
- 다음 연산을 지원하는 키-값 저장소를 설계해보자
- put(key, value): 키-값 쌍을 저장소에 저장한다.
- get(key): 인자로 주어진 키에 매달린 값을 꺼낸다.
문제 이해 및 설계 범위 확정
- 키-값 쌍의 크기는 10KB 이하이다.
- 큰 데이터를 저장할 수 있어야 한다.
- 높은 가용성을 제공해야 한다. 즉, 시스템은 장애가 있더라도 빨리 응답해야 한다.
- 높은 규모 확장성을 제공해야 한다. 즉, 트래픽의 양에 따라 자동적으로 서버 증설/삭제가 이루어져야 한다.
- 데이터 일관성 수준은 조정이 가능해야 한다.
- 응답 지연시간(latancy)이 짧아야 한다.
단일 서버 키-값 저장소
- 가장 직관적인 방법은 키-값 쌍 전부를 메모리에 해시 테이블로 저장하는 것이다. 그러나 모든 데이터를 메모리에 두는 것은 불가능하다.
- 데이터를 압축하거나 자주 쓰이는 데이터만 메모리에 두는 방법이 있지만 근본적인 해결책은 아니다.
분산 키-값 저장소
- 키-값 쌍을 여러 서버에 분산시키기 때문에, 분산 키-값 저장소는 분산 해시 테이블이라고도 불린다. 분산 시스템을 설게할 때는 CAP 정리를 이해해야 한다.
CAP 정리
- CAP 정리는 데이터 일관성(consistency), 가용성(availability), 파티션 감내(partition tolerance)라는 세 가지 요구사항을 동시에 만족하는 분산 시스템을 설계하는 것은 불가능하다는 정리다.
- 데이터 일관성(consistency): 분산 시스템에 접속하는 모든 클라이언트는 어떤 노드에 접속하든 관계없이 같은 데이터를 봐야한다.
- 가용성(availability): 분산 시스템에 접속하는 클라이언트는 일부 노드에 장애가 발생하더라도 항상 응답을 받을 수 있어야 한다.
- 파티션 감내(partition tolerance): 파티션은 두 노드 사이에 통신 장애가 발생하였음을 의미한다. 파티션 감내는 네트워크에 파티션이 생기더라도 시스템은 계속 동작하여야 한다는 것을 뜻한다.
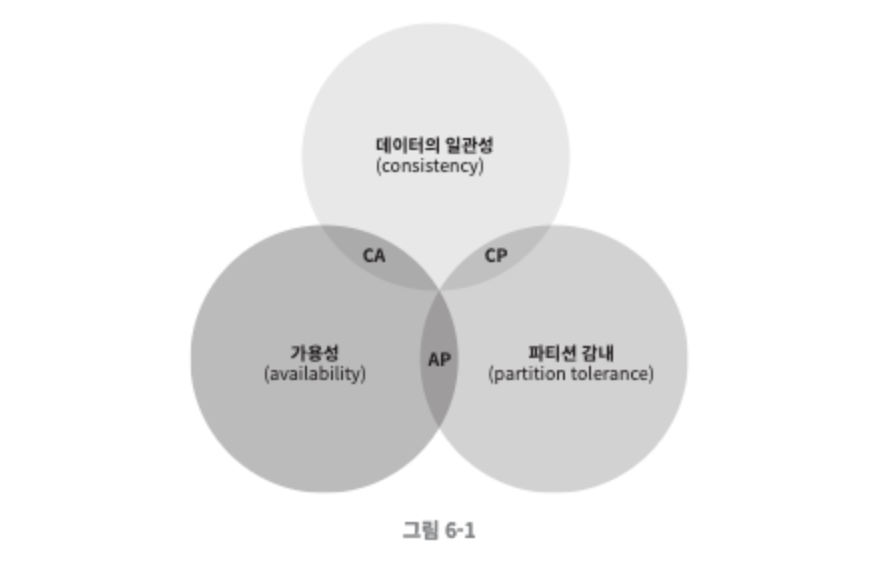
- CP 시스템: 일관성과 파티션 감내를 지원하는 키-값 저장소, 가용성을 희생
- AP 시스템: 가용성과 파티션 감내를 지원하는 키-값 저장소, 데이터 일관성을 희생
- CA 시스템: 시스템 일관성과 가용성을 지원하는 키-값 저장소, 파티션 감내를 지원하지 않으나, 네트워크 장애는 피할 수 없는 일로 여겨지므로 분산 시스템은 반드시 파티션 문제를 감내할 수 있도록 설계되어야 한다. 그러므로 실세계에 CA 시스템은 존재하지 않는다.
위의 정의만으로는 이해하기 어려우니 몇 가지 사례를 살펴보자. 세 대의 복제(replica) 노드 n1, n2, n3에 데이터를 복제하여 보관하는 상황을 그림 6-2와 같이 정의해보자.
이상적 상태
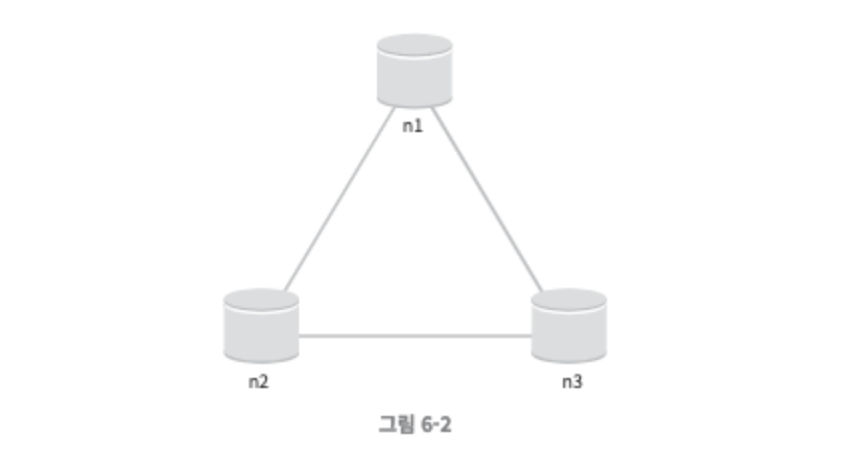
- 이상적 환경이라면 네트워크가 파티션되는 상황은 절대로 일어나지 않는다. 또한 n1에 기록된 데이터는 자동적으로 n2와 n3에 복제된다. 데이터 일관성과 가용성도 같이 만족한다.
실세계의 분산 시스템
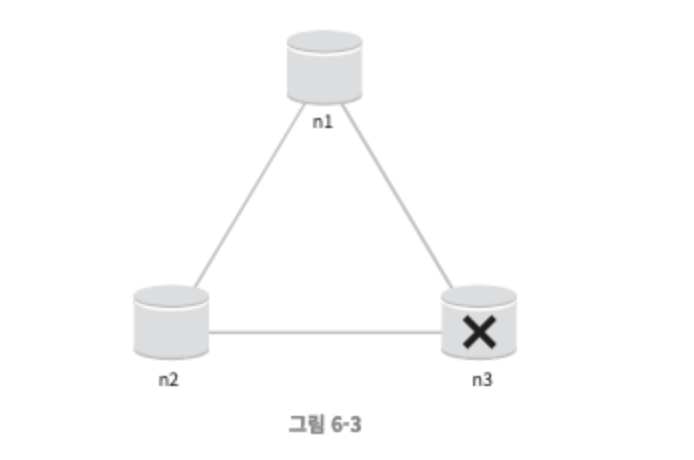
- 하지만 분산 시스템은 파티션 문제를 피할 수 없다. 이러한 문제가 발생하면 일관성과 가용성 중 하나를 선택해야 한다.
- 해당 그림은 n3에 장애가 발생하여 n1, n2와 통신할 수 없는 상황을 보여주고 있다. 클라이언트가 n1 또는 n2에 기록한 데이터는 n3에 전달되지 않는다. (가용성 선택)
- 마찬가지로 n3에 기록되었으나 아직 n1 및 n2에 로 전달되지 않은 데이터가 있다면 n1과 n2는 오래된 사본을 갖고 있을 것이다.
- 가용성 대신 일관성을 선택한다면(CP 시스템) 데이터 불일치 문제를 피하기 위해 n1과 n2에 대해 쓰기 연산을 중단시켜야 하는데, 그렇게 하면 가용성이 깨진다.
- 일관성을 대신 가용성을 선택한다면(AP 시스템) n3가 업데이트가 되지 않은 데이터를 반환하더라도 계속 읽기 연산을 허용해야 한다. 위의 그림에서 n1과 n2는 계속 쓰기 연산을 허용할 것이고, 파티션 문제가 해결된 뒤에 새로운 데이터를 n3로 전송할 것이다.
즉,분산 키-값 저장소룰 만들 때에는 그 요구사항에 맞게 CAP 정리를 적용해야 한다. 이 문제에 대해 면접관과 상의하고, 그 결론에 따라 시스템을 설계하도록 하자.
시스템 컴포넌트

평범한 백엔드 개발자