pandas
pandas는 앞으로 데이터 분석에 있어서 자주 살펴볼 라이브러리다.
pandas는 고수준의 자료구조와 파이썬에서 빠르고 쉽게 사용할 수 있는 데이터 분석 도구를 포함하고있다.
pandas가 Numpy의 스타일(벡터화된 데이터 처리,배열 기반의 함수제공)을 많이 차용했지만, 가장 큰 차이점은 pandas는 표 형식의 데이터나 다양한 형태의 데이터를 다루는 데 초점을 맞춰 설계했다.
Numpy는 단일 산술 배열 데이터를 다루는 데 특화되어 있다.
pandas 자료구조 소개
pandas에 대해 알아볼려면 pandas의 객체 Series와 DataFrame. 이 두 가지 자료구조에 익숙해질 필요가 있다. 이 두 가지 자료구조로 대부분의 문제를 해결할 수 있고, 탄탄한 기반을 제공하기 때문!
Series
Series는 일련의 객체를 담을 수 있는 1차원 배열 같은 자료구조다.
배열 데이터로 간단히 Series 객체를 생성할 수 있다.
import pandas as pd
obj=pd.Series([4,7,-5,3])
obj
"""
out:
0 4
1 7
2 -5
3 3
dtype: int64
"""Series 객체를 호출하면, 왼쪽에 색인을 보여주고 오른쪽에 해당 색인의 값을 보여준다. 위 예제에서는 데이터의 색인을 지정하지 않았으니 기본 색인인 range 값이 표시된다.
Series의 배열과 색인 객체는 각각 values와 index 메서드 통해 얻을 수 있다.
obj.values
#out:array([ 4, 7, -5, 3])
obj.index
#out:RangeIndex(start=0, stop=4, step=1)Series 객체를 생성할 때 색인을 지정해주고 싶다면 index 예약어에 객체를 넘기면 된다.
obj2=pd.Series([4,7,-5,3],index=['a','b','c','d'])
obj2
"""
out:
a 4
b 7
c -5
d 3
dtype: int64
"""Numpy 배열과 비교하자면, 단일 값을 선택하거나 여러 값을 선택할 때 색인으로 라벨을 사용할 수 있다.
obj2['a']
#out:4
obj2['d']=6
#out:6
obj2[['a','b','d']]
"""
out:
a 4
b 7
d 6
dtype: int64
"""여기서 ['a','b','d']는 색인의 배열로 해석된다
불리언 배열을 사용해서 값을 걸러 내거나 수학 함수도 적용할 수 있다. 또한, Numpy 배열 연산을 수행해도 색인-값 연결이 유지된다.
obj2[obj2>0]
"""
out:
a 4
b 7
d 6
dtype: int64
"""
obj2*2
"""
out:
a 8
b 14
c -10
d 12
dtype: int64
"""
import numpy as np
np.exp(obj2) #numpy의 단항 ufunc
"""
out:
a 54.598150
b 1096.633158
c 0.006738
d 403.428793
dtype: float64
"""Series는 색인 값이 데이터 값을 매핑하고 있으므로 파이썬의 사전형과 비슷하다. 때문에, Series 객체는 파이썬의 사전형을 인자로 받아야 하는 많은 함수에서 사전을 대체하여 사용할 수 있다.
'b' in obj2
#out: True
'e' in obj2
#out: False파이썬 사전 객체로부터 Series 객체를 생성할 수도 있다.
sdata={'Ohio':35000,"Texas":71000,"Oregon":16000,"Utah":5000}
obj3=pd.Series(sdata)
obj3
"""
out:
Ohio 35000
Texas 71000
Oregon 16000
Utah 5000
dtype: int64
"""사전 객체만 가지고 Series 객체를 생성하면 생성된 Series 객체의 색인에는 사전의 키값이 순서대로 들어간다.색인을 직접 지정하고 싶다면 원하는 순서대로 직접 색인을 넘겨줄 수 있다.
states=['California','Ohio','Oregon','Texas']
obj4=pd.Series(sdata,index=states)
obj4
#out:
#California NaN
#Ohio 35000.0
#Oregon 16000.0
#Texas 71000.0
#dtype: float64위 예제를 보면 sdata에 있는 값 중 3개만 확인할 수 있는데, 'California'에 대한 값은 찾을 수 없기 때문이다. 이 값은 NaN(not a number)로 표시된다.
'Utah'는 states에 포함되어 있지 않으므로 실행 결과에서 빠지게 된다.
pandas의 isnull과 notnull 함수는 누락된 데이터를 찾을 때 사용된다.
pd.isnull(obj4)
#out:
#California True
#Ohio False
#Oregon False
#Texas False
#dtype: bool
pd.notnull(obj4)
#out:
#California False
#Ohio True
#Oregon True
#Texas True
#dtype: bool이 메서드는 Series의 인스턴스 메서드로도 존재한다.
obj4.isnull()
#out:
#California True
#Ohio False
#Oregon False
#Texas False
#dtype: bool누락된 데이터를 처리하는 방법은 따로 작성해두었다.
Series의 유용한 기능으로 산술 연산에서 색인과 라벨을 자동 정렬해주는 것도 있다.
obj3+obj4
#out:
#California NaN
#Ohio 70000.0
#Oregon 32000.0
#Texas 142000.0
#Utah NaN
#dtype: float64Series 객체와 Series의 색인은 모두 name 속성이 있는데 이 속성은 pandas의 핵심 기능과 밀접한 관련이 있다.
obj4.name='plpulation'
obj4.index.name='state'
obj4
#out:
#state
#California NaN
#Ohio 35000.0
#Oregon 16000.0
#Texas 71000.0
#Name: population, dtype: float64Series 색인은 대입하여 변경할 수 있다.
obj
#out:
#0 4
#1 7
#2 -5
#3 3
#dtype: int64
obj.index=['Bob','Steve','Jeff','Ryan']
obj
#Bob 4
#Steve 7
#Jeff -5
#Ryan 3
#dtype: int64DataFrame
DataFrame은 표 같은 스프레드시트 형식의 자료구조이다. 여러 개의 컬럼이 있는데 각 컬럼은 서로 다른 종류의 값(숫자, 문자열, 불리언 등) 을 담을 수 있다.
DataFrame은 로우와 컬럼에 대한 색인을 가지고 있는데, 색인의 모양이 같은 Series 객체를 담고 있는 파이썬 사전으로 생각하면 편하다.
DataFrame 생성자에 넘길 수 있는 자료형의 목록은 다음과 같다.
| 형 | 설명 |
|---|---|
| 2차원 ndarray, 리스트, 튜플의 사전 | 데이터를 담고있는 행렬, 선택적으로 행과 열의 이름을 전달할 수 있다. |
| Numpy의 구조화 배열 | 배열의 사전과 같은 방식으로 취급된다. |
| Series의 사전 | Series의 각 값이 컬럼이 된다. 명시적으로 색인을 넘겨주지 않으면 각 Series의 색인이 DataFrame의 컬럼 이름이 된다. |
| 중첩된 사전 | 내부에 있는 사전이 컬럼이 된다. 키값은 'Series의 사전'과 마찬가지로 합쳐져서 로우의 색인이된다. |
| 사전이나 Series의 리스트 | 리스트의 각 항목이 DataFrame의 로우가 된다. 합쳐진 사전의 키값이나 Series의 색인이 DataFrame의 컬럼이름이 된다. |
| 리스트나 튜플의 리스트 | 2차원 ndarray와 같은 방식으로 취급된다. |
| 다른 DataFrame | 색인을 따로 지정하지 않으면 DataFrame의 색인이 그대로 사용된다. |
| Numpy MaskedArray | 2차원 ndarray와 같은 방식으로 취급되지만 마스크값은 반환되는 데이터프레임에서 NA값이 된다. |
DataFrame 객체는 다양한 방법으로 생성할 수 있지만 가장 흔하게 사용되는 방법은 '같은 길이의 리스트'가 담긴 '사전'을 이용하거나 Numpy 배열을 이용하는 것이다.
data={'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002,2003],
'pop':[1.5,1.7,3.6,2.4,2.9,3.2]}
frame=pd.DataFrame(data)
frame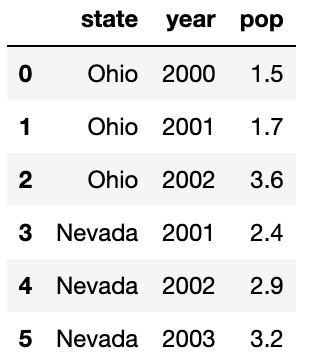
ipython이 아닌 jupyter notebook을 이용하면 DataFrame 객체는 위와 같이 보기 편하도록 html 표형식으로 출력된다.
앞으로 다룰 데이터는 주석으로 출력값을 표현하는데 한계가 있어, 편의상 주석으로 출력값을 표현하는 게 아닌 캡쳐본으로 대체하겠다.
큰 dataFrame을 다룰 때는 head 메서드를 이용해서 처음 5개의 로우만 출력할 수 있다.
frame.head()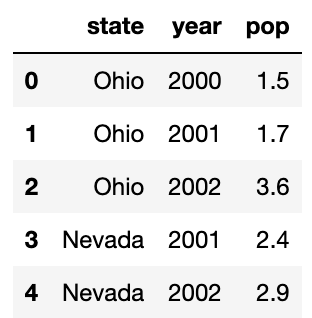
columns를 지정하면 원하는 순서를 가진 DataFrame 객체가 생성된다.
pd.DataFrame(data,columns=['year','state','pop'])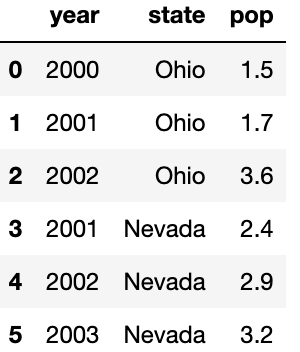
마찬가지로 사전에 없는 값을 넘기면 결측치(NaN)으로 저장된다.
frame2=pd.DataFrame(data,columns=['year','state','pop','debt'],index=['one','two','three','four','five','six'])
frame2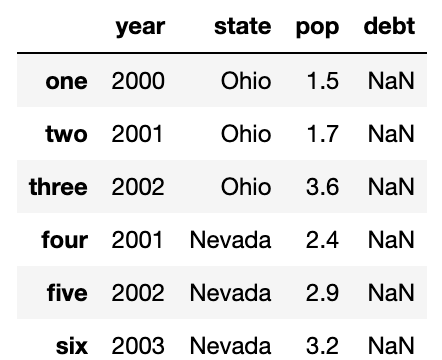
DataFrame의 컬럼은 Series처럼 사전 형식의 표기법으로 접근하거나 속성 형식으로 접근할 수 있다.
frame2.year
frame2['pop']
반환된 Series 객체가 DataFrame과 같은 색인을 가지면 알맞은 값으로 name속성이 채워진다.
로우는 위치나 loc 속성을 이용해서 이름을 통해 접근할 수 있다.
frame2.loc['three']
컬럼으로 값을 대입할 수 있다. 예를 들어 현재 비어 있는 'debt' 컬럼에 스칼라값이나 배열의 값을 대입할 수 있다.
frame2['debt']=np.arange(6.)
frame2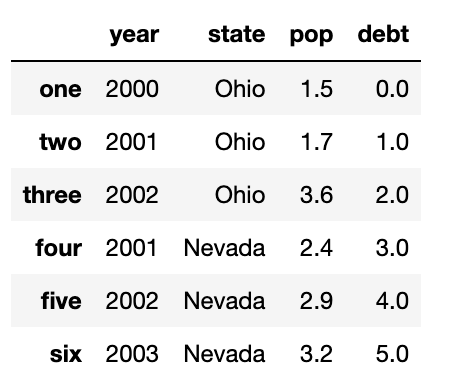
리스트나 배열을 컬럼에 대입할 때는 대입하려는 값의 길이가 DataFrame의 크기와 동일해야 한다. Series를 대입하면 DataFraem의 색인에 따라 값이 대입되며 존재하지 않는 색인에는 NaN이 대입된다.
val=pd.Series([-1.2,-1.5,-1.7],index['two','four','five'])
frame2['debt']=val
frame2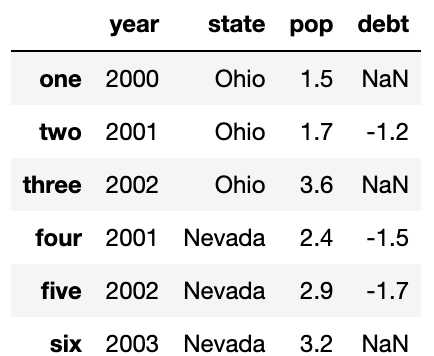
존재하지 않는 컬럼에 데이터를 대입하여 새로운 컬럼을 생성할 수 있다. 또한 파이썬 사전형에서 처럼 del 예약어를 사용해서 컬럼을 삭제할 수 있다.
del 예약어에 대한 예제로, state 컬럼의 값이 'Ohio'인지 아닌지에 대한 불리언 값을 담고 있는 새로운 컬럼을 생성해보자.
frame2['eastern']=frame2.state=='Ohio'
frame2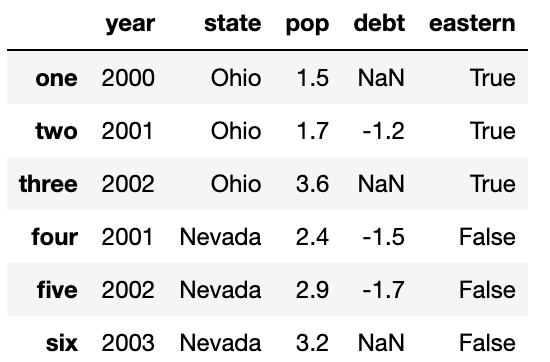
del 예약어를 통해 이 컬럼을 삭제할 수 있지만, 삭제할 때 이용할 수 있는 메서드(drop)가 있으니, 추천하진 않는다.
del frame2['eastern']
frame2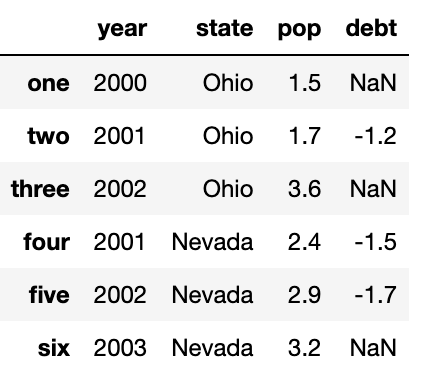
DataFrame에서 색인을 이용해서 얻은 컬럼은 Numpy와 마찬가지로 내부 데이터에 대한 뷰이기에 복사가 이루어지지않는다. 복사본이 필요하면 copy 메서드를 이용하자!
DataFrame 객체를 생성할 때 '같은 길이의 리스트에 담긴 사전'이 아닌 '중첩된 사전'을 통해서도 객체를 생성할 수 있다.
pop={'Nevada':{2001:2.4,2002:2.9},'Ohio':{2000:1.5,2001:1.7,2002:3.6}}
frame3=pd.DataFrame(pop)
frame3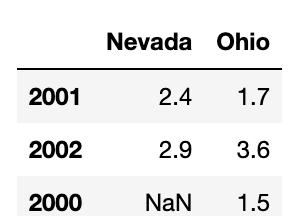
이 중첩된 사전을 DataFrame에 넘기면 바깥에 있는 사전의 키는 컬럼이 되고 안에 있는 키는 로우가 된다.
Numpy 배열과 유사한 문법으로 데이터를 전치할 수도 있다.
frame3.T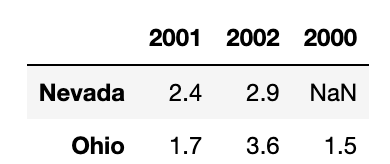
데이터프레임의 색인과 컬럼에 name 속성을 지정했다면 이 역시 함께 출력된다.
frame3.index.name='year';frame3.columns.name='state'
frame3Series와 유사하게 values 속성은 DataFrame에 저장된 데이터를 2차원 배열로 반환한다.
frame3.values
DataFrame의 컬럼이 서로 다른 dtype을 가지고 있다면 모든 컬럼을 수용하기 위해 그 컬럼의 배열의 dtype이 선택된다는걸 기억하자.
색인 객체
pandas의 색인 객체는 표 형식의 데이터에서 각 로우와 컬럼에 대한 이름과 다른 메타데이터를 저장하는 객체다.
※메타데이터:데이터를 설명하는 데이터
색인이 제공하는 기능을 유용하게 사용할 일이 별로 없을 수 있지만, 일부 연산의 경우 색인을 반환하기도 하므로 어떻게 동작하는지 이해하는 것은 중요하다.
색인 객체는 변경이 불가능하다. 그렇기에 자료구조 사이에서 안전하게 공유될 수 있음을 기억하자.
obj=pd.Series(range(3),index=['a','b','c'])
index=obj.index
#index[1]='d' ->TypeError 발생
labels=pd.Index(np.arange(3))
labels
#out:Int64Index([0, 1, 2], dtype='int64')
obj2=pd.Series([1.5,-2.5,0],index=labels)
obj2
#out:obj2=pd.Series([1.5,-2.5,0],index=labels)
obj2
obj2=pd.Series([1.5,-2.5,0],index=labels)
obj2
#out:0 1.5
#1 -2.5
#2 0.0
#dtype: float64
obj2.index is labels
#out:True파이썬 집합과는 달리 pandas의 인덱스는 중복되는 값을 허용한다.또한,중복되는 값으로 선택을 하면 해당 값을 가진 모든 항목이 선택이된다.
dup_labels=pd.Index(['foo','foo','bar','bar'])
dup_labels
#out:Index(['foo', 'foo', 'bar', 'bar'], dtype='object')
df=pd.Series([1,2,3,4],index=dup_labels)
df
#out:foo 1
#foo 2
#bar 3
#bar 4
#dtype: int64
df.foo=10
df
#out: foo 10
#foo 10
#bar 3
#bar 4
#dtype: int64마치며
이번 로그에서는 pandas의 Series와 DataFrame이란 무엇인지 알아보았고, 또 그것을 간단하게 핸들링해보았다...!
다음 로그에서는 Series와 DataFrame의 또 다른 기능들을 추가적으로 살펴보자.
