들어가며
데이터 분석 작업에서는 데이터를 불러오고, 정제하고, 변형하고, 재정렬하는 데이터 준비 과정에 많은 시간을 들이게 된다.
이때 파이썬 표준 라이브러리를 pandas와 함께 사용하면 큰 수고 없이 데이터를 원하는 형태로 가공할 수 있다.
이번 로그에서는 결측치, 중복 데이터, 문자열 처리와 같은 데이터 변환에 대한 도구들을 알아보자.
누락된 데이터 처리하기
누락된 데이터를 처리하는 일은 데이터 분석에서 흔히 발생하는 일이다. pandas는 누락 데이터를 가능한 쉽게 처리할 수 있게 모든 기술 통계는 누락된 데이터를 배제하고 처리한다.
pandas의 결측치 처리와 관련된 메서드는 크게 4가지가 있다.
| 인자 | 설명 |
|---|---|
| dropna | 누락된 데이터가 있는 축(로우,컬럼)을 제외시킨다. |
| fillna | 누락된 데이터를 대신할 값을 채운다. |
| isnull | 누락되거나 NA인 값을 알려주는 불리언 객체를 반환한다. |
| notnull | isnull과 반대되는 메서드 |
누락된 데이터 골라서 제거하기
pandas로 누락된 데이터를 골라내는 몇 가지 방법이 있는데, isnull 메서드의 불리언 객체를 사용해 직접 null data를 제거하는 방법도 있지만, dropna를 통해 간편히 해결할 수도 있다.
Series에 dropna 메서드를 적용하면 null이 아닌 데이터만 들어 있는 Series 객체를 반환한다.
data=pd.Series([1,NA,3.5,NA,7])
data.dropna()
"""
0 1.0
2 3.5
4 7.0
dtype: float64
"""DataFrame 객체의 경우에는 NA값인 로우나 컬럼을 제외시키거나, 하나라도 포함되고 있는 로우나 컬럼을 제외시킬 수 있다.dropna는 기본적으론 NA값을 하나라도 포함하고 있는 로우를 제외시킨다.
data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA],
[NA, NA, NA], [NA, 6.5, 3.]])
cleaned = data.dropna()
cleaned
# 0 1 2
#0 1.0 6.5 3.0이때 how='all'옵션을 넘기면 모두 NA값인 로우만 제외 시킨다.
data.dropna(how='all')
#0 1 2
#0 1.0 6.5 3.0
#1 1.0 NaN NaN
#3 NaN 6.5 3.0DataFrame의 몇 개 이상의 값이 들어 있는 로우만 살펴보고 싶다면 thresh 옵션에 원하는 개수를 넘기면 된다.
df=pd.DataFrame(np.random.randn(7,3))
df.iloc[:4,1]=NA
df.iloc[:2,2]=NA
df
df.dropna(thresh=2)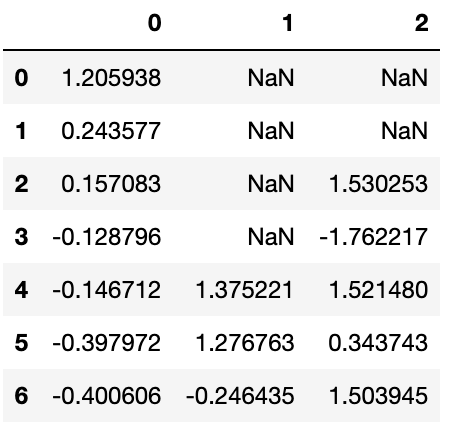
즉, row를 Null 데이터가 포함된 개수에 따라 dropna 옵션을 통해 제어할 수 있다.
결측치 채우기
학습할 데이터의 수가 적은 경우에는 누락된 값을 제외시키지 않고, 데이터 상의 결측을 어떻게든 메우고 싶은 경우가 있을 수 있다.
이 경우 fillna 메서드에 Null 값에 채워넣고 싶은 값을 넘겨주면된다. fillna에 Dictionary 객체를 넘겨서 각 컬럼마다 다른 값을 채울 수도 있다.
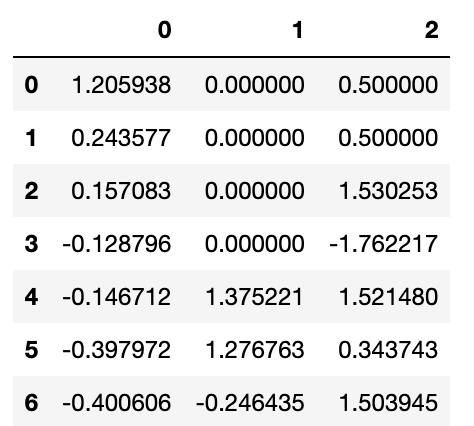
df.fillna({1:0,2:0.5})
"""
column 1의 Null에는 0을,
column 2의 Null에는 0.5를 채운다
"""
원래 fillna는 새로운 객체를 반환하지만, inplace 옵션을 True로 지정해주면 기존 객체를 변경할 수도 있다.
또한 코드가 왜 출력값이 아래와 같은지 생각해보자.
df=pd.DataFrame(np.random.randn(6,3))
df.iloc[2:,1]=NA
df.iloc[4:,2]=NA
df.fillna(method='ffill',limit=2,inplace=True)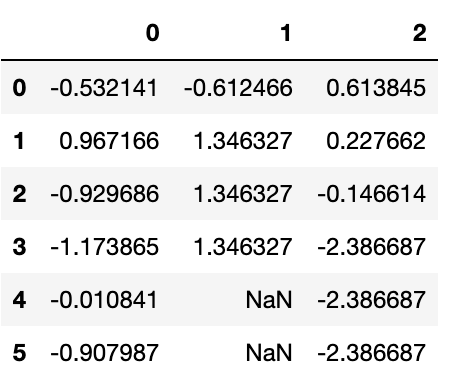
fillna Method의 option 중 'ffill'은 NA가 등장하기 이전 값을 그대로 복사한다.
df.iloc[2:,1]을 통해 column 1의 row index 2~5 4개의 row에 NA값으로 대체된다.
하지만, 현재 이러한 복사의 limit가 2로 제한되어져 있기에, 2개의 값은 NA가 아닌 직전값으로 대체되었지만, row index 4,5의 data는 대체되지 않았다.
fillna를 이용해서 매우 다양한 일을 할 수 있는데, 예를 들어 Series(DataFrame의 Column)의 평균값이나 중간값을 전달할 수도 있다.
df.fillna({1:df[1].mean(),2:df[2].mean()})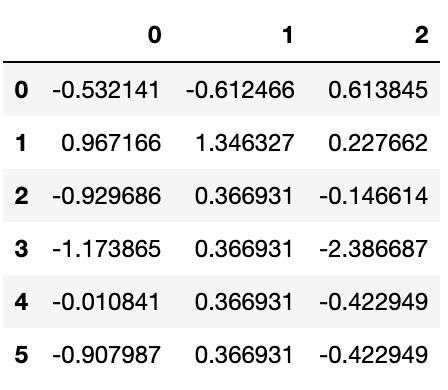
문자열 다루기
파이썬은 문자열이나 텍스트 처리가 용이하다. 대부분의 텍스트 연산은 문자열 객체의 내장 메서드로 간단하게 처리할 수있다.좀 더 복잡한 패턴 매칭이나 텍스트 조작은 pandas를 활용하여 처리할 수 있다.
문자열 객체 메서드
문자열을 다뤄야 하는 대부분은 파이썬 내장 문자열 메서드만으로도 충분하다. 예를 들어 일정한 문자로 구분된 문자열은 split 메서드를 이용해서 분리할 수 있다. 이 split 메서드는 공백 문자를 제거하는 strip 메서드와 조합해서 사용하기도 한다.
val='a,b, guido'
pieces=[x.strip() for x in val.split(',')]
pieces
#['a', 'b', 'guido']일치하는 부분문자열의 위치를 찾는 방법도 있다. index나 find를 사용하는 것도 가능하지만 파이썬의 in 예약어를 사용하면 일치하는 부분문자열을 쉽게 찾을 수 있다.
'guido' in val
#True
val.index(',')
#1
val.find(":")
#-1find와 index의 차이는 index의 경우에는 문자열을 찾지못할 시 ValueError를 발생시키고,find는 -1을 반환한다.
count는 특정 부분문자열이 몇 건 발견되었는지 반환한다.
val.count(',')
#2replace는 특정 문자열을 다른 문자열로 치환한다. 이 메서드는 대체할 문자열로 비어있는 값을 넘겨서 특정 문자열을 삭제할 때도 사용된다.
val.replace(',','::')
#'a::b:: guido'
val.replace(',','')
#'ab guido'이외에도 join 메서드를 이용하여, 문자열을 구분자로 하여 다른 문자열을 순서대로 이어붙일 수 있다.
'::'.join(pieces)
'a::b::guido'정규표현식
정규표현식은 텍스트에서 문자열 패턴을 찾는 유연한 방법을 제공한다.
파이썬에는 re 모듈이 내장되어 있어서 문자열에 대한 정규표현식을 처리한다.
re모듈 함수는 패턴 매칭, 치환, 분리 세 가지로 나눌 수 있다. 정규표현식은 텍스트 내에 존재하는 패턴을 표현하고 이를 여러가지 다양한 목적으로 사용할 수 있게 돼있다.
여러가지 공백 문자가 포함된 문자열을 나누고 싶다면 하나 이상의 공백 문자를 의미하는 /s+를 사용해서 문자열을 분리한다.
import re
text='foo bar\tbaz\tqux'
re.split('\s+',text)
#['foo', 'bar', 'baz', 'qux']
#또 다른 방법
regex=re.compile('\s+')
regex.split(text)re.split('\s+',text)을 사용하면 먼저 정규표현식이 컴파일되고, 그다음에 split메서드가 실행된다. re.complie로 직접 정규표현식을 컴파일하고 그렇게 얻은 정규표현식 객체를 재사용하는 것도 가능하다.
이러한 정규표현식에 매칭되는 모든 패턴의 목록을 얻고 싶다면 findall 메서드를 사용하면 된다.
regex.findall(text)
[' ', '\t', '\t']같은 정규표현식을 다른 문자열에도 적용해야 한다면 re.compile을 이용해서 정규표현식 객체를 만들어쓰는 편이 cpu사용량을 아낄 수 있다.
match와 search는 findall 메서드와 닮았다.
| 인자 | 설명 |
|---|---|
| findall | 문자열에서 일치하는 모든 부분문자열을 찾아준다 |
| search | 패턴과 일치하는 첫 번째 존재를 반환한다 |
| match | 문자열의 시작부분에서 일치하는 것만 찾아준다. |
이메일 주소를 검사하는 정규표현식의 통해 세 메서드 사이의 차이점을 찾아보자.
text = """Dave: dave@google.com
Steve: steve@gmail.com
Rob: rob@gmail.com
Ryan: ryan@yahoo.com
"""
pattern = r'[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}'
#pattern 변수는 이메일을 이룰 수 있는 패턴을 기록한 것이다.
regex=re.compile(pattern,flags=re.IGNORECASE)
#re.IGNORECASE는 정규표현식이 대소문자를 가리지 않도록 한다.
regex.findall(text)
#['dave@google.com', 'steve@gmail.com', 'rob@gmail.com', 'ryan@yahoo.com']findall메서드를 사용해서 이메일 주서의 리스트를 생성하였다.
search메서드는 이전에 말했든 텍스트에서 첫 번쨰 이메일 주소(패턴과 일치하는 첫 번째 존재)만을 찾아준다.
regex.search(text)
#<re.Match object; span=(5, 20), match='dave@google.com'>
print(regex.match(text))
#Nonematch메서드는 문자열의 시작부분에서 일차하는지 검사하기 때문에 None값을 반환한다.
sub메서드는 찾은 패턴을 주어진 문자열로 치환하여 새로운 문자열을 반환한다.
print(regex.sub('SUB',text))
#Dave: SUB
#Steve: SUB
#Rob: SUB
#Ryan: SUB이메일 주소를 찾아서 각 컴포넌트로 나눠야 한다면 패턴을 괄호로 묶어서 처리하면 된다. 이렇게 만든 정규표현식을 match 객체를 이용하면 groups 메서드로 각 패턴 컴포넌트의 튜플을 얻을 수 있다.
pattern = r'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\.([A-Z]{2,4})'
regex=re.compile(pattern,flags=re.IGNORECASE)
m=regex.match('cwoo505@naver.com')
m.groups()
#('cwoo505', 'naver', 'com')
m=regex.match('cwoo505@naver.com dkssud231@goggle.com')
m.groups()
#('cwoo505', 'naver', 'com')당연히 match 함수는 문자열의 시작부분에서 일치하는 것만 찾아주기 때문에 하나의 케이스만 반환한다.
이런 경우(패턴에 그룹이 존재)엔 findall 메서드는 튜플의 목록을 반환한기에 이를 사용해주면 된다.
regex.findall(text)
#[('dave', 'google', 'com'),
# ('steve', 'gmail', 'com'),
# ('rob', 'gmail', 'com'),
# ('ryan', 'yahoo', 'com')]sub 역시 \1,\2 같은 특수한 기호를 사용해서 각 패턴 그룹에 접근할 수 있다. \1은 첫 번째 그룹을 의미하고, 마찬가지로 \2는 2번째 그룹을 의미한다.
sen=regex.sub(r'Username:\1,Domain:\2,Suffix:\3',text)
print(sen)
#Dave: Username:dave,Domain:google,Suffix:com
#Steve: Username:steve,Domain:gmail,Suffix:com
#Rob: Username:rob,Domain:gmail,Suffix:com
#Ryan: Username:ryan,Domain:yahoo,Suffix:com7.3.3 pandas의 벡터화된 문자열 함수
뒤죽박죽😵💫인 데이터를 분석을하기 위해선 문자열을 다듬고 정규화하는 작업을 해야한다. 문자열을 담고 있는 컬럼에 누락된 값이 있다면 일은 더 복잡해진다.
data={'Dave':'dave@google.com','Steve':'steve@gmail.com','Rob':'rob@gmail.com','Wes':np.nan}
data=pd.Series(data)
data.isnull()
#Dave False
#Steve False
#Rob False
#Wes True
#dtype: bool문자열과 정규표현식 메서드는 map을 이용해서 각 값에 적용할 수 있지만 NA값을 만나면 실패하게 된다.
물론 이런 문제를 해결하기 위해서 Series에는 NA값을 건너뛰도록하는 간결한 문자열 처리 메서드가 있다.
이는 Series의 str속성을 이용하는데, 예제를 보자.
data.str.contains('gmail')
#Dave False
#Steve True
#Rob True
#Wes NaN
#dtype: object정규표현식을 IGNORECASE 같은 re옵션과 함께 사용하는 것도 가능하다.
data.str.findall(pattern,flags=re.IGNORECASE)
#Dave [(dave, google, com)]
#Steve [(steve, gmail, com)]
#Rob [(rob, gmail, com)]
#Wes NaN
#dtype: object마치며
이번 로그에서는 누락된 데이터를 다루는 법과 문자열(정규표현식)을 다뤄봤는데, 다음 로그에서는 데이터를 원하는 형식으로 변환시키는 방법을 배워보자.
