
📌 NetCDF ?
NetCDF(Network Common Data Form) 는 배열 기반 (과학적 측정) 데이터를
저장하는 파일 포맷(이하 nc 파일), 그리고 이런 파일을
생성, 액세스 및 공유할 수 있도록 지원하는 소프트웨어 라이브러리들을
모두 포괄하는 개념입니다.
이번 글에서는 이 NetCDF 를 이해하기 위해서 다음과 같은 순서로 글을 작성했습니다.
- NetCDF 파일 포맷의 특징
- NetCDF 파일의 구성요소
- NetCDF 라이브러리 활용
1. NetCDF 파일 포맷의 특징
nc 파일 은 다양한 특징이 있는데 NetCDF 소개 (공식 페이지)에서는 다음과 같이 소개합니다.
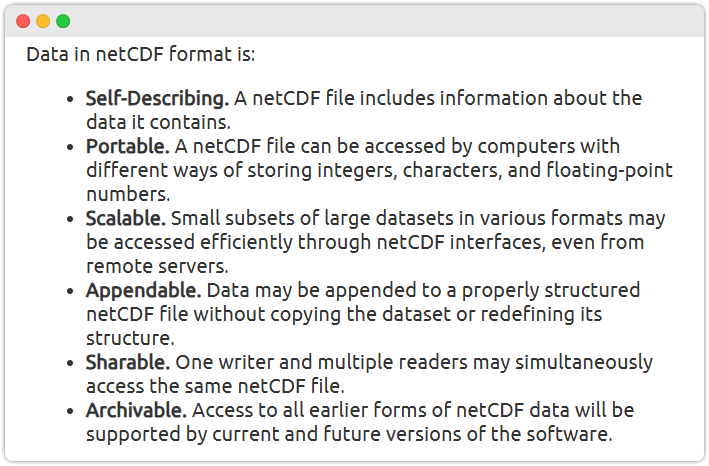
(제 개인적 주관으로는) 이중에서 Self-Describing 이 가장 중요합니다.
nc 파일은
속성(attribute)이라는 정보를 담는데,
이 정보는 nc 파일이 담고 있는 배열 데이터 또는 nc 파일 자체의메타정보를 의미합니다.
조금 모호하죠? 이러한 Attribute 정보를 조회하는 실제 예시를 하나 보겠습니다.
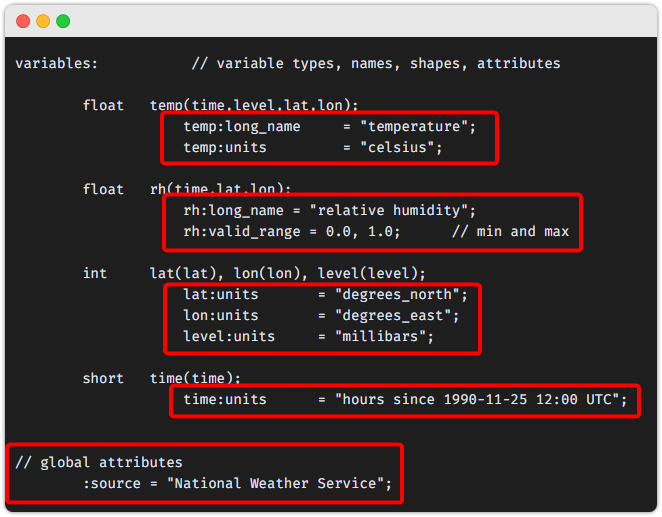
아래는 ncdump 라는 프로그램으로 nc 파일 의 정보를 조회하는 예시입니다.
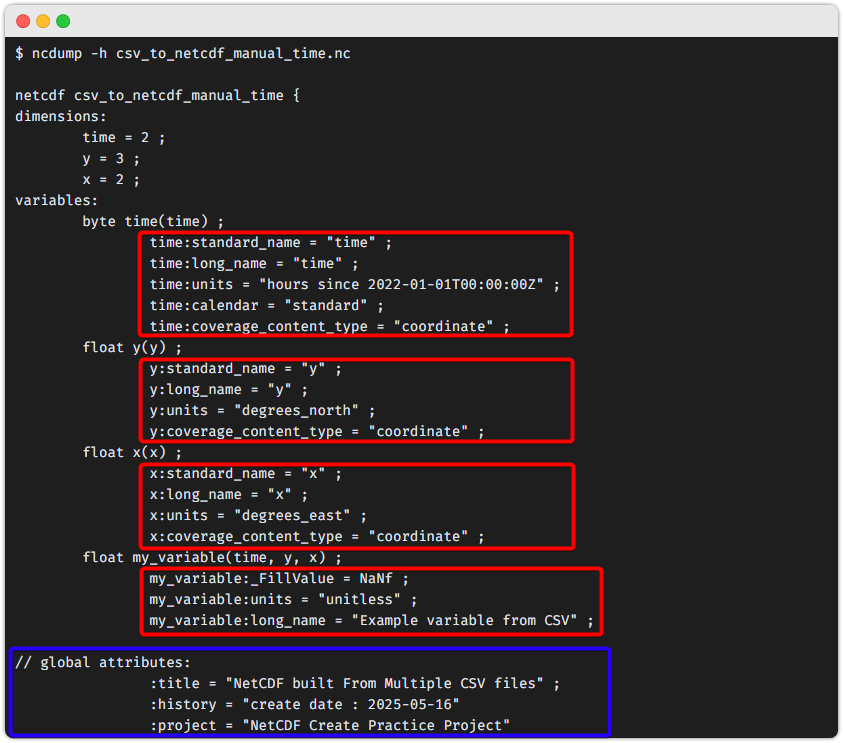
- 여기에서 박스친 부분들이 바로 Attribute 입니다.
- 여기서 속성정보로 생각해야 될 것들은 크게 2가지입니다.
빨간색 박스친 부분은 각 배열 데이터(=variable)들에 대한 메타정보파란색 박스하단의 정보들은 nc 파일 자체에 대한 메타정보
나중에 netcdf 파일을 직접 생성하는 코드를 작성해볼 건데,
이러한 attribute 를 지정하는 코드가 거의 절반을 차지할 정도로
nc 파일의 내용 중 많은 부분을 차지합니다!
좀 장황할 수도 있지만 이런 attribute 덕분에 nc 파일을
Self-Describing (=자기 서술적) 하다고 합니다.
참고: variable?
nc 파일 포맷은 한 개 이상의 배열 데이터들을 갖을 수 있습니다.
그리고 nc 파일은 이 데이터 하나하나를 변수(variable) 라고 부릅니다.
더 자세한 건 다음 목차를 계속 읽다보면 알게 됩니다!
2. NetCDF 파일의 구성요소
이 목차의 내용은 난해해서 당장 이해가 안될 수 있습니다.
하지만3. NetCDF 라이브러리 활용목차를 따라하다보면 자연스럽게 이해하게 됩니다.
너무 어려우면 과감하게 Skip 하세요 😊
NetCDF 파일에 ncdump 와 같은 프로그램을 통해서
내용을 조회하면 대게 아래와 같은 형태로 출력됩니다.
netcdf example_1 { // 파일명
dimensions: // dimension names and sizes are declared first
lat = 5,
lon = 10,
level = 4,
time = unlimited;
variables: // variable types, names, shapes, attributes
float temp(time,level,lat,lon);
temp:long_name = "temperature";
temp:units = "celsius";
float rh(time,lat,lon);
rh:long_name = "relative humidity";
rh:valid_range = 0.0, 1.0; // min and max
int lat(lat), lon(lon), level(level);
lat:units = "degrees_north";
lon:units = "degrees_east";
level:units = "millibars";
short time(time);
time:units = "hours since 1990-11-25 12:00 UTC";
// global attributes
:source = "National Weather Service";
data: // optional data assignments
level = 1000, 850, 700, 500;
lat = 20, 30, 40, 50, 60;
lon = -160,-140,-118,-96,-84,-52,-45,-35,-25,-15;
time = 12;
rh =.5,.2,.4,.2,.3,.2,.4,.5,.6,.7,
.1,.3,.1,.1,.1,.1,.5,.7,.8,.8,
.1,.2,.2,.2,.2,.5,.7,.8,.9,.9,
.1,.2,.3,.3,.3,.3,.7,.8,.9,.9,
0,.1,.2,.4,.4,.4,.4,.7,.9,.9;
}📏 차원 (Dimensions)
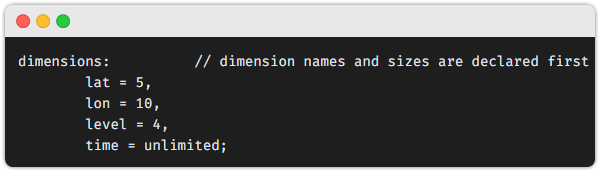
- 데이터(=배열)의 형태를 정의하는 척도를 제공합니다.
- netcdf 의 배열 데이터는 1차원뿐만 아니라 n 차원 형태도 넣을 수 있습니다.
이때 각 차원에 명칭과 길이(size)를 지정한 것입니다.
- Dimensions 들은 추후 Variable(=배열 데이터 변수)에서 사용됩니다.
- ex:
float temp(time,level,lat,lon)- temp 라는 변수는 4차원 배열 형태를 갖고 있고
- 4차원 배열의 각 차원은
time,level,lat,lon를 의미합니다.
- ex:
- 기본적으로는 각 차원은 고정된 길이어야 하지만 예외적으로 무제한(UNLIMITED)일
수도 있습니다. 하지만 이 무제한 차원은NetCDF파일 상에서 오로지 하나만 설정할 수 있습니다. 또한 각 Variable 에 첫번째 차원으로만 지정해야합니다.
📊 변수 (Variables)
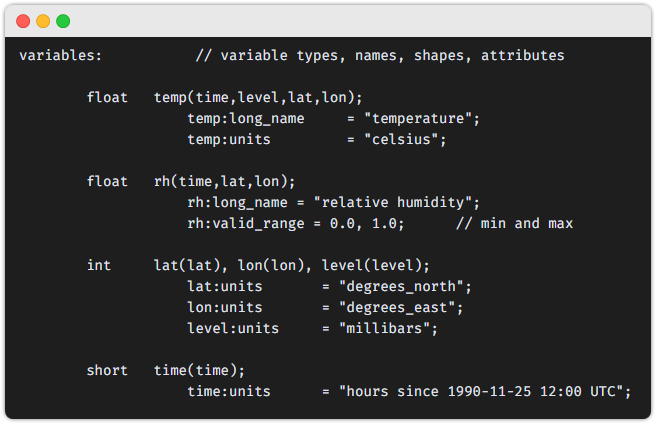
- 다차원 배열 데이터의 명칭, 데이터 타입, 차원정보 및 속성 정보를 정의합니다.
- 데이터 타입은 각 변수 명 앞에 있습니다.
- 차원정보 예시 :
temp(time, level, lat, lon) - 속성정보 예시 :
ex: temp:long_name = "temperature"
🏷️ 속성 (Attributes)
-
부가 정보를 제공하는 요소입니다.
-
크게 2가지 부가 정보를 제공합니다.
Variable Attribute는 각 변수에 대한 부가 설명이며
Global Attribute는 nc 파일 자체에 대한 부가 설명입니다.
- (중요) 이 속성명에는 규칙(
Conventions)이 존재합니다.
- (중요) 속성명 중
standard_name의 값 같은 경우에는 표준이 따로 있습니다.
규칙과 표준들을 꼭 지켜야만 NetCDF 파일을 생성 및 활용할 수 있는 건 아닙니다!
하지만 이러한 것들을 지키면 NetCDF 시각화 라이브러리들의 지원을 받을 수 있습니다!
이런 표준과 규칙에 대해서는 이 유튜브 영상을 한번 보는 것도 추천드립니다.
📍 좌표 변수 (Coordinate Variables)
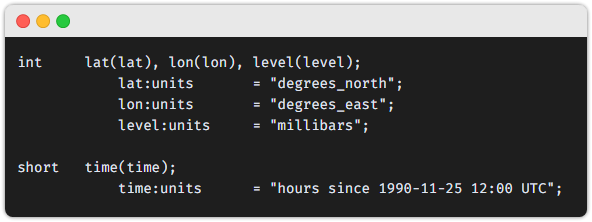
변수이긴 하지만 Dimension 에 대한 Attribute 설정을 위한 특별한 변수입니다.
이런 변수들은 각 차원(Dimension) 과 동일한 이름을 갖는 특징이 있습니다.
예: float lat(lat);
또한 중요한 특징으로 좌표변수가 갖는 배열값은 반드시 1차원이어야 하며
오름차순 또는 내림차순 둘 중 명확하게 방향을 가져야 합니다.
참고: 각 차원에 대한 적절한 standard_name 속성을 제공하면 NetCDF 시각화
라이브러리의 지원을 받을 수 있습니다.
3. NetCDF 라이브러리 활용
장황하고 어려운 설명은 이 정도만 하겠습니다.
이제는 NetCDF 라이브러리를 활용한 실습을 해보겠습니다.
실습을 위해서 python 을 사용토록 하겠습니다.
이번 목차에서는 python 과 NetCDF 라이브러리를 사용합니다.
개발환경이 없다면 Docker 를 통해서 환경을 구성할 수 있는데,
이와 관련해서는 제가 이전에 작성한 글을 참고하시길 바랍니다.
3-1. 라이브러리 다운로드
- python 라이브러리 다운로드
pip install netCDF4 # netCDF 를 다루기 위한 라이브러리
pip install numpy # 복잡한 배열을 다루기 위한 라이브러리 - cli 프로그램 다운로드
apt install netcdf-bin # cli 환경에서 ncdump 사용하기 위함3-2. NetCDF 파일 생성
🎯 Dimension 생성
먼저 배열 데이터의 형태를 위한 기준이 되는 Dimension(차원)을 생성해보겠습니다.
import numpy as np
from netCDF4 import Dataset
# time Dimension 배열 생성, [0, 1]
time_coords = np.arange(0, 2)
# x/y 차원을 경도/위도로 사용할 예정이라서 값을 아래처럼 줬습니다.
y_coords = np.array([35.681, 36.681]) # y dimension 배열 생성
x_coords = np.array([126.957,127.957,128.957]) # x dimension 배열 생성
# NetCDF 파일 생성
with Dataset("output.nc", "w", format="NETCDF4") as nc:
# Dimension 정보 추가, 각 차원의 이름과 길이를 지정합니다.
nc.createDimension("time", len(time_coords)) # unlimit 을 원하면 2번째 인자값 지우기
nc.createDimension("y", len(y_coords))
nc.createDimension("x", len(x_coords))
이렇게 하고 cli 환경에서 ncdump 로 생성된 nc 파일을 조회하면...?
# 명령어 입력 방식: ncdump -h output.nc
## 출력:
netcdf output {
dimensions:
time = 2 ;
y = 2 ;
x = 3 ;
}NetCDF 파일의 구성요소 중 Dimension 이 생성된 것을 확인 할 수 있습니다!
각 dimension 의 명칭(time,x,y)과 길이가 정확히 적용된 것을 확인했습니다.
혹시 time dimension 이 날짜 형식(ex: 2025-04-01) 이 아니라 숫자형태인
이유가 궁금하신 분들은 보충 목차를 확인하시기 바랍니다.
🎯 Variable 생성
Coordinate Variable(=Dimension 전용 Variable)과
그외 일반적인 데이터를 담는 Variable 을 생성해보겠습니다.
import numpy as np
from netCDF4 import Dataset
time_coords = np.arange(0, 2) # time Dimension 배열 생성, [0, 1]
y_coords = np.array([35.681, 36.681]) # y dimension 배열 생성
x_coords = np.array([126.957,127.957,128.957]) # x dimension 배열 생성
with Dataset("output.nc", "w", format="NETCDF4") as nc:
# Dimension 생성
nc.createDimension("time", len(time_coords)) # unlimit 을 원하면 2번째 인자값을 주지마세요!
nc.createDimension("y", len(y_coords))
nc.createDimension("x", len(x_coords))
######## Coordinate Variable 생성 및 설정 ########
y_var = nc.createVariable("y", np.float32, ("y",)) # np.float32 대신 "float32" 문자열도 가능
x_var = nc.createVariable("x", np.float32, ("x",))
t_var = nc.createVariable("time", np.uint8, ("time",))
# Coordinate Variable 의 배열 값 세팅
t_var[:] = time_coords
y_var[:] = y_coords
x_var[:] = x_coords
# Coordinate Variable Attribute 세팅
# 참고로 standard name 은 아래 링크를 최대한 참고해서 작성해봤습니다.
# https://cfconventions.org/Data/cf-standard-names/current/build/cf-standard-name-table.html
t_var.setncattr("standard_name", "time")
t_var.setncattr("long_name", "time")
t_var.setncattr("unit", "days since 2025-05-01") # time dimension 은 unit 의 형태가 중요!
# 위도,경도 관련해서는 아래 링크를 참조
# https://cfconventions.org/Data/cf-conventions/cf-conventions-1.12/cf-conventions.html#coordinate-types
x_var.setncattr("standard_name", "longitude")
x_var.setncattr("long_name", "longitude")
x_var.setncattr("unit", "degree_east")
y_var.setncattr("standard_name", "latitude")
y_var.setncattr("long_name", "latitude")
y_var.setncattr("unit", "degree_north")
######## 데이터 Variable 생성 및 설정 ########
# 샘플 데이터 생성 각 time,y,x dimension 을 모두 사용함으로,
# 값의 갯수를 2 * 3 * 2, 즉 12 개로 맞췄습니다.
sample_data = np.array([1,2,3,4,5,6,7,8,9,10,11,12])\
.reshape((len(time_coords), len(y_coords), len(x_coords)))
# 랜덤 값을 세팅하고 싶다면?
# sample_data =\
# np.random.uniform(0, 10, (len(time_coords), len(y_coords), len(x_coords)))
# Variable 생성
sample_var =\
nc.createVariable(
"sample_data", # 변수명
np.float32, # 변수 배열의 요소 타입
("time", "y", "x",), # 배열의 차원
fill_value=np.nan # 배열 비어있는 값 default 값 지정
)
# variable 에 배열 데이터 넣기
sample_var[:, :, :] = sample_data
# Attribute 설정
sample_var.setncattr("standard_name", "sample data")
sample_var.setncattr("long_name", "just sample data")
sample_var.setncattr("unit", "unitless")- 코드를 한줄 한줄 뜯어보면 생각보다 굉장히 쉽습니다!
- 다만 attribute 지정 시
CF Convention를 최대한 지키려고 노력해야 합니다.
x,y,timevariable 이 이를 최대한 지킨 예시입니다. - 물론 sample_var 처럼 마구잡이로 attribute 를 설정해도 netcdf 파일 생성에는 문제가 없습니다.
이 상태에서 ncdump 로 nc 파일의 내용을 확인해봅시다.
# 명령어 입력 방식: ncdump output.nc
netcdf output {
dimensions:
time = 2 ;
y = 2 ;
x = 3 ;
variables:
float y(y) ;
y:standard_name = "latitude" ;
y:long_name = "latitude" ;
y:unit = "degree_north" ;
float x(x) ;
x:standard_name = "longitude" ;
x:long_name = "longitude" ;
x:unit = "degree_east" ;
ubyte time(time) ;
time:standard_name = "time" ;
time:long_name = "time" ;
time:unit = "days since 2025-05-01" ;
float sample_data(time, y, x) ;
sample_data:_FillValue = NaNf ;
sample_data:standard_name = "sample data" ;
sample_data:long_name = "just sample data" ;
sample_data:unit = "unitless" ;
data:
y = 35.681, 36.681 ;
x = 126.957, 127.957, 128.957 ;
time = 0, 1 ;
sample_data =
1, 2, 3,
4, 5, 6,
7, 8, 9,
10, 11, 12 ;
}정확히 제가 원하는 대로 들어갔네요 👍
🔥 주의사항. 배열요소 타입과 fill_value
nc.createVariable 메소드의 2번째 인자로 배열 요소들의 타입을 지정하게 됩니다.
여기에 추가로 fill_value=np.nan 처럼 인자를 추가로 줄 수 있습니다.
v = nc.createVariable(
"my_variable",
np.float32, # 2번째 인자는 타입정보!
("time", "y", "x"),
fill_value=np.nan # FillValue(=default value) 속성 지정!
)fill_value 인자를 통해서 Variable Attribute 중 하나인
_FillValue 를 세팅하게 됩니다.
_FillValue 는 배열에서 중간에 값이 없을 때,
어떤 Default Value 를 사용할지를 결정하는 값입니다.
이런 이유로 _FillValue 는 타입정보와 호환되는 값을 넣어줘야 합니다.
특히 타입정보가 float 형태인 경우에만 fill_value=np.nan 를 사용할 수 있습니다
int 형 타입에 np.nan 을 줄 수 없습니다.
int 형 배열에 np.nan 기본값을 주면 아래처럼 에러가 납니다!
nc.createVariable(
"sample_data",
np.int32, # 배열의 요소 타입 = int
("time", "y", "x",),
fill_value=np.nan # 이 상태에서 np.nan 설정하면...
)
// 에러 발생!
// ValueError: cannot convert float NaN to integer 🎯 Global Attribute 적용
마지막으로 NetCDF 파일 자체에 부가 설명인 Global Attribute 를 지정해줍시다.
with Dataset("output.nc", "w", format="NETCDF4") as nc:
# 변수 생성 및 설정 내용은 모두 생략하겠습니다!
######## Global Attribute 설정 ########
nc.setncattr("project", "sample project")
nc.setncattr("history", "create in 2025-05-18")
nc.setncattr("Conventions", "CF-1.12")간단하죠?
이 상태에로 nc 파일을 생성하고 다시 ncdump 로 내용을 확인해보겠습니다.
# 명령어 입력 방식: ncdump -h output.nc
netcdf output {
dimensions:
time = 2 ;
y = 2 ;
x = 3 ;
variables:
float y(y) ;
y:standard_name = "latitude" ;
y:long_name = "latitude" ;
y:unit = "degree_north" ;
float x(x) ;
x:standard_name = "longitude" ;
x:long_name = "longitude" ;
x:unit = "degree_east" ;
ubyte time(time) ;
time:standard_name = "time" ;
time:long_name = "time" ;
time:unit = "days since 2025-05-01" ;
float sample_data(time, y, x) ;
sample_data:_FillValue = NaNf ;
sample_data:standard_name = "sample data" ;
sample_data:long_name = "just sample data" ;
sample_data:unit = "unitless" ;
// global attributes:
:project = "sample project" ;
:history = "create in 2025-05-18" ;
:Conventions = "CF-1.12" ;
}- 맨끝에 보면
//global attributes:라는 게 추가된 것을 확인할 수 있습니다!
4. 다음 목표
이제는 NetCDF 파일이 대충 뭔지 어느정도 감을 잡았고,
간단한 파일 생성/조회법도 알아봤습니다.
다만 이번 글에서는 nc 파일의 배열 데이터를 손으로 일일이 작성했는데,
실제로는 csv 또는 geoTiff 파일의 데이터를 활용해서 nc 파일을 생성합니다.
CSV, GeoTiff 모두 배열 형태의 데이터를 담을 수 있는 포맷이기 때문이죠.
다음 글에서는 CSV/GeoTiff 로 NetCDF 파일을 생성하는 방법을 알아보겠습니다.
다음 글 링크: GeoTiff / CSV 데이터로 NetCDF 만들기 (with python)
보충: time dimension 의 숫자형 배열
왜 time dimension 의 값은 왜 숫자 배열일까요?
이러는 이유는 이 링크에서 확인할 수 있습니다.
이유는 저기서 확인하면 되고, 그렇다면 저런 숫자형태로 어떻게
시간을 표현할 수 있을까요?
방법은 다음과 같습니다.
- time dimension 은 숫자형 배열을 주고,
time dimension과 매칭된coordinate variable의unit 속성값으로
days since 2025-04-01처럼 세팅하면 끝입니다.
예를 들어서 아래처럼 세팅했다고 쳐봅시다.
- time dimension :
[0, 1] - time variable -> attribute unit :
days since 2025-04-01
이러면 각 배열의 인덱스에 있는 값들은 "일자"에 해당합니다.
즉 배열의 각 값들이 가르키는 시간의 의미는 다음과 같습니다.
0 : 2025-04-01
1 : 2025-04-02참고 링크
