CPU Architecture and Program Execution
임베디드시스템설계

임베디드 시스템의 구조
하드웨어(프로세서, 메모리, peripheral)와 소프트웨어(OS, 시스템 소프트웨어, application)의 결합
CPU/Processor의 구조
- Control and Timing Section : CPU가 instruction을 제대로 call할 수 있도록 도와준다
- Register Section : general purpose register와 special register로 이루어져 있다. general purpose register에 일반적인 연산 결과 등을 저장하고 special register은
eip나 stack pointer등이 있다. - ALU : computational, logical, arithmetic instruction을 수행하고 그 결과에 따라 memory component를 요구하기도 한다.
Processor Architecture
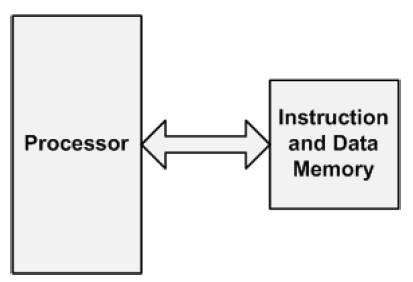
Von-Neumann
instruction 과 data가 같은 memory에 저장된다. 더 simple하기 때문에 생산 비용이 낮다.
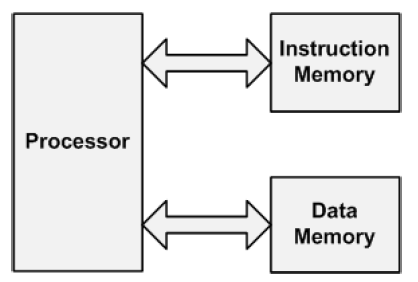
Havard
instruction과 data가 분리된 memory에 저장된다. system performance가 향상되고 두 메모리가 따로 연결되어 있기 때문에 instruction과 data를 동시에 fetch할 수 있다.
Instruction Execution Process
Instruction fetch -> Instruction interpretation -> Sequencing -> Execution
special register인 instruction register(IR)로 instruction을 읽어온다. instruction은 memory에 존재하고 PC레지스터가 next instruction의 주소를 가지고 있다.
CPU가 IR 주소의 instruction을 fetch하고 그 instruction의 meaning을 이해한다(decode).
프로그램은 여러 instruction의 sequence이기 대문에 instruction을 하나씩 이해하고 PC값을 증가시키면서 sequentially하게 프로그램을 실행한다.
실행에 필요한 ALU의 control signal 값을 바꿔준다.
System Organization
Memory-mapped I/O
memory와 I/O가 same address space를 사용한다.
address를 보면 그 address의 범위를 보고 어디에 접근하는지(target이 memory인지 I/O인지) 판별할 수 있다.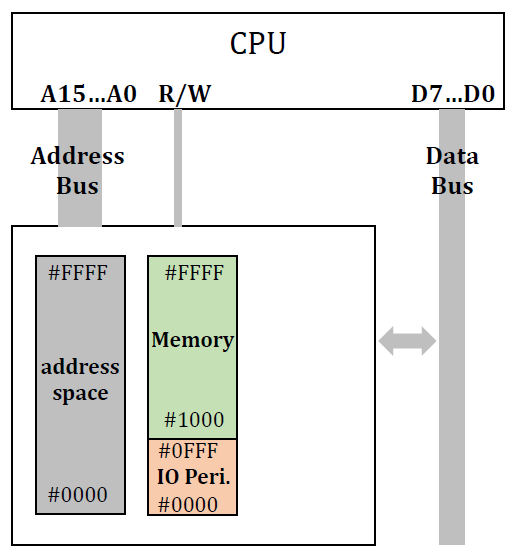 예를 들면
예를 들면 0FFF라는 주소에 접근을 하게 되면 0FFF는 I/O peripheral영역이므로 I/O를 target으로 함을 알 수 있다.
Port-mapped I/O
I/O와 memory가 다른 address space를 사용한다. 따라서 address만으로는 target이 무엇인지 알 수 없다.
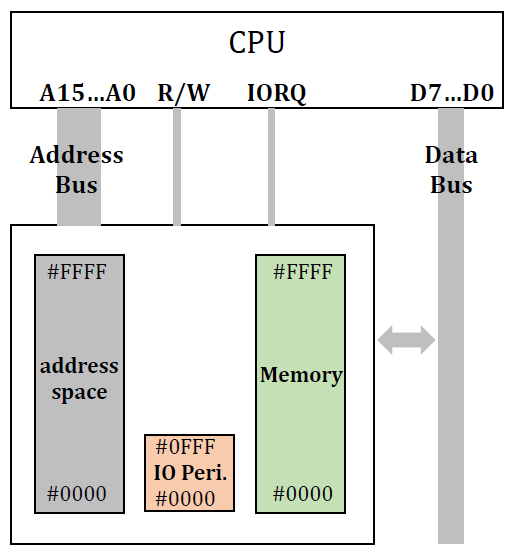 예를 들면
예를 들면 0FFF라는 address에 접근할 때 I/O peripheral의 address space와 memory에 모두 0FFF가 존재하기 때문에 둘 중 어느 곳의 0FFF인지 그냥은 알 수 없다.
따라서 target이 무엇인지 판별하기 위해 추가적인 신호가 필요하고, 그것이 IORQ이다.
IORQ는 I/O request를 의미하며 0이면 memory에 접근하는 것이고 이면 I/O에 접근하는 것이다.
Processor Operation Modes
User mode
unpreviledge mode이다.
user program이 실행되는 mode이다. 특별한 instruction은 실행할 수 없고, 중요한 메모리 영역에도 접근할 수 없다.
Supervisor mode
previledge mode이다.
OS나 시스템 소프트웨어가 사용되는 모드로, 민감하거나 security한 instruction도 사용할 수 있고 모든 메모리 영역에 접근할 수 있다.
PSW
프로세서는 PSW-bit을 통해 두 모드를 구분할 수 있다.
예를 들면, PSW-bit이 1이면 supervisor mode이다.
Interrupts
Polling
event가 발생했을 때 flag등을 올리는 방식이다. 프로그램이 계속해서 레지스터와 device를 check해야하기 때문에 비효율적이다.
따라서 polling의 대안이 interrupt이다.
Interrupt
dedicated hardware가 CPU와 디바이스를 사용해 interrupt signal을 hardware line을 통해 CPU에게 전달한다.
프로그램은 레지스터와 device상태를 check할 필요가 없어진다. 하드웨어가 interrupt가 발생했을 때 그 사실을 프로그램에게 알려주기 때문이다.
interrupt는 프로그램이 interrupt-handling subroutine을 call하도록 강제한다.
interrupt는 외부의 event에 더 빨리 응답할 수 있기 때문에 real-time programming에 적절하다.
하지만 때로는 polling이 interrupt보다 빠를 수도 있다.
이벤드가 엄청 많이 발생하는 경우(예를 들면 네트워크 패킷이 엄청 도착한다던가)에는 interrupt보다 polling이 빠를 수 있다.
Interrupt handler
interrupt handler는 special code이다.
interrupt가 발생하면 CPU가 interrupt를 확인하고 instruction의 실행을 중단한 뒤 interrupt handler를 call해서 interrupt를 프로세싱한다. handle이 끝나면 interrupt되었던 프로그램의 context를 restore해서 실행을 재개한다.
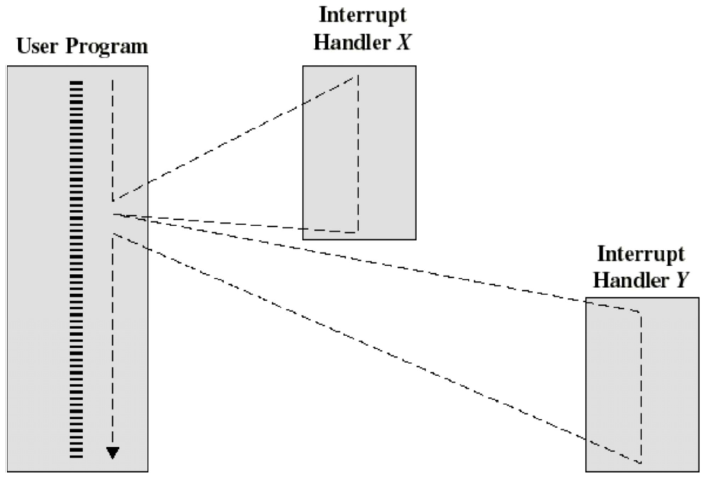
Multiple interrupts
Sequential Order
X를 handling하는 동안에는 interrupt가 disable돼서 다른 interrupt를 받을 수 없다. 따라서 그 시간 동안의 interrupt가 pending되고 X의 handling이 끝나면 interrupt가 enable된다. interrupt가 enable되면 pended interrupt가 순차적으로 handle되기 시작한다.
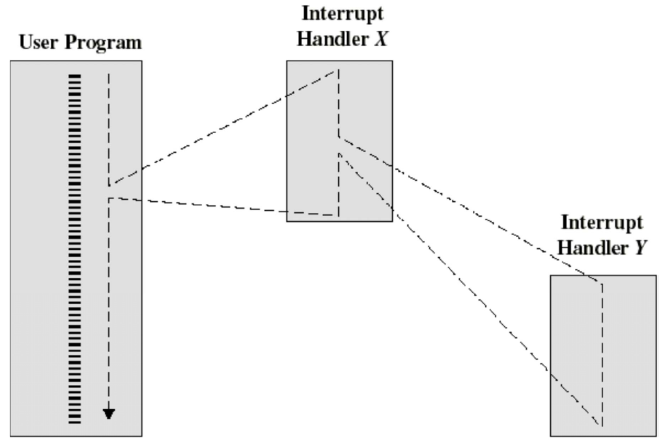
Nested
X가 handle되고 있는 도중 Y가 발생하면 Y를 handle할 수 있다. Y의 실행이 끝나면 다시 X로 돌아온다.
모든 interrupt가 nested되는 것은 아니고 나중에 발생한 interrupt의 priority가 현재 handling되고 있는 interrupt의 priority보다 높으면 nested된다(interrpt handler가 interrupt됨).
만약 나중에 발생한 interrupt의 priority가 낮으면 interrupt가 pending되어 순차적으로 실행된다.
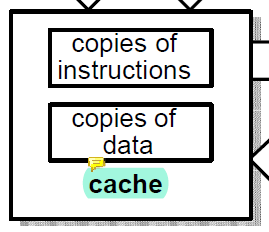
Cache Memory
cache는 비싸지만 레지스터만큼 빠르다.
target address를 cache에서 찾지 못하면 memory access를 하고 그 결과를 cache에 저장한다. 그럼 같은 address에 접근하는 다른 access는 cache를 통해 빠른 속도로 access가 가능하다.
Unified Instruction and Data Cache
instruction과 data가 같은 cache에 저장된다.
Separate Data and Instruction Caches
instruction과 data가 서로 다른 cache에 저장된다.
프로세서가 instruction과 data를 동시에 cache로부터 fetch할 수 있다.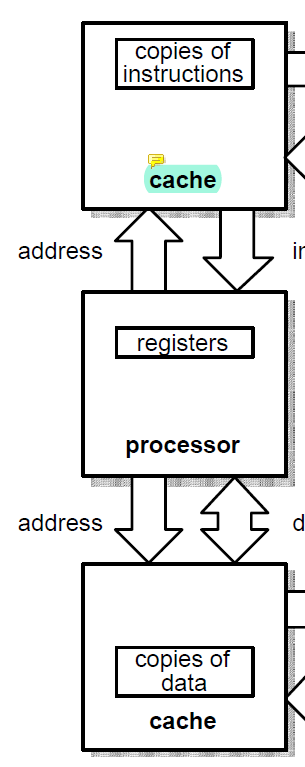
L1 cache는 unified형태이거나 separate형태를 가지고 있는데 L2, L3 cache는 대부분 unified 형태이다. 비용문제..
CPU Pipelining
instruction의 throughput을 높여서 performance를 증가시키는 테크닉이다.
Pipelining allows hardware resources to be fully utilized
Pipelining을 쉽게 해주는 것
시스템이 simple, regular instruction form을 가진 경우 pipelining이 쉽다.
Pipelining을 어렵게 하는 것
Structural Hazards
hardware resource에 접근하는 경우이다. CPU가 memory access를 한다던가... pipelining을 하려면 instruction이 실행될 때 fetch도 같이 되어야 하는데 CPU가 memory access를 위해 memory를 사용하면 다음 instruction을 fetch할 수 없게 된다.
Data Hazards
instruction의 dependency로 인한 것이다. 앞의 instruction이 실행될 때까지 기다려야 한다.
Control Hazards
CPU가 control flow를 바꿀 때 발생한다. conditional branch같은 것이 해당된다. condition이 check될 때까지 next instruction을 fetch하지 못하고 기다려야 한다.
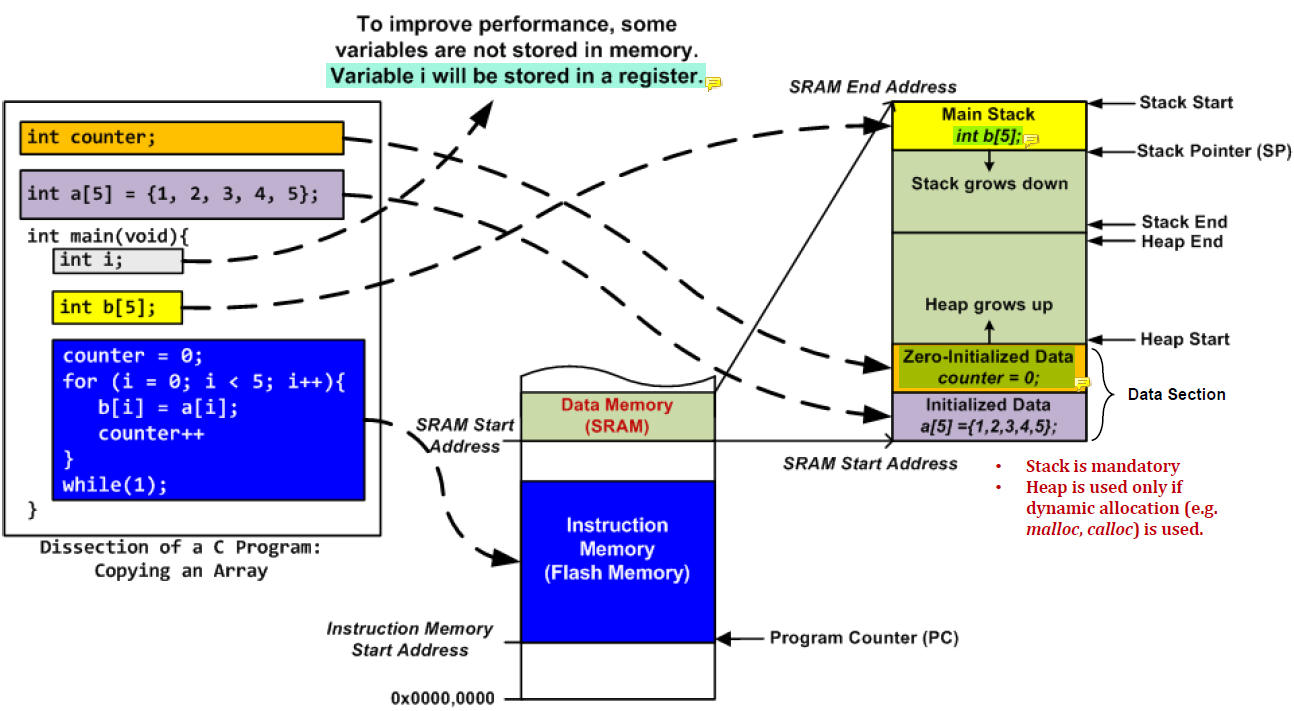
Loading Code and Data into Memory
Data memory는 SRAM에 존재하고 Instruction Memory는 Flash memory이다.
1 int counter;
2 int a[5] = {1, 2, 3, 4, 5};
3
4 int main() {
5 int i;
6 int b[5];
7
8 counter = 0;
9 for (i = 0; i < 5; i++) {
10 b[i] = a[i];
11 counter++;
12 }
13 while(1);
14 }1의 counter은 uninitialized variable이다.
data memory의 zero-initialized data 영역에 저장된다.
2의 a는 initialized variable이다.
data memory의 initialized data 영역에 저장된다.
5의 i와 6의 b는 local variable이다.
i는 매우 simple하기 때문에 레지스터에 저장된다.
b는 레지스터에 저장하기엔 크기 때문에 data memory의 stack에 저장된다.
8~13은 code area이다.
instruction memory에 저장된다.