
데이터베이스의 검색 속도 향상에는 index가 사용된다. 이 index는 어떤 일을 하는지, 그리고 어떻게 사용해야 검색 속도를 향상시킬 수 있는 지를 알아본다.
인덱스의 특징
Read Performance 향상
- 보통의 테이블은 id를 pk로 갖는다. id는 정수로 구성되며 1씩 증가하는 값이기 때문에 id를 이용해 테이블을 검색 할 때는 데이터베이스가 테이블의 모든 행을 조사하지 않아도 된다.
- 왜냐하면, 데이터베이스가 이미 id를 정렬한 복사본 컬럼을 가지고 있기 때문이다. - 인덱스 컬럼은 실제 테이블의 행에 대한 포인터를 가지고 있어서 만약 조회시 인덱스에서 이미 원하는 id를 찾았다면 포인터를 통해 해당 id에 대한 나머지 데이터를 어디서 찾아야 하는 지 바로 알 수 있다.
게시판 테이블을 가정해 보자
만약 게시판 테이블이 유저 이름, 제목, 내용, 날짜로 구성되어 있을 때 유저 이름으로 게시물들을 검색하고 싶다면?
- 이 때는 유저 이름에 대해 인덱스를 설정해 놓는 것이 좋다. 그러면 데이터베이스는 유저 이름으로 정렬된 인덱스 컬럼을 생성해 놓고 조회할 때마다 해당 컬럼을 이용해 빠르게 검색할 수 있다.
이처럼 검색에 자주 이용될 컬럼을 인덱스로 설정하는 것이 좋다.
만약 내용에 대해 인덱스를 설정 한다면?
- 보통 내용 전체를 통째로 쿼리 하지는 않는다. 즉, 이는 자주 발생하는 케이스는 아니기 때문에 굳이 index로 지정할 필요가 없다.
외래키를 검색에 사용하기
위에서 예를 들었던 게시판 테이블을 다시 가져와서 생각해 보자.
게시판 테이블이 User 테이블의 pk를 외래키로 갖는다고 가정하자. 이 때 이 외래키는 user_id이다.
만약 정수로 구성된 user_id를 인덱스로 설정해 놓으면 특정 유저가 작성한 게시물을 조회할 때 해당 유저의 id에 유저가 작성한 게시물들이 포인터로 연결 되어 있기 때문에 해당 유저가 작성한 게시물들을 더 빠르게 조회할 수 있다.
여러 컬럼에 Index 적용하기
테이블에 여러 개의 인덱스를 설정해 놓을 수도 있다.
도서관에서 내가 원하는 책을 찾을 때를 생각해 보자. 보통 각 책장들은 책의 장르 별로 구분이 되어 있으며 해당 책장에 가보면 그 안에서 작가의 이름이 가나다 순으로 정렬 되어 있다. 그렇다면 이 도서관은 장르와 작가명이라는 두 가지 index를 사용하고 있는 것이다.
데이터베이스에서도 도서관에서와 같이 인덱스를 여러 개 설정할 수 있다. 이 때 검색에 많이 사용되는 컬럼들을 인덱스로 지정하면 된다.
여러 개의 인덱스를 지정할 때는 순서가 중요하다.
게시판의 예시를 다시 가져와 생각해 보자. 만약 우리 서비스에 유저가 로그인 했을 때 본인이 작성한 게시물을 조회하는 페이지로 들어왔다고 해보자.
이 경우user_id와 날짜 두 컬럼을 인덱스로 지정하면 된다.
이 때 두 컬럼을 어떤 순서로 인덱스로 설정하는 것이 데이터베이스 성능 향상에 더 도움이 될까?
- (
user_id,날짜)user_id가 먼저 오고 그 다음날짜가 온다면 원하는user_id로 조회한 뒤 그user_id에 대한날짜를 찾게 된다.- 즉, 원하는 첫 번째 인덱스를 통해 원하는 데이터를 발견하면 두 번째 인덱스를 이용할 때는 원하는
user_id가 아닌 데이터들은 모두 조회 대상에서 제거 된다.
- (
날짜,user_id)- 로그인 후 내가 작성한 모든 게시물을 조회해야 하는데
날짜를 첫 번째 인덱스로 사용할 경우 날짜를 특정할 수 없다. 따라서,날짜를 인덱스로 사용할 수 없다. 즉, 인덱스 컬럼에서 원하는 값을 발견한 뒤 첫 번째 인덱스를 기준으로 두 번째 인덱스에서 원하는 값을 찾는 것이 불가능하다. - 이렇게 할 경우 인덱스를 사용하는 의미가 없다. 즉, 두 번째 인덱스에는 로그인 한 유저의 id가 여러 개 발견되기 때문에 속도가 향상되지 않는다.
- 로그인 후 내가 작성한 모든 게시물을 조회해야 하는데
Index를 사용할 경우 Read VS Write 속도 비교
DB에 대한 접근 요청 중 Read보다 Write가 더 많은 경우 index를 사용시 DB의 성능이 오히려 저하될 수 있다.
인덱스도 데이터베이스의 10% 정도에 해당하는 저장 공간을 차지 하는데 write 요청이 빈번한 경우 인덱스 크기가 비대해질 수 있기 때문에 오히려 성능이 저하될 수 있는 것이다.
여러 개의 index를 사용하는 경우를 생각해 보자.
테이블에 새로운 row를 추가할 경우 데이터베이스는 각 인덱스 컬럼에도 역시 새로운 데이터에 대한 명단을 추가해야 한다. index 컬럼 내에 새로운 데이터가 들어갈 위치를 찾아 데이터가 잘 정렬될 수 있도록 해야 한다. 이렇게 새로운 데이터의 인덱스를 추가할 위치를 찾기 위한 과정에서 인덱스 데이터가 많아질수록 데이터베이스의 성능은 떨어지게 되며 이는 CREATE, UPDATE, DELETE 모두에 해당한다.
인덱스는 항상 최신의 상태로 유지되어야 하며 데이터의 추가 및 삭제에 따라 인덱스 역시 추가 및 삭제 되어야 한다. 따라서, 다음의 사항들을 적절히 고려해야 한다.
- 불필요한 인덱스는 아닌가?
- 더이상 기존에 설정했던 인덱스가 사용되지 않는다면 이 인덱스는 제거하는 것이 좋다. - 읽기 요청보다 쓰기 요청이 더 많이 일어나지는 않는가?
- 쓰기 요청이 더 많다면 index를 쓰지 않는 것이 더 나을 수도 있다.
그렇다면, 인덱스는 언제 사용하면 좋을까?
- 데이터 수가 많은 테이블 조회시
- JOIN, WHERE, ORDER BY가 자주 사용되는 테이블
인덱스의 자료구조
인덱스의 자료구조는 B+tree를 이용한다. 먼저, 이와 유사한 B+tree에 대해 알아보자.
B-tree
B-tree는 Binary search tree와 유사하지만, 한 노드 당 자식 노드를 2개 이상 가질 수 있으며 데이터는 정렬 되어 있다는 특징을 보인다.
B-tree는 루트로부터 리프까지의 거리가 일정한 '균형 트리'이기 때문에 어떤 값에 대해서도 같은 시간을 들여 결과를 얻을 수 있는 ‘균일성’을 갖는다. 그렇기 때문에 안정된 성능을 보인다.
그러나, 테이블 갱신의 반복이 이어지면 서서히 균형이 깨지게 되며 자료를 찾는 데 걸리는 시간이 증가하게 되어 성능이 악화 된다. 그렇기 때문에 빠른 성능을 위해 사용하는 인덱스의 자료 구조로는 적합하지 않다.
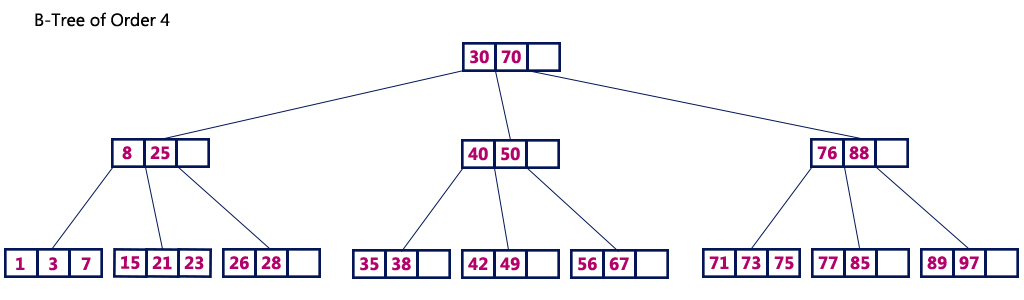
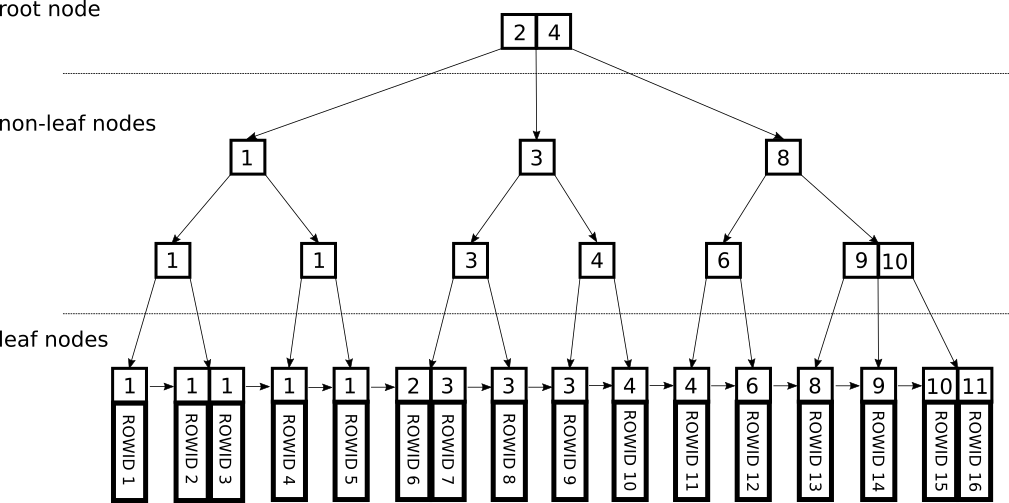
B+tree
오직 리프 노드에만 key와 data를 저장하며 리프 노드는 linked list로 서로 연결되어 있다. 이 때, 브랜치 노드에는 key만 담아두고 data는 담지 않는다. 리프 노드에만 데이터를 담기 때문에 메모리를 더 확보해 많은 key들을 수용할 수 있다.
따라서, B-tree는 하나의 노드에 많은 key들을 담을 수 있어 트리의 높이는 더 낮아지게 되고 이에 따라 cache hit을 높일 수 있다.
풀 스캔시 B-tree는 모든 노드에서 선형 탐색을 해야 하지만 B+tree는 모든 데이터가 리프 노드에 있기 때문에 리프 노드에서만 한 번의 선형 탐색을 하면 된다. 그렇기 때문에 인덱스의 자료구조로 사용 된다.
<용어 정리>
- Cache hit
- CPU에서 요청한 데이터가 캐시에 존재하는 경우를 말한다.
- 이와 반대로 cache miss는 캐시 메모리에 데이터가 존재하지 않는 경우를 의미한다.
- cache miss가 발생하면 데이터 저장소로부터 필요한 캐시를 찾아 캐시 메모리에 로드한다.
참고
