
텍스트를 위한 딥러닝(제 2탄)
🗣️ 트랜스포머 아키텍처
도입부
2017년부터 새로운 모델 아키텍처인 트랜스포머(transformer)가 대부분의 자연어 처리 작업에 순환 신경망을 앞지르기 시작하였다. 트랜스포머는 순환층이나 합성곱 층을 사용하지 않고 '뉴럴 어텐션(neural attention)' 이라는 간단한 메커니즘을 사용하여 강력한 시퀀스 모델을 만들 수 있다.
뉴럴 어텐션은 빠르게 딥러닝에서 가장 영향력있는 아이디어 중 하나가 되었다. 효과적인 이유와 트랜스포머 아키텍처의 기본 구성 요소 중 하나인 셀프 어텐션을 사용해 트랜스포머 인코더를 만들어보자 !
셀프 어텐션 알아보기
셀프 어텐션이란 ? 모델이 어떤 특성에 조금 더 주의를 기울이고, 다른 특성에 조금 덜 주의를 기울이는 것. 중요도를 상대성에 따라서 두는 것이다.
셀프 어텐션의 목적은 시퀀스에 있는 관련된 토큰의 표현을 사용하여 한 토큰의 표현을 조절하는 것이다. 이는 문맥을 고려한 표현을 만든다.
스마트한 임베딩 공간이라면 주변 단어에 따라 단어의 벡터 표현이 달라져야한다. 여기에 셀프 어텐션이 사용된다. (예를 들어, 셀프 어텐션 : "station" 과 문장에 있는 다른 모든 단어 사이의 어텐션 점수를 계산한다. 그다음 이를 사용하여 단어 벡터에 가중치를 부여하여 새로운 "station" 벡터를 만든다. 첫 번째 , station벡터와 문장에 있는 다른 모든 단어 사이의 관련성 점수를 계산한다. 이것이 어텐션 점수이다. 두 번째 , 관련성 점수로 가중치를 두어 문장에 있는 모든 단어 벡터의 합을 계산한다. 이와 같은 과정을 문장에 있는 모든 단어에 대해 반복하여 문장을 인코딩하는 새로운 벡터 시퀀스를 만든다.)
일반화된 셀프 어텐션 : 쿼리-키-값 모델
지금까지 하나의 입력 시퀀스만 고려하였다. 하지만 트랜스포머 아키텍처는 원래 기계 번역을 위해 개발되었기에, 현재 번역하려는
소스 시퀀스(source sequence)와 변환하려는타깃 시퀀스(target sequence)두가지가 필요하다.
트랜스포머는 한 시퀀스를 다른 시퀀스로 변환하기 위해 고안된 시퀀스-투-시퀀스(sequence-to-sequence) 모델이다.
여기서 소개한 셀프 어텐션 메커니즘은 다음과 같다.
output = sum(inputs(C) * pairwise_scores(inputs(A), inputs(B))
이는 inputs(A)에 있는 모든 토큰이 inputs(B)에 있는 모든 토큰에 얼마나 관련되어 있는지 계산하고, 이 점수를 사용하여 inputs(C)에 있는 모든 토큰의 가중치 합을 계산한다는 것을 의미한다.
A, B, C가 동일한 입력 시퀀스여야 한다는 조건은 없다. 일반적으로 3개의 다른 시퀀스로 이를 수행할 수 있다. 이를 쿼리(query), 키(key), 값(value) 이라고 부른다. 이 연산은 '쿼리에 있는 모든 원소가 키에 있는 모든 원소에 얼마나 관련되어있는지를 계산하고, 이 점수를 사용하여 값에 있는 모든 원소의 가중치 합을 계산' 하는 것이다.
output = sum( values * pairwise_scores( query , keys ))
이는 데이터베이스에서 이미지 검색하기에서 유래했는데, 쿼리와 키를 비교하고, 매칭 점수를사용하여 값의 순서를 매기는 것과 동일하다.
개념적으로 이것이 트랜스포머 스타일의 어텐션이 하는 일 이다.
찾고 있는 것을 설명하는 참조 시퀀스인 쿼리를 가지고 있다. 정보를 추출할 지식의 본체인 값(value)도 가지고 있다. 쿼리와 쉽게 비교할 수 있는 포맷으로 값을 설명하는 키가 각 값에 할당되어 있으며, 쿼리와 키를 매칭하기만 하면 된다. 마지막으로 값의 가중치 합을 반환한다.
하지만, 실제로 키와 값은 같은 시퀀스인 경우가 많다. 예를 들어 기계 번역에서는 쿼리가 타깃 시퀀스고, 소스 시퀀스는 키와 값의 역할을 한다. 타깃의 각 원소(movie)에 대해 소스(what's yourt favorite film?)에서 이와 관련된 원소(film과 movie의 매칭 점수가 높아야한다)를 찾는다. 시퀀스 분류라면 쿼리, 키 , 값이 모두 같아야하고, 시퀀스가 자기 자신과 비교하여 각 토큰에 전체 시퀀스의 풍부한 맥락을 부여해야하는데, 일반 셀프 어텐션을 이용하면 불가능하다.
"이를 통해 멀티 헤드 어텐션이 필요하게된 계기가 되었다. "
멀티 헤드 어텐션 알아보기
멀티 헤드 어텐션은, 셀프 어텐션 메커니즘의 변형이다. "멀티 헤드" 라는 이름은 셀프 어텐션의 출력 공간이 독립적으로 학습되는 부분 공간으로 나눠진다는 사실을 의미한다.
- 초기 쿼리, 키, 값이 독립적인 3개의 밀집 투영(dense projection)을 통과하여 3개의 별개 벡터가 된다.
- 각 벡터는 뉴럴 어텐션으로 처리되고, 이 출력이 하나의 출력 시퀀스로 연결된다. 이런 각 부분 공간을
헤드라고 한다.
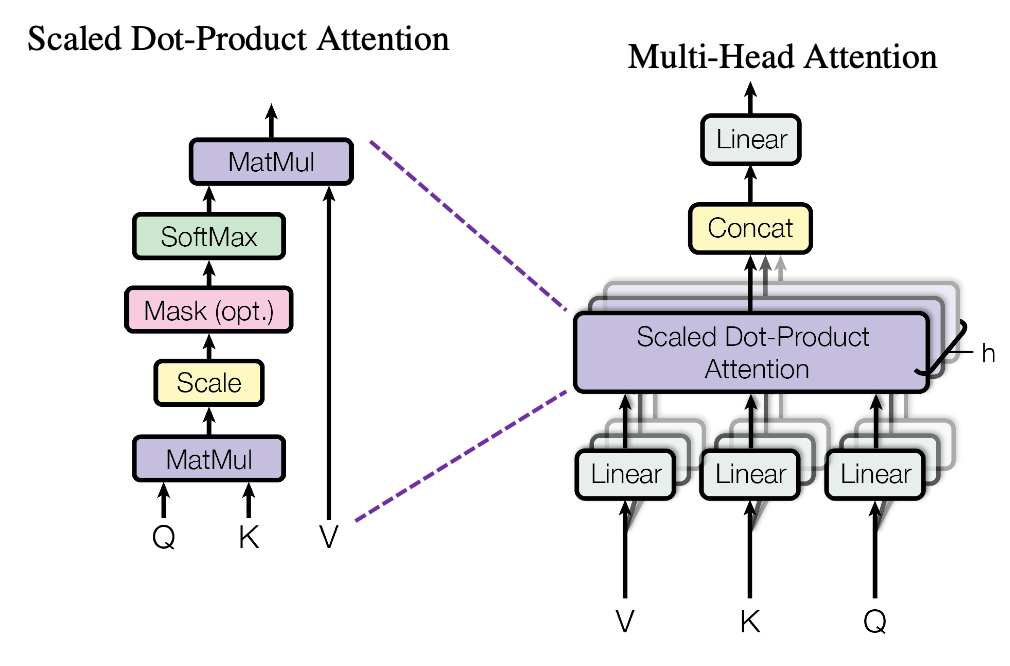
이러한 학습 가능한 밀집 투영 덕분에 이 층이 실제로 무언가를 학습 할 수 있다. 이렇게 독립적인 헤드가 있다면 층이 토큰마다 다양한 특성 그룹을 학습하는데 도움이 된다. 한 그룹 내의 특성은 다른 특성과 연관되어 있지만 다른 그룹에 있는 특성과는 거의 독립적이다.
트랜스포머 인코더
멀티 헤드 어텐션에서 밀집 투영을 추가하는 것이 유용하다는 것을 알았다. 그렇다면 어텐션 메커니즘의 출력에 1개나 2개를 추가한다면 어떨까? 밀집층을 추가해보자. 밀집층, 잔차, 정규화층을 넣어 연결하는 과정이 트랜스포머 인코더(transformer encoder) 를 형성하는 것이다.
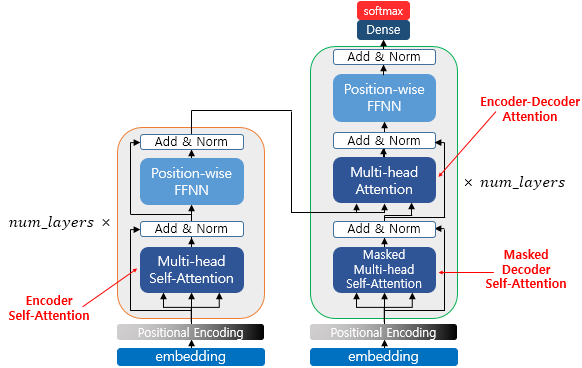
위의 그림과 같이 소스 시퀀스를 처리하는 랜스포머 인코더 소스 시퀀스를 사용하여 변환된 버전을 생성하는 랜스포머 디코더 가 존재한다.
자, 이제 트랜스포머 인코더를 구현해보자.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim #입력 토큰 벡터의 크기
self.dense_dim = dense_dim #내부 밀집 층의 크기
self.num_heads = num_heads #어텐션 헤드의 개수
self.attention = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs, mask=None): #call()메서드에 연산을 수행한다.
if mask is not None: #Embedding층에서 생성하는 마스크는 2D이지만 어텐션 층은 3D또는 4D를 기대한다.
mask = mask[:, tf.newaxis, :]
attention_output = self.attention(
inputs, inputs, attention_mask=mask)
proj_input = self.layernorm_1(inputs + attention_output)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)
def get_config(self): #모델 저장을 위한 직렬화 구현
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim,
})
return config다음으로, 트랜스포머 인코더를 사용해 텍스트 분류하기를 진행해보자. LSTM 기반 모델과 비슷하다.
vocab_size = 20000
embed_dim = 256
num_heads = 2
dense_dim = 32
inputs = keras.Input(shape=(None,), dtype="int64")
x = layers.Embedding(vocab_size, embed_dim)(inputs)
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
---------------------------------------------------------------------
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, None)] 0
embedding (Embedding) (None, None, 256) 5120000
transformer_encoder (Transf (None, None, 256) 543776
ormerEncoder)
global_max_pooling1d (Globa (None, 256) 0
lMaxPooling1D)
dropout (Dropout) (None, 256) 0
dense_2 (Dense) (None, 1) 257
=================================================================
Total params: 5,664,033
Trainable params: 5,664,033
Non-trainable params: 0
_________________________________________________________________모델 훈련을 진행해보면,
callbacks = [
keras.callbacks.ModelCheckpoint("transformer_encoder.keras",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20, callbacks=callbacks)
model = keras.models.load_model(
"transformer_encoder.keras",
custom_objects={"TransformerEncoder": TransformerEncoder})
print(f"테스트 정확도: {model.evaluate(int_test_ds)[1]:LSTM 모델보다 약간 낮은 87.5%의 정확도를 달성한다.
왜 그럴까?
코드에서 확인할 수 있다. 여기서는 순서를 중요시하는 시퀀스 모델을 만들어야하나. 여기서의 트랜스포머 인코더는 전혀 시퀀스 모델이 아니다. 시퀀스 토큰은 독립적으로 처리하는 밀집 층과 토큰을 집합으로 바라보는 어텐션 층으로 구성되어있다. 시퀀스에 있는 토큰 순서를 바꾸어도 정확히 동일한 어텐션 점수와 표현을 얻을 것이다. 즉 ! 셀프 어텐션은 시퀀스 원소 쌍 사이의 관계에 초점을 맞춘 집합 처리 메커니즘이다. 원소가 시퀀스 처음에 등장하는지, 마지막에 등장하는지, 중간에 등장하는지 알수 없다 이말이다 !
근데 왜 트랜스포머를 시퀀스 모델이라고 부를까?
트랜스포머는 기술적으로 순서에 구애받지 않지만 모델이 처리하는 표현에 순서 정보를 수동으로 주입하는 하이브리드 방식이다. 이를 치 인코딩(positional encoding)이라고 한다.
위치 인코딩이란, 모델에 단어 순서 정보를 제공하기 위해 문장의 단어 위치를 각 단어 임베딩에 추가하는 과정이다.
- 입력 단어의 임베디은 현재 문장의 단어 위치를 표현하는 위치 벡터이다. 단어 위치를 임베딩 벡터에 연결하여 생성한다. 여기서, 이산적인 입력분포에 잘 동작하기 위해 위치에 따라 주기적으로 바뀌는 [-1,1]범위의 값을 가진 벡터를 단어 임베딩에 추가하였다.
BUT, 좋은 방법이 아니다.- 따라서 단어 인덱스의 임베딩을 학습하는 것처럼 위치 임베딩 벡터를 학습한다. 그다음 위치 임베딩을 이에 해당하는 단어 임베딩에 추가하여 위치를 고려한 단어 임베딩을 만든다.
이러한 기법을위치 임베딩이라고 부른다.
서브 클래싱으로 위치 임베딩을 한번 구현해보자.
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, input_dim, output_dim, **kwargs):
#위치 임베딩의 단점은 시퀀스 길이를 미리 알아야한다는 것
super().__init__(**kwargs)
self.token_embeddings = layers.Embedding( #토큰 인덱스를 위한 Embedding층을 준비한다.
input_dim=input_dim, output_dim=output_dim)
self.position_embeddings = layers.Embedding(
input_dim=sequence_length, output_dim=output_dim)
self.sequence_length = sequence_length
self.input_dim = input_dim
self.output_dim = output_dim
def call(self, inputs):
length = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=length, delta=1)
embedded_tokens = self.token_embeddings(inputs)
embedded_positions = self.position_embeddings(positions)
return embedded_tokens + embedded_positions #두 임베딩 벡터를 더한다.
def compute_mask(self, inputs, mask=None):
return tf.math.not_equal(inputs, 0)
def get_config(self):
config = super().get_config()
config.update({
"output_dim": self.output_dim,
"sequence_length": self.sequence_length,
"input_dim": self.input_dim,
})
return config영광의 순간 ! 트랜스포머 인코더와 위치 임베딩을 합쳐보자.
vocab_size = 20000
sequence_length = 600
embed_dim = 256
num_heads = 2
dense_dim = 32
inputs = keras.Input(shape=(None,), dtype="int64")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(inputs)
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("full_transformer_encoder.keras",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20, callbacks=callbacks)
model = keras.models.load_model(
"full_transformer_encoder.keras",
custom_objects={"TransformerEncoder": TransformerEncoder,
"PositionalEmbedding": PositionalEmbedding})
print(f"테스트 정확도: {model.evaluate(int_test_ds)[1]이 모델의 테스트 정확도는 88.3%이다. 이렇게 텍스트 분류에 단어 순서가 중요하다는 것을 확인할 수 있다.
텍스트 분류를 넘어 : 시퀀스-투-시퀀스 학습하기
이제 단순 텍스트 분류 뿐만이 아닌, NLP의 분류 작업 외 시퀀스-투-시퀀스 모델을 학습하며 기술 심화를 진행해보자!
시퀀스-투-시퀀스 모델(sequence-to-sequence model) 은 입력으로 시퀀스(문장이나 문단 종종)를 받아 이를 다른 시퀀스로 바꾼다.
이는 여러가지 NLP어플리케이션의 핵심이 된다.
기계번역: 소스 언어에 있는 문단을 타깃 언어의 문단으로 바꾼다.텍스트 요약: 긴 문서를 대부분 중요한 정보를 유지한 짧은 버전으로 바꾼다.질문답변: 입력 질문에 대한 답변을 생성한다.텍스트 생성: 시작 텍스트를 사용하여 하나의 문단을 완성한다.
훈련 도중에는 다음과 같은 작업을 수행한다.
인코더: 인코더 모델이 소스 시퀀스를 중간 표현으로 바꾼다.디코더: (0에서 i-1까지의) 이전 토큰과 인코딩된 소스 시퀀스를 보고 타깃 시퀀스에 있는 다음 토큰 i를 예측하도록 훈련된다.
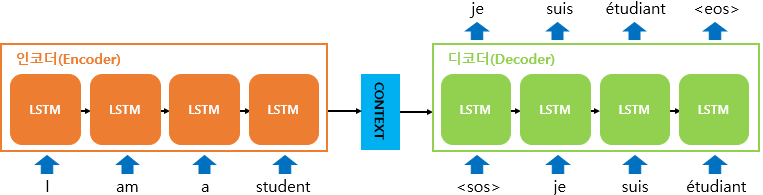
조금 더 쉽게 설명을 들어보면, 이 사이트를 참고해보면 좋다. 위키독스_시퀀스투시퀀스모델
모델의 흐름을 살펴보자.
1. 인코더가 소스 시퀀스를 인코딩한다.
2. 디코더가 인코딩된 소스 시퀀스와 ("[start]" 문자열과 같은) 초기 "시드(seed)" 토큰을 사용하여 시퀀스의 첫 번째 토큰을 예측한다.
3. 지금까지 예측된 시퀀스를 디코더에 다시 주입하고 다음 토큰을 생성하는 식으로 ("[end]" 문자열과 같은) 종료 토큰이 생성될 때까지 반복한다.
자, 이제 정확한 예제를 살펴볼 시간 !!
기계 번역 예제
기계 번역 작업에 시퀀스-투-시퀀스 모델을 적용해보자. (트랜스포머를 개발한 것은 기계 번역을 위해서라는거)
첫 번째, 영어 - 스페인어 번역 데이터셋을 사용하여 파일을 내려받고, 훈련-검증-테스트 셋까지 만들어보자.
!wget http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip
!unzip -q spa-eng.zip
#파일 다운받기
text_file = "spa-eng/spa.txt"
with open(text_file) as f:
lines = f.read().split("\n")[:-1]
text_pairs = []
for line in lines:
english, spanish = line.split("\t") #각 라인은 영어 구절과 이에 해당하는 스페인 번역을 포함해 탭으로 구분됨.
spanish = "[start] " + spanish + " [end]" #형식 맞추기 위해 스타트와 엔드 추가
text_pairs.append((english, spanish))
#파일 파싱해보기
import random
random.shuffle(text_pairs)
num_val_samples = int(0.15 * len(text_pairs))
num_train_samples = len(text_pairs) - 2 * num_val_samples
train_pairs = text_pairs[:num_train_samples]
val_pairs = text_pairs[num_train_samples:num_train_samples + num_val_samples]
test_pairs = text_pairs[num_train_samples + num_val_sam그다음 영어와 스페인어를 위한 2개의 TextVectorization 층을 준비한다. 문자열을 전처리하는 방식을 커스터마이징해야한다.
조건 1. 앞에서 추가한 "[start]" 와 "[end]" 토큰을 유지해야한다.
조건 2. 구두점은 언어마다 다르다 ! 스페인어 T.V층에서 구두점 문자를 삭제하려면 ¿ 문자도 삭제해야한다.
영어와 스페인어 텍스트 쌍을 벡터화해보자.
import tensorflow as tf
from tensorflow.keras import layers
import string
import re
strip_chars = string.punctuation + "¿"
strip_chars = strip_chars.replace("[", "")
strip_chars = strip_chars.replace("]", "")
#스페인어 T.V층을 위해 사용자 정의 문자열 표준화 함수를 정의한다.
def custom_standardization(input_string):
lowercase = tf.strings.lower(input_string)
return tf.strings.regex_replace(
lowercase, f"[{re.escape(strip_chars)}]", "")
vocab_size = 15000
sequence_length = 20
source_vectorization = layers.TextVectorization( #영어층
max_tokens=vocab_size,
output_mode="int",
output_sequence_length=sequence_length,
)
target_vectorization = layers.TextVectorization( #스페인어층
max_tokens=vocab_size,
output_mode="int",
output_sequence_length=sequence_length + 1,
standardize=custom_standardization,
)
train_english_texts = [pair[0] for pair in train_pairs]
train_spanish_texts = [pair[1] for pair in train_pairs]
source_vectorization.adapt(train_english_texts) #각각의 어휘사전 만들기
target_vectorization.adapt(train_spanish_texts)번역 작업을 위한 데이터셋을 준비하자.
batch_size = 64
def format_dataset(eng, spa):
eng = source_vectorization(eng)
spa = target_vectorization(spa)
return ({
"english": eng,
"spanish": spa[:, :-1],
}, spa[:, 1:])
def make_dataset(pairs):
eng_texts, spa_texts = zip(*pairs)
eng_texts = list(eng_texts)
spa_texts = list(spa_texts)
dataset = tf.data.Dataset.from_tensor_slices((eng_texts, spa_texts))
dataset = dataset.batch(batch_size)
dataset = dataset.map(format_dataset, num_parallel_calls=4)
return dataset.shuffle(2048).prefetch(16).cache()
train_ds = make_dataset(train_pairs)
val_ds = make_dataset(val_pairs)자 여기까지 진행하면 모델 학습을 위한 전처리 준비 완료 !
이제는 RNN을 사용한 시퀀스-투-시퀀스 모델을 만들어보자.
RNN을 사용한 시퀀스-투-시퀀스 모델
RNN(인코더)를 사용하여 전체 소스 문장을 하나의 벡터로 바꾼다. 이 벡터는 RNN의 마지막 출력이거나 또는 마지막 상태 벡터일 수 있다. 그 다음 벡터를 달느 RNN(디코더)의 초기 상태로 사용한다. 이 RNN은 타깃 시퀀스에 있는 원소0..N을 사용하여 스텝 N+1을 예측한다.
기반 인코더 먼저 작성
from tensorflow import keras
from tensorflow.keras import layers
embed_dim = 256
latent_dim = 1024
source = keras.Input(shape=(None,), dtype="int64", name="english")
x = layers.Embedding(vocab_size, embed_dim, mask_zero=True)(source)
encoded_source = layers.Bidirectional(
layers.GRU(latent_dim), merge_mode="sum")(x)그다음 GRU 기반 디코더 작성
past_target = keras.Input(shape=(None,), dtype="int64", name="spanish")
x = layers.Embedding(vocab_size, embed_dim, mask_zero=True)(past_target)
decoder_gru = layers.GRU(latent_dim, return_sequences=True)
x = decoder_gru(x, initial_state=encoded_source)
x = layers.Dropout(0.5)(x)
target_next_step = layers.Dense(vocab_size, activation="softmax")(x)
seq2seq_rnn = keras.Model([source, past_target], target_n모델을 훈련해보면
seq2seq_rnn.compile(
optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
seq2seq_rnn.fit(train_ds, epochs=15, validation_data=val이 모델의 경우, 과거 정보만 사용해서 미래를 예측한다는 의미이기 때문에 모델 추론 시 제대로 동작하지 않을 수 있다.
import numpy as np
spa_vocab = target_vectorization.get_vocabulary()
spa_index_lookup = dict(zip(range(len(spa_vocab)), spa_vocab))
max_decoded_sentence_length = 20
def decode_sequence(input_sentence):
tokenized_input_sentence = source_vectorization([input_sentence])
decoded_sentence = "[start]"
for i in range(max_decoded_sentence_length):
tokenized_target_sentence = target_vectorization([decoded_sentence])
next_token_predictions = seq2seq_rnn.predict(
[tokenized_input_sentence, tokenized_target_sentence])
sampled_token_index = np.argmax(next_token_predictions[0, i, :])
sampled_token = spa_index_lookup[sampled_token_index]
decoded_sentence += " " + sampled_token
if sampled_token == "[end]":
break
return decoded_sentence
test_eng_texts = [pair[0] for pair in test_pairs]
for _ in range(20):
input_sentence = random.choice(test_eng_texts)
print("-")
print(input_sentence)
print(decode_sequence(input_sentence))RNN 인코더와 디코더로 새로운 문장을 번역하는 부분을 봐도, 간단하지만 효율적이지 않다. 전체 소스 시퀀스와 지금까지 생성된 전체 타깃 시퀀스를 새로운 단어를 샘플링할 때마다 모두 다시 처리해야하기 때문이다.
여기서 알아보는 시퀀스-투-시퀀스 RNN방식의 제약은
-
소스 시퀀스가 인코더 상태 벡터로 완전하게 표현되어야한다. 이는 번역할 수 있는 문장의 크기와 복잡도에 큰 제약이 된다.
-
RNN 은 오래된 과거를 점진적으로 잊어버리는 경향이 있기 때문에, 매우 긴 문장을 처리하는데 문제가 있다. 이는 RNN기반 모델이 긴 문서를 번역하는데 필수적인 넓은 범위의 문맥을 감지할 수 없다는 의미이다.
따라서 이러한 제약으로 인해 시퀀스-투-시퀀스 문제에 트랜스포머 아키텍처 를 적용하게 되었다.
트랜스포머를 사용한 시퀀스-투-시퀀스 모델
트랜스포머 아키텍처를 사용하면 RNN이 다룰 수 있는 것보다 훨씬 길고 복잡한 시퀀스를 성공적으로 처리할 수 있다.
RNN 인코더와 달리 트랜스포머 인코더는 시퀀스 형태로 인코딩된 표현을 유지한다. 즉 문맥을 고려한 임베딩 벡터의 시퀀스가 된다는 것 !
모델의 나머지 절반은 트랜스포머 디코더인데, RNN 디코더와 마찬가지로 타깃 시퀀스에 있는 토큰 0..N 을 읽고 토큰 N+1을 예측한다. 여기서 중요한 점은 이를 수행하면서 뉴럴 어텐션을 사용하여 인코딩된 소스 문장에서 어떤 토큰이 현재 예측하려는 타깃 토큰에 가장 관련이 높은지를 식별한다는 것이다.
트랜스포머 디코더를 살펴보자.
트랜스포머 디코더는 인코더와 매우 비슷하지만, 타깃 시퀀스에 적용되는 셀프 어텐션 블록과 마지막 블록의 밀집 층 사이에 추가적인 어텐션 블록이 들어가있다. 클래스를 정의해보자.
class TransformerDecoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.num_heads = num_heads
self.attention_1 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.attention_2 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
self.layernorm_3 = layers.LayerNormalization()
self.supports_masking = True #이 속성은 층이 입력 마스킹을 출력으로 전달하도록 만든다.
#케라스에서 마스킹을 사용하려면 명시적으로 설정을 해야한다.
def get_config(self):
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim,
})
return config
def get_causal_attention_mask(self, inputs):
input_shape = tf.shape(inputs)
batch_size, sequence_length = input_shape[0], input_shape[1]
i = tf.range(sequence_length)[:, tf.newaxis]
j = tf.range(sequence_length)
mask = tf.cast(i >= j, dtype="int32")
mask = tf.reshape(mask, (1, input_shape[1], input_shape[1]))
mult = tf.concat(
[tf.expand_dims(batch_size, -1),
tf.constant([1, 1], dtype=tf.int32)], axis=0)
return tf.tile(mask, mult)
def call(self, inputs, encoder_outputs, mask=None):
causal_mask = self.get_causal_attention_mask(inputs)
if mask is not None:
padding_mask = tf.cast(
mask[:, tf.newaxis, :], dtype="int32")
padding_mask = tf.minimum(padding_mask, causal_mask)
attention_output_1 = self.attention_1(
query=inputs,
value=inputs,
key=inputs,
attention_mask=causal_mask)
attention_output_1 = self.layernorm_1(inputs + attention_output_1)
attention_output_2 = self.attention_2(
query=attention_output_1,
value=encoder_outputs,
key=encoder_outputs,
attention_mask=padding_mask,
)
attention_output_2 = self.layernorm_2(
attention_output_1 + attention_output_2)
proj_output = self.dense_proj(attention_output_2)
return self.layernorm_3(attention_output_2 + pro트랜스포머 디코더를 만들 때 Causal padding을 고려해야한다. Causal padding은 시퀀스-투-시퀀스 트랜스포머의 핵심 중추인데, RNN은 한 스텝 씩 입력을 보는 반면(출력 스텝 N을 생성하기 위해 스텝 0..N 만 사용할 수 있다) 트랜스포머 디코더는 순서에 구애받지 않고 한번에 타깃 시퀀스 전체를 본다.
따라서 전체 입력을 사용하도록 둔다면 단순히 입력 스텝 N+1 을 출력 위치 N에 복사하는 방법을 학습할 것이다. 따라서 이 모델은 완벽한 훈련 정확도를 달성하나 추론을 수행 할 때 N 이상의 입력 스텝이 없기 때문에 쓸모가 없다.
해결 방법은 모델이 미래에서 온 정보에 주의를 기울이지 못하도록 어텐션 행렬의 위쪽 절반을 마스킹하면 된다.
이를 위해 Transformerdecoder 클래스에 get_causal_attention_mask(self, inputs) 메서드를 추가하여 MultiHearAttention 층에 전달할 수 있는 어텐션 행렬을 만든다.
코드는 위에 포함되어 있다.
기계 번역을 위한 트랜스포머
기계 번역을 위한 모델을 구현해보자.
지금까지 실습을 통해 진행했던 Positional Embedding 층, TransformerEncoder와 TransformerDecoder 클래스를 합치면 된다. 인코더와 디코더는 여러개를 쌓아 더 강력한 것을 만들 수 있지만, 단순 하나만 일단 구현해보겠다.
먼저 Poisitional Embedding 층을 만들어보자.
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, input_dim, output_dim, **kwargs):
super().__init__(**kwargs)
self.token_embeddings = layers.Embedding(
input_dim=input_dim, output_dim=output_dim)
self.position_embeddings = layers.Embedding(
input_dim=sequence_length, output_dim=output_dim)
self.sequence_length = sequence_length
self.input_dim = input_dim
self.output_dim = output_dim
def call(self, inputs):
length = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=length, delta=1)
embedded_tokens = self.token_embeddings(inputs)
embedded_positions = self.position_embeddings(positions)
return embedded_tokens + embedded_positions
def compute_mask(self, inputs, mask=None):
return tf.math.not_equal(inputs, 0)
def get_config(self):
config = super(PositionalEmbedding, self).get_config()
config.update({
"output_dim": self.output_dim,
"sequence_length": self.sequence_length,
"input_dim": self.input_dim,
})
return config다음으로 엔드-투-엔드 트랜스포머를 만들어보자.
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.num_heads = num_heads
self.attention = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs, mask=None):
if mask is not None:
mask = mask[:, tf.newaxis, :]
attention_output = self.attention(
inputs, inputs, attention_mask=mask)
proj_input = self.layernorm_1(inputs + attention_output)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)
def get_config(self):
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim,
})
return configembed_dim = 256
dense_dim = 2048
num_heads = 8
encoder_inputs = keras.Input(shape=(None,), dtype="int64", name="english")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(encoder_inputs)
encoder_outputs = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
#소스 문장을 인코딩한다.
decoder_inputs = keras.Input(shape=(None,), dtype="int64", name="spanish")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(decoder_inputs)
x = TransformerDecoder(embed_dim, dense_dim, num_heads)(x, encoder_outputs)
#타깃 시퀀스를 인코딩하고 인코딩된 소스 문장과 합친다.
x = layers.Dropout(0.5)(x)
decoder_outputs = layers.Dense(vocab_size, activation="softmax")(x) #출력 위치마다 하나의 단어를 예측한다.
transformer = keras.Model([encoder_inputs, decoder_in구현이 완료되었으면, 시퀀스-투-시퀀스 트랜스포머를 훈련시켜보자.
transformer.compile(
optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
transformer.fit(train_ds, epochs=30, validation_data=v정확도가 대체적으로 66%정도가 나온다. 이제 작성한 모델을 바탕으로 이전에 본 적 없는 영어 문장을 번역해보자.
import numpy as np
spa_vocab = target_vectorization.get_vocabulary()
spa_index_lookup = dict(zip(range(len(spa_vocab)), spa_vocab))
max_decoded_sentence_length = 20
def decode_sequence(input_sentence):
tokenized_input_sentence = source_vectorization([input_sentence])
decoded_sentence = "[start]"
for i in range(max_decoded_sentence_length):
tokenized_target_sentence = target_vectorization(
[decoded_sentence])[:, :-1]
predictions = transformer(
[tokenized_input_sentence, tokenized_target_sentence]) #다음 토큰을 샘플링한다.
sampled_token_index = np.argmax(predictions[0, i, :])
sampled_token = spa_index_lookup[sampled_token_index] #다음 토큰 예측을 문자열로 바꾸고, 생성된 문장에 추가
decoded_sentence += " " + sampled_token
if sampled_token == "[end]":
break
return decoded_sentence
test_eng_texts = [pair[0] for pair in test_pairs]
for _ in range(20):
input_sentence = random.choice(test_eng_texts)
print("-")
print(input_sentence)
print(decode_sequence(input_sentence))-
Our electric heater did not work well.
[start] nuestra el su [end]
-
All my efforts were in vain.
[start] todos mis [UNK] fueron en primer parte [end]
-
They meant well.
[start] ellos [UNK] bien [end]
-
Tom and Mary each took one cookie.
[start] tom y mary [UNK] una la el que se [UNK] [end]
-
I gave some water to the dogs.
[start] le di algo de agua al perro [end]
-
Tom wished that his classmates would treat each other with more respect.
[start] tom [UNK] que sus esfuerzos [UNK] uno después del otro [end]
-
I was at the theater.
[start] estaba en el usted punto [end]
-
This is the best camera in the store.
[start] esta es la mejor cámara de fotos [end]
-
Let me feel it.
[start] dime [end]
-
Put your hat on.
[start] [UNK] este sombrero [end]
-
I had hoped that my mother would live until I got married.
[start] esperaba haber estado tan parado aquí después viven hasta que me [UNK] [end]
-
Then what happened?
[start] entonces qué ocurrió [end]
-
Isn't that right?
[start] eso es verdad [end]
-
Tom has forgiven Mary for everything.
[start] tom le dio a mary por todo [end]
-
I'll be reading a book.
[start] voy a estar leyendo un libro [end]
-
Be brief.
[start] sé [UNK] [end]
-
Let's see if we can get this door open.
[start] a ver si podemos [UNK] esta puerta [end]
-
I think I've forgotten something.
[start] creo que he dejado algo de que me he dejado algo [end]
-
He parked his car behind the building.
[start] Él se lo [UNK] entre su coche [end]
-
There are no witnesses.
[start] no hay enemigos [end]결과를 주관적으로 보면, 트랜스포머는 GRU 기반 번역 모델보다 성능이 훨씬 좋은 것을 확인할 수 있다.
이로써 자연어 처리에 대한 학습을 마친다.
기계가 언어를 이해하도록 가르치는 것은 우리가 갖출 수 있는 강력한 최신 기술이다.
