GFTE: Graph-based Financial Table Extraction
Yiren Li, Zheng Huang, Junchi Yan, Yi Zhou, Fan Ye, Xianhui Liu
[ paper ] [ github code ]
테이블 구조 인식에 대해 조사하다가 맞닥뜨린 논문. 테이블=표
이해와 요약은 내가 중요하다고 생각한 거 위주. 이건 논문 외 내용.
Abstract
표 데이터가 정보를 찾거나 비교하는데 용이하기 때문에 잘 쓰이죠. 저자들이 읽고 싶었던 경제 분야의 테이블은 비정형화된 PDF나 이미지 형태로 많이 존재하기 때문에 필요한 정보의 추출이 어려웠다고 합니다.
그래서 저자들은 FinTab이라는 중국어로 된 표 데이터셋이랑 json의 구조을 만들고, 새로운 graph-based CNN 모델인 GFTE를 개발하였습니다.
Instroduction
PDF 문서에서 각종 정보를 잘 추출해내고 싶은데 표에서 수동으로 정보를 추출해내는 것은 귀찮습니다. 자동 표 인식 툴을 이용하였을 때 어떤지는 아래를 보세요. 별로입니다.
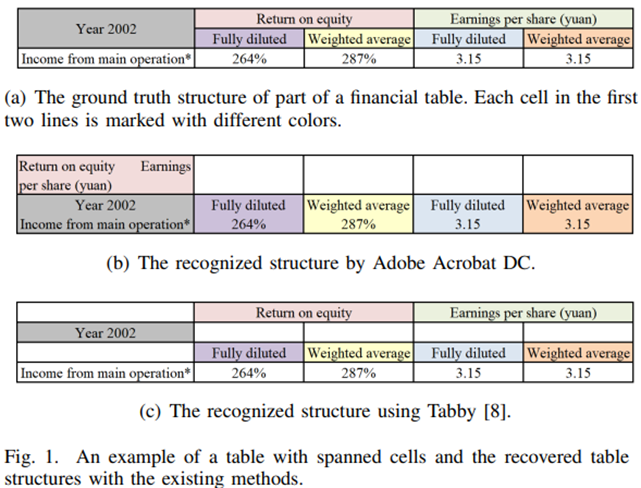
(a) table ground truth
(b) Adobe Acrobat DC를 이용한 표 인식 결과물
(c) Tabby를 이용한 표 인식 결과물
Tabby는 PDF 내에서 텍스트 위치를 찾고 위 아래줄과의 간격을 이용하여 테이블 구조를 인식한다.
- spanned cell : 여러 row나 column에 걸쳐져 있는 cell
테이블 구조 인식을 잘 하기 위해 FinTab이라는 벤치마크 데이터셋을 모으고, 분류하고, 정제하였으며 베이스라인 테스트를 위해 사용하였어요. 그리고 GFTE라는 GCN(graph-based CNN) 모델을 만들었습니다. GFTE는 테이블 구조 인식을 그래프에서 edge를 예측하듯이 보았고, 테이블의 이미지, 문자, 위치 특징을 합쳐서 GCN에게 먹이고 두 노드 사이의 관계를 예측하게 했습니다.
Related Work
테이블 추출에 관한 기존 연구 등등입니다.
데이터셋
다양한 테이블 관련 데이터 셋이 나와있는데 이 중 본 논문 안에서 실험에 쓰인 SciTSR만 설명 드리겠습니다. PDF 형식의 테이블 영역의 이미지와, 구조 labeling, 각 셀에 대한 bounding box를 제공합니다. 복잡 테이블에 대한 리스트인 SciTSR-COMP.list를 제공합니다.
| train | test | |
|---|---|---|
| tables | 12,000 | 3,000 |
| complicated tables | 2,885 | 716 |
Methods
테이블 추출은 2 step으로 이루어 집니다.
1. 테이블 탐지: 파일에서 어디가 테이블인지 알아냄
2. 테이블 구조 분해: 헤더를 인식하고, 행/열 구조, 데이터가 어디 있는지 쪼갬
테이블 추출을 위해 고안된 방법들
- Predefined layout-based approaches: 테이블 구조 템플릿을 몇 개 만들어 놓고, 템플릿과 비슷하게 생긴 부분이 있으면 테이블로 탐지하는 방식
- Heuristic-based approaches: 어떤 기준을 만나면 이게 테이블인지 아닌지 결정할 수 있게 규칙을 세우는 방식
- Statistical or optimization-based approches: 통계적인 방법과 오프라인 (컴퓨터로 학습한 게 아니라 진짜 통계 그 자체를 말하는 듯) 학습으로 얻은 파라미터를 사용하는 방식. 확률적 모델링, Naive 베이지안 분류, decision tree, SVM 등.
Data Collection and Annotation
경제 문서 표 데이터의 필요성을 느껴 FinTab이라는 벤치마크용 데이터셋을 만들었는데요. FinTab은 19개의 PDF 파일과 1600개의 테이블로 구성되어 있습니다. 119,021개의 셀과 2,859개의 merged cell을 포함합니다. 페이지에 걸쳐있는 표와 선이 없는 표 등 다양한 데이터를 포함하며 한문입니다. 저자들도 중국인들.
Baseline Algorithm
새로운 graph-neural-network 기반의 GFTE라는 알고리즘도 만들었습니다. 테이블 구조 인식에 사용할 수 있어요.
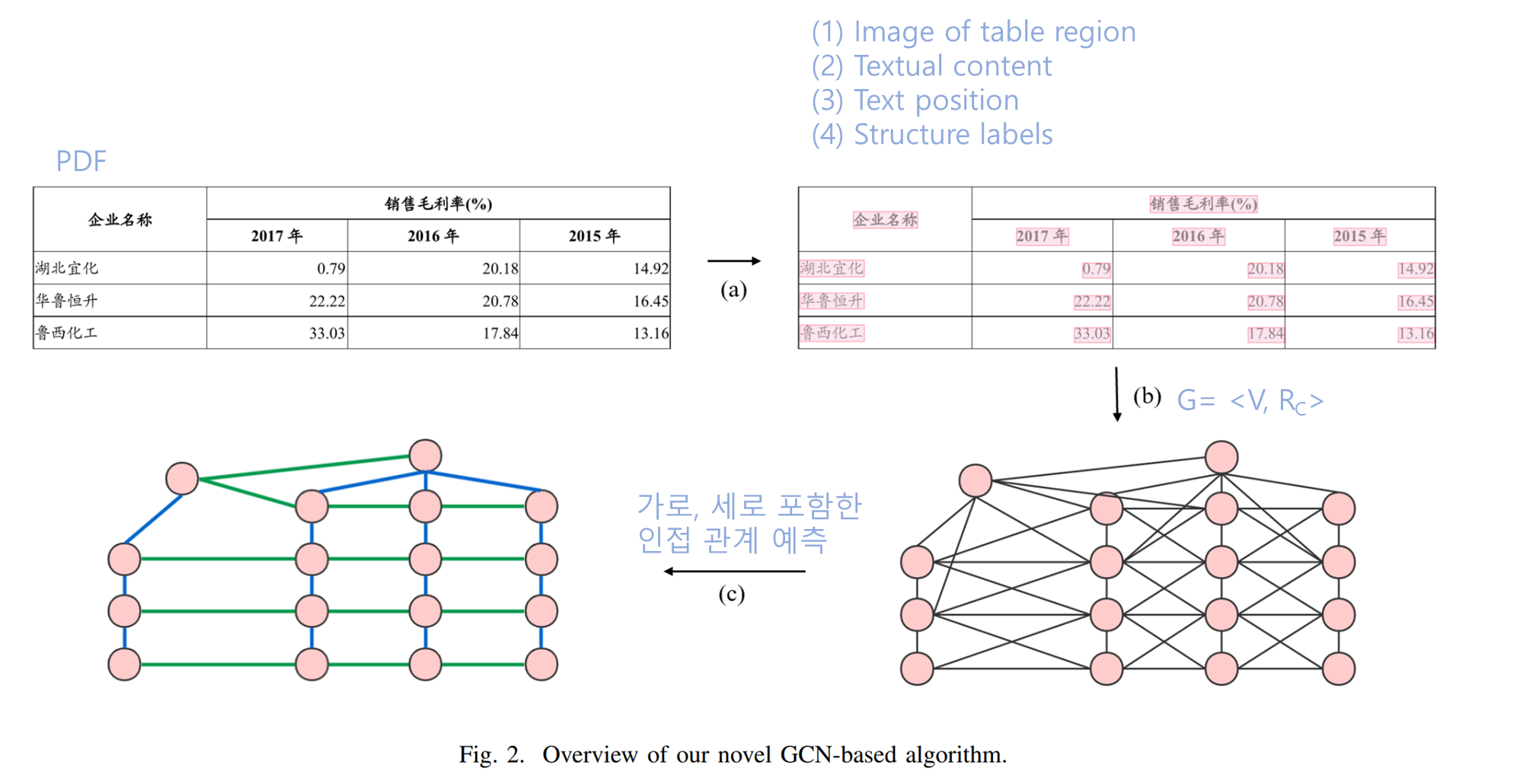
PDF 문서의 표가 들어오면
(a) 테이블의 ground truth - (1) 테이블 영역 이미지 (2) 텍스트 내용 (3) 텍스트의 위치 (4) 구조 라벨을 만듭니다.
(b) 테이블을 무방향 그래프인 로 만듭니다.
(c) GCN-based 알고리즘으로 가로(horizontal), 세로(vertical)의 adjacent relation를 예측합니다.
- AR (adjacent relation) : 인접관계라는 뜻으로, 셀 두개가 붙어 있으면 인접 관계가 있다고 표현합니다. 계산은 이 근처에서 찾아보세요.
문제를 어떻게 해석해야 할까요 ㅋㅋ
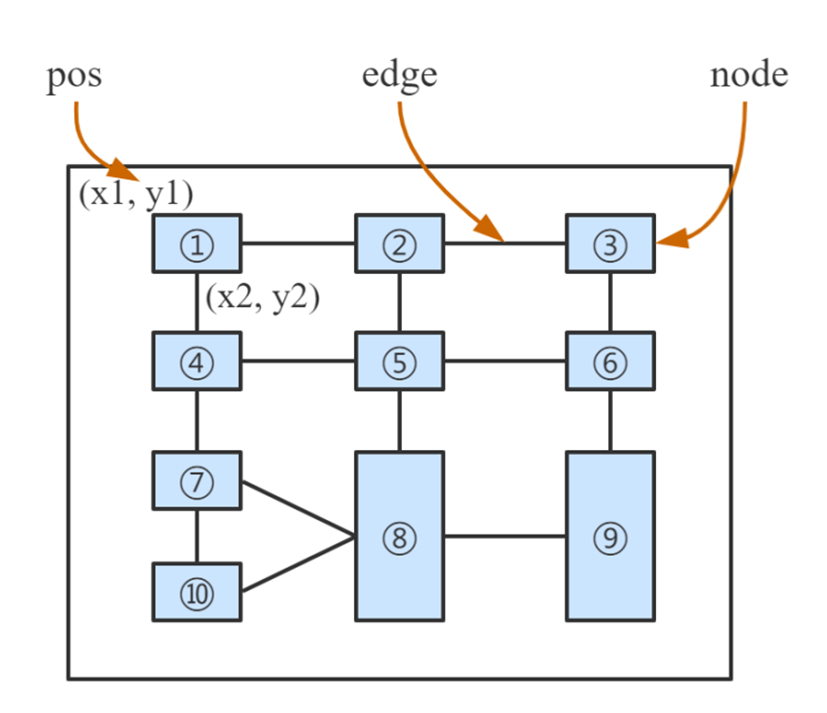
테이블 인식 문제에서, 테이블의 각 셀을 그래프에서 하나의 node로 보는 게 자연스럽겠죠. 그러면 어떤 한 노드의 이웃 노드와의 가로나 세로로 연결 관계는 edge들의 특징으로 이해할 수 있습니다.
을 노드들의 집합, 를 fully connected edges라고 생각해봅시다. 모든 N 사이에 edge들이 연결되어 있고, 이 끼리의 {vertical, horizontal, unrelated} 관계의 집합은 입니다. 이 때 테이블의 구조는 완전(complete) 그래프 로 나타낼 수 있습니다.
우리의 목표는 노드 사이의 를 정확하게 찾는 것인데 의 복잡도를 가지며 계산도 힘들고 시간도 아깝네요. 노드는 가로, 세로로 가장 가까운 노드랑만 연결이 되어 있기 때문에, 엣지의 수를 많이 줄여도 테이블 구조를 알 수 있을 것 같습니다.
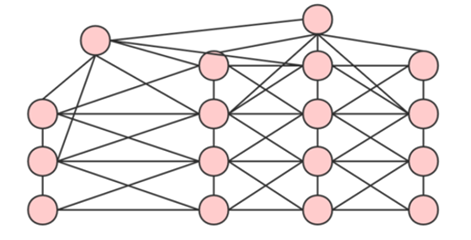
그래서 KNN으로 complete relations가 아닌 각 노드와 K개의 가장 가까운 이웃과의 관계만 포함하는 을 새로 만들었습니다. 이 때의 복잡도는 입니다.
요것이 저 원본 표를 fully connected하지 않고 K=6으로 나타낸 graph입니다.
GFTE
테이블의 각 셀, 즉 노드에는 텍스트 내용, 절대 위치, 이미지 등의 정보가 있습니다.
그리고 전체 구조를 아래 그림과 같이 구조 관계로 만들어야 합니다. 각 엣지가 같은 줄에 있으면 1, 없으면 0으로 가로, 세로 각각 라벨링을 합니다.
이 그림은 아까 표랑 다른 표의 ground truth이니 헷갈리지 마시길 바랍니다.
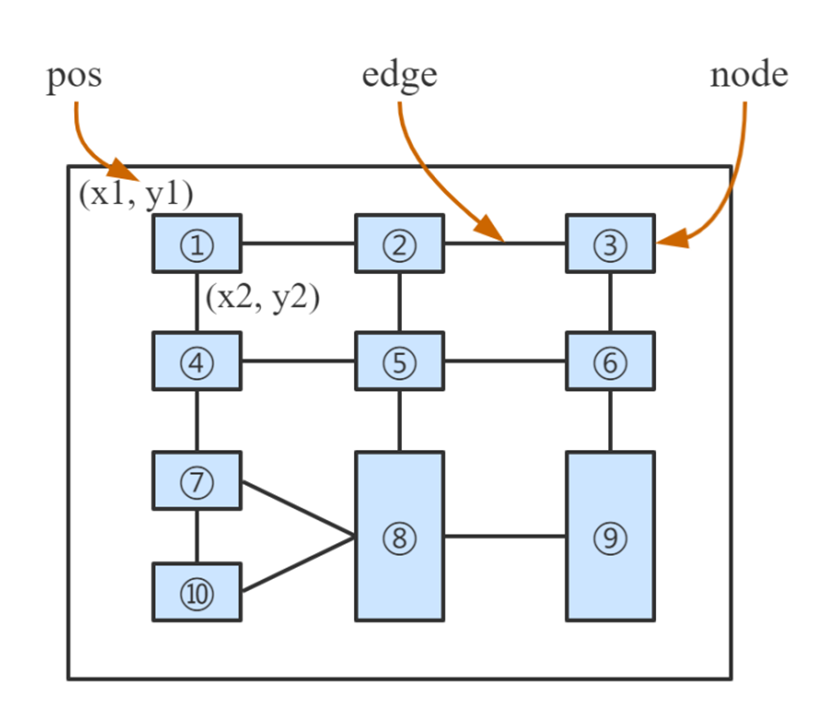 이 데이터들을 가지고 GFTE를 학습 시킵시다.
이 데이터들을 가지고 GFTE를 학습 시킵시다.
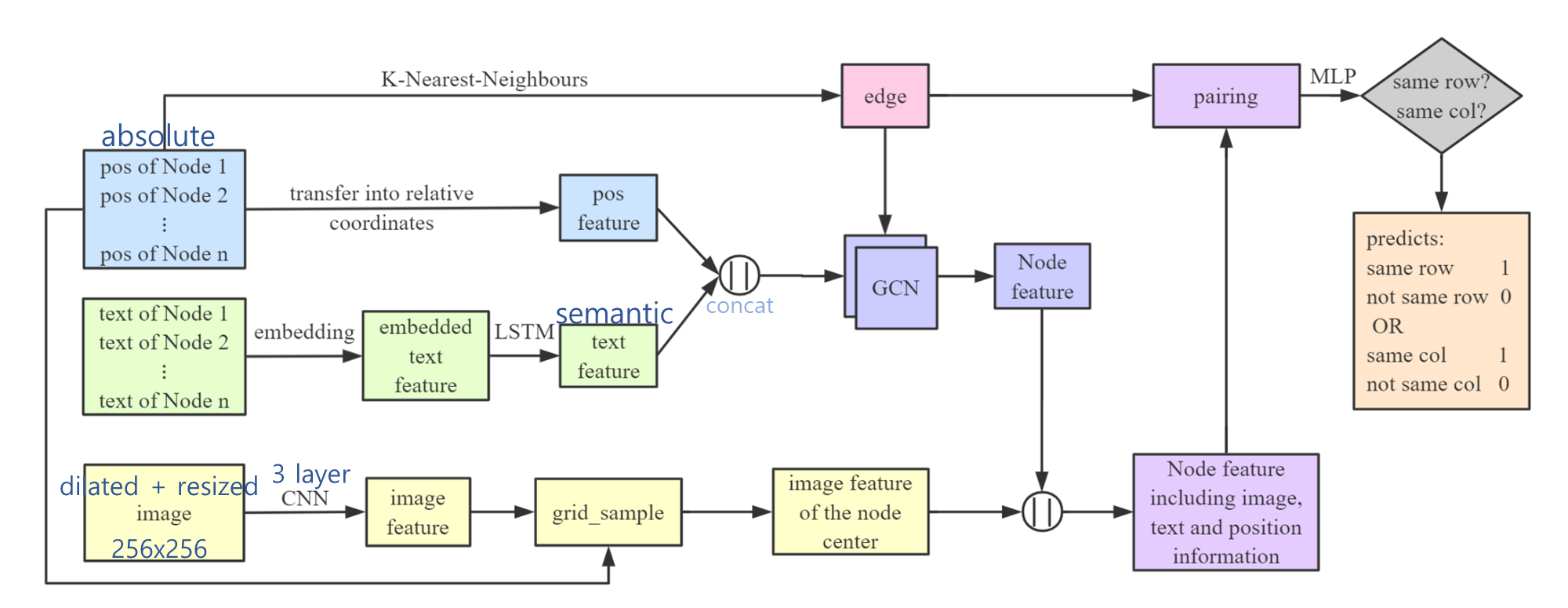 우선 절대 위치는 상대 위치로 바꾸어 그래프를 만드는 위치 특징으로 사용합니다. Plain text를 feature space에 임베딩하면 LSTM이 이 임베딩된 텍스트 특징으로 텍스트의 의미적 특징을 만들어 줍니다. 위치 특징, 텍스트 특징과 KNN으로 뽑아낸 엣지 정보를 합쳐서 두 레이어 짜리의 GCN에게 먹이면 노드들의 특징이 나옵니다.
우선 절대 위치는 상대 위치로 바꾸어 그래프를 만드는 위치 특징으로 사용합니다. Plain text를 feature space에 임베딩하면 LSTM이 이 임베딩된 텍스트 특징으로 텍스트의 의미적 특징을 만들어 줍니다. 위치 특징, 텍스트 특징과 KNN으로 뽑아낸 엣지 정보를 합쳐서 두 레이어 짜리의 GCN에게 먹이면 노드들의 특징이 나옵니다.
이미지는 작은 커널을 이용하여 선들을 두껍게 만들어서 크기를 키운 후 256x256 pixel로 정규화시킵니다. 3 레이어짜리 CNN으로 뽑아 낸 이미지 특징과 노드의 상대 위치를 사용하여 유동장 그리드를 만들어 냅니다. 유동장 그리드란 뭘까? 정말 모르겠네요. 이미지와 상대 위치를 결합한 특징이 어디로 향하는 지를 나타낸 걸까요?
여튼 그리드의 pixel 위치로 알아낸 정보로, 특정 상황에서 특정 노드의 이미지 특징을 알 수 있습니다. 그러면 노드 가운데에서의 이미지 특징을 알아냅니다.
이미지 특징, 노드 특징을 합친 이미지, 텍스트, 위치 정보를 포함한 노드 특징으로 2 노드에 1 엣지가 연결되도록 짝을 지어줘요. 얘네를 MLP에 넣으면 두 노드가 같은 행이나 열에 있는지 예측합니다.
베이스라인 알고리즘을 학습할 때는 아까 SciTSR 학습 데이터셋 이용하였고, 구린 샘플들은 걸렀대요.
Evaluation Result
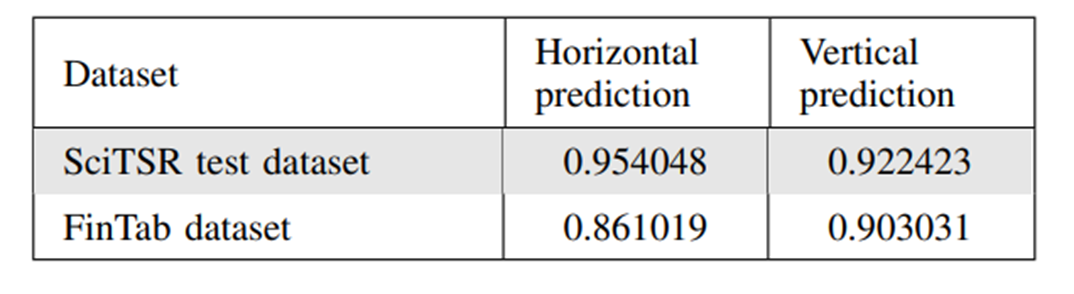 SciTSR test dataset을 validate용으로 사용하였고, FinTab dataset을 test용으로 사용하였어요.
SciTSR test dataset을 validate용으로 사용하였고, FinTab dataset을 test용으로 사용하였어요.
- train: SciTSR train dataset
- val: SciTSR test dataset
- test: FinTab dataset
SciTSR 데이터로 학습시켰기 때문에 validate 점수가 test 점수보다 높죠. 그러니까 어떤 데이터든 학습 데이터가 충분히 있으면 성능이 좋을 거라고 해요. 그리고 SciTSR은 영문, FinTab은 한문으로 이루어진 데이터인데, 언어도 다르고 완전 특징이 다른데도 test 점수가 어느정도 잘 나왔으니 지금 모델이 충분히 훌륭하다고 합니다.
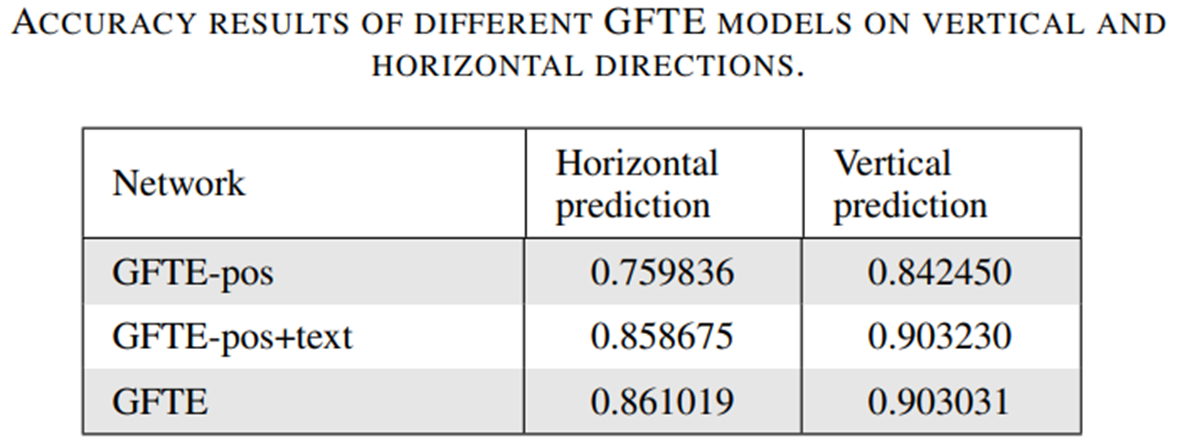
- GFTE-pos: 상대위치와 KNN 알고리즘으로 그래프를 생성하고, position feature만 학습
- GFTE-pos+text: LSTM에서 나온 text feature도 학습
- GFTE: 그리드 샘플링을 이용한 이미지특징까지 학습
표를 보시면 여러 특징을 사용할수록 정확도가 올랐구요. Text feature를 이용하였을 때 특히 horizontal에서 10%, vertical에서 5% 가량 정확도가 올랐습니다. 이미지 특징을 추가했을 때도 오르긴 하는데 엄청나진 않네요.
세 모델에서 모두 가로보다 세로의 정확도가 높은데요. 이것은 test에 쓰인 FinTab의 특징 때문인 것 같대요.
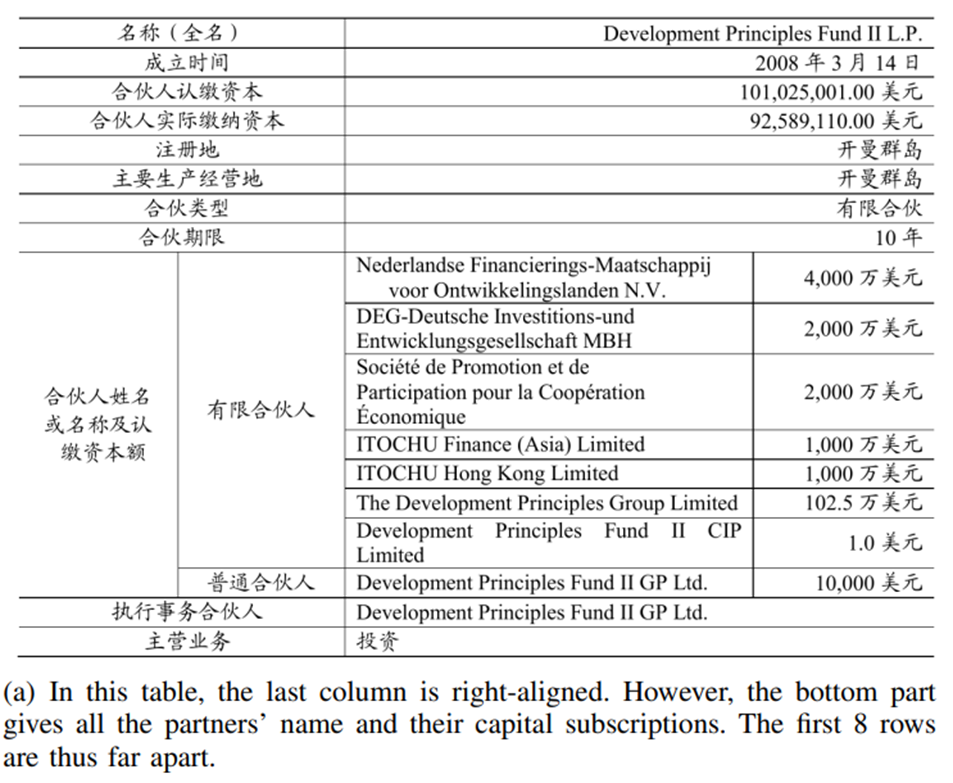 경제 테이블은 셀이 가로로 골고루 퍼져 있지 않아요. 보시면 위 8행은 아래 행들에 비해 가로로 멀찍히 떨어져 있죠.
경제 테이블은 셀이 가로로 골고루 퍼져 있지 않아요. 보시면 위 8행은 아래 행들에 비해 가로로 멀찍히 떨어져 있죠.
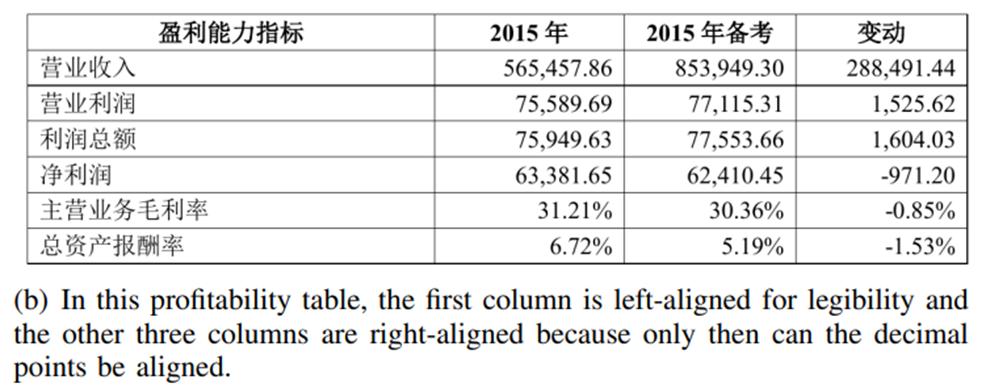 문자들은 왼쪽에 붙어 있고 숫자들은 소수점의 위치로 정렬을 하려고 셀의 오른쪽에 붙어 있네요. 문자 셀인 첫 번째 열에서 K개의 nearest neighbors를 계산하면 세로 애들이 더 가까우니 포함이 잘 되고 두 번째 열부터 있는 셀들은 K가 작을 수록 몇 개 포함되지 않습니다.
문자들은 왼쪽에 붙어 있고 숫자들은 소수점의 위치로 정렬을 하려고 셀의 오른쪽에 붙어 있네요. 문자 셀인 첫 번째 열에서 K개의 nearest neighbors를 계산하면 세로 애들이 더 가까우니 포함이 잘 되고 두 번째 열부터 있는 셀들은 K가 작을 수록 몇 개 포함되지 않습니다.
그러므로 세로 방향의 관계를 더 잘 찾는다고 하네요.
Conclusion
언어가 다르고 경제 테이블의 특징 때문에 아직 결과는 마음에 차지 않아요. FinTab을 이용한 멋진 테이블 추출 알고리즘이 새로 나오길 바랍니다. 미래에는 언어와 경제 테이블의 장벽도 극복하길 바라요.
