📔설명
SQL 옵티마이징 원리, SQL 공유 및 재사용, 쿼리 변환에 대해 알아보자
🍲SQL 옵티마이징 원리
1. 옵티마이저 소개
옵티마이저 종류
규칙기반 옵티마이저(Rule-Based Optimizer, RBO) : 휴리스틱(Heuristic) 옵티마이저 라고 불리며, 미리 정해 놓은 규칙에 따라 액세스 경로 평가 및 실행계획 선택
=> 규칙 : 액세스 경로별 우선순위로서, 인덱스/연산자/조건절 형태가 순위를 결정짓는 주요인
비용기반 옵티마이저(Cost-Based Optimizer, CBO) : 비용을 기반으로 최적화 수행
=> 비용(Cost) : 쿼리를 수행하는 데 소요되는 일량 또는 시간
=> 비용은 어디까지나 예상치
=> 미리 구해놓은 테이블과 인덱스에 대한 여러 통계정보를 기초로 각 오퍼레이션 단계별 예상 비용을 산정하고, 이를 합산한 총비용이 가장 낮은 실행계획 선택
=> 오브젝트 통계 항목 : 레코드 개수, 블록 개수, 평균 행 길이, 칼럼 값의 수, 칼럼 값 분포, 인덱스 높이, 클러스터링 팩터 등
=> 시스템 통계정보 : CPU 속도, 디스크 I/O 속도 등

최적화 목표
전체 처리속도 최적화 : 쿼리 최종 결과 집합을 끝까지 읽는 것을 전제로, 시스템 리소스를 가장 적게 사용하는 실행계획 선택
alter system set optimizer_mode = all_rows; -- 시스템 레벨 변경
alter session set optimizer_mode = all_rows; -- 세션 레벨 변경
select /*+ all_rows */ * from t where … ; -- 쿼리 레벨 변경최초 응답속도 최적화 : 전체 결과 집합 중 일부만 읽다가 멈추는 것을 전제로, 가장 빠른 응답 속도를 낼 수 있는 실행계획 선택
=> 해당 모드로 데이터를 끝까지 읽는다면, 전체 처리속도 최적화 실행계획보다 더 많은 리소스 사용, 전체 수행 속도도 느려짐
=> ex. first_rows_n으로 지정해 first_rows_10으로 지정하면 사용자가 전체 결과 집합 중 처음 10개 로우만 읽고 멈추는 것을 전제로 가장 빠른 응답 속도 내는 실행계획 선택
--oracle
select /*+ first_rows(10) */ * from t where ;
--sql server
select * from t where OPTION(fast 10);2. 옵티마이저 행동에 영향을 미치는 요소
SQL과 연산자 형태
결과가 같더라도 SQL을 어떤 형태로 작성했는지 또는 어떤 연산자를 사용했는지에 따라 옵티마이저가 다른 선택을 할 수 있음
옵티마이징 팩터
인덱스, IOT, 클러스터링, 파티셔닝, MV 등을 어떻게 구성했는지에 따라 실행계획과 성능 달라짐
DBMS 제약 설정
개체 무결성, 참조 무결성, 도메인 무결성 등을 위해 DBMS가 제공하는 PK, FK, Check, Not Null 같은 제약 설정 기능을 이용할 수 있고, 이 제약 설정은 옵티마이저가 쿼리 성능 최적화하는 데에 매우 중요한 정보 제공
ex. 인덱스 칼럼에 Not Null 제약이 설정돼 있으면, 옵티마이저는 전체 개수를 구하는 count에 해당 인덱스 활용 가능
옵티마이저 힌트
옵티마이저의 판단보다 사용자가 지정한 옵티마이저 힌트가 우선
통계정보
통계정보가 옵티마이저에게 미치는 영향력은 절대적. CBO의 모든 판단 기준은 통계정보에서 나옴
옵티마이저 관련 파라미터
SQL, 데이터, 통계정보, 하드웨어 등 모든 환경이 동일하더라도 DBMS 버전을 업그레이드하면 옵티마이저가 다르게 작동할 수 있는데, 이는 옵티마이저 관련 파라미터가 추가 또는 변경되면서 나타나는 현상
DBMS 버전과 종류
옵티마이저 관련 파라미터가 같더라도 버전에 따라 실행계획이 다를 수 있고, 같은 SQL이라도 DBMS 종류에 따라 내부적으로 처리하는 방식이 다를 수 있음
3. 옵티마이저의 한계
옵티마이징 팩터의 부족
옵티마이저는 주어진 환경에서 가장 최적의 실행계획을 수립하기 위해 정해진 기능을 수행할 뿐이며, 아무리 정교하고 기술적으로 발전해도 사용자가 적절한 옵티마이징 팩터(인덱스, IOT, 클러스터링, 파티셔닝 등)를 제공하지 않는다면 좋은 실행계획 수립 불가
통계정보의 부정확성
100% 정확한 통계정보를 유지하기는 현실적으로 불가능하다. 칼럼 분포가 고르지 않을 때 칼럼 히스토그램이 반드시 필요한데, 이를 수집하고 유지하는 비용이 만만치 않음
칼럼을 결합했을 때의 모든 결합 분포를 미리 구해두기 어려운 것도 큰 제약 중 하나
바인드 변수 사용 시 균등분포 가정
바인드 변수를 사용한 SQL에는 무용지물이다. 조건절에 바인드 변수를 사용하면 옵티마이저는 균등분포를 가정하고 비용을 계산
비현실적인 가정
예전 Oracle에서 Single Block I/O와 Multiblock I/O의 비용을 같게 평가하고 데이터 블록의 캐싱 효과도 고려하지 않았던 것
규칙에 의존하는 CBO
CBO라도 부분적으로는 규칙에 의존한다.
ex. 최적화 목표를 최초 응답속도에 맞추면, order by 소트를 대체할 인덱스가 있을 때 무조건 그 인덱스 사용
하드웨어 성능 특성
옵티마이저는 기본적으로 옵티마이저 개발팀이 사용한 하드웨어 사양에 맞춰져 있어서, 실제 운영 시스템의 하드웨어 사양이 그것과 다를 때 옵티마이저가 잘못된 실행계획을 수립할 가능성이 높아짐
애플리케이션 특성(I/O 패턴, 부하 정도)에 의해서도 하드웨어 성능은 달라짐
4. 통계정보를 이용한 비용계산 원리
CBO는 SQL 문장에서 액세스할 데이터 특성을 고려하기 위해 통계정보 이용

선택도
선택도(Selectivity) : 전체 대상 레코드 중에서 특정 조건에 의해 선택될 것으로 예상되는 레코드 비율
선택도->카디널리티->비용-> 액세스 방식, 조인 순서, 조인 방법 등 결정
히스토그램이 있다면 그것으로 선택도 산정, 히스토그램 없이 등치(=) 조건에 대한 선택도는 아래와 같음
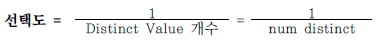
카디널리티
카디널리티(Cardinality) : 특정 액세스 단계를 거치고 난 후 출력될 것으로 예상되는 결과 건수
=> 총 로우 수에 선택도를 곱해서 구함
카디널리티=총 로우 수 X 선택도
칼럼 히스토그램이 없을 때 =조건에 의한 선택도는 1/num_distinct이므로 카디널리티는 아래와 같음
카디널리티= 총 로우 수 X 선택도=num_rows/num_distinct
select * from 사원 where 부서 = :부서부서 칼럼의 distinct value 개수가 10이면, 선택도는 0.1이고, 총 사원 수가 1000명일 때, 카디널리티는 100이 됨 (1000*0.1)
select * from 사원 where 부서 = :부서 and 직급 = :직급;조건절이 두 개 이상일 때는 각 칼럼의 선택도와 전체 로우 수를 곱해 주기만 하면 됨
직급이 총 4종류라, 선택도는 0.25이며, 위 쿼리 카디널리티는 25(1000*0.25*0.1)가 된다
히스토그램
미리 저장된 히스토그램 정보가 있다면, 옵티마이저는 그것을 사용해 더 정확하게 카디널리티 구함
=> 특히 분포가 균일하지 않은 칼럼으로 조회시 효과 발휘
=> 도수분포, 높이 균형, 상위도수분포, 하이브리드
-
도수분포 히스토그램:값별로빈도수를 저장하는 히스토그램
=> 칼럼이 가진값의 수가적을 때 사용, 칼럼 값의 수가 적기 때문에 각각 하나의 버킷을 할당하는 것이 가능
-
높이균형 히스토그램: 칼럼이 가진값의 수가 아주 많아각각 하나의 버킷을 할당하기 어려울 때 사용
=>히스토그램 버킷을 값의 수보다적게 할당하기 때문에 하나의 버킷이여러 개의 값담당
ex. 값의 수가 1000개, 히스토그램을 위해 할당한 버킷 수 100개면 하나의 버킷이 평균적으로 10개의 값 대표
=>각 버킷의 높이가같음
=> 각 버킷은{1/(버킷 개수) x 100} %의 데이터 분포를 가짐
=>각 버킷이 갖는빈도수는총 레코드 개수/버킷 개수로 구함

비용
옵티마이저 비용 모델에는 I/O 비용 모델과 CPU 비용 모델이 있음
=> I/O 비용 모델 : 예상되는 I/O 요청 횟수만을 쿼리 수행 비용으로 간주
=> CPU 비용 모델 : I/O 비용 모델에 시간 개념을 더해 비용 산정
인덱스를 경유한 테이블 액세스 비용
=> I/O 비용 모델에서 비용은디스크 I/O Call 횟수(논리적,물리적으로 읽은 블록 개수가 아닌 I/O Call 횟수)의미
=>인덱스를 경유한 테이블 액세스 시에는Single Block I/O방식이 사용되는데,디스크에서 한 블록을 읽을 때마다한 번의 I/O Call을 일으키는 방식이므로 읽게 될물리적 블록 개수가I/O Call 횟수와일치
비용 = blevel -- 인덱스 수직적 탐색 비용
+ (리프 블록 수 X 유효 인덱스 선택도) -- 인덱스 수평적 탐색 비용
+ (클러스터링 팩터 X 유효 테이블 선택도) -- 테이블 랜덤 액세스 비용
Full Scan에 의한 테이블 액세스 비용
=>Multiblock I/O 방식을 사용하므로총 블록 수를Multiblock I/O 단위로나눈만큼 I/O Call 발생
ex. 100 블록을 8개씩 나누어 읽는 다면 총13번의 I/O Call이 발생
=>Multiblock I/O 단위가증가할수록I/O Call 횟수가 줄고예상비용도 줄게 됨
🍝SQL 공유 및 재사용
1. 소프트 파싱 vs. 하드 파싱
라이브러리 캐시/프로시저 캐시 : 시스템 공유 메모리에서 SQL과 실행계획이 캐싱되는 영역
=> 사용자가 SQL 실행시, 먼저 SQL 파서(Parser)가 SQL 문장에 문법적 오류가 없는지 검사(Syntax 검사)
=> 문법적으로 오류가 없으면 의미상 오류가 없는지 검사(Semantic 검사)
ex. 존재하지 않거나 권한이 없는 객체 사용했는지 등
=> 검사를 마치면 사용자가 발행한 SQL과 그 실행계획이 라이브러리 캐시에 캐싱됐는지 확인
=> 만약 캐싱돼 있다면, 최적화 과정을 거치지 않고 바로 실행 가능
소프트 파싱(Soft Parsing): SQL과 실행계획을캐시에서 찾아곧바로 실행단계로 넘어가는 경우하드 파싱(Hard Parsing): SQL과 실행계획을캐시에서 찾지 못해최적화 과정을 거치고 나서 실행단계로 넘어가는 경우
SQL마다 해시 값에 따라 여러 해시 버킷으로 나누어 저장
SQL 공유 및 재사용의 필요성
옵티마이저가 SQL 최적화 과정에서 사용하는 정보
테이블, 칼럼, 인덱스 구조에 관한 기본 정보오브젝트 통계: 테이블 통계, 인덱스 통계, (히스토그램을 포함한) 칼럼 통계시스템 통계: CPU 속도, Single Block I/O 속도, Multiblock I/O 속도 등옵티마이저 관련 파라미터
어려운(hard) 작업을 거쳐 생성한 내부 프로시저를 한번만 사용하고 버린다면 비효율 발생
=> 파싱과 최적화 과정을 거친 SQL과 실행계획을 여러 사용자가 공유하면서 재사용할 수 있도록 공유 메모리에 캐싱해두는 이유
실행계획 공유 조건
SQL 수행 절차
문법적 오류와의미상 오류가 없는지 검사- 해시 함수로부터 반환된
해시 값으로라이브러리 캐시내 해시버킷 찾아감 - 찾아간 해시버킷에 체인으로 연결된 엔트리를 차례로
스캔하면서같은 SQL 문장을 찾음 - SQL 문장을 찾으면 함께 저장된
실행계획을 가지고 바로 실행 - 찾아간 해시버킷에서 SQL 문장을 찾지 못하면
최적화 수행 - 최적화를 거친 SQL과 실행계획을 방금 탐색한
해시버킷 체인에 연결 - 방금 최적화한 실행계획을 가지고
실행
캐시에서 SQL을 찾기 위해 사용되는 키 값이 SQL 문장 그 자체
실행계획을 공유하지 못하는 경우
- 공백 문자 또는 줄바꿈
select * from CUSTOMER;
select * from CUSTOMER;- 대소문자 구분
select * from CUSTOMER;
select * from customer;- 주석(Comment)
select * from CUSTOMER;
select /* 주석문 */ * from CUSTOMER;- 테이블 Owner 명시
select * from CUSTOMER;
select * from HR.CUSTOMER;- 옵티마이저 힌트 사용
select * from CUSTOMER;
select /*+ all_rows */ * from CUSTOMER;- 조건절 비교 값
select * from CUSTOMER where login_id='tommy';
select * from CUSTOMER where login_id='dangdang';리터럴(Literal) SQL : 사용자가 입력한 값을 조건절에 문자열로 붙여가며 매번 다른 SQL로 실행
2. 바인드 변수 사용
바인드 변수의 중요성
모든 프로시저의 처리 루틴이 같다면 여러 개 생성하기보다 아래처럼 파라미터로 받아 하나의 프로시저로 처리하도록 하는 것이 마땅
procedure LOGIN(login_id in varchar2) { ... }바인드 변수(Bind Variable) : 파라미터 드리븐 방식으로 SQL을 작성하는 방법
=> 하나의 프로시저를 공유하면서 반복 재사용 가능
select * from customer where login_id = : login_id바인드 변수를 사용하면 이를 처음 수행한 세션이 하드 파싱을 통해 실행계획을 생성, 해당 실행계획을 한번 사용하고 버리는 것이 아니라 라이브러리에 캐싱해 둠으로써 같은 SQL을 수행하는 다른 세션들이 반복 재사용할 수 있도록 함
--바인드 변수 사용해 SQL 2만번 수행
call count cpu elapsed disk query current rows
------ ---- ----- ------ ----- ----- ------ -----
Parse 20000 0.16 0.17 0 0 0 0
Execute 20000 0.22 0.42 0 0 0 0
Fetch 20000 0.45 0.47 0 60000 0 20000
------ ---- ----- ------ ----- ----- ------ -----
total 60000 1.23 1.07 0 60000 0 20000
Misses in library cache during parse: 1Parse Call : SQL문장을 캐시에서 찾으려고 시도한 횟수
=> 최초 Parse Call이 발생한 시점에 라이브러리 캐시에서 찾지 못해 하드 파싱 수행
바인드 변수 사용시 효과는 아주 분명
=> SQL과 실행계획을 여러 개 캐싱하지 않고, 하나를 반복 재사용하므로 파싱 소요시간과 메모리 사용량을 줄여줌. 궁극적으로 시스템 전반의 CPU와 메모리 사용률을 낮춰 데이터베이스 성능과 확장성을 높임, 특히 동시 사용자 접속이 많을 때 효과 좋음
아래는 바인드 변수를 쓰지 않아도 무방
배치 프로그램이나DW, OLAP등 정보계 시스템에서 사용되는Long Running 쿼리
=>파싱 소요시간이총 쿼리 소요시간에서 차지하는비중이 매우 낮고,수행빈도도 낮아하드파싱에 의한 라이브러리 캐시부하를 유발할 가능성이 낮음
=>바인드 변수대신상수 조건절을 사용함으로써 옵티마이저가칼럼 히스토그램을 활용할 수 있도록 하는 것이 유리조건절 칼럼의값 종류(Distinct Value)가소수일 때
=> 값 분포가 균일하지 않아옵티마이저가칼럼 히스토그램 정보를 활용하도록 유도하고자 할 때
특히 OLTP 환경에선 반드시 바인드 변수를 사용할 것을 권고
DBMS는 조건절 비교 값이 리터럴 상수일 때 이를 자동으로 변수화해주는 기능 제공
=> SQL Server : 단순 매개 변수화
=> Oracle : cursor_sharing 파라미터를 FORCE나 SIMILAR로 설정(기본 EXACT)
바인드 변수 사용 시 주의사항
변수를 바인딩하는 시점이 최적화 이후
=> 바인드 변수 사용시 SQL이 최초 수행될 때 최적화를 거친 실행계획을 캐시에 저장하고, 실행시점에는 그것을 그대로 가져와 값만 다르게 바인딩
그러므로 옵티마이저는 조건절 칼럼의 데이터 분포가 균일하다는 가정을 세우고 최적화 수행
=> 칼럼 히스토그램 정보 활용 불가
바인드 변수 부작용을 극복하기 위한 노력
바인드 변수 Peeking/Parameter Sniffing : SQL이 첫 번째 수행될 때의 바인드 변수 값을 살짝 훔쳐 보고, 그 값에 대한 칼럼 분포를 이용해 실행계획을 결정
=> 처음 실행될 때 입력된 값과 전혀 다른 분포를 갖는 값이 나중에 입력되면 성능 저하
=> 처음 입력한 값이 무엇이냐에 따라 실행계획이 결정
--대부분 비활성화하고 운영
alter system set "_optim_peek_user_binds" = FALSE ;적응형 커서 공유(Adaptive Cursor Sharing) : 입력된 변수 값의 분포에 따라 다른 실행계획이 사용되도록 처리
select * from 아파트매물 where 도시 = :CITY ;
--아래로 분리
select /*+ FULL(a) */ *
from 아파트매물 a
where :CITY in ('서울시', '경기도')
and 도시 = :CITY
union all
select /*+ INDEX(a IDX01) */ *
from 아파트매물 a
where :CITY not in ('서울시', '경기도')
and 도시 = :CITY;3. 애플리케이션 커서 캐싱
애플리케이션 커서 캐싱 : SQL 문장의 문법적, 의미적 오류 확인, 해시함수로부터 반환된 해시 값을 이용해 캐시에서 실행계획 찾고, 수행에 필요한 메모리 공간을 할당하는 작업을 반복하는 것을 생략하는 것
--두 개의 옵션으로 감싸 커서를 해제하지 않고 루프 내에서 반복 재사용
for(;;) {
EXEC ORACLE OPTION (HOLD_CURSOR=YES);
EXEC ORACLE OPTION (RELEASE_CURSOR=NO); --
EXEC SQL INSERT …… ; // SQL 수행
EXEC ORACLE OPTION (RELEASE_CURSOR=YES); --
}--애플리케이션에서 커서 캐싱 후 같은 SQL 반복 수행
call count cpu elapsed disk query current rows
----- ------ ----- ------ ----- ----- ------ -----
Parse 1 0.00 0.00 0 0 0 0
Execute 5000 0.18 0.14 0 0 0 0
Fetch 5000 0.17 0.23 0 10000 0 5000
----- ------ ----- ------ ----- ----- ------ -----
total 10001 0.35 0.37 0 10000 0 5000
Misses in library cache during parse: 1일반적인 방식으로 같은 SQL을 반복 수행할 땐 Parse Call 횟수가 Execute Call 횟수와 같게 나타남
=> 트레이스 결과에선 Parse Call이 한 번만 발생했고, 이후 발생X
--묵시적 캐싱(Implicit Caching 옵션 사용해 자바에서 구현
public static void CursorCaching(Connection conn, int count) throws Exception{
// 캐시 사이즈를 1로 지정
((OracleConnection)conn).setStatementCacheSize(1);
// 묵시적 캐싱 기능을 활성화
((OracleConnection)conn).setImplicitCachingEnabled(true);
for (int i = 1; i <= count; i++) {
// PreparedStatement를 루프문 안쪽에 선언
PreparedStatement stmt = conn.prepareStatement(
"SELECT ?,?,?,a.* FROM emp a WHERE a.ename LIKE 'W%'");
stmt.setInt(1,i);
stmt.setInt(2,i);
stmt.setString(3,"test");
ResultSet rs=stmt.executeQuery();
rs.close();
// 커서를 닫더라도 묵시적 캐싱 기능을 활성화 했으므로 닫지 않고 캐시에 보관하게 됨
stmt.close();
}
}
// 또는 아래처럼
public static void CursorHolding(Connection conn, int count) throws Exception{
// PreparedStatement를 루프문 바깥에 선언
PreparedStatement stmt = conn.prepareStatement(
"SELECT ?,?,?,a.* FROM emp a WHERE a.ename LIKE 'W%'");
ResultSet rs;
for (int i = 1; i <= count; i++) {
stmt.setInt(1,i);
stmt.setInt(2,i);
stmt.setString(3,"test");
rs=stmt.executeQuery();
rs.close(); }
// 루프를 빠져 나왔을 때 커서를 닫는다.
stmt.close();
}PL/SQL에서는 자동적으로 커서 캐싱=> static SQL을 사용할 때만
4. Static SQL vs. Dynamic SQL
Static SQL
Static SQL : String형 변수에 담지 않고 코드 사이에 직접 기술한 SQL문 (=Embedded SQL)
int main() {
printf("사번을 입력하십시오 : ");
scanf("%d", &empno);
EXEC SQL WHENEVER NOT FOUND GOTO notfound;
EXEC SQL SELECT ENAME INTO :ename
FROM EMP
WHERE EMPNO = :empno;
printf("사원명 : %s.\n", ename);
notfound:
printf("%d는 존재하지 않는 사번입니다. \n", empno);
}Dynamic SQL
Dynamic SQL : String형 변수에 담아서 기술하는 SQL문
=> String 변수를 사용하므로 조건에 따라 SQL문을 동적으로 바꿀 수 있고, 또는 런타임 시에 사용자로부터 SQL문의 일부 또는 전부를 입력받아 실행 가능
int main() {
char select_stmt[50] = "SELECT ENAME FROM EMP WHERE EMPNO = :empno";
// scanf("%c", &select_stmt); → SQL문을 동적으로 입력 받을 수도 있음
EXEC SQL PREPARE sql_stmt FROM :select_stmt;
EXEC SQL DECLARE emp_cursor CURSOR FOR sql_stmt;
EXEC SQL OPEN emp_cursor USING :empno;
EXEC SQL FETCH emp_cursor INTO :ename;
EXEC SQL CLOSE emp_cursor;
printf("사원명 : %s.\n", ename);
}PowerBuilder, PL/SQL, Pro*C, SQLJ 정도가 Static SQL을 지원하며, 그 외 개발언어는 모두 String 변수에 담아서 실행
=> Ad-hoc 쿼리 툴(ex. Toad, Orange, SQL*Plus 등)에서 작성하는 SQL도 모두 Dynamic SQL
바인드 변수의 중요성 재강조
Dynamic으로 개발하더라도 바인드 변수만 잘 사용했다면 라이브러리 캐시 효율을 떨어뜨리지 않는다.
🥣쿼리 변환
1. 쿼리 변환이란?
쿼리 변환(Query Transformation) : 옵티마이저가 SQL을 분석해 의미적으로 동일하면서도 더 나은 성능이 기대되는 형태로 재작성하는 것
=> 옵티마이저의 서브엔진 중 Query Transformer가 역할 담당
쿼리 변환 방식
휴리스틱(Heuristic) 쿼리 변환: 결과만 보장된다면무조건 쿼리 변환수행
=>규칙 기반 최적화 기법비용기반(Cost-based) 쿼리 변환: 변환된 쿼리의비용이 더낮을 때만 그것을 사용
2. 서브쿼리 Unnesting
서브쿼리 Unnesting : 중첩된 서브쿼리(Nested Subquery)를 풀어내는 것
=> 서브쿼리를 메인쿼리와 같은 레벨로 풀어냄
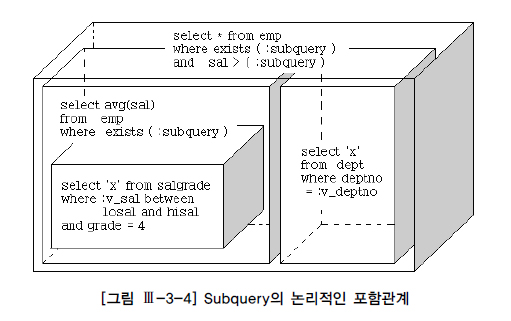
중첩된 서브쿼리는 메인쿼리와 부모와 자식이라는 종속적이고 계층적인 관계 존재
=> 논리적인 관점에서 처리과정은 필터 방식, 즉 메인 쿼리에서 읽히는 레코드마다 서브쿼리를 반복 수행하면서 조건에 맞지 않는 데이터를 골라내는 것
서브쿼리를 처리하는 데 있어 필터 방식이 항상 최적의 수행속도를 보장하지 못하므로 옵티마이저는 둘 중 하나 선택
- 동일한 결과를 보장하는
조인문으로 변환하고나서 최적화 =>서브쿼리 Unnesting - 서브쿼리를
Unnesting하지 않고, 원래대로 둔 상태에서 최적화
=>서브쿼리에Filter오퍼레이션 나타남
-- no_unnest
select * from emp
where deptno in (select deptno from dept)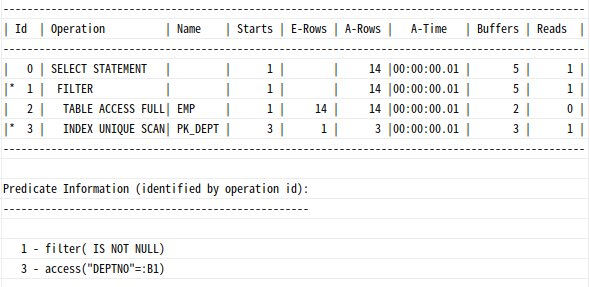
서브쿼리의 조건절이 바인드 변수로 처리되었다.
=> 서브쿼리를 별도의 서브플랜으로 최적화
--unnest 시 아래처럼 변함
select *
from (select deptno from dept) a, emp b
where b.deptno = a.deptno
--위와 동일
select emp.*
from dept, emp
where emp.deptno = dept.deptno| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 350 | 2 (0) |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 3 | 99 | 1 (0) |
| 2 | NESTED LOOPS | | 10 | 350 | 2 (0) |
| 3 | INDEX FULL SCAN | DEPT_PK | 4 | 8 | 1 (0) |
|* 4| INDEX RANGE SCAN | EMP_DEPTNO_IDX | 3 | | 0 (0) |
------------------------------------------------------------------
Predicate Information (identified by operation id):
------------------------------------------------------------------
4 - access("DEPTNO"="DEPTNO")서브쿼리를 Unnesting한 결과가 항상 더나은 성능 보장X
서브쿼리 힌트
unnest: 서브쿼리를Unnesting함으로써조인방식으로 최적화no_unnest: 서브쿼리를그대로 둔상태에서필터 방식으로 최적화
서브쿼리가 M쪽 집합이거나 Nonunique 인덱스일 때
select * from dept
where deptno in (select deptno from emp)1쪽 집합을 기준으로 M쪽 집합을 필터링 하는 형태이므로 당연히 서브쿼리 쪽 emp 테이블 deptno 칼럼에는 unique 인덱스가 없다.
select *
from (select deptno from emp) a, dept b
where b.deptno = a.deptno그런데 만약 옵티마이저가 임의로 위와 같이 변경한다면, 결과 오류가 발생
select * from emp
where deptno in (select deptno from dept)M쪽 집합을 드라이빙해 1쪽 집합을 서브쿼리로 필터링 하도록 작성했으므로 조인문으로 바꿔도 결과에 오류 발생X
=> dept 테이블에 PK/Unique 제약이나 Unique 인덱스가 없으면, 옵티마이저는 결과를 확신할 수 없어 쿼리 변환 시도X
위와 같은 경우 옵티마이저는 두 가지 방식 중 하나 선택하는데, Unnesting 후 어느 쪽 집합을 먼저 드라이빙 하느냐에 따라 달라짐
=> 1쪽 집합임을 확신할 수 없는 서브쿼리 쪽 테이블이 드라이빙된다면, 먼저 sort unique 오퍼레이션을 수행함으로써 1쪽 집합으로 만든 다음 조인
=> 메인 쿼리 쪽 테이블이 드라이빙된다면 세미 조인 방식으로 조인
-- sort unique 오퍼레이션
alter table dept drop primary key;
create index dept_deptno_idx on dept(deptno);
select * from emp
where deptno in (select deptno from dept);
-----------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |
-----------------------------------------------------------
| 0 | SELECT STATEMENT | | 11 | 440 |
| 1 | TABLE ACCESS BY INDEX ROWID | EMP | 4 | 148 |
| 2 | NESTED LOOPS | | 11 | 440 |
| 3 | SORT UNIQUE | | 4 | 12 |
| 4 | INDEX FULL SCAN | DEPT_DEPTNO_IDX | 4 | 12 |
|* 5| INDEX RANGE SCAN | EMP_DEPTNO_IDX | 5 | |
-----------------------------------------------------------
Predicate Information (identified by operation id):
-----------------------------------------------------------
5 - access("DEPTNO"="DEPTNO")옵티마이저는 dept 테이블이 unique 한 집합임을 확신할 수 없어 sort unique 오퍼레이션을 수행
--내부적으로 쿼리 변환
select b.*
from (select /*+ no_merge */ distinct deptno from dept order by deptno) a, emp b
where b.deptno = a.deptno;--세미조인
select * from emp
where deptno in (select deptno from dept)
--------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU) |
--------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 350 | 3 (0) |
| 1 | NESTED LOOPS SEMI | | 10 | 350 | 3 (0) |
| 2 | TABLE ACCESS FULL | EMP | 10 | 330 | 3 (0) |
|* 3 | INDEX RANGE SCAN | DEPT_IDX | 4 | 8 | 0 (0) |
--------------------------------------------------------------
Predicate Information (identified by operation id):
--------------------------------------------------------------
3 - access("DEPTNO"="DEPTNO")
sort unique 오퍼레이션을 수행하지 않고도 결과 집합이 M쪽 집합으로 확장되는 것을 방지하는 알고리즘 사용
=> Outer 테이블의 한 로우가 Inner 테이블의 한 로우와 조인에 성공하는 순간 진행을 멈추고, Outer 테이블의 다음 로우를 계속 처리
for(i=0; ; i++) { // outer loop
for(j=0; ; j++) { // inner loop
if(i==j) break;
}
}3. 뷰 Merging
-- 인라인 뷰
select *
from (select * from emp where job = 'SALESMAN') a ,
(select * from dept where loc = 'CHICAGO') b
where a.deptno = b.deptno
-- 옵티마이저는 가급적 아래처럼 풀어내려는 습성
select *
from emp a, dept b
where a.deptno = b.deptno
and a.job = 'SALESMAN'
and b.loc = 'CHICAGO';뷰 Merging : 액세스 쿼리 블록(뷰 참조하는 쿼리 블록)과 뷰 쿼리 블록을 머지(merge)
create or replace view emp_salesman
as
select empno, ename, job, mgr, hiredate, sal, comm, deptno
from emp
where job = 'SALESMAN' ;select e.empno, e.ename, e.job, e.mgr, e.sal, d.dname
from emp_salesman e, dept d
where d.deptno = e.deptno and e.sal >= 1500 ;-- 뷰 Merging X 시
------------------------------------------
Execution Plan
------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=3 Card=2 Bytes=156)
1 0 NESTED LOOPS (Cost=3 Card=2 Bytes=156)
2 1 VIEW OF 'EMP_SALESMAN' (VIEW) (Cost=2 Card=2 Bytes=130)
3 2 TABLE ACCESS (BY INDEX ROWID) OF 'EMP' (TABLE) (Cost=2 Card=2)
4 3 INDEX (RANGE SCAN) OF 'EMP_SAL_IDX' (INDEX) (Cost=1 Card=7)
5 1 TABLE ACCESS (BY INDEX ROWID) OF 'DEPT' (TABLE) (Cost=1 Card=1 Bytes=13)
6 5 INDEX (UNIQUE SCAN) OF 'DEPT_PK' (INDEX (UNIQUE)) (Cost=0 Card=1)-- 뷰 Merging 시 쿼리
select e.empno, e.ename, e.job, e.mgr, e.sal, d.dname
from emp e, dept d
where d.deptno = e.deptno
and e.job = 'SALESMAN'
and e.sal >= 1500;
----------------------------------------
Execution Plan
----------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=3 Card=2 Bytes=84)
1 0 NESTED LOOPS (Cost=3 Card=2 Bytes=84)
2 1 TABLE ACCESS (BY INDEX ROWID) OF 'EMP' (TABLE) (Cost=2 Card=2 Bytes=58)
3 2 INDEX (RANGE SCAN) OF 'EMP_SAL_IDX' (INDEX) (Cost=1 Card=7)
4 1 TABLE ACCESS (BY INDEX ROWID) OF 'DEPT' (TABLE) (Cost=1 Card=1 Bytes=13)
5 4 INDEX (UNIQUE SCAN) OF 'DEPT_PK' (INDEX (UNIQUE)) (Cost=0 Card=1)복잡한 연산을 포함하는 뷰를 Merging하면 오히려 성능이 더 나빠짐
group by절select-list에distinct연산자 포함
힌트
mergeno_merge
뷰 Merging이 불가능한 경우
집합 연산자(union, ..)connect by 절ROWNUMpseudo 칼럼select-list에집계 함수(avg, ...)분석 함수
4. 조건절 Pushing
조건절 Pushing : 뷰를 참조하는 쿼리 블록의 조건절을 뷰 쿼리 블록 안으로 밀어 넣는 기능
=> 조건절이 가능한 빨리 처리되도록 뷰 안으로 밀어 넣음
조건절 Pushing 관련 DBMS 기술
조건절 Pushdown: 쿼리 블록밖에 있는 조건절을 쿼리 블록안쪽으로 밀어 넣는 것조건절 Pullup: 쿼리 블록안에 있는 조건절을 쿼리 블록밖으로내오는 것
=> 이것을 다시다른 쿼리 블록에 Pushdown 하는 데 사용조인 조건 Pushdown: NL 조인 수행 중드라이빙 테이블에서 읽은 값을 건건이Inner 쪽뷰 쿼리 블록 안으로 밀어 넣는 것
조건절(Predicate) Pushdown
group by 절을 포함한 뷰를 처리할 때, 쿼리 블록 밖에 있는 조건절을 쿼리 블록 안쪽에 밀어 넣을 수 있다면, group by 해야 할 데이터 양을 줄일 수 있음
select deptno, avg_sal
from (select deptno, avg(sal) avg_sal from emp group by deptno) a
where deptno = 30;
--------------------------------------------------
Execution Plan
--------------------------------------------------
0 SELECT STATEMNT
1 VIEW |
2 SORT GROUP BY NOSORT
3 TABLE ACCESS BY INDEX ROWID | EMP
4 INDEX RANGE SCAN | EMP_DEPTNO_IDX
--------------------------------------------------
Predicate Information (identified by operation id):
--------------------------------------------------
4 - access("DEPTNO"=30)조건절 Pushing이 작동해 emp_deptno_idx 인덱스를 사용
조건절 Pullup
조건절 Pullup : 조건절 안쪽에 잇는 조건들을 바깥쪽으로 끄집어 내는 것
=> 다시 Pushdown에 사용
select * from
(select deptno, avg(sal) from emp where deptno=10 group by deptno) e1,
(select deptno, min(sal), max(sal) from emp group by deptno) e2
where e1.deptno = e2.deptno;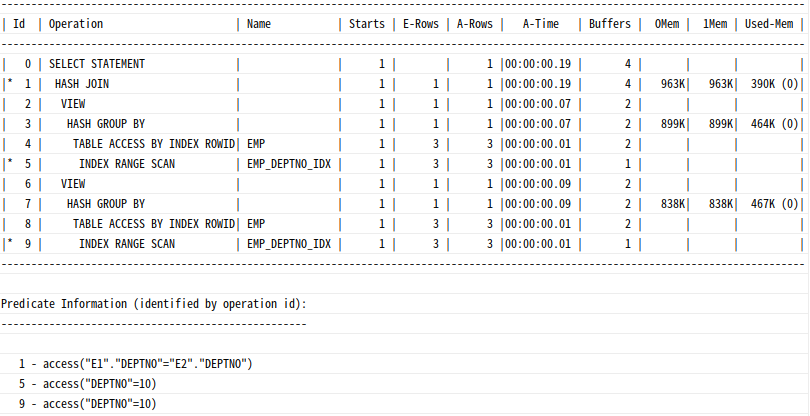
인라인 뷰 e2에는 deptno=10 조건이 없으나, Predicate 정보를 보면 양쪽 모두 해당 조건을 액세스 조건으로 사용한 것 확인 가능
--아래로 쿼리 변환
select * from
(select deptno, avg(sal) from emp where deptno=10 group by deptno) e1,
(select deptno, min(sal), max(sal) from emp where deptno=10 group by deptno) e2
where e1.deptno = e2.deptno;조인 조건 Pushdown
조인 조건 Pushdown : 조인 조건절을 뷰 쿼리 블록 안으로 밀어 넣는 것
=> NL 조인 수행 중에 드라이빙 테이블에서 읽은 조인 칼럼을 Inner 쪽 뷰 쿼리 블록 내에서 참조할 수 있도록 하는 기능
select d.deptno, d.dname, e.avg_sal
from dept d
,(select /*+no_merge push_pred */ deptno, avg(sal) avg_sal from emp group by deptno) e
where e.deptno(+) = d.deptno;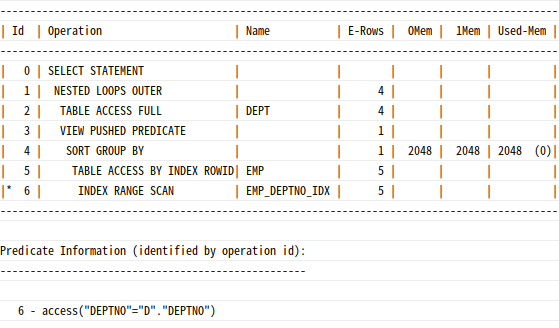
VIEW PUSHED PREDICATE 가 나타났으며, 이는 dept 테이블로부터 넘겨진 deptno에 대해서만 group by를 수행함
-- 조인 조건 Pushdown을 지원하지 않는 DBMS 사용 시
select deptno, dname
,to_number(substr(sal,1,7)) avg_sal
,to_number(substr(sal,8,7)) min_sal
,to_number(substr(sal,15)) max_sal
from (
select /*+ no_merge */ d.deptno, d.dname
,(
select lpad(avg(sal),7) || lpad(min(sal),7) || max(sal)
from emp
where deptno=d.deptno
) sal
from dept d
) 5. 조건절 이행
조건절 이행 : A=B 이고 B=C 이면 A=C 이다 라는 추론을 통해 새로운 조건절을 내부적으로 생성
select * from dept d, emp e
where e.job='MANAGER'
and e.deptno = 10
and d.deptno = e.deptno;0 SELECT STATEMENT
1 NESTED LOOPS
2 TABLE ACCESS BY INDEX ROWID
3 INDEX UNIQUE SCAN
4 TABLE ACCESS BY INDEX ROWID
5 INDEX RANGE SCAN
Predicate Information(identified by operation id):
-----------------------------------------------------
3 - access("D"."DEPTNO"=10)
5 - access("E"."DEPTNO"=10 AND "E"."JOB"="MANAGER")dept 테이블에도 같은 필터 조건이 추가된 것 확인 가능
--쿼리 변환
select * from dept d, emp e
where e.job= 'MANAGER'
and e.deptno=10
and d.deptno=106. 불필요한 조인 제거
조인 제거(Join Elimination) : 1:M 관계인 두 테이블을 조인하는 쿼리문에서 조인문을 제외한 1쪽 테이블을 어디에서도 참조하지 않는다면, 쿼리 수행시 1쪽 테이블은 읽지 않아도 되므로, 옵티마이저는 M쪽 테이블만 읽도록 쿼리 변환
select e.empno, e.ename, e.deptno, e.sal, e.hiredate
from dept d, emp e
where d.deptno=e.deptno;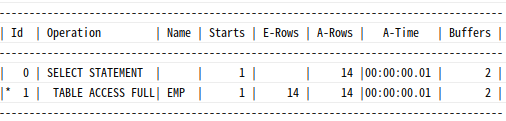
조인 제거 기능이 작동하려면 PK와 FK 제약이 설정돼 있어야만 함
=> PK가 없으면 조인 카디널리티를 파악할 수 없음
=> FK가 없으면 조인에 실패하는 레코드가 존재할 수 있어 함부로 쿼리 변환 불가
emp의 deptno 칼럼이 null 허용 칼럼이면 결과가 다를 수 있으므로 옵티마이저는 내부적으로 is not null 조건 추가
--11g 부터 추가됨
select e.empno, e.ename, e.sal, e.hiredate
from emp e, dept d
where d.deptno(+) = e.deptno;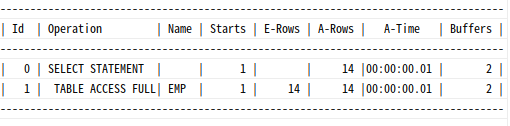
Outer 조인일 때는 not null 제약이나 is not null 조건은 물론, FK 제약이 없어도 논리적으로 조인 제거 가능
7. OR 조건을 Union으로 반환
select * from emp
where job='CLERK' or deptno=20;위 쿼리는 or 조건이므로 Full Table Scan으로 처리될 것이다.
--job과 deptno에 각각 생성된 인덱스 사용시
select * from emp
where job='CLERK'
union all
select * from emp
where deptno=20
and LNNVL(job='CLERK') OR-Expansion : 사용자가 쿼리를 직접 바꾸지 않아도 옵티마이저가 이런 작업 대신
0 SELECT STATEMENT
1 CONCATENATION
2 TABLE ACCESS BY INDEX ROWID EMP
3 INDEX RANGE SCAN EMP_JOB_IDX
4 TABLE ACCESS BY INDEX ROWID EMP
5 INDEX RANGE SCAN EMP_DEPTNO_IDX
Predicate Information(identified by operation id):
---------------------------------------------------------
3 - access("JOB"='CLERK')
4 - filter(LNNVL("JOB"='CLERK'))
5 - access("DEPTNO"=20)위쪽 브랜치는 job='CLERK' 인 집합을 읽고, 아래쪽 브랜치는 deptno=20인 집합만 읽는다.
=> emp 테이블 액세스가 두 번 일어나기 때문에, 중복 액세스되는 영역의 비중이 낮을수록 효과적
중복 액세스 되더라도 결과 집합에는 중복이 없게 하기 위해 오라클 내부적으로 LNNVL 함수를 사용
=> job<>'CLKERK' 이거나 job is null인 집합만 읽으려는 것
=> LNNVL : 조건식이 false이거나 알 수 없는 값일 때 true 리턴
힌트
use_concat:OR-Expansion유도no_expand:OR-Expansion방지
select /*+ USE_CONCAT */ * from emp
where job='CLERK' or deptno=20;
select /*+ NO_EXPAND */ * from emp
where job='CLERK' or deptno=20;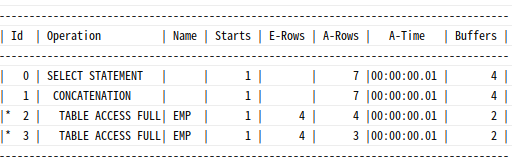
8. 기타 쿼리 변환
집합 연산을 조인으로 변환
Intersect나 Minus 같은 집합 연산을 조인 형태로 변환하는 것
select job, mgr from emp
minus
select job, mgr from emp
where deptno=10;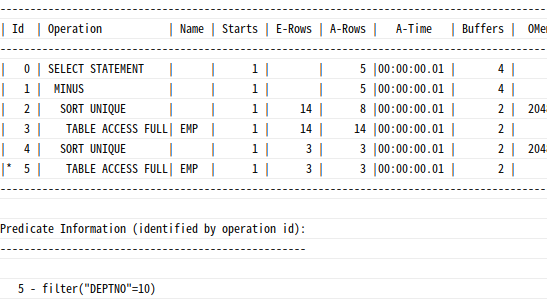
deptno=10에 속한 사원들의 job, mgr을 제외시키고 나머지만 찾는 쿼리
=> 각각 sort unique 연산 후 minus 수행
-- minus 연산을 조인 형태로 변환시
---------------------------------------
0 SELECT STATEMENT
1 HASH UNIQUE
2 HASH JOIN ANTI
3 TABLE ACCESS FULL | EMP
4 TABLE ACCESS FULL | EMP
Predicate Information(identified by operation id):
---------------------------------------------------
2 - access(SYS_OP_MAP_NONNULL("JOB")=SYS_OP_MAP_NONNULL("JOB") AND
(SYS_OP_MAP_NONNULL("MGR")=SYS_OP_MAP_NONNULL("MGR")
4 - filter("DEPTNO"=10) 해시 Anti 조인을 수행하고 나서 중복 값 제거를 위한 Hash Unique 연산을 수행
select distinct job, mgr from emp e
where not exist (
select 'x' from emp
where deptno=10
and sys_op_map_nonnull(job) = sys_op_map_nonnull(e.job)
and sys_op_map_nonnull(mgr) = sys_op_map_nonnull(e.mgr)
);sys_op_map_nonnull 함수 : null값 끼리 =비교 하면 false지만, true가 되도록 처리해야 할 때 사용
조인 칼럼에 IS NOT NULL 조건 추가
select count(e.empno), count(d.dname)
from emp e, dept d
where d.deptno = e.deptno
and sal <= 2900;조인 칼럼 deptno가 null인 데이터는 조인 액세스 불필요
select count(e.empno), count(d.dname)
from emp e, dept d
where d.deptno = e.deptno
and sal <= 2900
and e.deptno is not null -- 추가
and d.deptno is not null; -- 추가필터 조건 추가
select * from emp
where sal between :mn and :mx;쿼리 수행 시 사용자가 :mx보다 :mn 변수에 더 큰 값을 입력하면 공집합 이다.
=> 옵티마이저가 임의로 필터 조건식 추가
0 SELECT STATEMENT
1 FILTER
2 TABLE ACCESS FULL | EMP
Predicate Information
-------------------------------------
1 - filter(TO_NUMBER(:MN)<=TO_NUMBER(:MX))
2 - filter("EMP"."SAL">=TO_NUMBER(:MN) AND "EMP"."SAL"<=TO_NUMBER(:MX)) -- :mn에 5000, :mx에 100을 입력하고 수행시
0 recursive calls
0 db block gets
0 consistent gets
0 physical reads조건절 비교 순서

select * from T
where A=1
and B=1000;위 SQL문은 B칼럼에 대한 조건식을 먼저 평가하는 것이 유리
=> 대부분 B 조건을 만족하지 않기 때문
