1.프로젝트 진행 배경
지난 학기에 멀티미디어 정보처리 수업을 수강하면서 CNN을 기반으로 한 여러 이미지 처리 모델을 학습했었는데, 하계 현장 실습을 진행하면서 CNN이 자연어 처리에도 이용된다는 것을 알게되었다. (현장 실습하는 곳에서는 Transformer model을 바탕으로 한 감성 분석을 진행했다. 물론 인턴이 나는 레이블링 작업, 팀 세미나 참여, Transformer model 구조 발표 등 작은 부분을 맡아서 했지만...!) 이미지 처리 모델을 학습하면서 사용했던 CNN이 Attention Mechanism 보다는 아니지만 자연어 처리에서도 꽤 좋은 성능을 보인다는 점에서 과연 어느 정도의 감성분석이 가능할지 궁금해서 프로젝트를 진행해보게 되었다. + NLP 공부 겸 ㅎㅎ
2. 감성분석(Sentiment Analysis)
텍스트에 들어있는 의견이나 감성, 평가, 태도 등의 주관적인 정보를 컴퓨터를 통해 분석하는 과정
ex) ‘너무 좋았다. 말이 필요 없음. 계속 보고 싶다.' => 긍정(1)
‘지루하지는 않은데 완전 막장임... 돈주고 보기에는....’ => 부정(0)
3. CNN(Convolutional Neural Networks)
Convolution + Pooling
- Convolution : feature map을 만들어 특징을 뽑는 역할
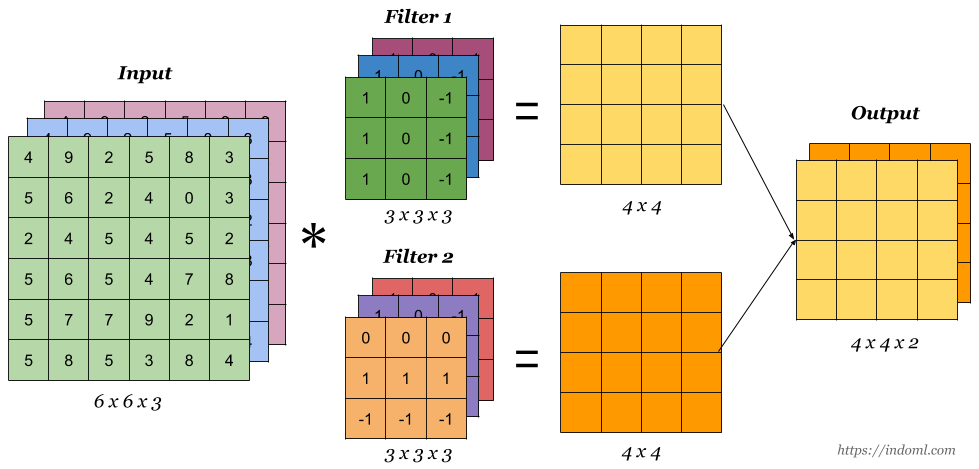
- Pooling : FC(Fully Connected) Laye를 거치기 전 적당히 크기를 줄이고, 특정 feature를 강조하는 역할 (CNN은 주로 max pooling 사용)

4. NLP(Natural Language Processing)에 사용되는 CNN
- 이미지 처리에 사용되는 2D CNN과 달리 1D CNN 사용
- 1D CNN : 커널의 너비를 문장 행렬에서의 임베딩 벡터의 차원과 동일하게 설정
ex) 커널의 사이즈 = 2
=> 높이가 2, 너비가 임베딩 벡터의 차원인 커널
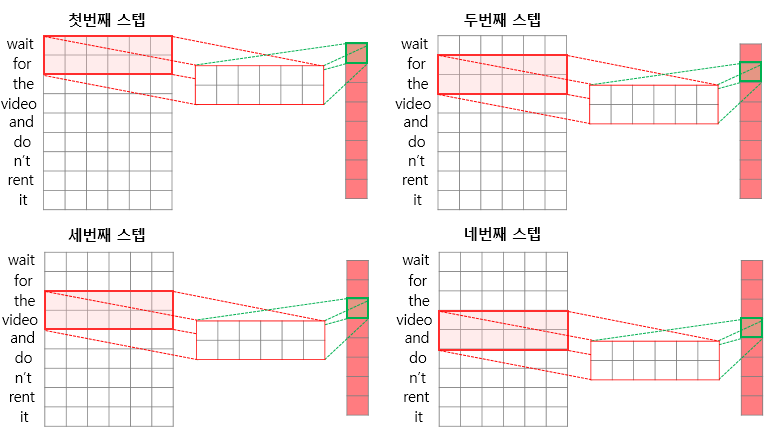
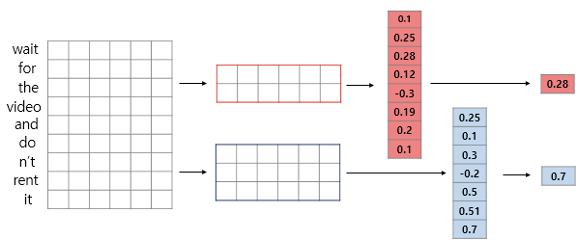
5. CNN을 이용한 NAVER 영화 리뷰 감성 분석
1) csv 파일 생성
먼저 txt 파일로 저장된 영화 review를 csv 파일로 변환해 주었다.
import pandas as pd
train_data = pd.read_csv('ratings_train.txt', sep='\t').dropna()
test_data = pd.read_csv('ratings_test.txt', sep='\t').dropna()
# column 이름 변경
train_data.rename(columns = {'document' : 'review'}, inplace = True)
test_data.rename(columns = {'document' : 'review'}, inplace = True)
# csv 파일로 저장
train_data.to_csv('train_data.csv', index=False)
test_data.to_csv('test_data.csv', index=False)2) KoNLPy 설치
한국어 정보처리를 위한 파이썬 패키지인 KoNLPY를 설치하고, 형태소 분석을 위해 Mecab도 함께 설치해주었다. 아래를 보면 성공적으로 형태소 분석이 잘 되는 것을 볼 수 있다. (코모란과 꼬꼬마는 추가로 설치해주지 않아도 사용할 수 있는 것 같다! 사용해보니 잘 사용되었다!)
from konlpy.tag import Mecab # 형태소 분석기
mecab = Mecab()
# 윤딴딴 - 조금은 울적한 하루를 보낸 뒤 (가사가 좋아서 ..🤤)
print(mecab.morphs('그 끝날에 오늘의 어지러운 기록도 나의 색이 돼줄까 \
그래 그래 나는 다시 어디쯤을 지나 또 다른 문을 열기 위해 애쓰고 있어 \
그 하루들에 오늘처럼 무너지는 날에도 괜찮아 나는 괜찮아'))
Mecab를 설치하는데 어려움을 조금 겪었는데 여기 보면 쉽게 설치할 수 있다.
3) 감성 분석
preprocessing
# 필요한 library imort
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import time
from torchtext.legacy import data
from torchtext import datasets
import random
import numpy as np
from konlpy.tag import Mecab
mecab = Mecab()# 랜덤 시드 고정
SEED = 42
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = TrueKERNEL_SIZE = [3,4,5] # 총 3개의 kernel size 사용( KERNEL_SIZE, embed_dimension)
def tokenizer(text):
token = mecab.morphs(text)
if len(token) < max(KERNEL_SIZE):
for i in range(0, max(KERNEL_SIZE)-len(token)):
token.append('<PAD>') # 커널 사이즈 보다 문장의 길이가 작은 경우 에러 방지
return token필드 정의를 통해 앞으로 어떤 전처리를 할지 정의해주었다. 이후 TabularDataset을 이용하여 앞서 필드에서 정의했던 토큰화 방법으로 토큰화를 수행하고, 각 데이터 셋을 분리해주었다!
# 필드 정의
REVIEW = data.Field(tokenize = tokenizer, batch_first = True) # 배치 우선 여부(True일 경우 텐서 크기의 0번째 인덱스는 배치사이즈로 설정)
LABEL = data.LabelField(dtype = torch.float)
# {csv컬럼명 : (데이터 컬럼명, Field이름)} / id는 사용 x
fields = {'review': ('review', REVIEW), 'label': ('label', LABEL)}
# 데이터 셋 만들기 (정의한 필드에 기반하여 데이터를 불러옴)
train_data, test_data = data.TabularDataset.splits(path = 'data', # 데이터 파일 경로
train = 'train_data.csv',
test = 'test_data.csv',
format = 'csv', # 데이터 파일 형식
fields = fields)
train_data, valid_data = train_data.split(random_state = random.seed(SEED))
# 결과 확인
print('훈련 샘플의 개수 : {}'.format(len(train_data)))
print('테스트 샘플의 개수 : {}'.format(len(test_data)))
print(vars(train_data[3]))이제 단어 집합을 만들어보자. 단어 집합 생성 시에는 fasttext.simple.300d을 불러와서 사용하였는데, 해당 벡터는 이미 다른 데이터셋에서 학습된 사전 훈련된 것으로, weight 값을 가져와서 이를 초기값으로 사용하고, 추가로 학습을 진행하여 fine-tuning 하는 과정을 거치면 모델 성능을 개선하는데 도움이 된다고 한다!!
# 단어 집합 만들기
MAX_VOCAB_SIZE = 25000 # 단어 집합의 최대 크기
REVIEW.build_vocab(train_data,
max_size = MAX_VOCAB_SIZE,
vectors = 'fasttext.simple.300d', # -> 한글 지원
unk_init = torch.Tensor.normal_)
LABEL.build_vocab({'0': 0, '1': 1}) # LABEL.build_vocab(train_data) 시 {'1': 0, '0': 1} mapping 됨.
print('단어 집합의 크기 : {}'.format(len(REVIEW.vocab)))
print(REVIEW.vocab.stoi) # 생성된 단어 집합 내 단어 확인BucketIterator에서 sort_key를 통해 비슷한 길이의 데이터를 묶어서 처리하기 때문에 패딩이 최소화 되고, 이에 따른 연산 효율이 향상된다! (학습 속도가 빨라지고, 메모리 사용량은 줄어든다!!)
BATCH_SIZE = 128
# BucketIterator : 모든 텍스트 작업을 일괄로 처리하고 단어를 인덱스 숫자로 변환 하는것을 도움
train_loader, valid_loader, test_loader = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
sort_key = lambda x: len(x.review), # 길이가 유사한 것을 일괄 처리하고, 패딩을 최소화하기위해 길이로 정렬
sort_within_batch = True) # 내림차순 정렬model
크게 embedding, convolution, pooling, fc layer를 거친다!
# Model
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_kernels, kernel_sizes, output_dim, dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(num_embeddings = vocab_size, # 임베딩을 할 단어들의 개수 (단어 집합의 크기)
embedding_dim = embedding_dim, # 임베딩 할 벡터의 차원 (하이퍼파라미터)
padding_idx = pad_idx) # 패딩을 위한 토큰의 인덱스
self.convs = nn.ModuleList([nn.Conv2d(in_channels = 1, # input channel수 ( ex RGB 이미지 = 3 )
out_channels = n_kernels, # convolution에 의해 생성될 channel의 수
kernel_size = (ksize, embedding_dim)) # ksize만 변화. embedding_dim은 고정
for ksize in kernel_sizes])
self.fc = nn.Linear(len(kernel_sizes)*n_kernels, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, review):
embedded = self.embedding(review)
embedded = embedded.unsqueeze(1) # 특정 위치에 1인 차원을 추가 <-> squeeze : 1인 차원을 제거
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
cat = self.dropout(torch.cat(pooled, dim = 1))
res = self.fc(cat)
return self.fc(cat)# 모델 선언
INPUT_DIM = len(REVIEW.vocab)
EMBEDDING_DIM = 300
N_KERNELS = 100
KERNEL_SIZES = [3,4,5]
OUTPUT_DIM = 1
DROPOUT = 0.5
PAD_IDX = REVIEW.vocab.stoi[REVIEW.pad_token]
model = CNN(INPUT_DIM, EMBEDDING_DIM, N_KERNELS, KERNEL_SIZES, OUTPUT_DIM, DROPOUT, PAD_IDX)
print('모델 파라미터 수 :', sum(param.numel() for param in model.parameters() if param.requires_grad))# 사전 훈련된 단어 벡터 불러오기
pretrained_weight = REVIEW.vocab.vectors
print(pretrained_weight.shape, model.embedding.weight.data.shape)
print(model.embedding.weight.data.copy_(pretrained_weight))UNK_IDX = REVIEW.vocab.stoi[REVIEW.unk_token]
# unk, pad token -> 0 처리
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)train
BCEWithLogitsLoss는 BCELoss에 sigmoid 함수가 합쳐져 있는 손실 함수인데, BCELoss 보다 모델의 안정성과 수렴 속도 면에서 좋은 성능을 보이는 경우가 많다고 한다!
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss() # BCELoss + sigmoiddef binary_accuracy(preds, y):
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds==y).float()
acc = correct.sum() / len(correct)
return accdef train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.review).squeeze(1) # output_dim = 1
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
predictions = model(batch.review).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secsN_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_loader, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_loader, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'MovieSentimentAnalysis.pt') # 모델 저장
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')test
model.load_state_dict(torch.load('MovieSentimentAnalysis.pt'))
test_loss, test_acc = evaluate(model, test_loader, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')def sentiment_predict(review, tokenizer, model):
tokens = tokenizer(review) # 토큰화
idxes=[]
# 각 단어를 정수로 변환
for token in tokens:
try:
idxes.append(REVIEW.vocab[token])
except KeyError: # 단어 집합에 없는 단어일 경우 <unk>로 대체
idxes.append(vocab['<unk>'])
idxes = torch.LongTensor(idxes)
idxes = idxes.unsqueeze(0)
predictions = torch.sigmoid(model(idxes).squeeze(1))
if(predictions > 0.5):
print("{:.2f}% 확률로 긍정 리뷰입니다.\n".format(predictions.item() * 100))
else:
print("{:.2f}% 확률로 부정 리뷰입니다.".format((1-predictions.item())*100))sentiment_predict('정말 대작입니다... 꼭 보세요', tokenizer, model)