임선집 강사의 머신러닝 강의를 듣고..

종류
- 지도 학습(Supervised)
- 비지도 학습 (Pattern Discovery)
- 강화 학습 ex) 알파고, 로봇 청소기
- 숫자
- 텍스트
- 이미지
--> Pytorch의 중요성이 높아짐
회귀
연속된 수치에 대해서
분류
과적합 과소적합
정확도
MSE(mean square error 평균 제곱 오차)
평균을 기준으로 +- -> 오차의 제곱을 mean square error로 부르고
**미분가능 -> 더 많이 사용
MAE(mean Absolute error)
큰 오차를 줄이기 위해서 사용하는
미분은 불가능 -> 덜 사용함
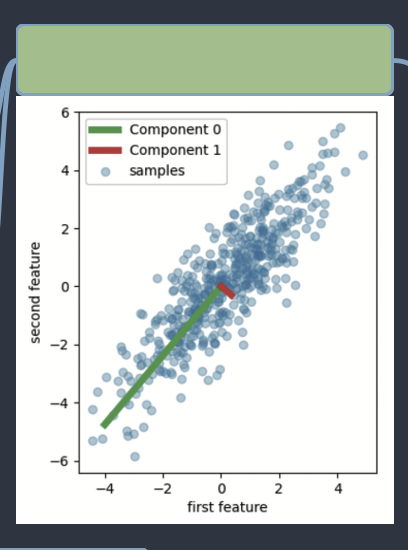
주성분 분석(Principal Component Analysis)과 차원축소
PCA는 고차원 데이터의 주요 특징을 추출하고, 데이터를 더 잘 이해하기 위해 사용PCA는 데이터의 분산을 최대한 보존하면서 데이터를 새로운 좌표계로 변환하여 저차원 표현을 만듬
새로운 좌표계의 축은 원본 데이터의 주성분
모델의 설명력(적합성)을 표현함.
--> 이부분은 다시 공부가 필요함
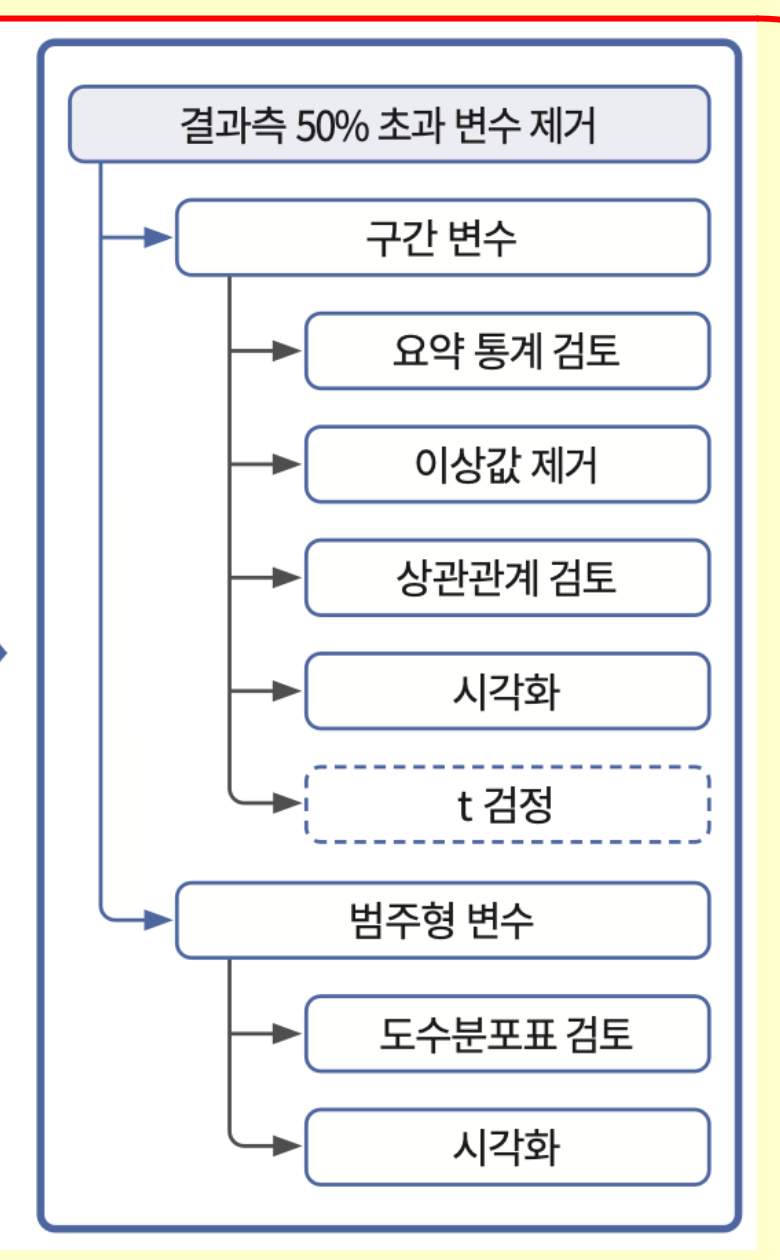
머신러닝에서 해야 할 것
R^2(mean square error 평균 제곱 오차)
(평균 - 피팅된선) / 평균
SSR / SST
SSE(sum squares Explained) 개별 예측y의 제곱합
SST(sum squares Total) 개별 y의 제곱합
SSR(sum squares Regression) 잔차의 제곱합
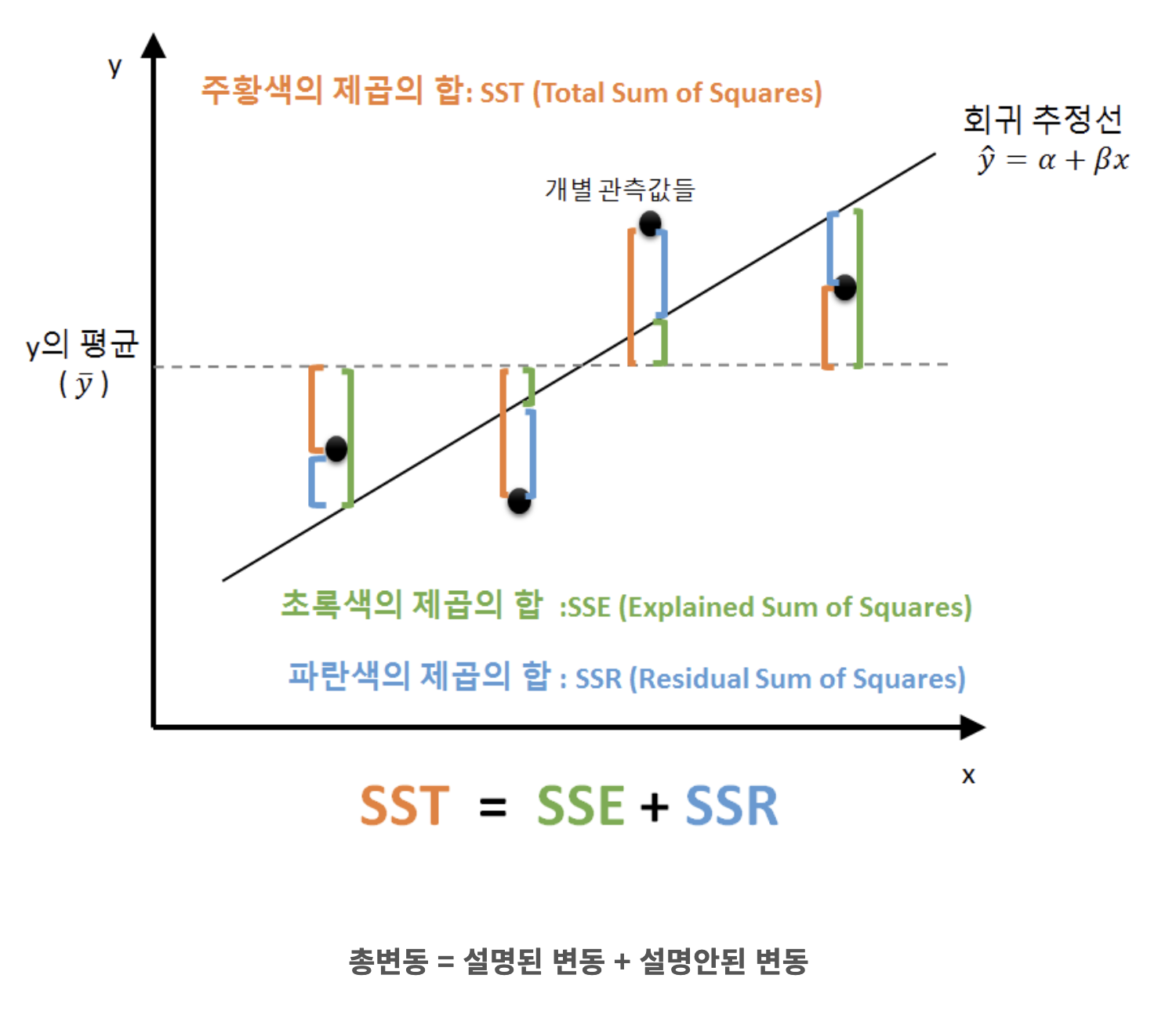
--> 추가 공부 필요..
standardization(데이터 스케일 표준화)
평균이 0이고, 표준편차가 1인 정규분포(gausiuan distribution)꼴
Roc 곡선
++ -> accuracy
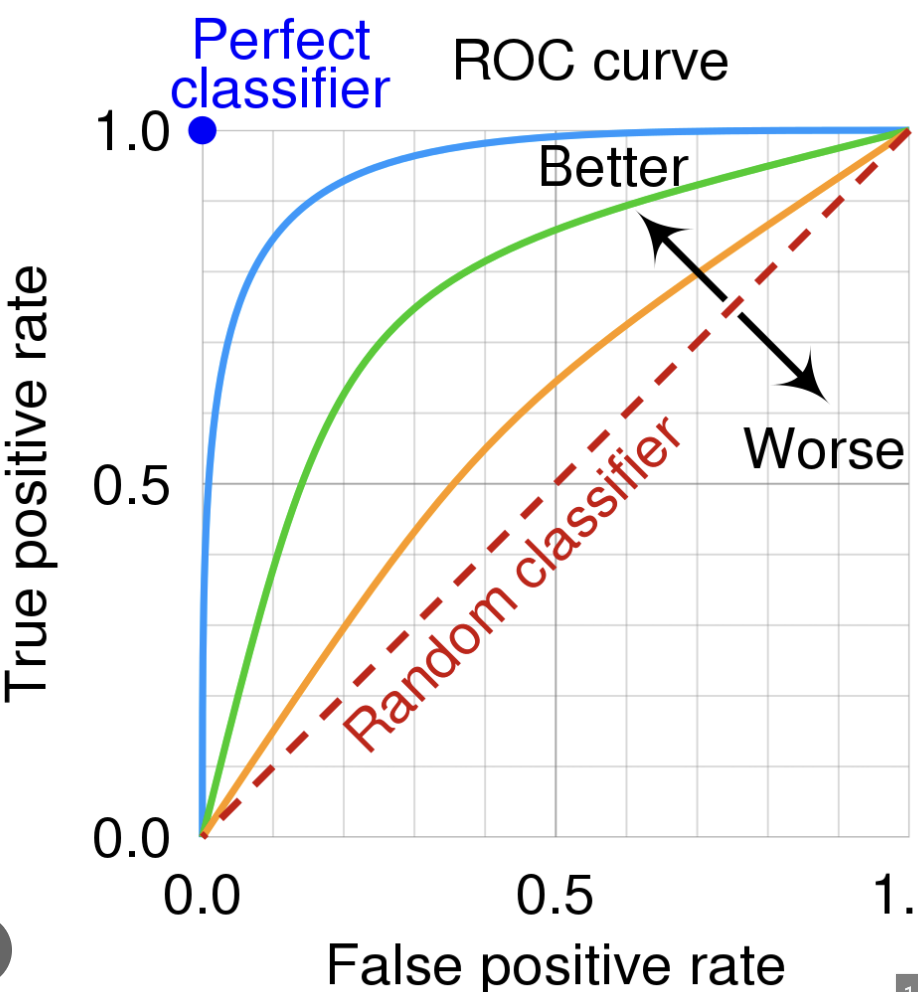
연속변수, 이상변수 타겟에서의 모델 판단
분류 -> Odds ratio
회귀 -> R^2

zigzag
덕분에 좋은 정보 얻어갑니다, 감사합니다.