTO dto) {
Long writerId=findWriterFeignClient.findWriterById(dto.getWriterId());
DiabetesDiary diary = new DiabetesDiary(writerId, dto.getFastingPlasmaGlucose(), dto.getRemark());
diaryRepository.save(diary);
return diary.getId();
}
}빌드하고 도커 컴포즈 실행한 후, 일지 마이크로 서비스의 컨트롤러 url을 postman으로 호출해보니 두 마이크로 서비스 모두를 경유함을 확인할 수 있었다.
