카테고리
1. 자료구조의 공부이유
2. Array
3. Binary Search & Linear Search 알고리즘
자료구조의 공부이유
- 나의 코드를 최적화 하기위해서 필요함.
- 프로그래밍은 다했고 배포를 했는데 어플리케이션이 느릴때
- 코드 퀄리티를 높이기위해 Clean code를 진행할 때
-
알고리즘 (definition)
- 어떠한 액션을 수행하기 위해 컴퓨터가 수행해야하는 것들
실생활 ex) 커피를 마시고 , 양치하고 집을나서는 행동들같은 목적을 달성하기 위한 여러개의 행동들종류) path finder알고리즘, 암호화 알고리즘
key word는 데이터이다.
아마존이나, 구글의 툴을 무료로 사용하는 이유는 그들은 사용자들의 데이터를 사용하며 최적화한다.
그리고 그 데이터들로 needs를 찾아내고 수익을 창출한다.
front 프로그래머는 json이란 못생긴 프런트단 파일을 사용자의 needs에 맞춰서 바꿔내고,
backend프로그래머는 사용자들의 데이터들을 가져와서 전송하고 삭제하고 업데이트하는 역할을한다,
결국 키워드는 data이며 데이터를 최적화하기위해서 data structure 자료구조를 배우는 것이다. array는 언제쓰고 linked lists는 언제 써야할까?, 언제 읽기가 필요하고 검색이 필요한지 자료구조를 배우면 알 수 있다.
Time complexity 만약에 어떤 알고리즘이 5step으로 결과를 만들어낼 수 있다면 20steps 후 결과를 만들어내는 알고리즘보다 훨씬 효율적이다.
Non Volatile(비 휘발성) - 하드디스크에있는 메모리 (hard drive)
Volitile(휘발성) -Ram (컴퓨터를 껐다 키면사라지는 메모리)
ram에 메모리를 접속하는 것이 hard disk메모리에 접속하는 보다 더 빠르다. ram에 저장된 메모리는 주소를 이용해서 찾아갈 수 있다.
Array
- operation num 1 read
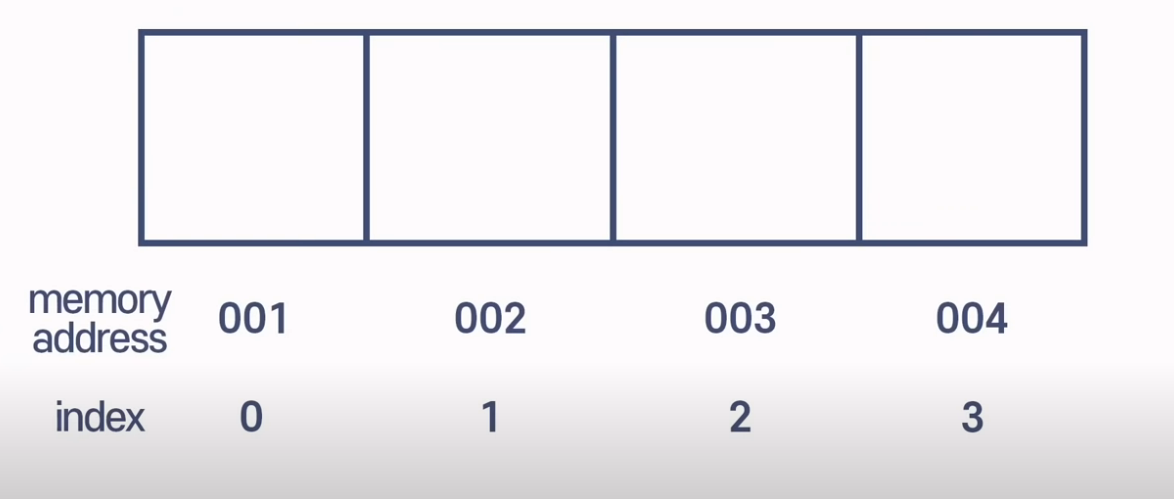
array는 0부터 인덱싱 2번인덱스에 있는 값을 읽고싶다면
컴퓨터에게 2번 인덱스의 값을달라고 요청하면 된다.
이런식으로 컴퓨터가 저장하고 있는 주소를 배열에 인덱스로 정리해서 요청하면 보다 빠르게 데이터를 읽어낼 수 있으므로
많은 자료를 읽을 때는 배열이 좋다. -
operation num 2 searching
특정한 데이터를 찾고싶은데 해당 데이터가 어디에 있는지 몰라서 하나하나 다 찾아봐야한다. ram에 있는 메모리 박스는 다음과 같이 어떤데이터가 있는지 알 수가 없다.
주소가 있어서 접근은 할 수 있지만, 주소로 접근을 직접해야 배열에 어떤 값이 들어있는지 확인할 수 있다. 위와 같이 순차적으로 하나하나 0부터 찾아나가는 것을 linear search라고 말한다. -
operation num 3 insert
만약 어떠한 아이템을 첫배열에 넣고 싶은 경우 다른데이터들을 뒤로 보낸다음에 배열의 첫번째에 아이템을 저장해야함. -
operaion num 4 delete
배열의 중간요소나 첫번째 요소를 삭제할 때는, 해당 요소를 삭제한다음 모든 배열을 한칸씩 앞당겨서 저장해야한다.
만약에 delete나 insert를 해야한다면 마지막 배열의 content를 삭제해야한다. 그래야 빠르게 진행할 수 있다.
Binary Search & Linear Search 알고리즘
둘다 같은 Search 알고리즘에 포함되어있음
* Linear Search 알고리즘
만약 7을 찾고 싶다면
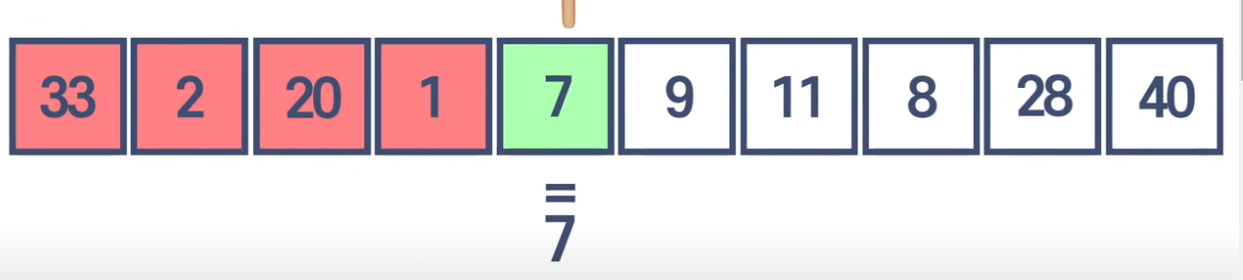
다음과 같이 선형 알고리즘은 순서대로 해당 번호를 찾아나간다.
배열의 수가 길면 길수록 마지막에 넣은 요소를 찾는대 더 오래걸릴 것이다.
이것을 선형복잡도 ( Linear Time Complexity)라고 합니다.
* binary search 알고리즘
sorted Array(정렬된 알고리즘)에서만 사용이 가능하다.
sorted array - 배열이 순서대로 정렬된 상태, 정렬된 상태에서 배열을 검색하는 것은 그렇지 않은 것보다 굉장히 빠르다.
다만 insert나 delete시에는 배열 하나하나에 넣어야하는 수를 비교해서 적합한 위치에 값을 넣거나 삭제해야하기 때문에 시간이 더 걸린다.
bineary search(이진탐색)
0과 1로된 수를 탐색한다는 것을 의미하는 것이 아니라 하나를 둘로 쪼갠다는 뜻을 의미한다. 둘로 (반을)쪼개서 비교하고 왼쪽 오른쪽과 (작다/크다)로 비교해서 한쪽은 배제하므로 약 3번만에 찾는 것이 가능하다.
데이터가 2배가 되어도 필요한 스텝은 2배가 되지않아 빠른 검색이 가능하다.
이진탐색을 하기위해 필요한일 - 배열을 정렬해야한다.
출처-
https://www.youtube.com/watch?v=WjIlVlmmNqs&list=PL7jH19IHhOLMdHvl3KBfFI70r9P0lkJwL&index=4
