스프링부트 번개장터 프로젝트 백엔드

📖 목차
- 주제
- 스펙
- ERD 설계
- API 명세서
- 구현
- 트러블 슈팅
📌 주제
중고 거래 서비스 플랫폼인 번개장터 클론 코딩을 주제로 백엔드 개발을 맡아서 프로젝트를 진행
📌 스펙
- 클라우드 : AWS(EC2, RDS)
- OS : Ubuntu 18.04
- 서버 : Nginx 1.14.0
- IDE(툴) : Intellij, MySQL
- 프레임워크 : Spring Boot
- SDK : 11
📌 ERD 설계
1) 개체
- 요구사항 기능 분석 후 개체, 속성 파악
예) 회원 테이블, 상품 테이블, 카테고리 테이블 등등 - 개체 간의 관계 파악 (이 과정에서 관계 테이블이 생성될 수 있음)
예) 1:N관계, M:N관계
2) 속성
- PK의 데이터 타입은 BIGINT : 데이터가 무한히 많아지는 경우 고려 -> 개발 시 long 자료형
- 회원정보에서 password의 데이터 타입은 길이를 넉넉하게 VARCHAR(200)으로 : password는 암호화 과정을 거친 후에 저장하기 때문에
- 미디어 파일 URL의 데이터 타입은 TEXT
- Y/N값으로 구분하는 필드의 경우 BIT자료형을 사용하면 true/false값으로 사용이 가능
- 컬럼명명 규칙은 카멜케이스로 : java에서 카멜케이스 사용
- createdAt, updatedAt, status 컬럼을 테이블에 전체적으로 추가하는 것을 추천, 필요 없는 테이블을 추려서 제외하는 방향으로 고려
꼭 모든 테이블에 추가할 필요는 없지만, 서비스에서 중요한 데이터를 저장하는 테이블에는 추가해주는 것이 좋음 - 음수를 사용하는 경우가 아니라면 int unsigned 타입으로 수정(불필요한 공간을 최소화하기 위해)

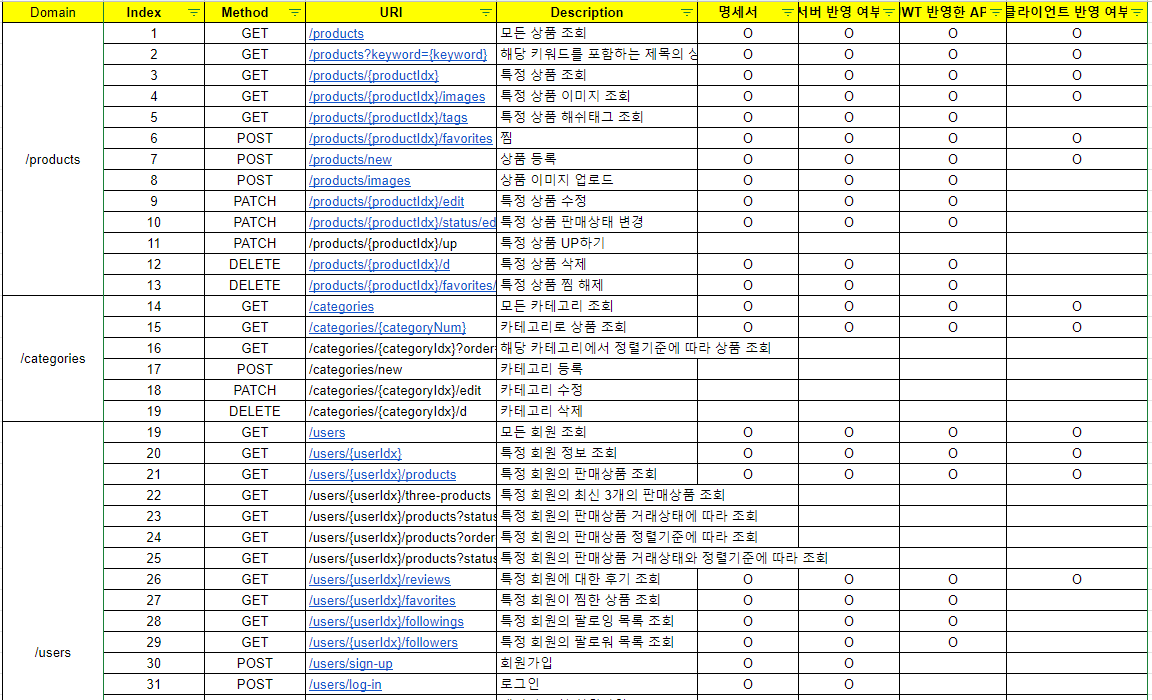
📌 API 명세서
1) 도메인 별로 나누기
- /products
- /users
- /categories
- /chats
- /accounts
- /purchases
2) RESTful API 규칙에 따라 리스트업
- 마지막이 / 로 끝나서는 안 된다.
- _(언더바) 대신 -(하이픈)을 사용한다.
- 소문자로 구성한다.
- 동사는 포함하지 않고, HTTP Method로 대체한다.
- 복수형 명사를 사용한다.
- 파일 확장자는 표시하지 않는다.
- 관계 표현
- 서브리소스로 관계 표현하는 방법
⇒ 일반적으로 소유 “has”의 관계를 묵시적으로 표현할 때 좋다.
예) GET, users/{userId}/devices - 서브리소스에 관계를 명시하는 방법
⇒ 관계의 명이 애매하거나 “구체적인 표현”이 필요할 때 사용한다.
예) GET, /users/{userId}/likes/devices
3) 각 API 세부사항 작성
- HTTP Method와 url
- Header (토큰, 타입 등)
- Body (요청 값, 타입, 예시, 설명)
- Query String & Path Valiable (사용될 경우에만 기입, 타입, 예시, 설명)
- Response (응답 값, 타입, 예시, 설명)
- 응답 코드 (정상 응답 코드, 에러 코드)
- 기타 : 응답 샘플
같이 협업하는 프론트엔드에서 봤을 때 이해하기 쉽고 정확하게 의사소통이 될 수 있도록 작성하는 것이 중요
📌 구현
1) 회원 관련
- 싸이클 : 소셜(일반) 회원가입 - > 소셜(일반) 로그인 - > 이름, 소개글 수정 - > 회원 탈퇴 - > 재 회원가입
- 회원 테이블과 소셜로그인 회원 테이블로 관리
- 소셜 회원가입/로그인 : access token으로 네이버에 회원 정보 요청, 네이버로부터 받은 "회원 ID"를 PK로 사용하고 회원 테이블에서 네이버 "회원 ID"를 참조
- 회원 탈퇴 시에는 status 값을 A(ctive)에서 D(elete)로 수정
- 재 회원가입 시에 status 값을 D(elete)에서 A(ctive)로 수정 => status 값을 이용하여 DB를 효율적으로 관리
소셜 로그인
1. 네이버 id와 pw를 입력
2. 네이버 서버에서 클라이언트(프론트)한테 access token을 줌
3. 클라이언트 서버에서 백엔드 서버에게 그 토큰을 줌
4. 백엔드에서 토큰을 사용하여 네이버 서버에 있는 필요한 정보를 가져옴
5. 이미 저장해놨던 소셜로그인 ID와 비교
6. 비교해서 맞으면 JWT 뿌림
2) 상품 관련
- 싸이클 : 상품 조회 / 상품 등록 - > 상품 수정 - > 삭제
- 제목의 키워드로 검색하거나 특정 상품을 조회
- 상품 등록 시에 상품 정보와 이미지들을 등록할 수 있도록 구현 (Transation 어노테이션 사용)
- 상품 수정 시에 원하는 부분만 수정할 수 있음
- 상품 삭제 시에는 status 값을 A(ctive)에서 D(elete)로 수정 => status 값을 이용하여 DB를 효율적으로 관리
3) 카테고리 관련
- 대분류 - 중분류 - 소분류 관계
- 대분류는 백의 자리로 구분(ex. 100, 200, 300)
- 중분류는 십의 자리로 구분(ex. 110, 120, 130)
- 소분류는 일의 자리로 구분(ex. 111, 112, 113)
- 카테고리 종속 관계를 관리하기에 편리
백의 자리가 같은 것은 같은 대분류 카테고리
십의 자리가 같은 것은 같은 중분류 카테고리
4) 찜
- 하나의 API에 찜하기 기능과 찜 해제 기능
- 처음에 찜 => 찜 생성
- 두번째 찜 => 찜 해제(status 값을 A에서 D)
- 세번째 찜 => 찜(status 값을 D에서 A)
=> status 값을 이용하여 DB를 효율적으로 관리
=> 하나의 API로 통합하여 클라이언트에게 편리한 API 제공
5) 팔로우
- 하나의 API에 팔로우 기능과 언팔로우 기능
- 처음에 팔로우 => 팔로우 생성
- 두번째 팔로우 => 언팔로우(status 값을 A에서 D)
- 세번째 팔로우 => 팔로우(status 값을 D에서 A)
=> status 값을 이용하여 DB를 효율적으로 관리 => 하나의 API로 통합하여 클라이언트에게 편리한 API 제공
📌 트러블 슈팅
1) 조인 후 데이터 조회할 때, 누락된 데이터가 있다?
=> INNER JOIN과 OUTER JOIN을 잘 확인해 볼 것
2) AWS EC2의 IP 주소가 바껴있다?
=>EC2 재부팅을 하면 IP 주소가 바뀐다. 탄력적 IP 설정으로 IP 주소를 고정시킬 수 있으니 처음부터 탄력적 IP로 고정시킬 것
3) API 테스트 도중 Cannot construct instance of 'dto 이름' 에러가 콘솔에 떴다면?
=> @NoArgsConstructor 어노테이션을 추가해 볼 것
4) AWS에서 스프링부트 실행 시에 에러 Message:HikariPool-1 - Thread starvation or clock leap detected ??
=> 11개 이상의 Connection을 제공
예) spring.datasource.hikari.maximum-pool-size=20
5) 트랜잭션 추가 후에 Post, Patch API가 실행이 안된다?
=> 여러 이유가 있겠지만, @Transactional(readOnly = true) 이 어노테이션을 사용한 경우 insert, update sql문 에러가 발생하니 @Transactional(readOnly = false)로 바꿔볼 것
6) 소셜 로그인 구현 시 네이버 서버에서 회원 정보를 가져오지 못한다면?
=> SSL 인증한 서버로부터 회원 정보를 요청해야 한다. SSL 인증이 된 서버인지 확인해 볼 것
7) nullpointerexception
null인 객체를 선언하고서, 그 객체가 갖는 메소드를 사용하려고 할 때 발생한 에러
=> 처음에 객체가 null이 아니도록 값을 넣어서 선언해 볼 것
