[MultiGPU] Docker based Env Setting for MultiGPU and DeepSpeed
Background
SingleGPU를 사용할때와 달리, MultiGPU를 사용하기 위해서는 생각보다 신경써야 할 것이 많다. 특히, DeepSpeed를 사용하기 시작하면 더 많은 에러들을 관찰할 수 있다.
특히, 개인연구자들이 MultiGPU와 DeepSpeed를 동시에 활용하는 상황은 잘 없기에 이에 대한 해결책을 찾기도 쉽지 않다. 일일이 문서를 찾아보거나 어느 인도 프로그래머의 유튜브를 찾아보는 방법 밖에 없는 경우도 있다.
기록과 다른 분들의 시행 착오를 줄이기 위해 필자가 설정하여 성공한 방법을 공유한다. 다만, 개인별 GPU 환경이나 라이브러리 버전에 따라 달라질 수 있다는 점은 유의해주시길 바란다.
Env
- A100 8대
- Ubuntu 22
Docker 환경 설정
Docker를 사용하면 환경 설정이 그나마 편해진다. 하지만 아무 Docker Image를 사용한다고 해서 Nvidia GPU 환경에서 MultiGPU를 사용할 수 있는 것은 아니다.
가급적이면 Nvidia에서 제공해주는 공식 Docker Image를 사용하자. 아무래도 최신 버전까지 관리해주니 믿고 쓰기 좋다. Docker HUb에서 찾아볼 수 있다 (https://hub.docker.com/r/nvidia/cuda/tags).
물론 해당 도커를 사용하기 전에 로컬에서 nvidia-smi, nvcc --version 등의 명령어가 작동하는 상태여야 한다. 이 부분은 본 문서의 범위를 벗어나므로 따로 서술하진 않겠다.
일단 이미지를 내려받아보자. 여러분은 위 링크에서 최신 버전을 다운받으면 된다.
docker pull nvidia/cuda:12.2.0-devel-ubuntu20.04다음으로, 도커 환경을 실행할 것인데, --shm-size=10g 와 --ulimit memlock=-1 두 가지 옵션을 추가해야 한다.
먼저, --shm-size=10g 을 설정해줘야 하는 이유는 아래 reference에 있는 링크에서 찾아볼 수 있는데, 핵심은 다음의 설명에 나와있다. 즉, 도커의 Shared Memory 설정을 늘려주는 것인데, 데이터가 작을때는 괜찮지만 대량의 데이터를 다룰 경우에는 반드시 설정해주어야 한다.

다음으로 --ulimit memlock=-1 의 경우에는 아래 글을 읽어보도록 하자.
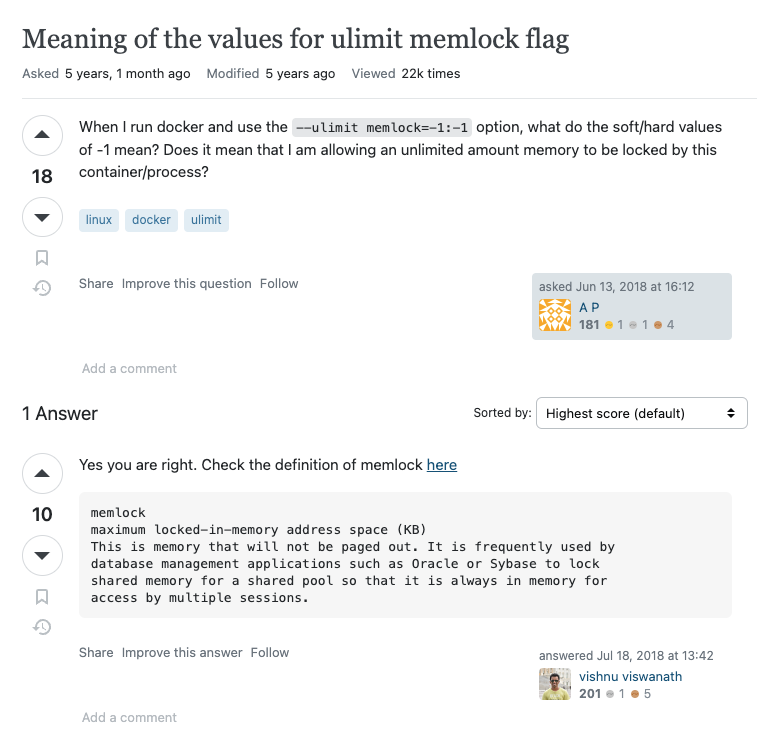
그렇다면 해당 설정을 반영해서 Docker image를 run 해보자. 아래는 실행 예시이다. [The name what you want]는 원하는 이미지의 이름을 넣으면 되고, [USER FOLDER PATH]는 자신이 연결하고 싶은 로컬 폴더의 경로를 써주면 된다.
docker run -d --gpus all --ipc=host --shm-size=10g --ulimit memlock=-1 --hostname [The name what you want] --name [The name what you want] -p 9060:22 -v [USER FOLDER PATH]:/workspace -it nvidia/cuda:12.2.0-devel-ubuntu20.04다음으로 Docker가 제대로 실행되고 있는지 docker ps 명령어로 확인하고, 이상이 없다면 docker를 실행시켜보자.
docker exec -it [The name what you want] /bin/bashInstall Libraries
사실 Docker Image를 만들어서 쓰면 되지만, 이번에는 직접 하나하나 설치해보도록 하자. 아래의 명령어를 순서대로 넣으면 된다. 원하는 설정이 있다면 변경해서 설치해도 괜찮다.
Basic Libraries 설치
$ apt update && sudo apt upgrade -y
$ apt install software-properties-common -y
$ add-apt-repository ppa:deadsnakes/ppa
$ apt install python3.10 python3.10-dev -y
$ alias python='python3.10'
$ apt install python3.10-distutils -y
# curl 설치
$ apt install curl -y
# pip 설치
$ curl -sS https://bootstrap.pypa.io/get-pip.py | python3.10
# pytorch 설치
# pytorch는 각자 환경에 맞게 pytorch 공식 사이트에서 다운받도록 하자.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118DeepSpeed 설치
DeepSpeed를 설치하기 위해서는 두 가지 방법이 있는데, 간단하게 pip install deepspeed로 설치하는 방법과 git repository에서 최신버전을 설치하는 방법이 있다. 일반적으로는 pip으로 설치해도 큰 문제가 없겠지만, 만약 설치가 제대로 되지 않는다면 아래의 명령어로 git에서 직접 설치하는 것을 추천한다.
git에서 설치하는 방법은 Wrtn의 Seoyeon님께서 블로그에 올리신 자료를 참고했다.
# Docker 환경에 git이 설치되어있지 않으므로
$ apt install git -y
# TORCH_CUDA_ARCH_LIST 설정에 입력할 값을 찾기 위해 아래 명령어 입력
$ CUDA_VISIBLE_DEVICES=0 python -c "import torch; print(torch.cuda.get_device_capability())"
# A100은 (8, 0), A6000은 (8, 6)이 나올듯
=> (8,0)
# build를 위해 cmake 설치
$ apt-get install cmake -y
# DeepSpeed repo clone
$ git clone https://github.com/microsoft/DeepSpeed/
$ cd DeepSpeed
$ rm -rf build
# 위에서 나온 TORCH_CUDA_ARCH_LIST의 값에 따라 설정
# A100
$ TORCH_CUDA_ARCH_LIST="8.0" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \
--global-option="build_ext" --global-option="-j8" --no-cache -v \
--disable-pip-version-check 2>&1 | tee build.log
# A6000
$ TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \
--global-option="build_ext" --global-option="-j8" --no-cache -v \
--disable-pip-version-check 2>&1 | tee build.log
Code Base
코드는 직접 Accelerate로 만들어도 되지만, Huggingface Transformers에 있는 모델을 활용할 경우에는 코드가 표준화되어있으므로 굳이 시간을 들일 필요가 없다.
코드 베이스는 다양하지만 가장 추천하는건 Huggingface 에서 제공하는 공식 예시 코드이다. 아래 코드를 커스텀해서 사용하면 잘 작동할 것이다. 다만, MultiGPU 환경에서 약간의 이슈가 있었는데, 해당 이슈에 대한 내용은 필자가 작성한 글을 참고하면 해결할 수 있을 것이다.
다만, 본 글에서 적은 방식은 필자의 환경에 최적화된 방식이므로 다른 환경에서는 다른 이슈가 발생할 수 있다. 이때는 가급적이면 공식문서를 참고해서 해결하고 해당 내용을 웹 상에 공유해주면 바람직할 것이다.
Reference
- https://stackoverflow.com/questions/69693950/error-some-nccl-operations-have-failed-or-timed-out
- https://unix.stackexchange.com/questions/449595/meaning-of-the-values-for-ulimit-memlock-flag
- https://velog.io/@seoyeon96/DeepSpeed%EB%A1%9C-%ED%81%B0-%EB%AA%A8%EB%8D%B8-%ED%8A%9C%EB%8B%9D%ED%95%98%EA%B8%B0
