A100 Node 환경설정(1) - Nvidia Driver, CUDA, 환경변수 설정, CUDA Toolkit 설치
들어가며
딥러닝 개발을 하면서 가장 많이 고통(?)받는 것은 아마 적절한 환경 세팅일 것이다.
필자의 경우는 Deepspeed를 사용할때 이러한 현상을 가장 많이 겪었는데 대부분의 경우에는 라이브러리 버전과 의존성 문제이거나, 설치된 환경에서의 문제가 가장 컸다. 특히, CUDA 버전이 너무 높아서 Pytorch Stable 버전과의 호환성이 떨어져서, 최신의 Pytorch를 써야한다거나(안정성이 떨어진다..), Deepspeed를 활용해서 학습할때 분명히 가능한 환경임에도 OOM이 된다거나 하는 등의 알 수 없는 에러가 발생하는 경우들이 있었다.
이번에 HGX A100 8-GPU 노드에서 Deepspeed로 인해 고통받다가 환경을 재설정하면서 알게 된 점을 기록해본다.
환경
- OS: Ubuntu 20.04
- GPU: A100
- Node: HGX A100
CUDA 삭제 (재설치 시)
이번 절은 JEO96님의 글을 참고하였다. 기존에 설치된 CUDA를 재설치할 목적이라면 이 절차를 거쳐야 한다. 만약 새롭게 설치하는 것이라면 다음 차례로 넘어가면 된다.
먼저, 기존에 있던 cuda 관련 파일을 모두 삭제한다. 아래 명령어를 활용하면 된다.
sudo apt-get --purge -y remove 'cuda*'
sudo apt-get --purge -y remove 'nvidia*'
sudo apt-get autoremove --purge cuda
# cudnn remove
cd /usr/local/
sudo rm -rf cuda*그리고 만약 CUDA를 이전에 설정했다면, 설정파일인 bashrc에 환경 변수를 추가해두었을 것이다. bashrc에서 관련 설정도 제거하도록 하자. bashrc 파일을 수정하기 위해서는 nano나 vim을 활용하면 된다.
# bashrc 파일에 들어가기
nano ~/.bashrc
# 아래 내용 삭제
export PATH=/usr/local/cuda/bin:${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
# 변경된 내용 저장 후 다시 처음으로 돌아와서 설정 변경 적용
source ~/.bashrcnouveau 비활성화
다음으로 nouveau를 비활성화한다. nouveau가 정확하게 하는 역할을 이해하지는 못했지만, Lee-Jaewon님에 따르면 Nvidia Toolkit과 충돌이 날 수 있다고 한다.

아래 명령어를 입력하면 된다.
# 삭제
sudo bash -c "echo blacklist nouveau > /etc/modprobe.d/blacklist-nvidia-nouveau.conf"
sudo bash -c "echo options nouveau modeset=0 >> /etc/modprobe.d/blacklist-nvidia-nouveau.conf"
# 비활성화 확인
cat /etc/modprobe.d/blacklist-nvidia-nouveau.conf
# 아래와 같이 출력되면 정상
> blacklist nouveau
> options nouveau modeset=0다음으로 리부트를 해준다.
sudo reboot컴퓨터가 켜지면 커널 업데이트를 한다.
sudo update-initramfs -uNvidia driver 설치
해당 절은 PixelStudio님의 글을 참고하였다.
먼저, 그래픽카드 정보와 그에 매칭되는 드라이버 버전을 확인해보자.
# 그래픽카드 및 설치 가능한 드라이버 확인
ubuntu-drivers devices아래와 같이 해당 그래픽카드에서 설치할 수 있는 드라이버들을 보여준다. 그 중에서 recommended라고 설치된 부분을 기억하자.
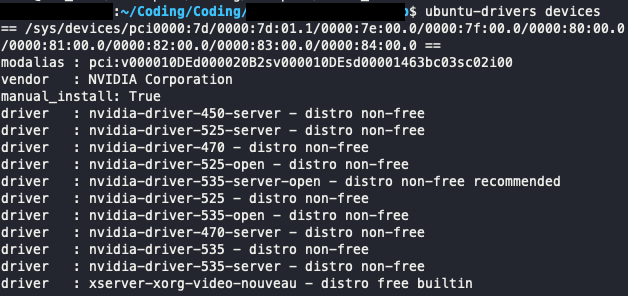
드라이버를 설치하는 옵션은 자동과 수동이 있는데, 특별한 목적이 없다면 recommended 된 버전을 자동으로 설치하자.
sudo ubuntu-drivers autoinstall그리고 재부팅을 한다.
sudo rebootCUDA 설치
다음으로 CUDA Toolkit을 설치한다. CUDA 설치는 NVIDIA에서 지원해주는 CUDA Toolkit Archive (아래 링크)에서 설치하면 된다.
https://developer.nvidia.com/cuda-toolkit-archive
아래 화면에서 원하는 버전의 CUDA Toolkit을 설치하면 되는데, 필자의 경우에는 11.8.0 버전을 선택했다.
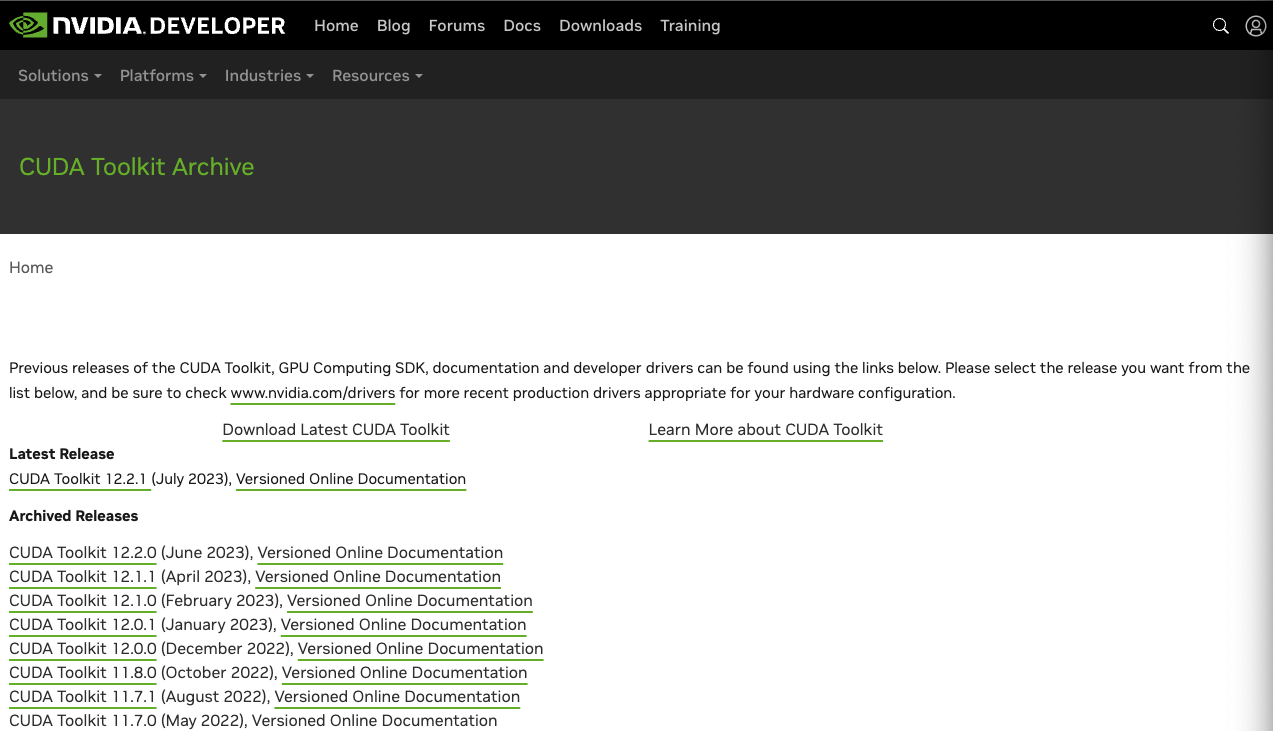
이유는 11.8.0 버전이 PyTorch Stable (2.0.1) 버전과 호환되는 버전이기 때문이다. (이후에는 변경될 수 있음)

다시 돌아와서, 11.8.0 버전을 클릭하면 아래와 같이 여러 선택지가 나온다.
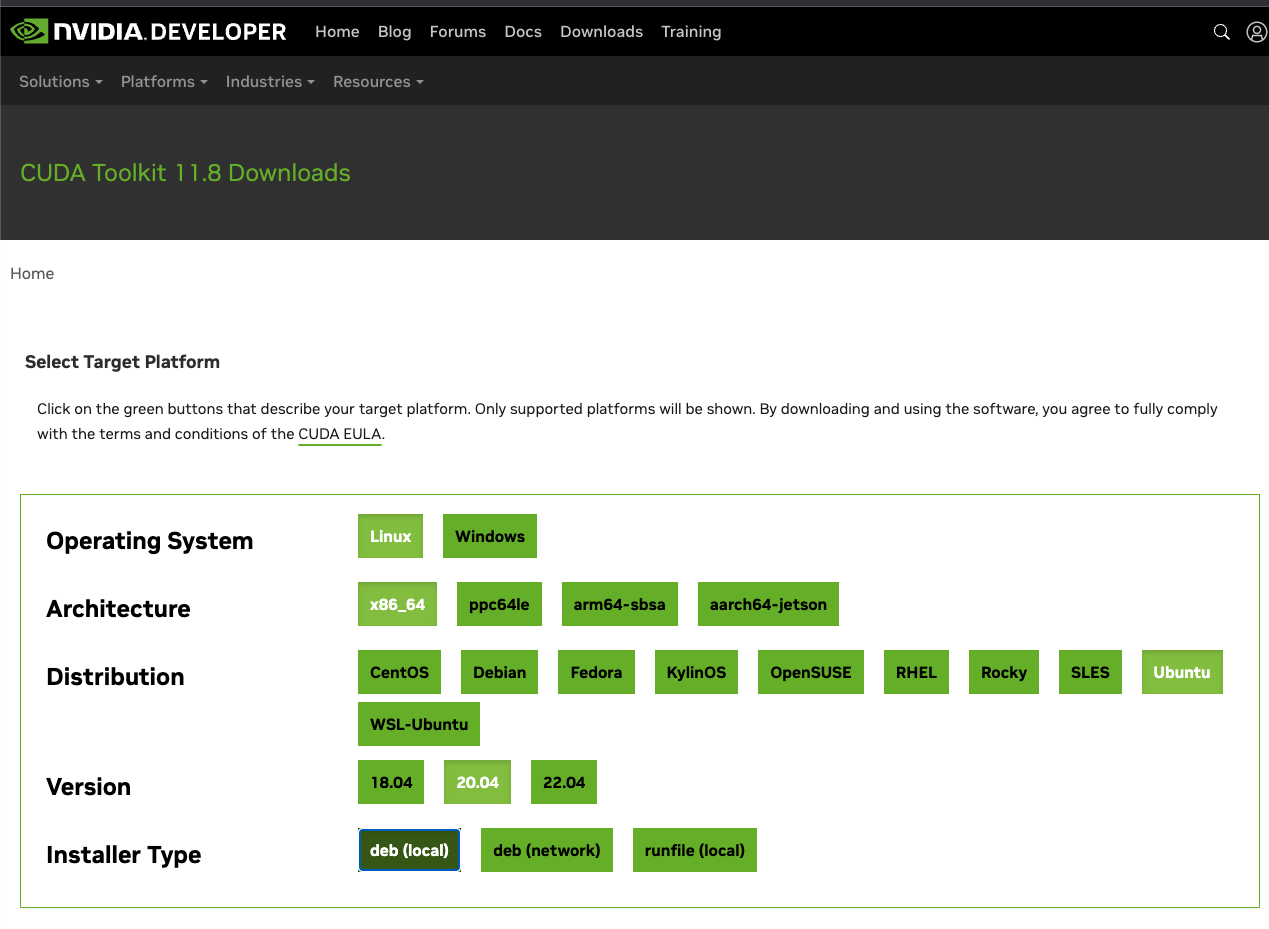
이때 자신의 OS, Architecture 등을 선택하면 설치할 수 있는 명령어가 나온다. 나온 명령어를 한줄씩 사용해서 설치하면 된다. 아래 명령어는 환경에 따라서 다를 수 있으므로 직접 링크에 들어가서 복사하면서 붙여넣길 권장한다.
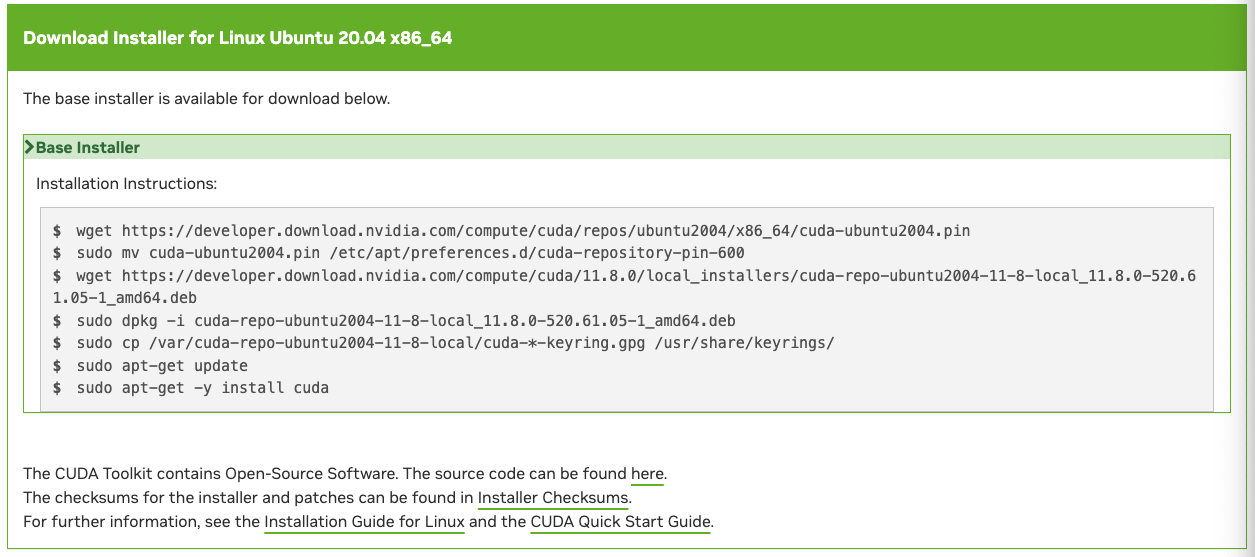
다시 재부팅을 하도록 하자.
sudo reboot경로와 환경변수 설정
bashrc에 경로와 환경변수를 설정해줄 것이다. 먼저 nano나 vim을 활용하여 bashrc로 이동한다.
nano ~/.bashrcbashrc의 가장 아랫 부분에 아래 경로와 환경변수를 입력한다. 아래는 cuda-11.8 버전일 경우의 설정이다. 만약 버전이 바뀐다면 바뀐 버전명에 맞게 숫자를 변경하도록 하자.
# cuda-11.8버전의 경우
export PATH=$PATH:/usr/local/cuda-11.8/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.8/lib64
export CUDADIR=/usr/local/cuda-11.8CUDA Toolkit 설치
아까 cuda toolkit은 설치한 것이 아닌가요? 라고 물어볼 수 있지만 추가로 아래 명령어를 입력해서 설치하도록 하자.
sudo apt install nvidia-cuda-toolkit설치 확인
설치가 끝났다면, 설치가 되었는지 확인해보자.
nvidia-smi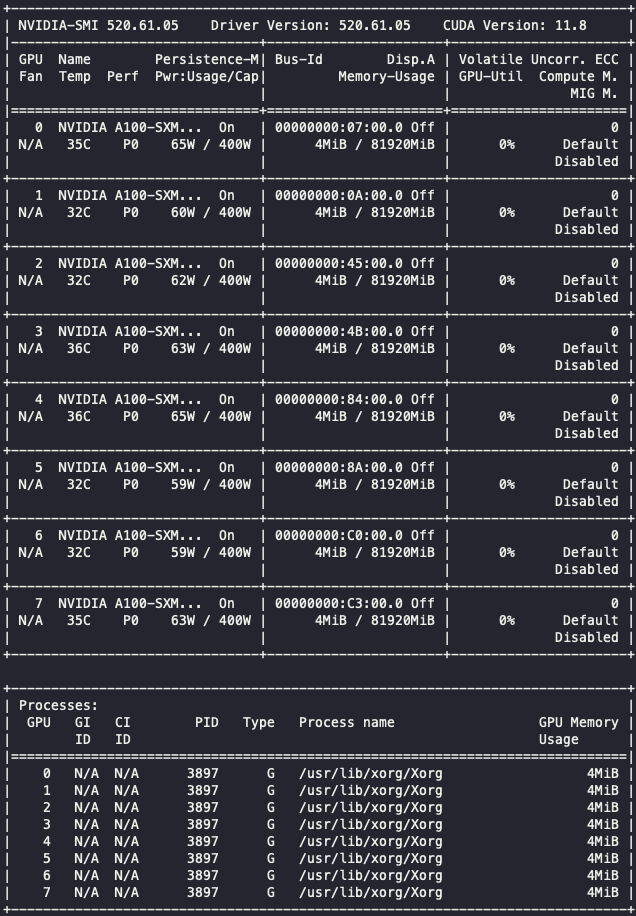
nvcc --version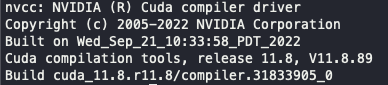
이렇게 아름다운(?) 출력이 나오면 첫 단계는 완료되었다고 할 수 있다.
Reference
- JEO96님의 'Ubuntu 20.04 CUDA 재설치'
https://jeo96.tistory.com/entry/Ubuntu-2004-CUDA-%EC%9E%AC%EC%84%A4%EC%B9%98 - Lee-Jaewon님의 Nouveau 관련 글
https://lee-jaewon.github.io/ubuntu/CUDA/ - PixelStudio님의 'Nvidia드라이버 설치하기'
https://pstudio411.tistory.com/entry/Ubuntu-2004-Nvidia%EB%93%9C%EB%9D%BC%EC%9D%B4%EB%B2%84-%EC%84%A4%EC%B9%98%ED%95%98%EA%B8%B0
