해시 키 재배치(rehash) 문제
- N개의 캐시 서버가 있다고 할 때, 부하를 나누기 위해 보편적으로 아래의 해시 함수를 사용한다.
serveriIndex = hash(key) % N (N = 서버 개수)
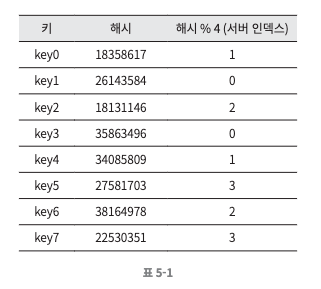
- 4대의 서버를 사용한다고 가정했을 때의 각각의 키에 대해 해시 값과 서버 인덱스를 계산한 표
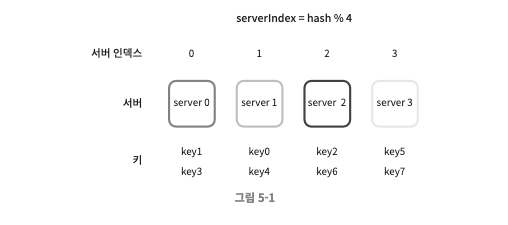
- 위의 해시 함수를 거쳐 각각의 요청이 서버에 할당 된다.
이 방법은 서버 풀의 크기가 고정되어 있을 때, 그리고 데이터 분포가 균등할 때는 잘 동작한다. 하지만 서버가 추가되거나 기존 서버가 삭제되면 문제가 생긴다. 아래의 예시는 1번 서버가 장애를 일으켜 동작을 중단했다고 가정한 상태다.
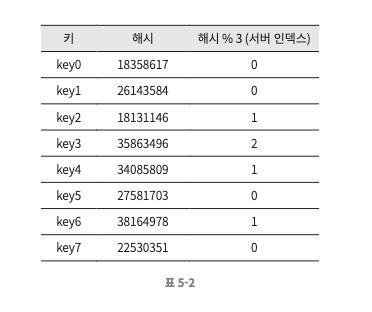
- 재분배된 표
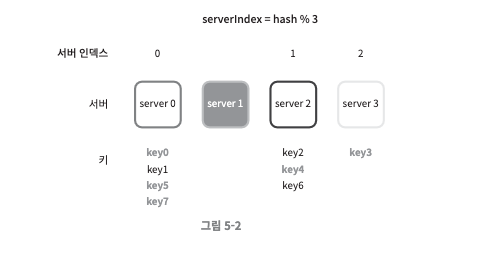
- 서버 풀의 크기가 3으로 줄어들어 서버 인덱스가 재분배되었고, 이는 대규모 캐시 미스(cache miss)를 유발한다.
안정 해시(Consistent Hashing)
- 안정 해시는 해시 테이블 크기가 조정될 때 평균적으로 오직
k/n개의 키만 재배치하는 해시 기술이다. 여기서 k는 키의 개수, n은 슬롯의 개수다.
해시 공간과 해시 링
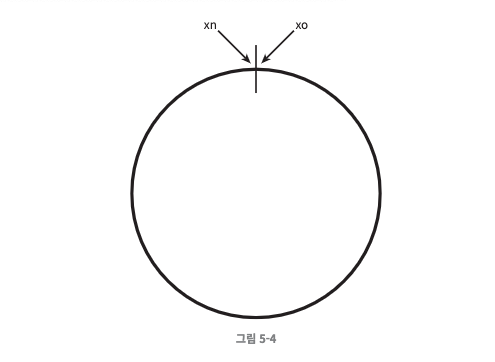
- 해시 함수 f는 SHA-1을 사용한다고 하고, 함수 출력 값 범위는 x0, x1 ... xn과 같다고 하자. SHA-1의 해시 공간은 0 ~ 2^160 -1이며, x0=0, xn = 2^160-1이고 나머지 값들은 그 사이의 값을 가질 것이다.
- 이 해시를 구부려 접으면 아래와 같은 해시 링이 만들어진다.
해시 서버
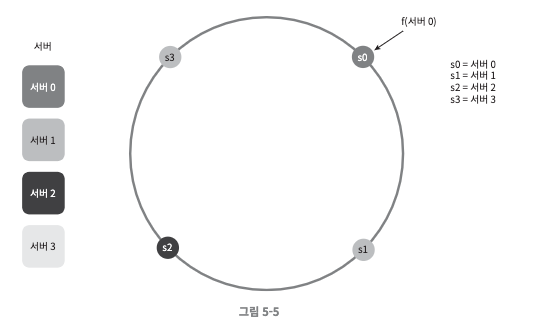
- 4개의 서버를 해시 링에 배치
해시 키
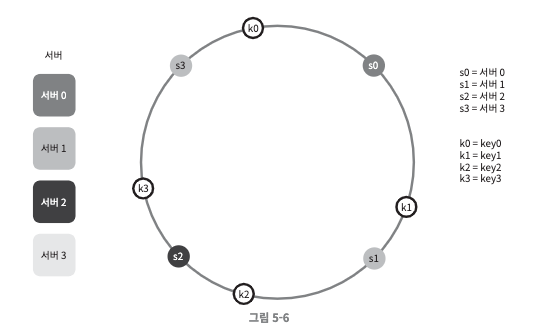
- 여기서 사용된 해시 함수는 "해시 키 재배치 문제"에 언급된 함수와 다르며, 나머지 연산은 사용하지 않고 있음에 유의하자.
- 캐시할 키 key0,key1,key2,key3 또한 해시 링 위의 아무 지점에 배치할 수 있다.
서버 조회
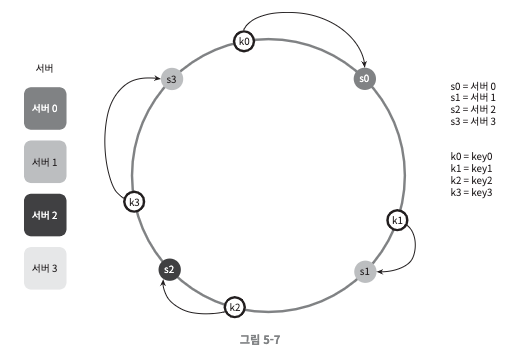
- 키가 저장되는 서버는, 해당 키의 위치로부터 시계 방향으로 링을 탐색해서 가장 먼저 만나는 서버
- key0은 서버0, key1은 서버1, key2은 서버2, key3은 서버3에 저장된다.
서버 추가
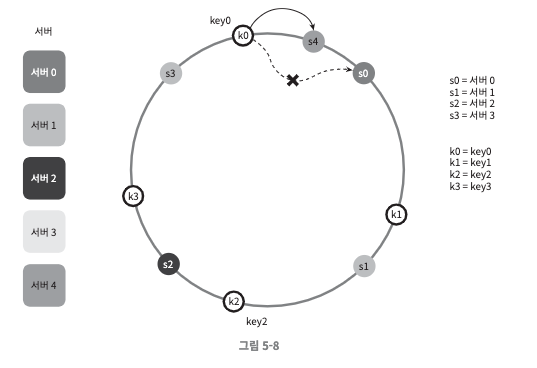
- 서버 4가 추가되면서 key0에서 가장 가까운 서버는 4이므로 key0만 재배치 되었다.
서버 제거
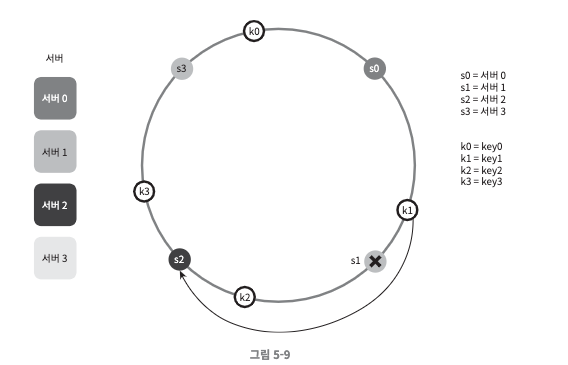
- 서버 1이 삭제되면서 key1이 그 다음 가까운 서버 2로 재배치 되었다.
기본 구현법의 두 가지 문제
- 안정 해시 알고리즘은 MIT에서 처음 제안되었고, 절차는 아래와 같다.
- 서버와 키를 균등 분포(uniform distribution) 해서 함수를 사용해 해시 링에 배치한다.
- 키의 위치에서 링을 시계 방향으로 탐색하다 만나는 최초의 서버가 키가 저장될 서버다.
- 다만 이 접근법에는 두 가지의 문제가 있다.
파티션의 크기를 균등하게 유지하는 것이 불가능
- 서버가 추가되거나 삭제되는 상황을 감안하면 파티션의 크기를 균등하게 유지하는 게 불가능하다.
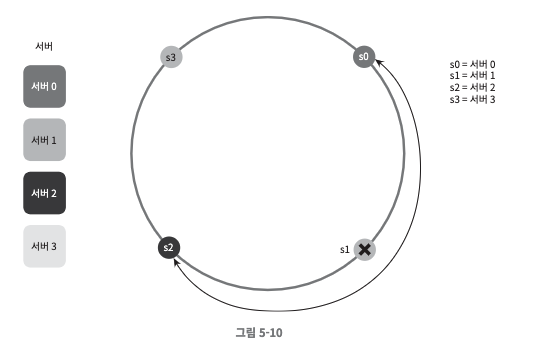
- s1이 삭제되는 바람에 s2의 파티션이 다른 파티션 대비 거의 두 배로 커졌다.
키의 균등 분포(uniform distribution)를 달성하기 어려움
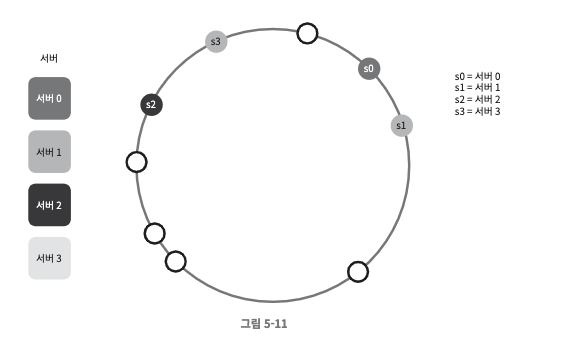
- 위와 같이 키와 서버가 분포되어 있을 경우에 s1, s3은 아무 데이터도 갖지 않는다. 대부분의 키는 s2에 보관될 것이다.
위의 두 가지 문제를 해결하기 위해 가상 노드(virual node) 또는 복제(replica)라 불리는 기법이다.
가상 노드
- 가상 노드는 실제 노드 또는 서버를 가리키는 노드로서, 하나의 서버는 링 위에 여러 개의 가상 노드를 갖는다.
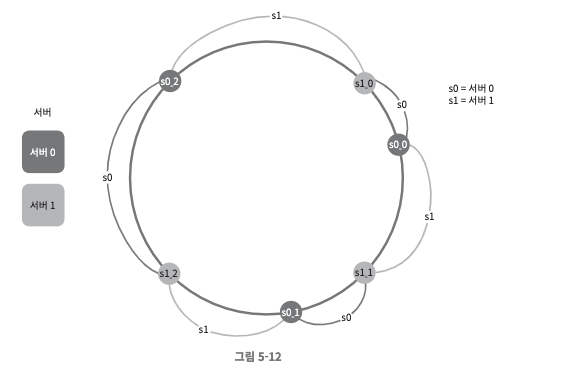
- 위의 그림에서 서버 0과 서버 1은 3개의 가상 노드를 갖는다. (숫자 3은 임의로 정한 것이며, 실제 시스템에는 이보다 훨씬 큰 값을 사용)
- 하나의 서버를 링에 배치하기 위에 세 개의 가상 노드를 사용했다. 즉 각 서버는 하나가 아닌 여러 개 파티션을 관리해야 한다. 그림에서 s0으로 표시된 파티션은 서버 0, s1은 서버 1이 관리하는 파티션이다.
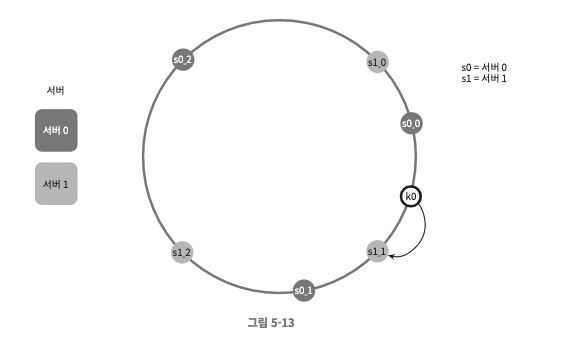
- 키의 위치로부터 시계방향으로 링을 탐색하다 만나는 최초의 가상 노드가 해당 키가 저장될 서버가 된다.
- k0은 시계방향으로 링을 탐색하다 s1_1을 만나고, 해당 키는 서버 1로 할당이 된다.
- 가상 노드의 개수를 늘리면 키의 분포는 점점 더 균등해진다. 표준 편차가 작아져서 데이터가 고르게 분포되기 때문이다. 다만 가상 노드 데이터를 저장할 공간이 더 많이 필요하다.
재배치할 키 결정
서버가 추가되거나 제거되면 데이터 일부는 재배치해야 한다. 어느 범위의 키가 재배치되어야 할까?
서버 추가
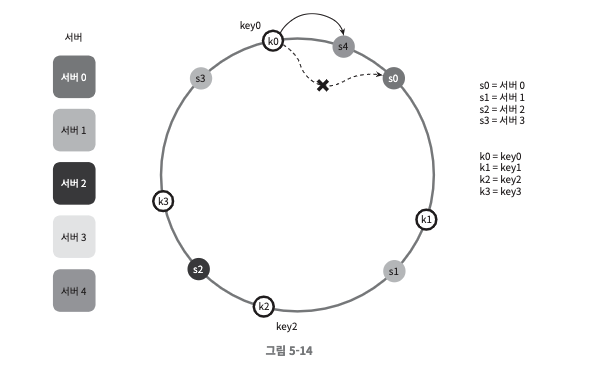
- 서버 4가 추가되었을 때, 영향을 받는 범위는 s3(반시계 방향에 있는 첫 번째 서버)부터 s4(새로 추가된 노드)다. 즉 s3부터 s4 사이에 있는 키들을 s4로 재배치해야 한다.
서버 삭제
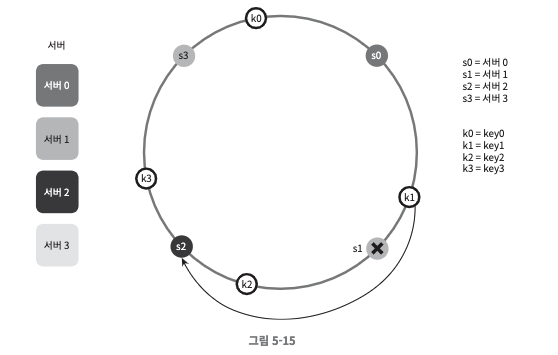
- 서버 1가 삭제되었을 때, 영향을 받는 범위는 s0(반시계 방향에 있는 첫 번째 서버)부터 s1(삭제된 노드)다. 즉 s0부터 s1 사이에 있는 키들을 s2로 재배치해야 한다.
마치며
- 안정 해시의 이점
- 서버가 추가되거나 삭제될 때 재배치되는 키의 수가 최소화된다.
- 데이터가 보다 균등하게 분포되므로 수평적 규묘 확장성을 달성하기 쉽다.
- 핫스팟 키 문제를 줄인다. 특정한 샤드에 대한 접근이 지나치게 빈번하면 서버 과부하 문제가 생길 수 있다. 케이티 페리, 저스틴 비버 같은 유명인의 데이터가 전부 같은 샤드에 있는 경우를 생각하면 이해하기 쉽다.
- 실제 사용되는 사례
- 아마존 DynamoDB의 파티셔닝 관련 컴포넌트
- 아파치 카산드라 클러스터에서 데이터 파티셔닝
- 디스코드 채팅 어플리케이션
- Akamai CDN
- 매그레프 네트워트 부하 분산기

평범한 백엔드 개발자