GAN(Generative Adversarial Network)
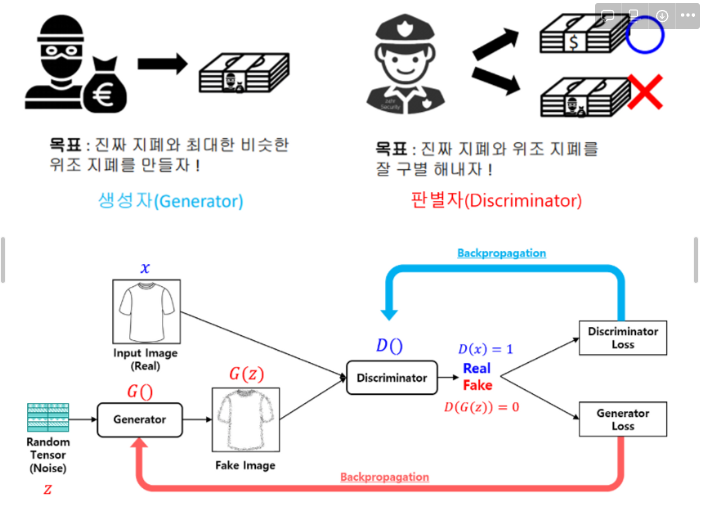
- Generator(생성모델)와 Discriminator(판별모델)라는 2개의 네트워크로 이루어져 있다.
- 두 네트워크를 적대적으로 학습시키며 목적을 달성하는 방법이다.
- 생성모델(G)의 목적은 진짜 분포에 가까운 가짜 분포를 생성하는 것
- 판별모델(D)의 목적은 표본이 가짜 분포에 속하는지 진짜 분포에 속하는지 결정하는 것
GAN PyTorch로 구현해보기 전체 코드
import os
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, random_split
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt
import pytorch_lightning as pl
random_seed = 42
torch.manual_seed(random_seed)
BATCH_SIZE=128
AVAIL_GPUS = min(1, torch.cuda.device_count())
NUM_WORKERS=int(os.cpu_count() / 2)
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, data_dir="./data",
batch_size=BATCH_SIZE, num_workers=NUM_WORKERS):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
self.num_workers = num_workers
self.transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
]
)
def prepare_data(self):
MNIST(self.data_dir, train=True, download=True)
MNIST(self.data_dir, train=False, download=True)
def setup(self, stage=None):
# Assign train/val datasets
if stage == "fit" or stage is None:
mnist_full = MNIST(self.data_dir, train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
# Assign test dataset
if stage == "test" or stage is None:
self.mnist_test = MNIST(self.data_dir, train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=self.batch_size, num_workers=self.num_workers)
def val_dataloader(self):
return DataLoader(self.mnist_val, batch_size=self.batch_size, num_workers=self.num_workers)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.batch_size, num_workers=self.num_workers)
# Detective: fake or no fake -> 1 output [0, 1]
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
# Simple CNN
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 1)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
# Flatten the tensor so it can be fed into the FC layers
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return torch.sigmoid(x)
# Generate Fake Data: output like real data [1, 28, 28] and values -1, 1
class Generator(nn.Module):
def __init__(self, latent_dim):
super().__init__()
self.lin1 = nn.Linear(latent_dim, 7*7*64) # [n, 256, 7, 7]
self.ct1 = nn.ConvTranspose2d(64, 32, 4, stride=2) # [n, 64, 16, 16]
self.ct2 = nn.ConvTranspose2d(32, 16, 4, stride=2) # [n, 16, 34, 34]
self.conv = nn.Conv2d(16, 1, kernel_size=7) # [n, 1, 28, 28]
def forward(self, x):
# Pass latent space input into linear layer and reshape
x = self.lin1(x)
x = F.relu(x)
x = x.view(-1, 64, 7, 7) #256
# Upsample (transposed conv) 16x16 (64 feature maps)
x = self.ct1(x)
x = F.relu(x)
# Upsample to 34x34 (16 feature maps)
x = self.ct2(x)
x = F.relu(x)
# Convolution to 28x28 (1 feature map)
return self.conv(x)
# GAN
class GAN(pl.LightningModule):
def __init__(self, latent_dim=100, lr=0.0002):
super().__init__()
self.save_hyperparameters()
self.generator = Generator(latent_dim=self.hparams.latent_dim)
self.discriminator = Discriminator()
#random noise
self.validation_z = torch.randn(6, self.hparams.latent_dim)
def forward(self, z):
return self.generator(z)
def adversarial_loss(self, y_hat, y):
return F.binary_cross_entropy(y_hat, y)
def training_step(self, batch, batch_idx, optimizer_idx):
real_imgs, _ = batch
# sample noise
z = torch.randn(real_imgs.shape[0], self.hparams.latent_dim)
z = z.type_as(real_imgs)
# train generator : max_log(D(G(z)))
if optimizer_idx == 0:
fake_imgs = self(z)
y_hat = self.discriminator(fake_imgs)
y = torch.ones(real_imgs.size(0), 1)
y = y.type_as(real_imgs)
g_loss = self.adversarial_loss(y_hat, y)
log_dict = {"g_loss" : g_loss}
return {"loss": g_loss, "progress_bar": log_dict, "log": log_dict}
# train discriminator : max_log(D(x)) + log(1 - D(G(z)))
if optimizer_idx == 1:
# how well can it label as real
y_hat_real = self.discriminator(real_imgs)
y_real = torch.ones(real_imgs.size(0), 1)
y_real = y_real.type_as(real_imgs)
real_loss = self.adversarial_loss(y_hat_real, y_real)
# how well can it label as fake
y_hat_fake = self.discriminator(self(z).detach())
y_fake = torch.zeros(real_imgs.size(0), 1)
y_fake = y_fake.type_as(real_imgs)
fake_loss = self.adversarial_loss(y_hat_fake, y_fake)
d_loss = (real_loss + fake_loss) / 2
log_dict = {"d_loss" : d_loss}
return {"loss": d_loss, "progress_bar": log_dict, "log": log_dict}
def configure_optimizers(self):
lr = self.hparams.lr
opt_g = torch.optim.Adam(self.generator.parameters(), lr=lr)
opt_d = torch.optim.Adam(self.discriminator.parameters(), lr=lr)
return [opt_g, opt_d], []
def plot_imgs(self):
z = self.validation_z.type_as(self.generator.lin1.weight)
sample_imgs = self(z).cpu()
print('epoch', self.current_epoch)
fig = plt.figure()
for i in range(sample_imgs.size(0)):
plt.subplot(2, 3, i+1)
plt.tight_layout()
plt.imshow(sample_imgs.detach()[i, 0, :, :], cmap='gray', interpolation='none')
plt.title("Generated Data")
plt.xticks([])
plt.yticks([])
plt.axis('off')
plt.show()
def on_epoch_end(self):
self.plot_imgs()
dm = MNISTDataModule()
model = GAN()
GAN PyTorch로 구현 - (1) 환경 설정 및 데이터 준비
import os
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, random_split
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt
import pytorch_lightning as pl
random_seed = 42
torch.manual_seed(random_seed)
BATCH_SIZE=128
AVAIL_GPUS = min(1, torch.cuda.device_count())
NUM_WORKERS=int(os.cpu_count() / 2)- 필요 라이브러리 import
- 랜덤 시드, 배치 크기 설정
- 사용할 GPU 수와 데이터 로딩에 사용할 CPU 워커 수 설정
GAN PyTorch로 구현 - (2) MNIST 데이터 모듈 정의
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, data_dir="./data", batch_size=BATCH_SIZE, num_workers=NUM_WORKERS):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
self.num_workers = num_workers
self.transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
]
)
def prepare_data(self):
MNIST(self.data_dir, train=True, download=True)
MNIST(self.data_dir, train=False, download=True)
def setup(self, stage=None):
if stage == "fit" or stage is None:
mnist_full = MNIST(self.data_dir, train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
if stage == "test" or stage is None:
self.mnist_test = MNIST(self.data_dir, train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=self.batch_size, num_workers=self.num_workers)
def val_dataloader(self):
return DataLoader(self.mnist_val, batch_size=self.batch_size, num_workers=self.num_workers)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.batch_size, num_workers=self.num_workers)- PyTorch Lightning의 LightningDataModule 사용
- MNIST 데이터 셋 다운로드 및 훈련, 검증, 테스트 데이터셋 준비
GAN PyTorch로 구현 - (3) 생성 모델(Generator) 정의
class Generator(nn.Module):
def __init__(self, latent_dim):
super().__init__()
self.lin1 = nn.Linear(latent_dim, 7*7*64)
self.ct1 = nn.ConvTranspose2d(64, 32, 4, stride=2)
self.ct2 = nn.ConvTranspose2d(32, 16, 4, stride=2)
self.conv = nn.Conv2d(16, 1, kernel_size=7)
def forward(self, x):
x = self.lin1(x)
x = F.relu(x)
x = x.view(-1, 64, 7, 7)
x = self.ct1(x)
x = F.relu(x)
x = self.ct2(x)
x = F.relu(x)
return self.conv(x)- 생성모델(G)은 랜덤 노이즈(latent vector)를 입력받아 이미지를 생성
- 선형 변환과 upsampling을 사용하여 이미지 생성
GAN PyTorch로 구현 - (4) 판별 모델(Discriminator) 정의
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 1)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return torch.sigmoid(x)- 판별모델(D)은 입력 이미지가 진짜인지 가짜인지 판단
- 여러 층의 convolution과 pooling, dropout을 사용하여 이미지 분류
- 최종 출력은 sigmoid 함수를 통해 0과 1사이의 값으로 변환
GAN PyTorch로 구현 - (5) GAN 모델 정의
class GAN(pl.LightningModule):
def __init__(self, latent_dim=100, lr=0.0002):
super().__init__()
self.save_hyperparameters()
self.generator = Generator(latent_dim=self.hparams.latent_dim)
self.discriminator = Discriminator()
self.validation_z = torch.randn(6, self.hparams.latent_dim)
def forward(self, z):
return self.generator(z)
def adversarial_loss(self, y_hat, y):
return F.binary_cross_entropy(y_hat, y)
def training_step(self, batch, batch_idx, optimizer_idx):
real_imgs, _ = batch
z = torch.randn(real_imgs.shape[0], self.hparams.latent_dim)
z = z.type_as(real_imgs)
if optimizer_idx == 0:
fake_imgs = self(z)
y_hat = self.discriminator(fake_imgs)
y = torch.ones(real_imgs.size(0), 1)
y = y.type_as(real_imgs)
g_loss = self.adversarial_loss(y_hat, y)
log_dict = {"g_loss": g_loss}
return {"loss": g_loss, "progress_bar": log_dict, "log": log_dict}
if optimizer_idx == 1:
y_hat_real = self.discriminator(real_imgs)
y_real = torch.ones(real_imgs.size(0), 1)
y_real = y_real.type_as(real_imgs)
real_loss = self.adversarial_loss(y_hat_real, y_real)
y_hat_fake = self.discriminator(self(z).detach())
y_fake = torch.zeros(real_imgs.size(0), 1)
y_fake = y_fake.type_as(real_imgs)
fake_loss = self.adversarial_loss(y_hat_fake, y_fake)
d_loss = (real_loss + fake_loss) / 2
log_dict = {"d_loss": d_loss}
return {"loss": d_loss, "progress_bar": log_dict, "log": log_dict}
def configure_optimizers(self):
lr = self.hparams.lr
opt_g = torch.optim.Adam(self.generator.parameters(), lr=lr)
opt_d = torch.optim.Adam(self.discriminator.parameters(), lr=lr)
return [opt_g, opt_d], []
def plot_imgs(self):
z = self.validation_z.type_as(self.generator.lin1.weight)
sample_imgs = self(z).cpu()
print('epoch', self.current_epoch)
fig = plt.figure()
for i in range(sample_imgs.size(0)):
plt.subplot(2, 3, i+1)
plt.tight_layout()
plt.imshow(sample_imgs.detach()[i, 0, :, :], cmap='gray', interpolation='none')
plt.title("Generated Data")
plt.xticks([])
plt.yticks([])
plt.axis('off')
plt.show()
def on_epoch_end(self):
self.plot_imgs()- Generator와 Discriminator를 포함
- 훈련 과정과 손실 함수 정의
optimizer_idx == 0일때는 Generator,optimizer_idx == 1일때는 Discriminator 학습
Generator 학습
생성된 가짜 이미지를 진짜 이미지로 분류하게 만드는 것이 목표로 Discriminator가 가짜 이미지를 진짜 이미지로 분류할 확률을 최대화하도록 학습
-
노이즈 샘플링
-z = torch.randn(real_imgs.shape[0],self.hparams.latent_dim) z = z.type_as(real_imgs) -
가짜 이미지 생성 :
fake_imgs = self(z) -
생성된 가짜 이미지를 Discriminator에 입력하여 진짜 이미지로 분류할 확률 y_hat을 얻음 :
y_hat = self.discriminator(fake_imgs) -
Discriminator가 가짜 이미지를 진짜 이미지로 분류하도록 진짜 라벨 y를 생성 :
y = torch.ones(real_imgs.size(0), 1),y = y.type_as(real_imgs) -
진짜 라벨과 Discriminator의 출력 간의 이진 교차 엔트로피 손실 계산(Generator 손실 계산) :
g_loss = self.adversarial_loss(y_hat, y)
Discriminator 학습
진짜 이미지를 진짜로, 가짜 이미지를 가짜로 분류할 확률을 최대화하도록 학습
y_hat_real = self.discriminator(real_imgs): 진짜 이미지를 Discriminator에 입력하여 진짜로 분류할 확률 y_hat_real을 얻음y_real = torch.ones(real_imgs.size(0), 1),y_real = y_real.type_as(real_imgs): 진짜 이미지를 진짜로 분류하도록 하기 위한 진짜 라벨 y_real 생성real_loss = self.adversarial_loss(y_hat_real, y_real): 진짜 라벨과 Discriminator의 출력 간의 이진 교차 엔트로피 손실 계산y_hat_fake = self.discriminator(self(z).detach()): Generator를 통해 생성된 가짜 이미지를 Discriminator가 가짜로 분류할 확률 y_hat_fake를 구함. 이때detach()를 사용하여 Generator의 역전파 차단y_fake = torch.zeros(real_imgs.size(0), 1),y_fake = y_fake.type_as(real_imgs): 가짜 라벨 y_fake 생성fake_loss = self.adversarial_loss(y_hat_fake, y_fake): 가짜 라벨과 Discriminator의 출력 간 이진 교차 엔트로피 손실을 계산하여 가짜 이미지 손실 y_fake 구함d_loss = (real_loss + fake_loss) / 2: Discriminator 손실 계산

올 때 메로나🍧