
우선 아무거나 눌러서 test.csv파일을 살펴보겠습니다. 대강 이런 모양이군요.
대강 이런 모양이군요.
train.csv로 모델을 만들고 test.csv 파일로 모델의 정확도를 판단하는거겠죠?
train.csv 파일에는 Survived가 0과 1로 나타나있습니다.
어떤 사람들이 생존할 가능성이 더 높았는지에 대한 답변을 할 수 있는 예측 모델을 구축하는 것이 목적입니다.
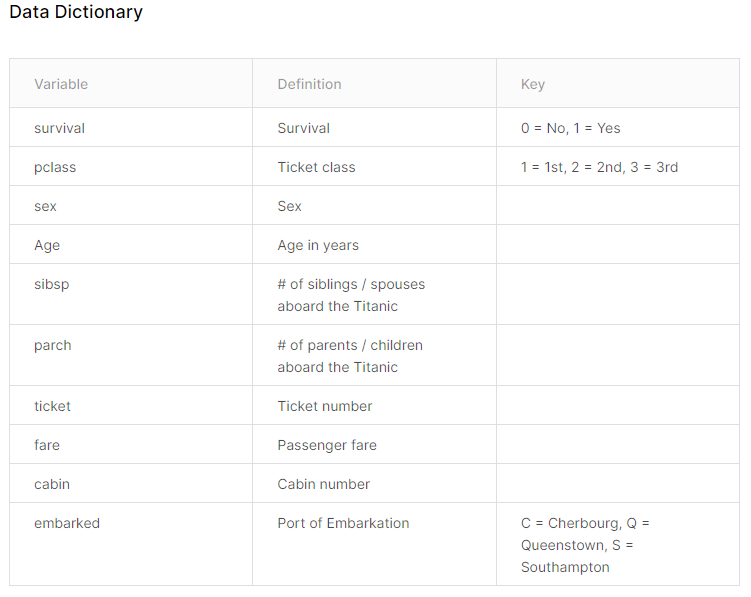
 변수에 대해 확인해줍니다. 영어는 언제 봐도 싫네요..
변수에 대해 확인해줍니다. 영어는 언제 봐도 싫네요..
stepbrother, stepsister는 의붓형제자매를 뜻하는 걸까요? 복잡하네요
parch = 0인 경우는 유모와 여행하는 아이군요... 벌써부터 짜증이 몰려옵니다.
하지만 첫 번째 프로젝트부터 포기하면 멋없으니까 일단 해봅시다.
저는 간죽간살이기 때문이죠.
하지만 노간지로 다른 사람의 모델을 한 번 보기로 합니다.
Code로 들어가면 다른 사람들의 코드를 볼 수 있습니다. Most Votes 순으로 정렬하여 가장 상위를 보도록 합시다. 기대가 됩니다... 근데 스크롤이 꽤 길군요...
기대가 됩니다... 근데 스크롤이 꽤 길군요...
대충 보아하니, 어쩌고저쩌고 pandas numpy matplotlib(시각화) import하고 csv파일을 읽은 뒤,
dataframe에 csv파일을 불러오고...
categorical한 value와 numerical한 value를 구분하고...
(바보감자는 눈앞이 캄캄해지려합니다. 한글이 세계 공용문자가 되었으면..)
뭐 일단 여기까지는 할 수 있으니까 저도 해보겠습니다.
import pandas as pd
import numpy as np
train_df = pd.read_csv('...\\train.csv')
test_df = pd.read_csv('...\\test.csv')
print(train_df.columns.values)대충 dataframe으로 가져왔고, value를 찍어보았습니다.
'PassengerId' 'Survived' 'Pclass' 'Name' 'Sex' 'Age' 'SibSp' 'Parch'
'Ticket' 'Fare' 'Cabin' 'Embarked'
이를 나누자면
Survived(0, 1), Sex(male, female), Embarked(C, Q, S), Pclass(1, 2, 3) /
(Continuous) Age(int), Fare(float), (Discrete) SibSp(int), Parch(int)
그리고 PassengerID(int), Name, Ticket, Cabin입니다.
데이터타입이 별 게 다 있습니다.
train_df.info()
print('_'*40)
test_df.info() 이렇게 확인할 수 있네요. 역시 사람은 똑똑해야합니다.
이렇게 확인할 수 있네요. 역시 사람은 똑똑해야합니다.
train_df.describe()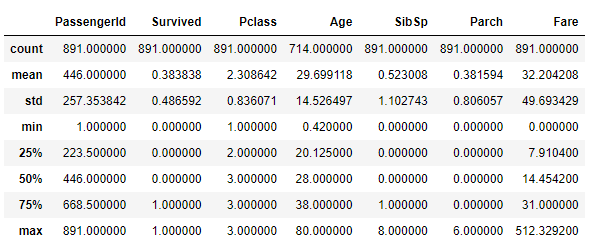 이렇다고 합니다. 해석할 수 있습니다.
이렇다고 합니다. 해석할 수 있습니다.
다음으로 범주형 데이터를 보겠습니다.
train_df.describe(include=['O'])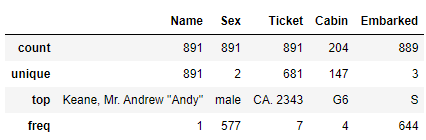 그렇다고 합니다.
그렇다고 합니다.
대충 보겠습니다.
약 38.38%의 승객이 생존하였습니다. 탑승객 중 약 64.7%이 남성입니다. 50%의 승객이 28세 미만입니다. 40세에서 80세의 승객 비율은 25% 미만입니다. 평균적으로 32달러를 지불하고 탑승하였습니다. Southampton에서 탑승한 승객이 약 72.4%로 가장 많습니다.
티켓값은 약 23%의 중복값이 있습니다. Cabin은 null값이 많이 존재합니다.
이름과 passengerID는 생존여부에 영향이 없습니다. (있다면 소름돋을것 같습니다)
여기서 몇 가지 가정을 해볼 수 있습니다.
성별에 따른 생존율, 형제자매와 부모여부에 따른 생존율, PClass에 따른 생존율 정도를 생각해볼 수 있겠습니다.
(참고: https://www.kaggle.com/startupsci/titanic-data-science-solutions)
