
4장 : 신경망 시작하기 - 분류와 회귀
영화 리뷰 분류 : 이진 분류 문제
Dense 층을 쌓을 때 두가지 중요한 구조상의 결정이 필요하다.
- 얼마나 많은 층을 쌓을 것인가?
- 각 층에 얼마나 많은 유닛을 둘 것인가?
필자의 말에 따라서 현재는
- 16개의 유닛을 가진 2개의 중간층
- 현재 리뷰의 감정을 스칼라 값의 예측으로 출력
하는 구조를 따라 갈 것이다.
신경망을 만들고 훈련과 검증 정확도를 출력해보면,
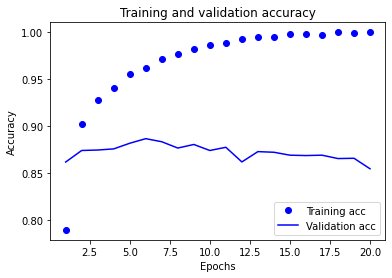
여기서 볼 수 있듯이 훈련 손실이 epoch 마다 감소하고 훈련 정확도는 epoch마다 증가한다. 하지만 검증 손실과 정확도는 네번째 epoch 에서부터 그래프가 역전 되는 것을 확인할 수 있다. overfitting된 것을 확인 할 수 있다.
이 과대적합을 방지하기 위해서 네번째 epoch 이후에 훈련을 중지할 수 있다.
이런 단순하게 그래프로 확인해보고 epoch만 바꾸는 것만으로도 정확도를 높일 수 있다 !
이 문제 학습을 통해서 알아야 할 것은
- 이진 분류에서 스칼라 시그모이드 출력에 대해 사용할 손실 함수는
binary_crossentropy이다.
2.rmsprop 옵티마이저는 문제에 상관없이 일반적으로 충분히 좋은 선택이다. - 훈련 데이터에 대해 성능이 향상됨에 따라 신경망은 과대적합되기 시작하고, 이전에 본 적 없는 데이터에서는 결과가 점점 나빠지게 된다. 항상 훈련 세트 이외의 데이터에서 성능을 모니터링해야한다.
뉴스 기사 분류 : 다중 분류 문제
로이터(Reuter) 뉴스를 46개의 상호 배타적인 토픽으로 분류하는 신경망을 만들어보자. 클래스가 많기 때문에 다중 분류(muliclass classification) 의 예이다. 포인트가 정확히 하나의 범주로 분류되기 때문에 정확하게 단일 레이블 다중 분류(single-label, multiclass classification) 문제이다.
신경망을 만들고 훈련과 검증의 정확도 값을 출력하면

다음과 같은 결과를 확인할 수 있는데, 이 모델은 9번째 epoch 이후에 과대적합이 시작되므로 여기서 멈추고 테스트 세트에서 평가를 진행하면 정확도가 올라가는 것을 확인할 수 있다.
이 문제 학습을 통해서 알아야 할 것은
- N개의 클래스로 데이터 포인트를 분류하려면 모델의 마지막 dense 층의 크기는 N이여야한다.
- 단일 레이블, 다중 분류 문제에서는 N개의 클래스에 대한 확률 분포를 출력하기 위해 softmax 활성화 함수를 사용해야한다.
- 이러한 문제에서는 항상 범주형 크로스엔트로피를 사용해야한다. 이것을 사용할 시, 모델이 출력한 확률 분포와 타깃 분포 사이의 거리를 최소화할 수 있다.
- 다중 분류에서 레이블을 다루는 두가지 방법은
- 레이블을 범주형 인코딩(one-hot encoding)(=원 핫 인코딩)으로 인코딩하고, categorial_crossentropy 손실 함수를 사용한다.
- 레이블을 정수로 인코딩하고 sparse_categorical_crossentropy 손실 함수를 사용한다.
- 많은 수의 범주를 분류할 때 중간층의 크기가 너무 작아 모델에 정보의 병목이 생기지 않도록 주의해야한다.
주택 가격 예측 : 회귀 문제
머신러닝 문제 중, 개별적인 레이블 대신에 연속적인 값을 예측하는 회귀(regression) 문제에 해당된다.
여기서 사용할 모델의 경우 마지막 층은 하나의 유닛을 가지고 있고 활성화 함수가 없다. (선형 층이라고 부른다) 이것이 전형적인 스칼라 회귀(하나의 연속적인 값을 예측하는 회귀) 를 위한 구성이다. 활성화 함수를 사용하면 출력 값의 범위를 제한하게 되는데, 이 모델에서 마지막 층이 순수한 선형이므로 모델이 어떤 범위 값이라도 예측하도록 자유롭게 학습한다.
회귀 문제에서 손실함수는 MSE(평균 제곱 오차)를 대부분 사용한다.
또한 K-겹 교차 검증(K-fold cross-validation) 을 사용한다.
데이터를 K개의 분할(fold)로 나누고 K개의 모델을 각각 만들어 K-1개의 분할에서 훈련하고 나머지 분할에서 평가하는 방법이다. 모델의 검증 점수는 K개의 검증 점수 평균이 된다.
이 문제 학습을 통해서 알아야 할 것은
- 회귀는 손실함수로써 MSE를 자주 사용한다.
- 회귀에서 사용되는 평가 지표는 분류와 다르다. 일반적인 회귀 지표는 평균 절대 오차(MAE)이다.
- 입력 데이터의 특성이 서로 다른 범위를 가지면 전처리 단계에서 각 특성을 개별적으로 스케일 조정해야한다.
4 가용한 데이터가 적다면 K-겹 검증을 사용하는 것이 신뢰할 수 있는 모델 평가 방법이다. - 가용한 훈련 데이터가 적다면 과대적합을 피하기 위해 중간층의 수를 줄인 작은 모델을 사용하는 것이 좋다.
이번 장에서 3가지 예제를 통해 신경망을 사용하여 분류와 회귀 문제에 어떻게 접근하는지 익숙해지면된다. (+ 과대적합도 다뤘다)
