문서 분류
-
문서 내 정보를 바탕으로 문서의 라벨을 예측하는 작업
-
"텍스트를 정형돠된 데이터로 변환하여(전처리),
의미 있는 정보를 얻어내는 기법(머신러닝)"
베이즈 정리 꼭 알아두기!
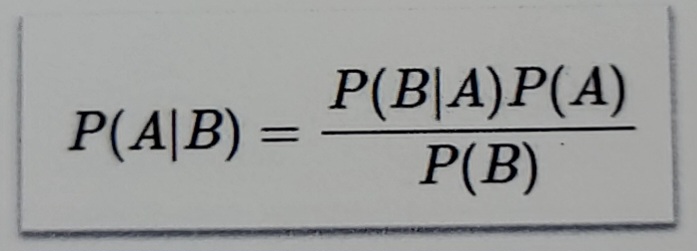
나이브 베이즈 분류기
-
나이브 = 간단한 / 베이즈 = 사람이름
-
베이즈 정리를 이용하여 텍스트 분류를 하는 방법론
-
확률과 통계기반 분류 모델
-
조건부 확률을 계산하는 방식으로
A B에 대한 확률을 계산할 수 있다면
B에 대한 A의 확률을 쉽게 계산할 수 있다는 정리
P(A) -> A가 일어날 확률
P(B) -> B가 일어날 확률
동전 던졌을 때 앞이 나올 확률 : A = 1/2
주사위를 던졌을 때 6이 나올 확률 : B = 1/6
P(A and B)(교집합) -> A와 B가 동시에 일어날 확률 : 1/12
=> A와 B가 상관이 없다면 (독립적이라면) P(A) x P(B)
P(A | B)(조건부확률) -> B가 발생했을 때 A의 확률 = 1/2
P(A and B) = P(A) * P(B | A)(시간차) => 1/12
= P(B) x P(A | B) => P(A) x P(B|A) = P(B) x P(A|B)
=> P(A|B) = P(A) x P(B|A) / P(B) = 베이즈 룰, 규칙
P(Y|X) = [P(X|Y) * P(Y)] / P(X)P-value 란?
-
어떤 결과가 우연히 발생한 것이 아니라
실제로 효과나 관련성이 있는지를 판단하는데 사용 -
주어진 가설 검정에서 얻은 결과가
영 가설을 기각할만큼
근거가 충분한지를 나타내는 것
(영 가설 = 연구자가 어떤 변화나 효과를 기대하지 않고 초기 가적으로 세우는 가설) -
p-value가 0.05 또는 0.01 미만인 경우,
일반적으로 "유의하다(significant)"고 간주
토픽 모델링
-
데이터로부터 원인을 추론하는 사후 분석
-
덱스트 데이터에서 주제(topic) 구조를 발견하고
추출하기 위한 통계적 모델링 기법
토픽(Topic) 이란?
- 관련된 단어들의 집합..
토픽을 추출하기 위해 해야하는 것
-
- 관련된 단어들을 묶어내는 것
-
- 단어의 집합으로부터 토픽을 정밀하게 표현하는 것
LSA(잠재 의미 분석) 이란?
-
DTM(단어의 카운트)를 차원 축소 하여 축소 차원에서 근접 단어들을 토픽으로 묶는 방법론
-
즉, 차원을 축소해 단어들의 잠재적이 의미를 추출하는 방법론
-
행렬기반 차원축소 방법 중 하나인
Truncated SVD를 사용한다 -
Truncated(절단된)라는 말은 기존 데이터의
차원을 줄이는 작업을 의미 -
차원이 줄어든다는 것은 정보를 압축하면서 상대적으로 중요하지 않은 노이즈 정보를
삭제시키고 핵심 정보만 남긴다는 의미 -
LSA(SVD)는 내가 줄이고 싶은 차원을
지정 할 수 있다 -
이 줄이려는 차원의 숫자 t를 토픽이라고
정의하는 것 -
T가 너무 크면 노이즈가 많이 포함되어
핵심 내용을 알 수 없고
T가 너무 작으면 중요한 정보까지 손실 될 수 있다PCA = 분해, 분산
SVD = 중요도, 기여도
-
SVD(Singular Value Decomposition)은
선형 대수학에서 사용되는 중요한 행렬 분해 기술 중 하나 이다LDA = 잠재 디리클레 할당
-
Latent Dirichlet Allocation
-
하나의 문서 안에 여러 토픽이 혼합되어져 있으며,
토픽은 확률 분포에 기반한 단어들의 집합으로 구성되어 있다고 가정 -
LDA는 가장 대표적인 토픽 모델링 방법론 중 하나
-
문장의 생성 원리를 고려한 방법
-
모든 문서는 작성되기 전에 다양한 의도(topic)를 갖고 있고, 그 의도를 표현하기 위해 적합한 단어들이 확률적으로 선택되어 문서가 작성된다는 생각을 한다.
-
문서는 이러한 과정 끝에 나타난 보여지는 결과물이고 이를 역추적하는 방식으로 토픽을 분석하는 방법론
텍스트 요약은 크게 2가지
추출적 요약(extractive summarization)
-
추출적 요약은 원본 문서 내에 있는 정보(문장, 단어)들 중 중요한 정보를 추출하여 요약하는 방식
-
추출적 요약 방식으로 만들어낸 결과물은 원본 문서의 있는 정보들로 이루어져 있다
-
요양문의 표현이 원본 문서의 제한을 받는다는 한계가 있음
-
주요 모델로는 머신러닝 방식의 TextRank, LexRank등이 있다
추상적 요약(abstractive summarization)
-
추상적 요약은 원본 문서의 핵심 문맥을 반영하는 새로운 문장을 생성하여 요약문을 만들어내는 방식이다
-
지도학습 방식으로서, 원본 문서 데이터와 함께 원본에 대한 요약문 데이터셋을 함께 구축하여 학습시켜야 하는 커다란 제약이 있다
-
주요 모델로는 seq2seq 모델 기반의 모델들이 있다
TextRank
-
텍스트 내 문장, 단어의 중요도를 계산하여 중요도가 높은 순으로 요약하는 방법론
-
TextRank는 웹 상에서의 문서의 중요도를 계산하는
구글의 PageRank를 텍스트에 적용한 알고리즘 -
PageRank는 어떤 문서가 다른 문서에 인용이 많이 될수록
중요도가 커지도록 계산하는 방식이다 -
웹 페이지 대신 노드들을 문장, 단어로 대체하여 문서 내의 문장, 단어의 중요도를 계산한다
Damping Factor
-
'어떤 마구잡이로 웹서핑을 하는 사람이 그 페이지에 만족을 못하고
다른 페이지로 가는 링크르 클릭할 확률' -
0.85면 85%확률로 다른 페이지를 클릭해볼 것이라는 뜻
