
Generative Adversarial Networks, Diffusion Models, VAE 등 Image Generation Model들은 실제 사진과 같은 퀄리티의 이미지들을 만들어 낸다. 이러한 고퀄리티 image generation 모델들에 text embedding을 결합시켜 stability, runaway 등 기업들에선 사용자들의 text input으로 해당 내용의 이미지를 생성해 주는 서비스를 제공한다. 그러나 이런 생성모델들은 2D image밖에 생성해 내지 못한다. 그렇기 때문에 해당 scene을 다른 viewpoint에서 바라본 image를 얻는 것은 불가능하다. (사실 어느정도 가능하긴 하다. 다만 문제점이 많다)
예를 들어 강아지 사진을 만들고 싶은 사용자가 text prompt로 "강아지"를 주고 여러개의 이미지를 받아와 그중 가장 마음에 드는것을 골랐다. 이미지 안에 있는 강아지는 너무 마음에 드는데 강아지가 오른쪽을 바라보고 있는 사진이다. 그래서 해당 이미지의 내용물은 그대로 유지하며 강아지가 정면을 바라보는 사진을 얻고 싶은데 가능할까?
이러한 문제를 해결하고자 하는 task가 바로 3D image synthesis이다.
3D aware image synthesis
기존 generation model들은 높은 퀄리티와 큰 다양성을 갖는 이미지들을 생성해낸다.
⚠️ 근데 만약 생성된 image를 다른 viewpoint에서 보고 싶다면 이는 불가능하거나 좋은 퀄리티를 내지 못한다.
→ 이건 viewpoint를 explicit하게 modeling하지 않아서 생기는 문제점이다.
(만약 기존 2D GAN에서 생성된 같은 이미지에 대한 다른 viewpoint의 image를 보고 싶다면 feature space를 잘 disentangle 시켜서 camera viewpoint에 해당되는 축으로 feature를 바꿔줘야 한다. 즉 implicit하게 model안에서 생성된 feature space를 manipulate해야함)
이러한 문제를 해결하는 것이 3D aware image synthesis이다!
결국 generative model들을 3D aware하게 만드는 것이다.
3D aware하게 만드는 가장 쉬운 방법은 3D supervision을 주는 것인데 (image-viewpoint paired dataset) 이러한 데이터는 얻기 상당히 힘들다.
그렇기 때문에 GRAF, EG3D등 3D-aware image synthesis task를 다루는 논문들은 모두
3D aware image synthesis from unposed 2D images 라는 task를 풀려고 한다.
3D-aware GANs의 전반적인 pipeline
2D image synthesis는 바로 2D image를 generate하면 되겠지만 3D image synthesis는 viewpoint를 자유롭게 바꿔야 하기 때문에 추가적으로 Rendering하는 부분이 포함된다.

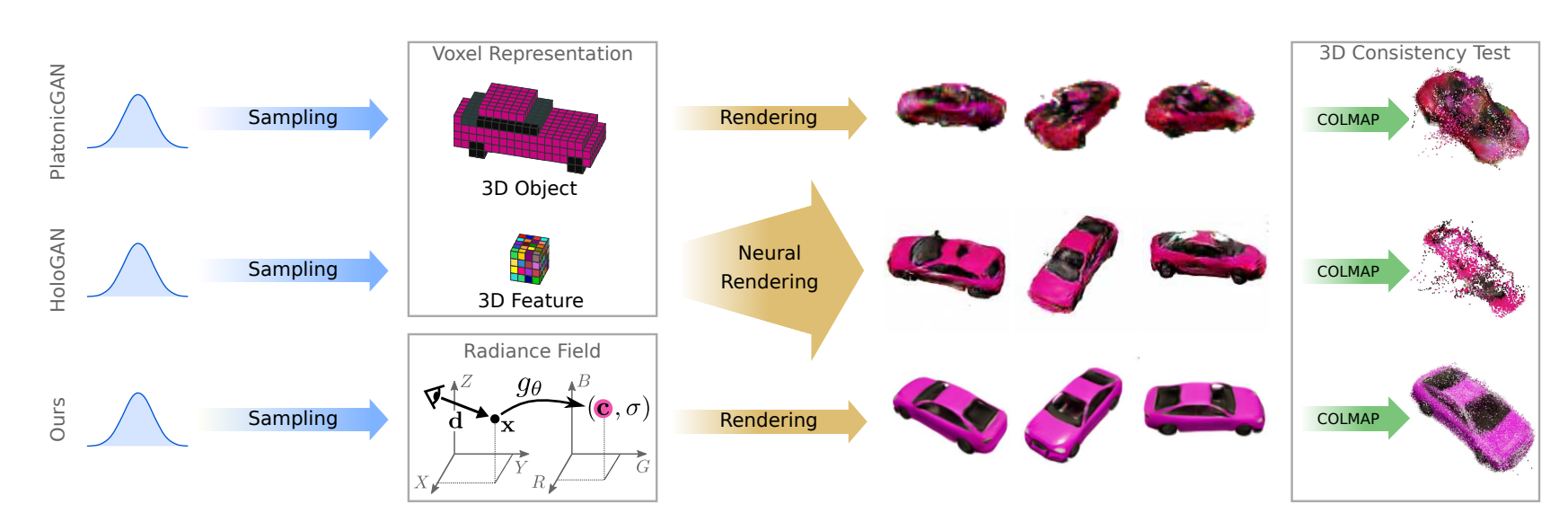
아래 그림과 같이 무언가를 생성하고 이를 rendering해야하는데, 이때 어떤 무언가를 생성할지 다양한 method들이 존재한다.
이때 PlatonicGAN은 voxel에 3D object를 생성하고 이를 바로 랜더링한다.
반면에 HoloGAN은 voxel에 3D feature을 생성하고 이를 Neural Rendering한다.
→ Neural rendering은 rendering을 하기 전에 NN을 통과하는 방법론이다.
마지막으로 GARF는 NeRF setting을 활용하여 color와 density를 생성한다
3D aware image synthesis를 접근하는 가장 naive한 방법은 사실 3D scene 자체를 다음과 같이 explicit하게 만들어 내는 것이다. (mesh, voxel, point cloud etc)

3D scene을 만들어 놓기만 하면 camera viewpoint를 바꿔가면서 3D->2D rendering만 해주면 완벽한 fidelity의 3D-aware한 이미지들을 생성해 낼 수 있을 것이기 때문이다.
그러나 3D scene자체를 explicit하게 생성해내는 것은 상당히 어려운 task이다(3D와 관련된 operation들이 다수 필요함 ex) 3D convolution)). 때문에 3D-aware한 2D 이미지 생성을 위해 3D-scene을 생성해내는 것은 뭔가 배보다 배꼽이 더 큰 상황이 되어버린다.
Explicit하게 표현하는것이 어렵다면 implicit하게 표현해보는 것은 어떨까?!
바로 Neural Radiance Field를 이용하는 것이다! NeRF setting은 실제 3D scene을 저장하는 것이 아니라 MLP의 parameter들 안에 3D scene에대한 정보를 담기 때문에 3D operation들이 필요없다. 다만 Rendering할때 각 ray당 3D point들을 많이 sample하여 MLP에 쿼리해야하기 때문에 소모적이긴 하지만,,,그래도 생성하고자 하는 Scene 분포를(train data distribution) MLP에 저장하고 이를 기존 volume rendering 기법을 통해 2D image로 만들어내는 것은 매우 합당해 보인다.
이러한 방법론을 가장 먼저 제시한 논문이 바로 GRAF이다.
추후 EG3D, Giraffe등 모두 GRAF setting을 사용하기 때문에 GRAF가 매우 중요하다!
👻 Comments
사실 NeRF setting을 이용한다고 method가 하나로 한정되는 것은 아니다. Vanilia nerf를 사용할 수도 있고 feature grid를 가지고 있는 nerf혹은 RGB, density가 아닌 feature와 density를 output하는 setting등 많은 방법론들이 존재한다. 이러한 NeRF연구들이 3D aware synthesis setting에서는 어떻게 쓰일지 앞으로의 연구들이 기대된다.
