기존의 문제점
- 데이터를 HDFS(Hadoop File System)에 넣었다 뺐다 하니까 느리다.
대체방법 고안
- 다시말해 처음부터 읽어오지 말고 RAM에 올려놓고 쿼리쿼리쿼리~
-> 하지만 RAM에 올려놓으면 또 에러나거나 컴퓨터가 꺼지면 소실되잖아..
대체방법 고안 2
- RAM에 READ-ONLY로 입력해 놓자!
-> 이것이 RDD
- 어떻게 만들어졌는지 계보(lineage)를 기록
- DAG(Directed acyclic graph)의 형태를 띰
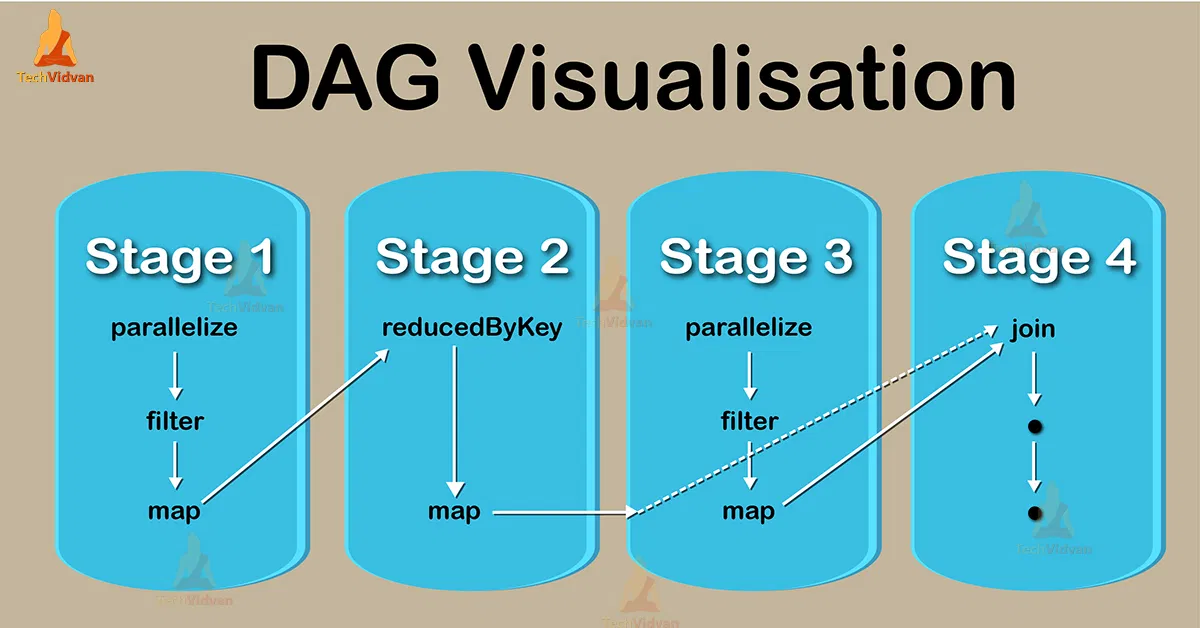
[https://techvidvan.com/tutorials/apache-spark-dag-directed-acyclic-graph/]
그렇게 transformation & action 하게 됨
lazy execution으로 계산 최적화

romantic ai developer