정규화
데이터 모델링은 2차원 표에 어떤 데이터를 어떻게 담는 것이 최적일지 고민하는 작업이다.
정규화(Normalization)란, 속성들의 종속성을 분석해서 하나의 종속성이 하나의 표(혹은, Relation)로 관리되도록 분해하는 과정이다.
데이터가 독립적이지 않고 중복으로 관리되어 데이터 간의 종속성에 계속 영향을 받는다면, 데이터 이상 현상(data anomaly)이 발생한다. 이로 인해 표에 삽입, 수정, 삭제 등의 작업을 할 때 의도하지 않은 다른 데이터에 문제가 발생한다.
정규화를 하면, 하나의 종속성이 하나의 표로 분리되므로 그 성격이 명확해진다. 또한 중복을 없애 데이터 이상 현상이 최소화되고, 데이터 무결성이 극대화된 구조가 된다.
함수 종속
함수 종속(functional dependency)는 하나의 집합(relation) 안에 존재하는 속성 사이의 연관 관계이다. 집합 내 속성 A가 속성 B의 값을 유일하게 식별하는 결정자(determinant)라면, B는 A에 함수적으로 종속된다. 하나의 집합에는 여러 종속 구조가 공존할 수 있다.
제1 정규화
모든 속성이 값을 반드시 하나만 가져야 한다. 어떤 속성이 값을 여러 개 가지고 있거나, 물리적으로는 하나만 갖지만 유사한 형태의 반복 속성이 존재한다면 Basis parent로부터 별도의 엔티티로 분리해야 한다.
제1 정규화로 생성된 집합은 자식(child)가 된다.
제2 정규화
모든 속성이 반드시 주 식별자 전부에 종속되어야 한다. 주 식별자 일부에만 종속될 경우, 해당 종속성을 별도 엔티티로 분리해야 한다. 주 식별자는 집합 내 속성의 결정자로서, 집합의 성격을 규정한다.
제2 정규화로 생성된 집합은 부모(parent)가 된다.
제3 정규화
주 식별자가 아닌 모든 속성이 상호 종속 관계여서는 안 된다. 즉, 일반 속성인 속성1과 속성2 사이에 종속성이 발생한다면, 이들은 별도 엔티티로 분리되어야 한다.
정규화의 의의
정규화된 모델은 다음과 같은 특징을 가진다.
- 속성 간의 종속성을 기준으로 성격이 유사한 속성들은 모이고, 관계없는 속성들은 분리된다. 속성들이 자연스럽게 자기 자리를 찾게 되면서 데이터 집합의 범주화가 이루어진다.
- 하나의 주제로 집약된 데이터 구조, 제대로 된 엔티티가 도출된다. 정규화를 통해 함수 송속을 없애고 밀접한 속성을 하나의 표에 집약시키면, 데이터 응집도는 높고 결합도는 낮게 분리된다.
- 데이터 중복이 최소화된 효율적이고 구조화된 모델이 나온다. 중복에 따른 이상 현상이 사라지며, 저장 용량 상의 이익도 생긴다.
- 데이터 간의 종속성을 분석하기 떄문에, 엔티티의 정체성을 가장 잘 표현하는 엔티티명과 주 식별자가 정확히 도출된다.주 식별자는 인스턴스를 구분하는 기준이므로, 집합의 개체 발생 규칙도 검증되어 더 정확해진다.
- 엔티티가 명확하고 정확해졌기 때문에, 업무 변경에 따른 확장성이 좋아진다.
- 데이터를 최적의 상태로 담게 된다. 데이터 중복이 최소화되어, 데이터 무결성을 극대화한다.
- 정규화된 모델은 그렇지 않은 모델에 비해 대부분 성능이 좋다.
정규화 = 성능 저하 ?
정규화를 하면 테이블이 늘어나 join이 증가하여 성능이 저하된다는 견해가 있다.
예를 들어, 다음과 같은 두 가지 테이블 구조가 있다고 가정하자.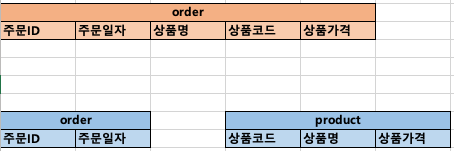
주황색 order 테이블은 정규화를 적용하지 않아 주문 ID와 상품 코드 중 상품 코드에 부분 종속된 속성이 존재한다. 이를 정규화하여 파란색 order, product 두 개로 분리했다.
만약 '특정일시 이전의 주문건을 조회'하려 할 때, 정규화되지 않은 주황색 테이블에서는 불필요하게 상품 관련 속성도 함꼐 읽어야 한다. 하지만 파란색 테이블들에서는, 왼쪽의 order 테이블만 읽으면 되므로 조건에 맞는 데이터를 더욱 빠르게 처리할 수 있다.
반면, 상품코드가 'A001'인 상품 정보를 주문일자와 함께 조회하는 경우, 반드시 join이 발생한다. 하지만 join의 기준인 FK가 인덱스로 지정되어 있다면, 성능상의 차이는 미미할 것이다.
이와 같이, 정규화의 결과로 테이블 수와 조인의 양이 늘어난다고 해서 반드시 성능이 저하되는 것은 아님을 알 수 있다.
데이터베이스는 데이터를 블록 단위(혹은 페이지 단위)로 읽고 쓴다. 하나의 블록에는 다수의 행이 포함된다. 블록은 IO의 최소 단위이다. 따라서, SQL 최적화는 더 많은 레코드를 불러오는 것보다 더 많은 블록을 읽어오는 것을 목표로 한다.
만약 정규화가 되지 않은 상태라면, 하나의 블록에 들어갈 수 있는 레코드 수는 제한될 것이다. 예를 들어 블록 하나가 8k이고 레코드 하나가 2k라면, 한 블록 당 레코드는 4개만 들어갈 수 있다. 그러나 정규화를 통해 레코드 크기가 하나당 1k만 줄어든다면, 블록 하나가 수용할 수 있는 레코드는 두 배가 된다. 이는 정규화가 IO의 대상이 되는 블록 수를 줄여줄 수 있음을 의미한다.
또한, 한 블록에 더 많은 개체가 존재하면 메모리에 한 번 올라간 블록이 재사용될 확률도 그만큼 높아진다. 즉, 적중률(=hit ratio)이 높아진다.
이와 같이, 모든 속성(컬럼)이 한 테이블에 담겨 있다면 조회하려는 속성의 많고 적음에 상관 없이 항상 전체 블록을 읽어야 하지만, 정규화가 잘 되어 있다면 훨씬 적은 블록을 읽고도 원하는 결과를 얻을 수 있다.
JOIN으로 인해 성능이 느려지는 경우가 있다면, 다음 경우가 있을 수 있다. 하지만 대부분의 경우 정규화는 더 뛰어난 성능을 제공한다.
1. 인덱스가 없는 경우
2. 조인 연결 고리 이상(조인 연결 고리에 해당하는 두 테이블의 컬럼 중 한 곳이 인덱스가 없거나, 인덱스가 있음에도 컬럼 변형 등으로 인해 옵티마이저가 인덱스를 사용할 수 없는 상황)
