01장: 인공지능과 머신러닝, 딥러닝
01-1 인공지능 개요
인공지능(Artificial Intelligence)
- 사람처럼 학습, 추론 가능한 시스템을 만드는 기술
인공지능 역사
- 1943: 워런 매컬러 & 월터 피츠 → 뉴런 모델 발표
- 1950: 앨런 튜링 → 튜링 테스트 제안
- 1957: 프랑크 로젠블라트 → 퍼셉트론 개발 (초기 신경망 모델)
인공지능 분류
- 약인공지능: 특정 업무 보조 (현실 적용)
- 강인공지능: 인간 수준의 사고 가능 (아직 실현 불가)
머신러닝
- 데이터를 이용해 자동으로 규칙을 학습하는 알고리즘 분야
- 대표 라이브러리: 사이킷런(Scikit-learn)
딥러닝
- 머신러닝의 하위 개념
- 인공신경망 기반의 학습 방법
- 프레임워크: TensorFlow (구글, 2015) / PyTorch (페이스북, 2018)
01-2 구글 코랩과 주피터 노트북
구글 코랩
- 웹 기반 파이썬 실행 환경
- 노트북 파일 형태로 텍스트 + 코드 작성 가능
- 코랩은 Jupyter Notebook 기반으로 구글이 제공하는 클라우드 에디터
주요 개념
- 셀(Cell): 코드 실행의 최소 단위
- 구글 드라이브: 저장 및 연동 가능
01-3 마켓 예제로 배우는 머신러닝 기초
용어 정리
- 특성(feature): 데이터의 속성 (예: 무게, 길이)
- 훈련(training): 규칙을 데이터로부터 학습
- 모델(model): 학습된 결과 객체
- 정확도(accuracy): 정답 예측 비율 → 사이킷런에서는
0~1사이로 반환
주요 도구
-
Matplotlib: 시각화 도구,
scatter()함수로 산점도 출력 -
Scikit-learn
KNeighborsClassifier(): k-최근접 이웃 분류 모델fit(): 학습predict(): 예측score(): 정확도 측정
02장: 데이터 다루기
02-1 훈련 세트와 테스트 세트
지도학습 vs 비지도학습
- 지도학습: 입력 + 정답 데이터 학습
- 비지도학습: 정답 없이 패턴 찾기
데이터 구조
- 입력 데이터 (데이터) = 특성
- 정답 (타깃) = 라벨
- 샘플: 하나의 데이터 행
- 데이터 세트 = 전체 데이터
- 훈련 세트 / 테스트 세트: 학습용 / 검증용 데이터 분리
배열 관련
- 넘파이(Numpy): 배열 연산 라이브러리
.shape: (샘플 수, 특성 수) 확인seed(): 난수 고정arange(): 일정 간격 배열 생성shuffle(): 배열 무작위 섞기
슬라이싱 vs 인덱싱
- 슬라이싱:
start:stop범위 선택 (stop 미포함) - 인덱싱: 여러 위치를 직접 선택
주의
fit()실행 시 모델은 이전 학습 결과를 잃음 (재훈련 필요)
02-2 데이터 전처리
튜플
- 리스트와 비슷하나 불변(immutable)
train_test_split()
- 데이터를 비율로 훈련/테스트 세트 분리
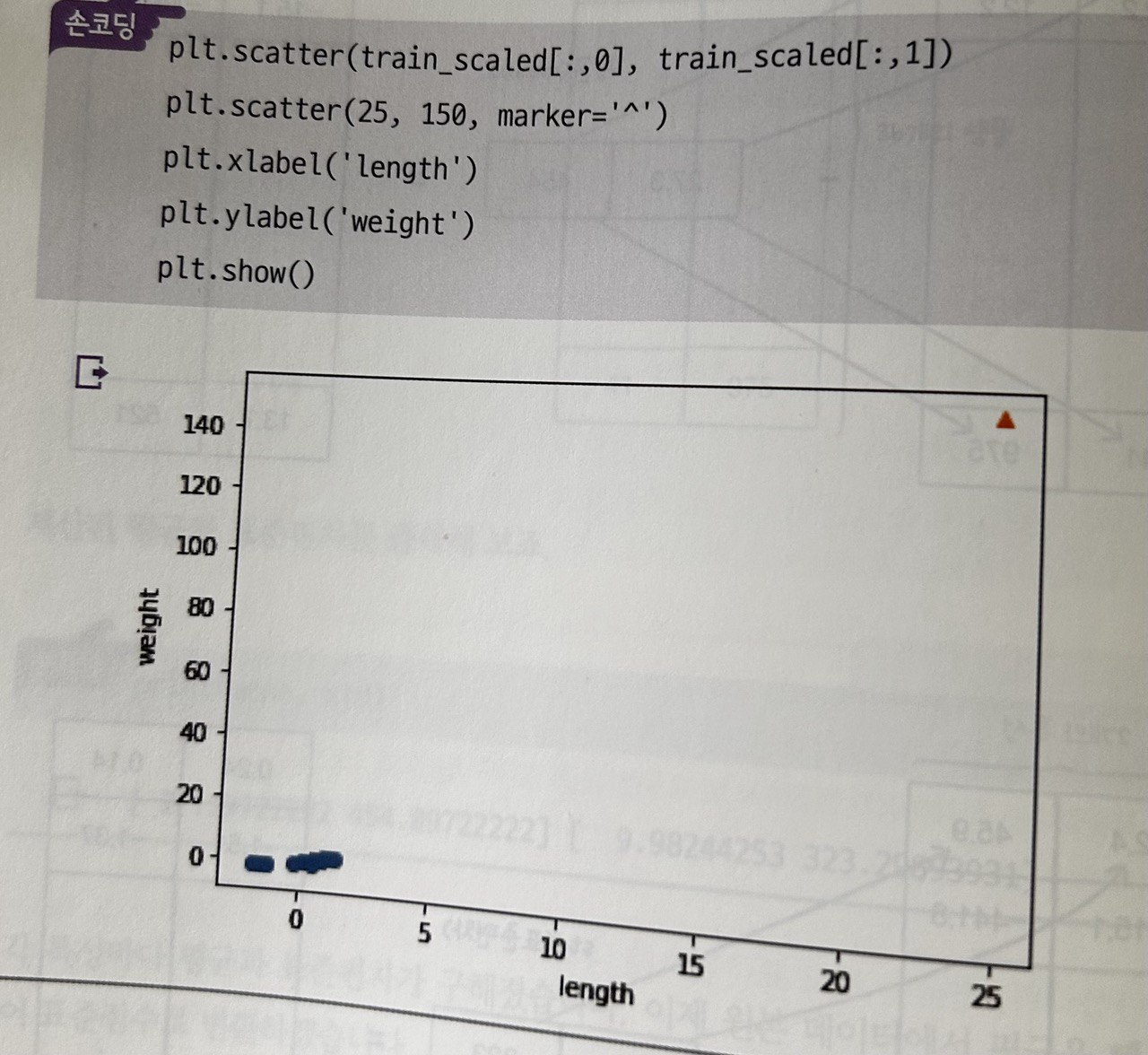
전처리 필요성
-
샘플 간 거리 기반 알고리즘에서는 값의 단위 차이가 영향 큼
-
표준화(standardization): 값의 범위를 평균 0, 표준편차 1로 조정
np.mean(): 평균np.std(): 표준편차- 브로드캐스팅을 활용해 전체 데이터 정규화 가능
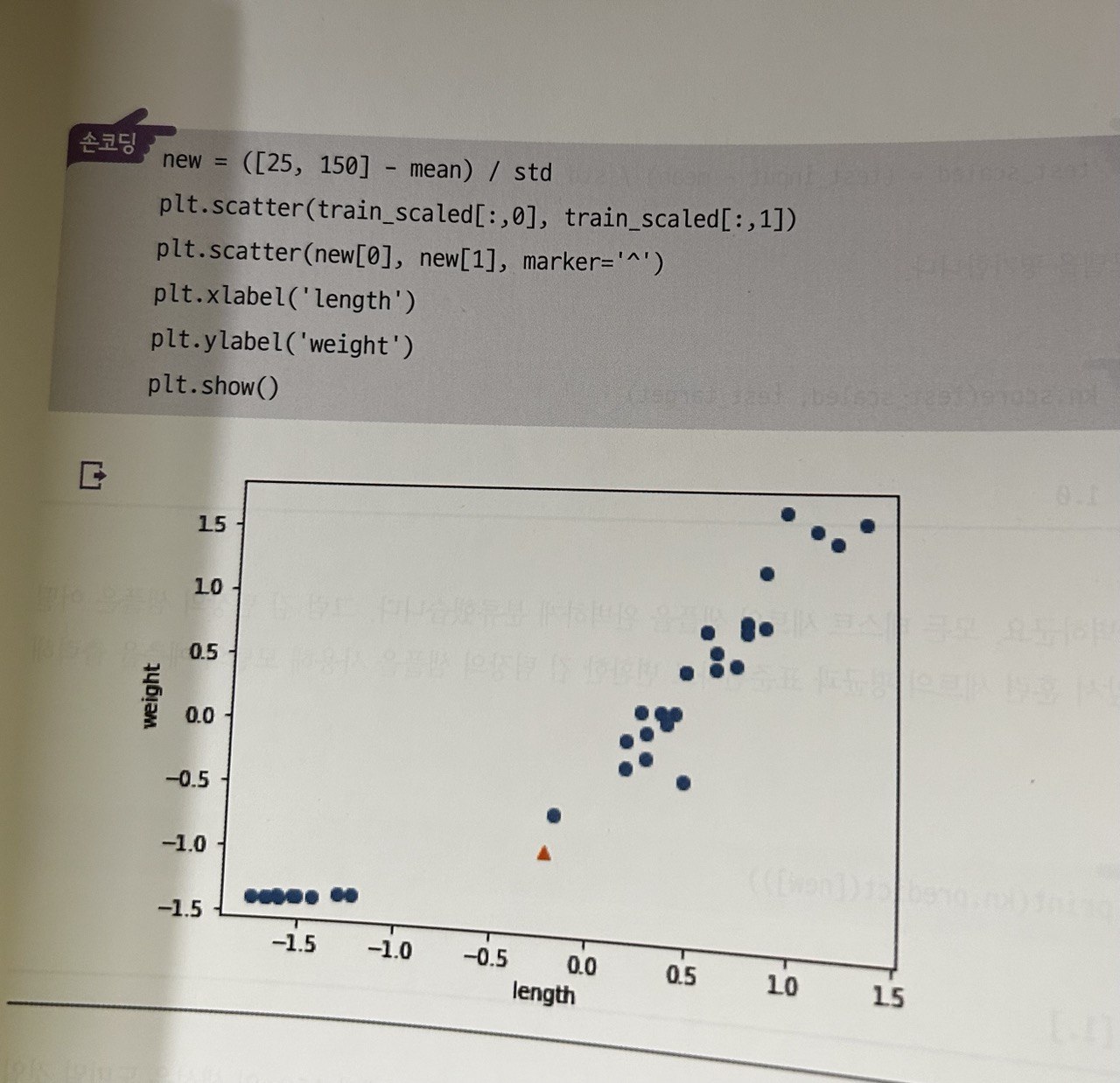
전처리 후 훈련
- 전처리된 입력값으로 모델을
fit()하여 학습해야 정확도 향상 가능
전처리 데이터로 모델 훈련하기