📔설명
소트 튜닝, DML 튜닝, 데이터베이스 Call 최소화, 파티셔닝, 대용량 배치 프로그램 튜닝, 고급 SQL 활용에 대해 알아보자
🥧소트 튜닝
1. 소트와 성능
메모리 소트와 디스크 소트
소트 오퍼레이션이 필요할 때마다 DBMS는 정해진 메모리 공간에 소트 영역(Sort Area)을 할당하고, 정렬 수행
=> Oracle : PGA
=> SQL Server : 버퍼 캐시
소트에 필요한 메모리 공간이 부족하면 디스크 사용
=> Oracle : Temp Tablespace
=> SQL Server : tempdb

소트를 발생시키는 오퍼레이션
Sort Aggregate:전체 로우를 대상으로집계수행시
=>SORT (AGGREGATE)라고 표현
=> 실제소트 발생 X
=>SQL Server:Stream Aggregate
select sum(sal), max(sal), min(sal) from emp;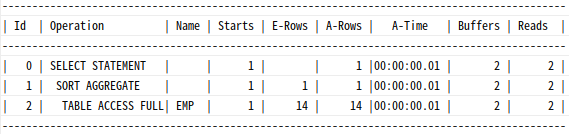
--sql server
StmtText
-------------------------------------------------------------
|--Compute Scalar(DEFINE:([Expr1004]=CASE WHEN [Expr1014]=(0)THEN NULL ELSE [Expr1015] END))
|--Stream Aggregate(DEFINE: )
|--Table Scan(OBJECT:([SQLPRO].[dbo].[emp]))Sort Order By:정렬된 결과 집합을 얻고자 할 때
select * from emp order by sal desc;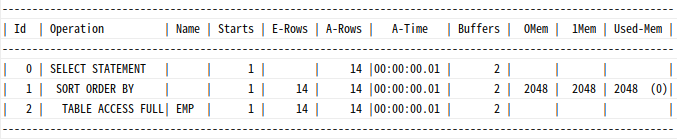
StmtText
------------------------------------------------------
|--Sort(ORDER BY:([SQLPRO].[dbo].[emp].[sal] DESC))
|--Table Scan(OBJECT:([SQLPRO].[dbo].[emp]))Sort Group By:Sorting알고리즘을 사용해그룹별 집계수행시
select deptno, job, sum(sal), max(sal), min(sal)
from emp
group by deptno, job;Execution Plan
-------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=4 Card=11 Bytes=165)
1 0 SORT (GROUP BY) (Cost=4 Card=11 Bytes=165)
2 1 TABLE ACCESS (FULL) OF 'SCOTT.EMP' (TABLE) (Cost=3 Card=14 Bytes=210)StmtText
-------------------------------------------------------------
|--Compute Scalar(DEFINE:([Expr1004]=CASE WHEN [Expr1014]=(0) THEN NULL ELSE [Expr1015] END))
|--Stream Aggregate(GROUP BY: )
|--Sort(ORDER BY:([SQLPRO].[dbo].[emp].[deptno] ASC, [SQLPRO].[dbo].[emp].[job] ASC))
|--Table Scan(OBJECT:([SQLPRO].[dbo].[emp]))오라클은 Hashing 알고리즘으로 그룹별 집계 수행하기도 함
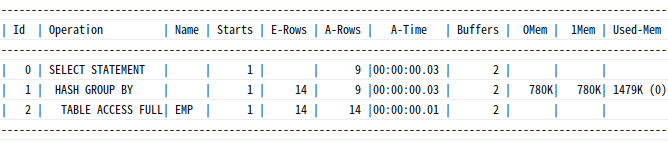
Sort Unique: 결과 집합에서중복레코드를제거할 때
=>Union연산자 또는Distinct연산자 사용시
select distinct deptno
from emp
order by deptno;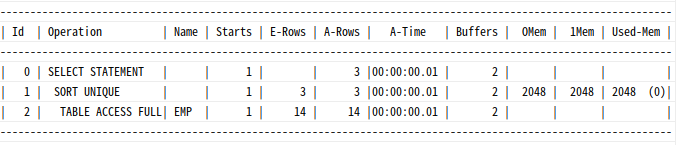
StmtText
-------------------------------------------------------------
|--Sort(DISTINCT ORDER BY:([SQLPRO].[dbo].[emp].[deptno] ASC))
|--Table Scan(OBJECT:([SQLPRO].[dbo].[emp]))Sort Join:소트 머지 조인수행시
select /*+ ordered use_merge(d) */ *
from emp e, dept d
where d.deptno = e.deptno;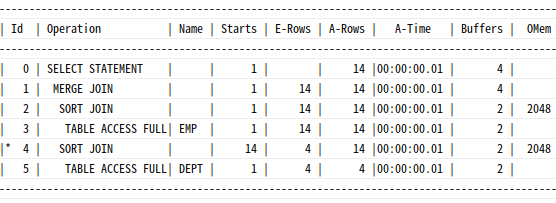
select *
from emp e, dept d
where d.deptno = e.deptno
option (force order, merge join)
StmtText
-------------------------------------------------------------
|--Merge Join(Inner Join, MANY-TO-MANY MERGE: )
|--Sort(ORDER BY:([e].[deptno] ASC))
| |--Table Scan(OBJECT:([SQLPRO].[dbo].[emp] AS [e]))
|--Sort(ORDER BY:([d].[deptno] ASC))
|--Table Scan(OBJECT:([SQLPRO].[dbo].[dept] AS [d]))Window Sort:윈도우 함수수행시
select empno, ename, job, mgr, sal,
row_number() over (order by hiredate)
from emp;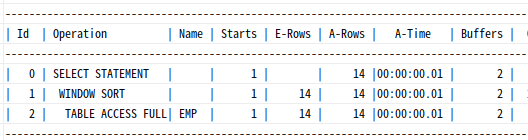
StmtText
-------------------------------------------------------------
|--Sequence Project(DEFINE:([Expr1004]=row_number))
|--Compute Scalar(DEFINE:([Expr1006]=(1)))
|--Segment
|--Sort(ORDER BY:([SQLPRO].[dbo].[emp].[hiredate] ASC))
|--Table Scan(OBJECT:([SQLPRO].[dbo].[emp]))소트 튜닝 요약
소트 튜닝 방안
데이터 모델측면에서의 검토- 소트가
발생하지 않도록 SQL 작성 인덱스를 이용한 소트 연산 대체소트 영역을 적게 사용하도록 SQL 작성- 소트 영역
크기 조정
2. 데이터 모델 측면에서의 검토
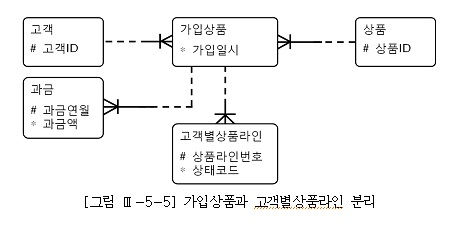
PK외에 관리할 속성이 아예 없거나, 소수여서 테이블 개수를 줄이기 위해 자식 테이블에 통합하는 경우
select 과금.고객id, 과금.상품id, 과금.과금액, 가입상품.가입일시
from 과금,
(select 고객id, 상품id, min(가입일시) 가입일시
from 고객별상품라인
group by 고객id, 상품id) 가입상품
where 과금.고객id(+)= 가입상품.고객id
and 과금.상품id(+) = 가입상품.상품id
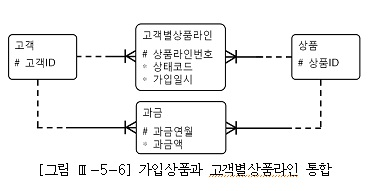
and 과금.과금연월(+) = :yyyymm위 모델처럼 정규화한 데이터 모델을 사용한다면, 쿼리도 간단
select 과금.고객id, 과금.상품id, 과금.과금액, 가입상품.가입일시
from 과금, 가입상품
where 과금.고객id(+) = 가입상품.고객id
and 과금.상품id(+) = 가입상품.상품id
and 과금.과금연월(+) = :yyyymm3. 소트가 발생하지 않도록 SQL 작성
Union을 Union All로 대체
select empno, job, mgr from emp where deptno = 10
union
select empno, job, mgr from emp where deptno = 20;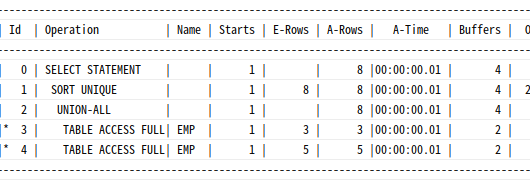
StmtText
-------------------------------------------------------------
|--Sort(DISTINCT ORDER BY:([Union1008] ASC, [Union1009] ASC, [Union1010] ASC))
|--Concatenation
|--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1000]))
| |--Index Seek(OBJECT:([SQLPRO].[dbo].[emp].[emp_dept_idx]), SEEK:([deptno]=(10.)))
| |--RID Lookup(OBJECT:([SQLPRO].[dbo].[emp]), SEEK:([Bmk1000]=[Bmk1000]))
|--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1004]))
|--Index Seek(OBJECT:([SQLPRO].[dbo].[emp].[emp_dept_idx]), SEEK:( deptno]=(20.)))
|--RID Lookup(OBJECT:([SQLPRO].[dbo].[emp]), SEEK:([Bmk1004]=[Bmk1004]))PK 칼럼인 empno가 select-list에 있으므로, 두 집합 간에는 중복 가능성이 전혀 없다.
=> union all을 사용하는 것이 마땅
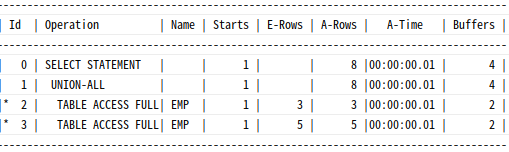
StmtText
-------------------------------------------------------------
|--Concatenation
|--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1000]))
| |--Index Seek(OBJECT:([SQLPRO].[dbo].[emp].[emp_dept_idx]), SEEK:([deptno]=(10.)))
| |--RID Lookup(OBJECT:([SQLPRO].[dbo].[emp]), SEEK:([Bmk1000]=[Bmk1000]))
|--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1004]))
|--Index Seek(OBJECT:([SQLPRO].[dbo].[emp].[emp_dept_idx]), SEEK:([deptno]=(20.)))
|--RID Lookup(OBJECT:([SQLPRO].[dbo].[emp]), SEEK:([Bmk1004]=[Bmk1004]))Distinct를 Exists 서브쿼리로 대체
distinct는 대부분 exists 서브쿼리로 대체함으로써 소트 연산 제거 가능
select distinct 과금연월
from 과금
where 과금연월 <= :yyyymm
and 지역 like :reg || '%'
call count cpu elapsed disk query current rows
----- ----- ----- ------- ------ ------ ------ -----
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 4 27.65 98.38 32648 1586208 0 35
----- ----- ----- ------- ------ ------ ------ -----
total 6 27.65 98.38 32648 1586208 0 35
Rows Row Source Operation
----- ---------------------------------------------------
35 HASH UNIQUE (cr=1586208 pr=32648 pw=0 time=98704640 us)
9845517 PARTITION RANGE ITERATOR PARTITION: 1 KEY (cr=1586208 pr=32648 )
9845517 TABLE ACCESS FULL 과금 (cr=1586208 pr=32648 pw=0 time=70155864 us중복 값을 제거하고 고작 35건 출력
select 연월
from 연월테이블 a
where 연월 <= :yyyymm
and exists (
select 'x'
from 과금
where 과금연월 = a.연월
and 지역 like :reg || '%'
)
call count cpu elapsed disk query current rows
----- ----- ------ -------- ------ ------ ------ -----
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 4 0.00 0.01 0 82 0 35
----- ----- ------ ------- ------ ------ ------ -----
total 6 0.00 0.01 0 82 0 35
Rows Row Source Operation
---- ---------------------------------------------------
35 NESTED LOOPS SEMI (cr=82 pr=0 pw=0 time=19568 us)
36 TABLE ACCESS FULL 연월테이블 (cr=6 pr=0 pw=0 time=557 us)
35 PARTITION RANGE ITERATOR PARTITION: KEY KEY (cr=76 pr=0 pw=0 time=853 us)
35 INDEX RANGE SCAN 과금_N1 (cr=76 pr=0 pw=0 time=683 us)월별로 과금이 발생했는지만 확인하면 되므로 위와 같이 작성
불필요한 Count 연산 제거
--데이터 존재 여부만 확인하면 되는데도 불필요하게 전체 건수 Count
declare
l_cnt number;
begin
select count(*) into l_cnt
from member
where memb_cls = '1'
and birth_yyyy <= '1950';
if l_cnt > 0 then
Zdbms_output.put_line('exists');
else
dbms_output.put_line('not exists');
end if;
end;
Call Count CPU Time Elapsed Time Disk Query Current Rows
---- ---- --------- ---------- ---- ---- ----- ----
Parse 1 0.000 0.000 0 0 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 2 0.172 17.561 4742 26112 0 1
---- ---- --------- ---------- ---- ---- ----- ----
Total 4 0.172 17.561 4742 26112 0 1
Rows Row Source Operation
---- ---------------------------------------------------
0 STATEMENT
1 SORT AGGREGATE (cr=26112 pr=4742 pw=0 time=17561372 us)
29184 TABLE ACCESS BY INDEX ROWID MEMBER (cr=26112 pr=4742 pw=0 time=30885229 us)
33952 INDEX RANGE SCAN MEMBER_IDX01 (cr=105 pr=105 pw=0 time=2042777 us)declare
l_cnt number;
begin
select 1 into l_cnt
from member
where memb_cls = '1'
and birth_yyyy <= '1950'
and rownum <= 1;
dbms_output.put_line('exists');
exception
when no_data_found then
dbms_output.put_line('not exists');
end;
Cal Count CPU Time Elapsed Time Disk Query Current Rows
---- ----- --------- ---------- ----- ----- ------ -----
Parse 1 0.000 0.000 0 0 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 2 0.000 0.000 0 3 0 1
---- ----- --------- ---------- ----- ----- ------ -----
Total 4 0.000 0.000 0 3 0 1Rows Row Source Operation
---- ---------------------------------------------------
0 STATEMENT
1 COUNT STOPKEY (cr=3 pr=0 pw=0 time=54 us)
1 TABLE ACCESS BY INDEX ROWID MEMBER (cr=3 pr=0 pw=0 time=46 us)
1 INDEX RANGE SCAN MEMBER_IDX01 (cr=2 pr=0 pw=0 time=26 us)--sql server은 top n절 또는 exists
declare @cnt int
select @cnt = count(*)
where exists
(
select 'x'
from member
where memb_cls = '1'
and birth_yyyy <= '1950'
)
if @cnt > 0
print 'exists'
else
print 'not exists'4. 인덱스를 이용한 소트 연산 대체
Sort Order By 대체
-- region+custid 순 인덱스 사용시 연산 대체
select custid, name, resno, status, tel1
from customer
where region = 'A'
order by custid
--------------------------------------------------------------------
|Id| Operation | Name | Rows|Bytes|Cost(%CPU)|
--------------------------------------------------------------------
| 0|SELECT STATEMENT | |40000|3515K| 1372 (1)|
| 1| TABLE ACCESS BY INDEX ROWID|CUSTOMER |40000|3515K| 1372 (1)|
| 2| INDEX RANGE SCAN |CUSTOMER_X02|40000| | 258 (1)|
--------------------------------------------------------------------OLTP 환경에서 극적인 성능 개선 효과를 가져다줌
=> 소트해야 할 레코드가 무수히 많고, 그중 일부만 읽고 멈출 때
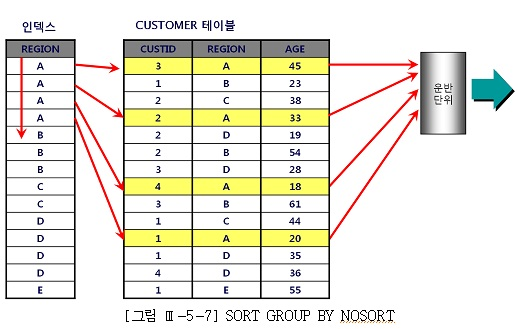
Sort Group By 대체
-- region이 선두 칼럼인 인덱스 사용시
select region, avg(age), count(*)
from customer
group by region;
---------------------------------------------------------------------------
| Id | Operation | Name |Rows |Bytes |Cost (%CPU)|
---------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 25 | 725 |30142 (1)|
| 1 | SORT GROUP BY NOSORT | | 25 | 725 |30142 (1)|
| 2 | TABLE ACCESS BY INDEX ROWID|CUSTOMER |1000K| 27M |30142 (1)|
| 3 | INDEX FULL SCAN |CUSTOMER_X01|1000K| |2337 (2)|
---------------------------------------------------------------------------
인덱스를 활용한 Min, Max 구하기
First Row Stopkey 알고리즘 : Min, Max 값을 인덱스를 이용해 빠르게 찾는 기능
--인덱스 주문일자+주문번호
--마지막 주문번호를 아주 빠르게 찾을 수 있음
select nvl(max(주문번호), 0) + 1
from 주문
where 주문일자 = :주문일자
Execution Plan
-------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 SORT (AGGREGATE)
2 1 FIRST ROW
3 2 INDEX (RANGE SCAN (MIN/MAX)) OF '주문_PK' (INDEX (UNIQUE))
StmtText
--------------------------------------------------------------------------------------
|--Stream Aggregate(DEFINE:([Expr1004]=MAX([SQLPRO].[dbo].[emp].[empno])))
|--Top(TOP EXPRESSION:((1)))
|--Index Seek(OBJECT:([SQLPRO].[dbo].[주문].[주문_PK]),SEEK:(……)ORDERED BACKWARD)5. 소트 영역을 적게 사용하도록 SQL 작성
소트 완료 후 데이터 가공
--1
select lpad(상품번호, 30) || lpad(상품명, 30) || lpad(고객ID, 10)
|| lpad(고객명, 20) || to_char(주문일시, 'yyyymmdd hh24:mi:ss')
from 주문상품
where 주문일시 between :start and :end
order by 상품번호
--2
select lpad(상품번호, 30) || lpad(상품명, 30) || lpad(고객ID, 10)
|| lpad(상품명, 20) || to_char(주문일시, 'yyyymmdd hh24:mi:ss')
from (
select 상품번호, 상품명, 고객ID, 고객명, 주문일시
from 주문상품
where 주문일시 between :start and :end
order by 상품번호
)정렬을 끝낸 후 데이터를 가공하므로 2번이 훨씬 소트 영역을 적게 사용
Top N 쿼리
Top N 쿼리로 작성시 소트 연산(=값 비교) 횟수와 소트 영역 사용량 최소화 가능
--sql server
select top 10 거래일시, 체결건수, 체결수량, 거래대금
from 시간별종목거래
where 종목코드 = 'KR123456'
and 거래일시 >= '20080304'
--oracle
select * from (
select 거래일시, 체결건수, 체결수량, 거래대금
from 시간별종목거래
where 종목코드 = 'KR123456'
and 거래일시 >= '20080304'
order by 거래일시
)
where rownum <= 10수행 시점에 종목코드+거래일시 순으로 인덱스 존재시 order by 연산 대체 가능
Execution Plan
-------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 COUNT (STOPKEY)
2 1 VIEW
3 2 TABLE ACCESS (BY INDEX ROWID) OF '시간별종목거래' (TABLE)
4 3 INDEX (RANGE SCAN) OF ' 시간별종목거래_PK' (INDEX (UNIQUE))Top N Stopkey : rownum 조건을 사용해 N건에서 멈추게 하는 것
Top N 쿼리의소트 부하 경감 원리

종목코드만을 선두로 갖는 다른 인덱스 사용하거나 Full Table Scan 방식으로 처리하면, 정렬 작업 불가피
ex. Top 10 (rownum<=10) 이면 10개 레코드를 담을 수 있는 배열을 할당하고, 처음 읽은 10개 레코드를 정렬한 상태로 담는다. 그 이후 읽는 레코드에 대해서는 맨 우측 값(=가장 큰 값)과 비교해서 작은 값이 나타날 때만 배열 내에서 다시 정렬 시도
Top N Sort 알고리즘 : Top N 쿼리가 소트 연산 횟수와 소트 영역 사용량을 줄여주는 원리
Top N 쿼리를 이용한 효과적인 이력 조회
-- 인덱스 칼럼 가공해 First Row Stopkey 작동 X
select 장비번호, 장비명, 상태코드
, substr(최종이력,1,8) 최종변경일자
, to_number((최종이력,9,4)) 최종변경순번
from (
select 장비번호, 장비명, 상태코드
, (
select max( H.변경일자 || lpad(H.변경순번,4) )
from 상태변경이력 H
where 장비번호 = P.장비번호
) 최종이력
from 장비 P
where 장비구분코드 = 'A001'
)
---------------------------------
0 SELECT STATEMENT
1 SORT AGGREGATE
2 INDEX RANGE SCAN | 상태변경이력_PK
3 TABLE ACCESS BY INDEX ROWID | 장비
4 INDEX RANGE SCAN | 장비_N1--12c 이상
select 장비번호, 장비명, 상태코드
, substr(최종이력,1,8) 최종변경일자
, to_number((최종이력,9,4)) 최종변경순번
, substr(최종이력,13) 최종상태코드
from (
select 장비번호, 장비명
, ( select 변경일자 || lpad(H.변경순번,4) || 상태코드
from (
select 장비번호, 변경일자, 변경순번, 상태코드
from 상태변경이력
where 장비번호 = P.장비번호
order by 변경일자 desc, 변경순번 desc
)
where rownum <= 1
) 최종이력
from 장비 P
where 장비구분코드 = 'A001'
)
-- count stopkey 작동6. 소트 영역 크기 조정
--oracle 8i 까지
alter session set sort_area_size = 1048576;oracle 9i 부턴 자동 PGA 메모리 관리(Automatic PGA Memory Management) 기능이 도입돼 사용자가 조정 안해도 됨
=> DB 관리자가 pga_aggregate_target 파라미터를 통해 전체적으로 이용 가능한 PGA 메모리 총량을 지정하면, Oracle이 알아서 세션에 메모리 할당
-- workarea_size_policy auto시 자동 PGA 관리 해주는데, 그러면 대량 배치시 오래 걸림
alter session set workarea_size_policy = manual;
alter session set sort_area_size = 10485760;🍦DML 튜닝
1. 인덱스 유지 비용
대용량 데이터를 입력, 수정, 삭제할 때는 인덱스를 모두 Drop하거나 Unusable 상태로 변경한 다음 작업하는 것이 빠름
2. Insert 튜닝
Oracle Insert 튜닝
Direct Path Insert
IOT는 정해진 키 순으로 정렬하면서 값을 입력하는 반면, 일반적인 힙 구조 테이블은 순서 없이 블록에 무작위로 값 입력
Direct Path Insert는 Freelist를 거치지 않고 HWM 바깥 영역에, 그것도 버퍼 캐시를 거치지 않고 데이터 파일에 곧바로 입력하는 방식
=> Undo 데이터 쌓지 않음
Direct Path Insert 방식으로 데이터 입력하는 방법
- insert select 문장에
/*+ append */ 힌트사용 병렬 모드로 insertdirect 옵션을 지정하고SQL*Loader(sqlldr)로 데이터 로드CTAS(create table .. as select)문장 수행
nologging 모드 Insert
alter table t NOLOGGING;nologging으로 바꾸면 Redo로그까지 최소화되므로 더 빠르게 insert 가능
=> Direct Path Insert 일 때만 작동
Direct Path Insert 방식으로 데이터를 입력하면 Exclusive 모드 테이블 Lock이 걸려 Insert 작업을 하는 동안 다른 트랜잭션은 해당 테이블에 DML 수행 못함
SQL Server Insert 튜닝
최소 로깅(minimal nologging)
-- 최소 로깅 사용을 위해선 데이터베이스 복구 모델이 Bulk-logged 또는 Simple로 설정
alter database SQLPRO set recovery SIMPLE파일 데이터를 읽어 DB로 로딩하는 Bulk Insert 구문을 사용시 With 옵션에 TABLOCK 힌트 추가하면 최소 로깅 모드 작동
BULK INSERT AdventureWorks.Sales.SalesOrderDetail
FROM 'C:\orders\lineitem.txt'
WITH (
DATAFILETYPE = 'CHAR',
FIELDTERMINATOR = ' |',
ROWTERMINATOR = ' |\n',
TABLOCK
)Oracle CTAS와 같은 select into 사용시 최소 로깅 모드
select * into target from source ;일반 insert문에 TABLOCK 힌트
insert into t_heap with (TABLOCK) select * from t_source클러스터형 인덱스(B*Tree 구조 테이블)에 Insert할 때도 최소 로깅 가능
=> 전제 조건 : 소스 데이터를 목표 테이블 정렬(클러스터형 인덱스 정렬 키) 순으로 정렬해야 함
최소 로깅을 위해 필요한 다른 조건
- 비어 있는 B*Tree 구조에서
TABLOCK 힌트사용 - 비어 있는 B*Tree 구조에서
TF-610을 활성화 - 비어 있지 않은 B*Tree 구조에서
TF-610을 활성화하고새로운 키 범위만 입력
입력하는 소스 데이터의 값 범위가 중복X라면, 동시 Insert 가능
use SQLPRO
go
alter database SQLPRO set recovery SIMPLE
DBCC TRACEON(610);
insert into t_idx
select * from t_source
order by col1 -- t_idx 테이블의 클러스터형 인덱스 키 순 정렬3. Update 튜닝
Truncate & Insert 방식 사용
대량의 데이터를 일반 Update문으로 갱신하면 상당히 오랜 시간 소요 (DELETE도)
- 테이블 데이터를 갱신하는 본연의 작업
- 인덱스 데이터까지 갱신
- 버퍼 캐시에 없는 블록을 디스크에서 읽어 버퍼 캐시에 적재한 후 갱신
- 내부적으로 Redo와 Undo 정보 생성
- 블록에 빈 공간 X시 새 블록 할당(=>
Row Migration발생)
--대량의 update시
create table 주문_임시 as select * from 주문;
-- SQL Server
select * into #emp_temp from emp;
alter table emp drop constraint 주문_pk;
drop index [주문.]주문_idx1; -- [] : SQL Server
truncate table 주문;
insert into 주문(고객번호, 주문일시, , 상태코드) select 고객번호, 주문일시,
(case when 주문일시 >= to_date('20000101', 'yyyymmdd') then '9999' else status end) 상태코드
from 주문_임시;
alter table 주문 add constraint 주문_pk primary key(고객번호, 주문일시);
create index 주문_idx1 on 주문(주문일시, 상태코드);--대량의 delete시
create table 주문_임시
as
select * from 주문 where 주문일시 >= to_date('20000101', 'yyyymmdd');
alter table emp drop constraint 주문_pk;
drop index 주문_idx1;
truncate table 주문;
insert into 주문
select * from 주문_임시;
alter table 주문 add constraint 주문_pk primary key(고객번호, 주문일시);
create index 주문_idx1 on 주문(주문일시, 상태코드);조인을 내포한 Update 튜닝
- 전통적인 방식의 Update문
update 고객
set (최종거래일시, 최근거래금액) = ( select max(거래일시), sum(거래금액)
from 거래
where 고객번호 = 고객.고객번호 and 거래일시 >= trunc(add_months(sysdate,-1)) )
where exisis ( select 'x'
from 거래 where 고객번호 = 고객.고객번호
and 거래일시 >= trunc(add_months(sysdate,-1) ) );위 Update를 위해선 기본적으로 거래 테이블에 고객번호+거래일시 인덱스가 있어야 함
=> 서브쿼리에 unnest와 함께 hash_sj 힌트를 사용해 해시 세미 조인으로 유도하는 것이 효과
- SQL Server 확장 Update문
update 고객
set 최종거래일시 = b.거래일시, 최근거래금액 = b.거래금액
from 고객 a
inner join ( select 고객번호, max(거래일시) 거래일시, sum(거래금액) 거래금액
from 거래
where 거래일시 >= dateadd(mm,-1,convert(datetime,convert(char(8),getdate(),112),112))
group by 고객번호 ) b
on a.고객번호 = b.고객번호- Oracle 수정 가능 조인 뷰 활용
update
(select c.최종거래일시, c.최근거래금액, t.거래일시, t.거래금액
from (select 고객번호, max(거래일시) 거래일시, sum(거래금액) 거래금액
from 거래
where 거래일시 >= trunc(add_months(sysdate,-1))
group by 고객번호) t , 고객 c
where c.고객번호 = t.고객번호 )
set 최종거래일시 = 거래일시 , 최근거래금액 = 거래금액조인 뷰 : from절에 두 개 이상 테이블을 가진 뷰
=> 키-보존 테이블에만 허용
=> 키-보존 테이블 : 조인된 결과 집합을 통해서도 중복 없이 Unique하게 식별이 가능한 테이블
=> Unique 인덱스가 있는지, 또는 조인 키 칼럼으로 Group By 했는지를 통해 유일성 여부 확인
- Oracle Merge문 활용
merge into문 활용시 하나의 SQL문 안에서 insert, update, delete 가능
merge into 고객 c
using (select 고객번호, max(거래일시) 거래일시, sum(거래금액) 거래금액
from 거래
where 거래일시 >= trunc(add_months(sysdate,-1))
group by 고객번호) t
on (c.고객번호 = t.고객번호)
when matched then
update set c.최종거래일시 = t.거래일시, c.최근거래금액 = t.거래금액🍧데이터베이스 Call 최소화
1. 데이터베이스 Call 종류
SQL 커서에 대한 작업 요청에 따른 구분
Parse Call: SQL파싱을 요청하는 CallExecute Call: SQL실행을 요청하는 CallFetch Call:SELECT문의 결과 전송을 요청하는 Call
select cust_nm, birthday from customer where cust_id = :cust_id
call count cpu elapsed disk query current rows
----- ----- ----- ------ ---- ----- ------ -----
Parse 1 0.00 0.00 0 0 0 0
Execute 5000 0.18 0.14 0 0 0 0
Fetch 5000 0.21 0.25 0 20000 0 50000
----- ----- ----- ------ ---- ----- ------ -----
total 10001 0.39 0.40 0 20000 0 50000Call 발생 위치에 따른 구분
-
User Call: DBMS외부에서 요청하는 Call
=> DBMS성능과확장성을 높이려면,User Call을 줄이는 노력 중요
-Loop 쿼리를 해소하고 집합적 사고를 통해One SQL로 구현
-Array Processing: Array 단위 Fetch, Bulk Insert/Update/Delete
-부분범위처리원리 활용
-효과적인 화면페이지 처리
-사용자 정의 함수,트리거,프로시저의 적절한 활용 -
Recursive Call: DBMS내부에서 발생하는 Call
=> SQL 파싱과 최적화 과정에서 발생하는데이터 딕셔너리 조회,사용자 정의 함수, 프로시저내에서의 SQL 수행
=>바인드 변수사용해하드파싱횟수 줄이기
2. 데이터베이스 Call과 성능
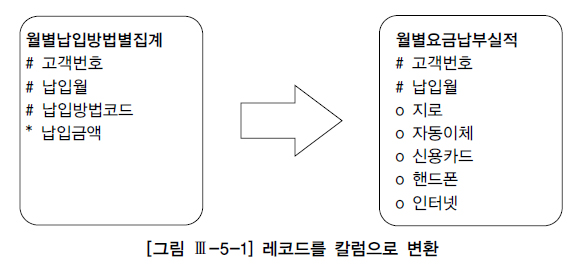
One SQL 구현의 중요성
public class JavaOneSQL{
public static void execute(Connection con, String input_month) throws Exception {
String SQLStmt = "INSERT INTO 납입방법별_월요금집계"
+ "(납입월,고객번호,납입방법코드,납입금액) "
+ "SELECT x.납입월, x.고객번호, CHR(64 + Y.NO) 납입방법코드 "
+ " , DECODE(Y.NO, 1, 지로, 2, 자동이체, 3, 신용카드, 4, 핸드폰, 5, 인터넷) "
+ "FROM 월요금납부실적 x, (SELECT LEVEL NO FROM DUAL CONNECT BY LEVEL <= 5) y "
+ "WHERE x.납입월 = ? "
+ "AND y.NO IN ( DECODE(지로, 0, NULL, 1), DECODE(자동이체, 0, NULL, 2) "
+ " , DECODE(신용카드, 0, NULL, 3) , DECODE(핸드폰, 0, NULL, 4) "
+ " , DECODE(인터넷, 0, NULL, 5) )" ;
PreparedStatement stmt = con.prepareStatement(SQLStmt);
stmt.setString(1, input_month);
stmt.executeQuery();
stmt.close();
}
static Connection getConnection() throws Exception { …… }
static void releaseConnection(Connection con) throws Exception { …… }
public static void main(String[] args) throws Exception{
Connection con = getConnection();
execute(con, "200903");
releaseConnection(con);
}
}데이터베이스 Call과 시스템 확장성
void insertWishList ( String p_custid , String[] p_goods_no ) {
SQLStmt = "insert into wishlist "
+ "select custid, goods_no "
+ "from cart "
+ "where custid = ? "
+ "and goods_no in ( ?, ?, ?, ?, ? )" ;
stmt = con.preparedStatement(SQLStmt);
stmt.setString(1, p_custid);
for(int i=0; i < 5; i++){
stmt.setString(i+2, p_goods_no[i]);
}
stmt.execute();
}3. Array Processing 활용
한 번의 SQL로 다량의 레코드 동시에 처리
public static void insert Data() throws Eception{
...
st.addBatch();
}
stmt1.setFetchSize(1000);
while(rs.next()){
...
if(++rows%1000==0) stmt2.executeBatch();
}
stmt2.executeBatch();
...Array에 Insert할 데이터를 계속 담기만 하다가 1000건이 쌓일 때마다 한 번씩 executeBatch를 수행하며, SELECT 결과 집합을 Fetch할 때도, 1000개 단위로 Fetch
4. Fetch Call 최소화
부분범위처리 원리
DBMS는 데이터를 클라이언트에 전송할 때 일정량씩 나누어 전송
set arraysize 100call count cpu elapsed disk query current rows
----- ---- ----- ------ ----- ----- ----- ------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.02 2 2 0 0
Fetch 301 0.14 0.18 9 315 0 30000
----- ---- ----- ------ ----- ----- ----- ------
total 303 0.14 0.20 11 317 0 300003만 개 로우를 읽기 위해 Fetch Call이 301번 발생한 것을 보고, ArraySize는 100이란 것을 알 수 있다.
부분범위처리 : 전체 데이터를 연속적으로 전송하지 않고 사용자로부터 Fetch Call이 있을 때마다 일정량씩 나누어서 전송하는 것
출력 대상 레코드가 많을수록 Array를 빨리 채울 수 있어 쿼리 응답 속도도 그만큼 빨라짐
ArraySize 조정에 의한 Fetch Call 감소 및 블록 I/O 감소 효과
대량 데이터를 파일로 내려받으려면 어차피 전체 데이터를 전송해야 하므로 가급적 값을 크게 설정
=> ArraySize를 조정한다고 전송해야 할 총량이 줄진 않지만, Fetch Call 횟수는 줄일 수 있음
앞쪽 일부 데이터만 Fetch하다가 멈추는 프로그램이라면 ArraySize를 작게 설정하는 것이 유리
=> 많은 데이터를 읽어 전송하고도 사용하지 않는 비효율 줄일 수 있음
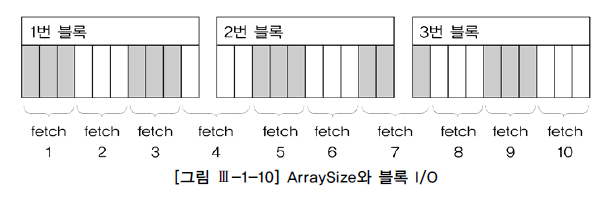
10개 행으로 구성된 3개의 블록이며 총 30개 레코드이다.
ArraySize를 3으로 설정하면 Fetch 횟수는 10이고, 블록 I/O는 12번 발생한다.
=> 첫 번째 Fetch에서 읽은 1번 블록을 2~4번째에서도 읽기 때문
만약 ArraySize를 10으로 설정하면 3번의 Fetch와 블록I/O로 줄일 수 있음
-- oracle pl/sql에서 array fetch 작동을 위한 cursor for loop 구문
for item in cursor
loop
……
end loop;5. 페이지 처리 활용
페이지 처리 방식 : 사용자가 다음 페이지를 요청할 때마다 개별적인 SQL문 수행
=> 웹 애플리케이션 환경에선 커서를 계속 연 채로 결과 집합을 핸들링할 수 없으므로
페이지 처리 X시
- 다량 발생하는
Fetch Call 부하 - 대량의 결과 집합을 클라이언트로 전송하면서 발생하는
네트워크 부하 - 대량의 데이터 블록을 읽으면서 발생하는
I/O 부하 AP 서버및웹 서버리소스 사용량 증가
부하 해소
페이지 단위로, 화면에서 필요한 만큼만Fetch Call페이지 단위로, 화면에서 필요한 만큼만네트워크를 통해 결과 전송인덱스와부분범위처리 원리를 이용해 각 페이지에 필요한 최소량만I/O- 데이터를
소량씩나누어 전송하므로AP웹 서버 리소스사용량 최소화
6. 분산 쿼리
--order_date 조건에 해당하는 데이터만 원격으로 보내서 조인과 group by를 거친 후 결과 집합 전송받음
select /*+ driving_site(b) */ channel_id, sum(quantity_sold) auantity_cold
from order a, sales@lk_sales b
where a.order_date between :1 and :2
and b.order_no = a.order_no
group by channel_id
Rows Row Source Operation
---- ---------------------------------------------
5 SORT GROUP BY
10981 NESTED LOOPS
939 TABLE ACCESS (BY INDEX ROWID) OF ‘ORDER’
939 INDEX (RANGE SCAN) OF ‘ORDER_IDX2’ (NON-UNIQUE)
10981 REMOTE분산 쿼리의 성능을 높이는 핵심 원리는 네트워크를 통한 데이터 전송량을 줄이는 데 있음
7. 사용자 정의 함수ㆍ프로시저의 특징과 성능
사용자 정의 함수ㆍ프로시저의 특징
사용자 정의 함수ㆍ프로시저는 내장함수처럼 네이티브 코드로 완전 컴파일된 형태가 아니어서 가상머신 같은 별도의 실행 엔진을 통해 실행
=> 실행될 때마다 콘텍스트 스위칭(Context Switching)이 일어나고, 이 때문에 내장함수를 호출할 때와 비교해 성능이 상당히 떨어짐
사용자 정의 함수ㆍ프로시저에 의한 성능 저하 해소 방안
create or replace function 일자검사(p_date varchar2) return varchar2
as
l_date varchar2(8);
begin
l_date := to_char(to_date(p_date, 'yyyymmdd'), 'yyyymmdd'); -- 일자 오류 시, Exception 발생
if l_date > to_char(trunc(sysdate), 'yyyymmdd') then
return 'xxxxxxxx'; -- 미래 일자로 입력된 주문 데이터
end if;
for i in (select 휴무일자 from 휴무일 where 휴무일자 = l_date)
loop
return 'xxxxxxxx'; -- 휴무일에 입력된 주문 데이터 end loop;
return l_date; -- 정상적인 주문 데이터
exception
when others then return '00000000'; -- 오류 데이터
end;1000만 개의 주문 레코드를 검사하면, 1000만 번의 콘텍스트 스위칭이 발생하며, 각각 Execute Call과 Fetch Call이 1000만 번씩 발생
사용자 정의 함수는 소량의 데이터를 조회할 때, 또는 부분범위처리가 가능한 상황에서 제한적으로 사용해야 함
--one sql로 구현
select * from 주문 o
where not exists (select 'x' from 일자 where c_date = o.주문일자)
or exists (select 'x' from 휴무일 where 휴무일자 = o.주문일자)🍨파티셔닝
1. 파티션 개요
파티셔닝(Partitioning) : 테이블 또는 인덱스 데이터를 파티션 단위로 나누어 저장
=> 테이블을 파티셔닝하면 파티션 키에 따라 물리적으로는 별도의 세그먼트에 데이터를 저장하며, 인덱스도 마찬가지
파티셔닝이 필요한 이유
- 관리적 측면 : 파티션 단위
백업,추가,삭제,변경 - 성능적 측면 : 파티션 단위
조회및DML 수행,경합및부하 분산
2. 파티션 유형
Range 파티셔닝
- 파티션 키 값의
범위로 분할 - 가장 일반적인 형태, 주로
날짜 칼럼을 기준으로 함
Hash 파티셔닝
- 파티션 키 값에
해시 함수를 적용하고, 거기서 반환된 값으로 파티션 매핑 - 데이터가
모든 파티션에고르게 분산되도록 DBMS가 관리
=> 각 로우 저장 위치 예측 불가 - 파티션 키의
데이터 분포가고른 칼럼이어야 효과적 병렬처리시 성능효과 극대화DML 경합 분산에 효과적
List 파티셔닝
불연속적인 값의 목록을 각 파티션에 지정- 순서와 상관없이, 사용자가
미리 정한 기준에 따라 데이터 분할 저장
Composite 파티셔닝
Range나List 파티션 내에 또 다른서브 파티션구성

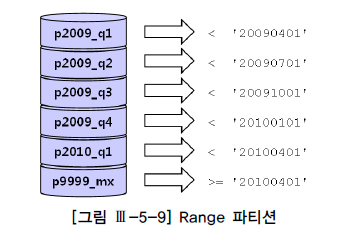
create table 주문 ( 주문번호 number, 주문일자 varchar2(8), 고객id varchar2(5), )
partition by range(주문일자) (
partition p2009_q1 values less than ('20090401') ,
partition p2009_q2 values less than ('20090701') ,
partition p2009_q3 values less than ('20091001') ,
partition p2009_q4 values less than ('20100101') ,
partition p2010_q1 values less than ('20100401') ,
partition p9999_mx values less than ( MAXVALUE ) -- 주문일자 >= '20100401'
) ;
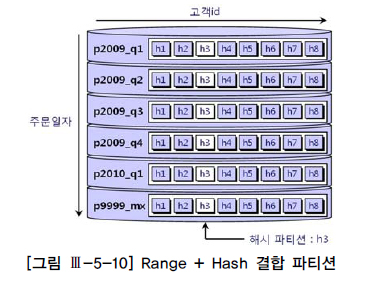
create table 주문 ( 주문번호 number, 주문일자 varchar2(8), 고객id varchar2(5), )
partition by range(주문일자)
subpartition by hash(고객id) subpartitions 8 (
partition p2009_q1 values less than('20090401') ,
partition p2009_q2 values less than('20090701') ,
partition p2009_q3 values less than('20091001') ,
partition p2009_q4 values less than('20100101') ,
partition p2010_q1 values less than('20100401') ,
partition p9999_mx values less than( MAXVALUE )
) ;
SQL Server의 파티션 생성절차
파일 그룹생성파일을파일 그룹에 추가파티션 함수생성 (분할 방법, 경계값 지정)파티션 구성표생성 (파티션 함수에서 정의한 각 파티션의위치(파일 그룹)지정)파티션 테이블생성
3. 파티션 Pruning
파티션 Pruning : 옵티마이저가 SQL의 대상 테이블과 조건절을 분석해 불필요한 파티션을 액세스 대상에서 제외하는 기능
정적 파티션 Pruning
액세스할 파티션을 컴파일 시점에 미리 결정하여, 파티션 키 칼럼을 상수 조건으로 조회하는 경우
select *
from sales_range
where sales_date >= '20060301' and sales_date <= '20060401'
-----------------------------------------------------
| Id | Operation | Name | Pstart | Pstop |
-----------------------------------------------------
| 0 | SELECT STATEMENT | | | |
| 1 | PARTITION RANGE ITERATOR | | 3 | 4 |
|* 2 | TABLE ACCESS FULL | SALES_RANGE | 3 | 4 |
-----------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("SALES_DATE">='20060301' AND "SALES_DATE"<='20060401')동적 파티션 Pruning
액세스할 파티션을 실행 시점에 결정하며, 파티션 키 칼럼을 바인드 변수로 조회하는 경우
select *
from sales_range
where sales_date >= :a and sales_date <= :b
--------------------------------------------------------
| Id | Operation | Name | Pstart | Pstop |
--------------------------------------------------------
| 0 | SELECT STATEMENT | | | |
|* 1 | FILTER | | | |
| 2 | PARTITION RANGE ITERATOR | | KEY | KEY |
|* 3 | TABLE ACCESS FULL | SALES_RANGE | KEY | KEY |
--------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(:A<=:B)
3 - filter("SALES_DATE">=:A AND "SALES_DATE"<=:B)4. 인덱스 파티셔닝
Local 파티션 인덱스 vs. Global 파티션 인덱스
-
Local 파티션 인덱스:테이블 파티션과1:1로 대응되도록 파티셔닝한 인덱스
=>인덱스 파티션 키를 사용자가따로 지정X, 테이블과1:1 관계유지하도록 DBMS가 관리
=> SQL Server에선정렬된 파티션 인덱스
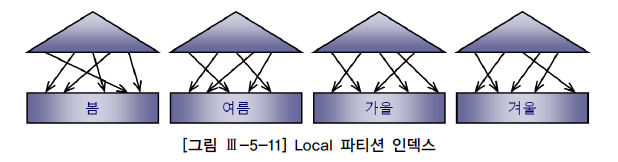
-
Global 파티션 인덱스: 테이블 파티션과독립적인 구성을 갖도록 파티셔닝한 인덱스
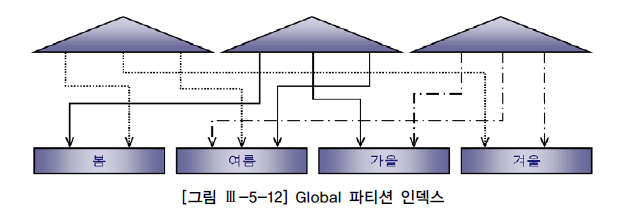
Prefixed 파티션 인덱스 vs. NonPrefixed 파티션 인덱스
인덱스 파티션 키 칼럼이 인덱스 구성상 왼쪽 선두 칼럼에 위치하는지에 따른 구분
Prefixed: 파티션 인덱스 생성시,파티션 키 칼럼을인덱스 키 칼럼왼쪽 선두에 두는 것Nonprefixed: 파티션 인덱스 생성시,파티션 키 칼럼을인덱스 키 칼럼왼쪽 선두에두지 않는 것
=>파티션 키가인덱스 칼럼에 아예속하지 않을 때도 여기 속함

인덱스 유형
- Local Prefixed 파티션 인덱스
- Local NonPrefixed 파티션 인덱스
- Global Prefixed 파티션 인덱스
- Global NonPrefixed 파티션 인덱스
- 비파티션 인덱스
인덱스 파티셔닝 가이드
Global 인덱스는 테이블 파티션에 대한 작업 시 Unusable 상태가 됨
=> 인덱스 다시 사용하려면 인덱스 rebuild 또는 재생성 해야 함

🍩대용량 배치 프로그램 튜닝
1. 배치 프로그램 튜닝 개요
배치 프로그램이란
배치(Batch) 프로그램 : 일련의 작업들을 하나의 작업 단위로 묶어 연속적으로 일괄 처리
=> 사용자와의 상호작용 없이
=> 대량의 데이터를 처리하는
=> 일련의 작업들을 묶어
=> 정기적으로 반복 수행하거나
=> 정해진 규칙에 따라 자동으로 수행
배치 환경의 변화
과거
일또는월배치 작업 위주야간에 생성된 데이터를주간 업무시간에 활용온라인과배치 프로그램의 구분이 비교적 명확
현재
시간배치 작업 비중 증가분배치 작업 일부 존재On-Demand 배치를 제한적이나마 허용
성능 개선 목표 설정
항상 전체 처리속도 최적화 목표
배치 윈도우를 적절히 조절
배치 프로그램 구현 패턴과 튜닝 방안
절차형으로 작성된 프로그램 :애플리케이션 커서를 열고, 루프 내에서 또다른 SQL이나 서브 프로시저를 호출하며 같은 처리 반복One SQL위주 프로그램 :One SQL로 구성하거나집합적으로 정의된 여러 SQL을 단계적으로 실행
절차형으로 작성된 프로그램의 비효율
- 반복적인 데이터베이스 Call
- Random I/O 위주
- 동일 데이터를 중복 액세스

2. 병렬 처리 활용
병렬 처리 : SQL문이 수행해야 할 작업 범위를 여러 개의 작은 단위로 나누어 여러 프로세스(쓰레드)가 동시에 처리하는 것
=> 대용량 데이터 처리시 수행 속도 극적으로 단축
select /*+ full(o) parallel(o, 4) */ count(*) 주문건수,
sum(주문수량) 주문수량, sum(주문금액) 주문금액
from 주문 o
where 주문일시 between '20100101' and '20101231';인덱스 스캔이 선택되면 parallel 힌트가 무시되기 때문에 full 힌트도 함께 작성 필요
select /*+ index_ffs(o, 주문_idx)) parallel_index(o, 주문_idx, 4) */ count(*) 주문건수
from 주문 o
where 주문일시 between '20100101' and '20101231'parallel_index 힌트를 사용할 때 index 또는 index_ffs 힌트를 함께 사용하는 습관 필요
=> Full Table Scan을 선택하면 parallel_index 힌트가 무시되기 때문
select count(*) 주문건수
from 주문
where 주문일시 between '20100101' and '20101231'
option (MAXDOP 4)Query Coordinator와 병렬 서버 프로세스
Query Coordinator(QC) : 병렬 SQL문을 발행한 세션
병렬 서버 프로세스 : 실제 작업을 수행하는 개별 세션
QC의 역할
병렬 SQL이 시작되면, 사용자가 지정한병렬도(DOP)와오퍼레이션 종류에 따라 하나 또는 두 개의병렬 서버 집합 할당
=>서버 풀로부터 필요한 만큼 서버 프로세스 확보각 병렬 서버에게작업 할당- 병렬로 처리하도록 사용자가 지시하지 않은 테이블은
직접 처리 각 병렬 서버의산출물을통합하는 작업 수행- 쿼리의 최종 결과 집합을
사용자에게전송
=>스칼라 서브 쿼리도 QC가 수행
select /*+ ordered use_hash(d) full(d) full(e) noparallel(d) parallel(e 4) */ count(*),
min(sal), max(sal), avg(sal), sum(sal)
from dept d, emp e
where d.loc = 'CHICAGO' and e.deptno = d.deptno
-------------------------------------------------------------
| Id | Operation | Name | TQ |IN-OUT | PQ Distrib |
-------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | |
| 1 | SORT AGGREGATE | | | | |
| 2 | PX COORDINATOR | | | | |
| 3 | PX SEND QC (RANDOM) | :TQ10002 | Q1,02 | P->S | QC (RAND) |
| 4 | SORT AGGREGATE | | Q1,02 | PCWP | |
| 5 | HASH JOIN | | Q1,02 | PCWP | |
| 6 | BUFFER SORT | | Q1,02 | PCWC | |
| 7 | PX RECEIVE | | Q1,02 | PCWP | |
| 8 | PX SEND HASH | :TQ10000 | | S->P | HASH |
| 9 | TABLE ACCESS FULL | DEPT | | | |
| 10 | PX RECEIVE | | Q1,02 | PCWP | |
| 11 | PX SEND HASH | :TQ10001 | Q1,01 | P->P | HASH |
| 12 | PX BLOCK ITERATOR | | Q1,01 | PCWC | |
| 13 | TABLE ACCESS FULL | EMP | Q1,01 | PCWP | |
-------------------------------------------------------------Intra-Operation Parallelism과 Inter-Operation Parallelism
select /*+ full(고객) parallel(고객 4) */ *
from 고객
order by 고객명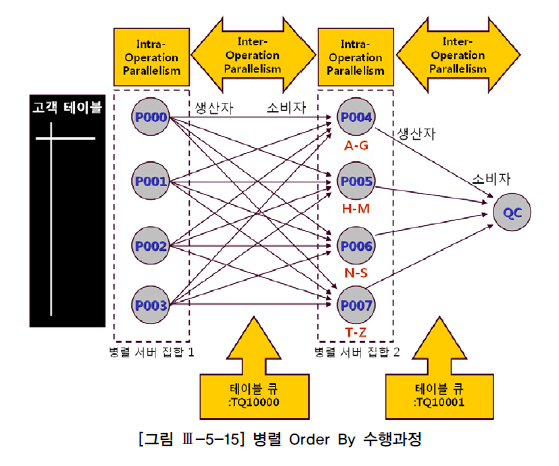
Intra-Operation Parallelism : 서로 배타적인 범위를 독립적으로 동시에 처리하는 것
=> 같은 서버 집합끼리는 서로 데이터를 주고 받을 일 없음
Inter-Operation Parallelism : 반대편 서버 집합에 분배하거나 정렬된 결과를 QC에게 전송하는 작업을 병렬로 동시에 진행하는 것
=> 항상 프로세스 간 통신이 발생
테이블 큐
테이블 큐(Table Queue) : 쿼리 서버 집합 간(P->P) 또는 QC와 쿼리 서버 집합 간(P->S, S->P) 데이터 전송을 위해 연결된 파이프 라인
테이블 큐 식별자 : 각 테이블 큐에 부여된 이름
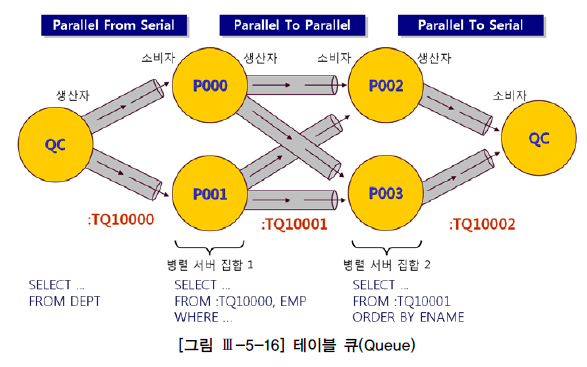
쿼리 서버 집합 간 Inter-Operation Parallelism이 발생할 땐 사용자가 지정한 병렬도의 배수 만큼 서버 프로세스 필요
=> 테이블 큐는 병렬도의 제곱만큼 파이프라인 필요
생산자, 소비자 모델
생산자에PX SEND,소비자에PX RECEIVE표시
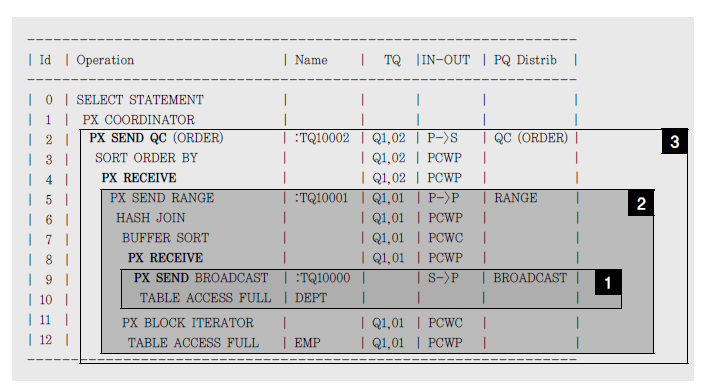
IN-OUT 오퍼레이션
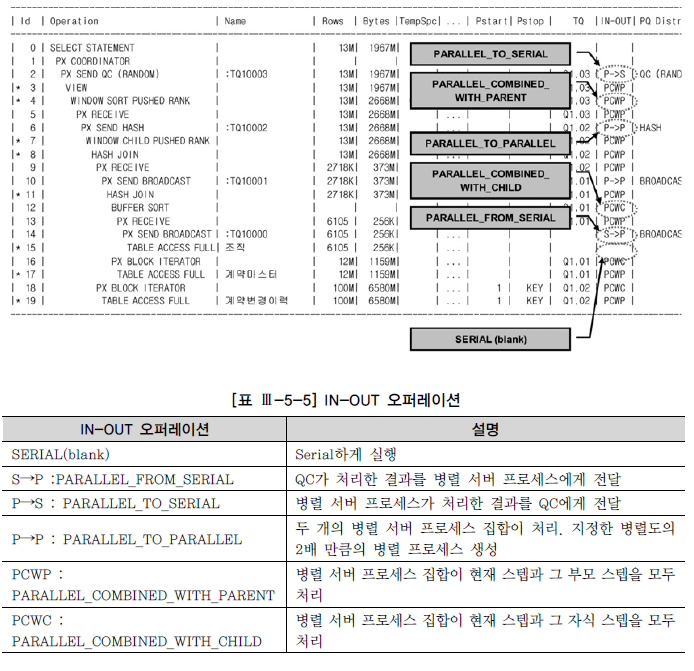
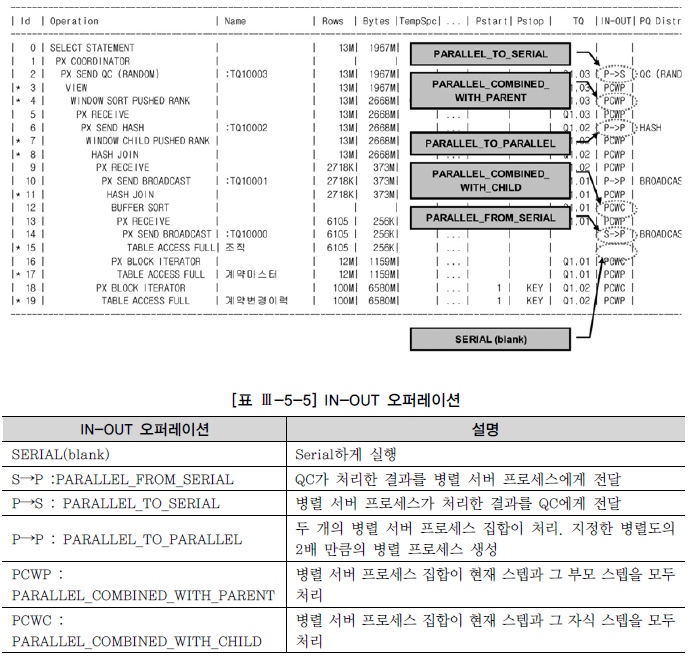
S->P,P->S,P->P:프로세스 간 통신발생PCWP와PCWC는 프로세스 간 통신 발생X, 각 병렬 서버가 독립적으로여러 스텝 처리시 나타남P->P,P->S,PCWP,PCWC는병렬오퍼레이션,S->P는직렬오퍼레이션
데이터 재분배
RANGE:order by또는sort group by를병렬로 처리할 때 사용
=> 정렬 작업을 맡은 두 번째 서버 집합의 프로세스마다처리 범위를 지정하고 나서, 데이터를 읽는 첫 번째 서버 집합이 두 번째 서버 집합의 정해진 프로세스에게정렬 키 값에 따라분배
=>QC는 정렬이 완료되고 나면순서대로 결과를 받아서 사용자에게 전송HASH:조인이나hash group by를 병렬로 처리시BROADCAST: QC 또는 첫 번째 서버 집합에 속한 프로세스들이 각각 읽은 데이터를두 번째 서버 집합에 속한모든병렬 프로세스에게 전송하는 방식
=>병렬 조인에서 크기가매우 작은테이블 있을 때 사용KEY: 특정 칼럼을 기준으로테이블또는인덱스를파티셔닝할 때 사용하는 분배 방식ROUND-ROBIN:파티션 키,정렬 키,해시 함수등에 의존하지 않고반대편 병렬 서버에무작위로 데이터 분배시
pq_distribute 힌트 활용
-
pq_distribute 힌트의 용도: 사용자가 직접 조인을 위한데이터 분배 방식결정
=> 옵티마이저가 파티션된 테이블을 적절히 활용하지 못하고동적 재분할을 시도할 때
=> 기존 파티션 키를 무시하고다른 키 값으로동적 재분할하고 싶을 때
=> 통계정보가 부정확하거나통계정보를 제공하기 어려운 상황에서 실행계획 고정하려고 할 때
=> 기타 여러 가지 이유로 데이터 분배 방식을 변경하려고 할 때 -
pq_distribute 사용법
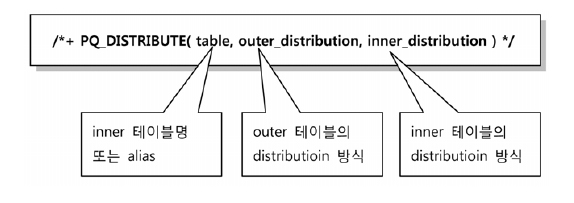
=>pq_distribute(none, none, none):Full-Partition Wise Join으로 유도시 사용
-양쪽 테이블 모두조인 칼럼에 대해 같은 기준으로파티셔닝돼 있을 때만 작동

=>pq_distribute(inner, partition, none):Partial-Partition Wise Join으로 유도할 때 사용
-outer 테이블을inner 테이블 파티션 기준에 따라파티셔닝
=>pq_distribute(inner,none,partition):Partial-Partition Wise Join으로 유도할 때 사용
-inner 테이블을outer 테이블 파티션 기준에 따라파티셔닝
=>pq_distribute(inner, hash, hash): 조인 키 칼럼을해시 함수에 적용하고 반환된 값을 기준으로양쪽 테이블을동적 파티셔닝
=>pq_distribute(inner, broadcast, none): outer 테이블을 broadcast -
pq_distribute 힌트를 이용한 튜닝 사례
=> 옵티마이저가 아주 큰 테이블을Broadcast하는 실행계획을 세울 때,pq_distribute를 사용해 분배 방식 조정
병렬 처리 시 주의사항
- 동시 사용자 수가
적은애플리케이션 환경(야간 배치 프로그램,DW,OLAP등)에서직렬로 처리할 때 보다 성능 개선 효과 확실할 때 (=>작은 테이블은병렬 처리 대상 제외) OLTP성 환경이라도작업을 빨리 완료함으로써 직렬로 처리할 때보다 오히려전체적인 시스템 리소스 사용률을 감소시킬 수 있을 때 (=>수행 빈도가 높지 않음 전제)병렬 DML 수행시Exclusive 모드 테이블 Lock이 걸림
🍪고급 SQL 활용
1. CASE문 활용
--이전 쿼리
INSERT INTO 월별요금납부실적 (고객번호, 납입월, 지로, 자동이체, 신용카드, 핸드폰, 인터넷)
SELECT K.고객번호, '200903' 납입월 , A.납입금액 지로 , B.납입금액 자동이체 , C.납입금액 신용카드 , D.납입금액 핸드폰 , E.납입금액 인터넷
FROM 고객 K ,
(SELECT 고객번호, 납입금액 FROM 월별납입방법별집계 WHERE 납입월 = '200903' AND 납입방법코드 = 'A') A ,
(SELECT 고객번호, 납입금액 FROM 월별납입방법별집계 WHERE 납입월 = '200903' AND 납입방법코드 = 'B') B ,
(SELECT 고객번호, 납입금액 FROM 월별납입방법별집계 WHERE 납입월 = '200903' AND 납입방법코드 = 'C') C ,
(SELECT 고객번호, 납입금액 FROM 월별납입방법별집계 WHERE 납입월 = '200903' AND 납입방법코드 = 'D') D ,
(SELECT 고객번호, 납입금액 FROM 월별납입방법별집계 WHERE 납입월 = '200903' AND 납입방법코드 = 'E') E
WHERE A.고객번호(+) = K.고객번호
AND B.고객번호(+) = K.고객번호
AND C.고객번호(+) = K.고객번호
AND D.고객번호(+) = K.고객번호
AND E.고객번호(+) = K.고객번호
AND NVL(A.납입금액,0)+NVL(B.납입금액,0)+NVL(C.납입금액,0)+NVL(D.납입금액,0)+NVL(E.납입금액,0) > 0
--SQL 재작성
INSERT INTO 월별요금납부실적 (고객번호, 납입월, 지로, 자동이체, 신용카드, 핸드폰, 인터넷)
SELECT 고객번호, 납입월 ,
NVL(SUM(CASE WHEN 납입방법코드 = 'A' THEN 납입금액 END), 0) 지로 ,
NVL(SUM(CASE WHEN 납입방법코드 = 'B' THEN 납입금액 END), 0) 자동이체 ,
NVL(SUM(CASE WHEN 납입방법코드 = 'C' THEN 납입금액 END), 0) 신용카드 ,
NVL(SUM(CASE WHEN 납입방법코드 = 'D' THEN 납입금액 END), 0) 핸드폰 ,
NVL(SUM(CASE WHEN 납입방법코드 = 'E' THEN 납입금액 END), 0) 인터넷
FROM 월별납입방법별집계
WHERE 납입월 = '200903'
GROUP BY 고객번호, 납입월 ;같은 레코드를 반복 액세스 하지 않고, 블록 액세스 양을 최소화해서 쿼리 작성
2. 데이터 복제 기법 활용
이전에 사용하던 기법은 복제용 테이블을 미리 만들어두고 활용하는 것
create table copy_t ( no number, no2 varchar2(2) );
insert into copy_t
select rownum, lpad(rownum, 2, '0') from big_table where rownum <= 31;
alter table copy_t add constraint copy_t_pk primary key(no);
create unique index copy_t_no2_idx on copy_t(no2);select * from emp a, copy_t b where b.no <= 2;조인절 없이 조인하면 카티션 곱이 발생해 데이터가 2배로 복제 되며, 3배로 복제하려면 no<=3으로 수정하면 된다.
9i 부터는 dual 테이블을 사용하면 편하다. connect by 구문을 이용하면 복제가 된다
select rownum no from dual connect by level <= 2;
no
-----
1
23. Union All을 활용한 M:M 관계의 조인
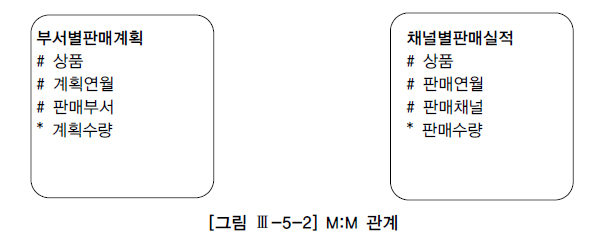
그대로 조인하면 카티션 곱이 발생한다. group by를 먼저 수행하고 나면 두 집합은 1:1 관계가 되므로 Full Outer Join을 통해 원하는 결과 집합을 얻을 수 있음
-- 전체 집합을 상품, 연월 기준으로 group by하면 됨
select 상품, 연월, nvl(sum(계획수량), 0) as 계획수량, nvl(sum(실적수량), 0) as 실적수량
from (
select 상품, 계획연월 as 연월, 계획수량, to_number(null) as 실적수량
from 부서별판매계획
where 계획연월 between '200901' and '200903'
union all
select 상품, 판매연월 as 연월, to_number(null) as 계획수량, 판매수량
from 채널별판매실적
where 판매연월 between '200901' and '200903'
) a
group by 상품, 연월 ;
상품 연월 계획수량 판매수량
---- ------ ------- ------
상품A 200901 10000 7000
상품A 200902 5000 0
상품A 200903 20000 8000
상품B 200901 20000 0
상품B 200902 15000 12000
상품B 200903 0 19000
상품C 200901 15000 13000
상품C 200902 0 18000
상품C 200903 20000 04. 페이징 처리

일반적인 페이징 처리용 SQL
SELECT *
FROM (
SELECT ROWNUM NO, 거래일시, 체결건수 , 체결수량, 거래대금, COUNT(*) OVER () CNT ……………………………………… 1
FROM (
SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM 시간별종목거래
WHERE 종목코드 = :isu_cd -- 사용자가 입력한 종목코드
AND 거래일시 >= :trd_time -- 사용자가 입력한 거래일자 또는 거래일시
ORDER BY 거래일시 ……………………………………………………………………………………… 2
)
WHERE ROWNUM <= :page*:pgsize+1 ………………………………………………………………… 3
)
WHERE NO BETWEEN (:page-1)*:pgsize+1 AND :pgsize*:page …………………………… 4
Execution Plan
-------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=5 Card=1 Bytes=75)
1 0 FILTER
2 1 VIEW (Cost=5 Card=1 Bytes=75)
3 2 WINDOW (BUFFER) (Cost=5 Card=1 Bytes=49)
4 3 COUNT (STOPKEY)
5 4 VIEW (Cost=5 Card=1 Bytes=49)
6 5 TABLE ACCESS (BY INDEX ROWID) OF '시간별종목거래' (TABLE) (Card=1 Bytes=56)
7 6 INDEX (RANGE SCAN) OF '시간별종목거래_PK' (INDEX (UNIQUE)) (Card=1)다음 버튼을 누를 때마다 :pgsize에는 Fetch해 올 데이터 건수를 입력하고 :page 변수에는 그때 출력하고자 하는 페이지 번호 입력
1: 다음 페이지에 읽을 데이터가 더 있는지 확인하는 용도.
=>cnt 값이:pgsize*:page보다 크면다음 페이지에 출력할 데이터가 더 있음
=> 필요 없는 기능이라면3의+1을 제거하면 됨2:종목코드+거래일시순으로 정렬된 인덱스가 있으면, 정렬 생략3::pgsize=10이고:page=3일 때, 거래일시 순으로31건만읽는다4::pgisze=10이고:page=3일 때, 안쪽 인라인 뷰에서 읽은31건중21~30번째 데이터, 즉3페이지만리턴
뒤쪽 페이지까지 자주 조회할 때
앞쪽 레코드를 스캔하지 않고 해당 페이지 레코드로 바로 찾아가도록 구현
-- :trd_time 변수에 다음 버튼을 누르면 이전 페이지에서 출력한 마지막 거래일시 입력
-- 종목코드+거래일시 인덱스
SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM ( SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM 시간별종목거래 A WHERE :페이지이동 = 'NEXT'
AND 종목코드 = :isu_cd
AND 거래일시 >= :trd_time -- 다음 버튼 클릭시
ORDER BY 거래일시 )
WHERE ROWNUM <= 11
Execution Plan
-------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=5 Card=1 Bytes=49)
1 0 COUNT (STOPKEY)
2 1 VIEW (Cost=5 Card=1 Bytes=49)
3 2 FILTER
4 3 TABLE ACCESS (BY INDEX ROWID) OF '시간별종목거래' (TABLE) (Card=1 Bytes=56)
5 4 INDEX (RANGE SCAN) OF '시간별종목거래_PK' (INDEX (UNIQUE)) (Card=1)-- 이전 버튼 눌렀을 때
-- :trd_time 변수에는 이전 페이지에서 출력한 첫 번째 거래일시 바인딩
SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM ( SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM 시간별종목거래 A
WHERE :페이지이동 = 'PREV'
AND 종목코드 = :isu_cd
AND 거래일시 <= :trd_time --이전 버튼
ORDER BY 거래일시 DESC --)
WHERE ROWNUM <= 11
ORDER BY 거래일시
Execution Plan
-------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=1 Card=1 Bytes=49)
1 0 SORT (ORDER BY) (Cost=1 Card=1 Bytes=49)
2 1 COUNT (STOPKEY)
3 2 VIEW (Cost=5 Card=1 Bytes=49)
4 3 FILTER
5 4 TABLE ACCESS (BY INDEX ROWID) OF '시간별종목거래' (TABLE) (Card=1 Bytes=56)
6 5 INDEX (RANGE SCAN DESCENDING) OF '시간별종목거래_PK' (INDEX (UNIQUE)) (Card=1)Union All 활용
SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM ( SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM 시간별종목거래
WHERE :페이지이동 = 'NEXT'
-- 첫 페이지 출력 시에도 'NEXT' 입력 AND 종목코드 = :isu_cd AND 거래일시 >= :trd_time
ORDER BY 거래일시 )
WHERE ROWNUM <= 11
UNION ALL
SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM ( SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM 시간별종목거래
WHERE :페이지이동 = 'PREV' AND 종목코드 = :isu_cd AND 거래일시 <= :trd_time
ORDER BY 거래일시 DESC )
WHERE ROWNUM <= 11
ORDER BY 거래일시5. 윈도우 함수 활용
상태코드는 장비상태가 바뀔 때만 저장
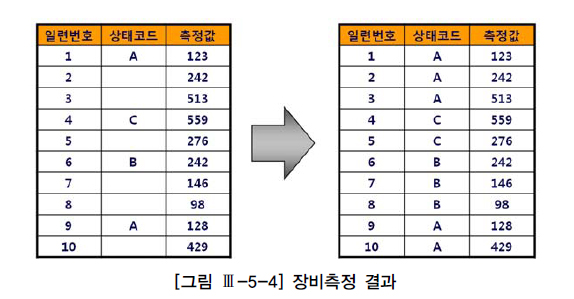
-- 상태코드가 NULL이면 최근에 상태코드가 바뀐 레코드의 값을 보여줌
select 일련번호, 측정값 ,
(select max(상태코드) from 장비측정 where 일련번호 <= o.일련번호 and 상태코드 is not null) 상태코드
from 장비측정 o
order by 일련번호위 쿼리는 일련번호에 최소한 인덱스가 있어야하며, 일련번호+상태코드로 구성된 인덱스가 있으면 최적
-- 부분범위처리 방식으로 앞쪽 일부만 보다가 멈춘다면
select 일련번호, 측정값 ,
(select /*+ index_desc(장비측정 장비측정_idx) */ 상태코드
from 장비측정
where 일련번호 <= o.일련번호
and 상태코드 is not null
and rownum <= 1) 상태코드
from 장비측정 o
order by 일련번호--전체 결과를 다 읽어야 한다면
select 일련번호, 측정값 ,
last_value(상태코드 ignore nulls) over(order by 일련번호
rows between unbounded preceding and current row) 상태코드
from 장비측정
order by 일련번호6. With 구문 활용
With 절을 처리하는 DBMS 내부 실행 방식
Materialize 방식: 내부적으로임시 테이블을 생성함으로써반복 재사용
=>With절을 선언한 SQL문이 실행되는 동안만 유지Inline 방식: 물리적으로 임시 테이블을 생성하지 않고참조된 횟수만큼런타임시 반복 수행
with 위험고객카드 as ( select 카드.카드번호, 고객.고객번호
from 고객, 카드
where 고객.위험고객여부='Y'
and 고객.고객번호 = 카드발급.고객번호 )