엔티티 모델링의 어려움은 문제 영역의 복잡도로부터 기인한다. 업무의 복잡도가 높다는 것은, 현실 세계에서 문제 영역을 정확하게 정의할 수 없다는 것을 의미한다. 프로젝트의 요구사항이 이 점을 잘 보여준다. 의뢰를 받는 사람 입장에서 요구사항은 반드시 변경되며(그것도 여러 번, 어쩌면 마감 직전까지), 따라서 완벽히 통제할 수 없다. 의뢰인인 고객조차 문제 영역을 정확히 모두 아는 것은 불가능하다. 그래서 요구사항은 늘 모호한 것이다.
이러한 복잡도 문제를 해결하기 위해 분류가 필요하다. 문제 영역의 요소들을 적절한 기준으로 묶고 나눠 복잡하게 얽혀있는 요소들을 정리한다. 하지만, 절대적인 분류 기준은 있을 수 없다. 분류의 기준은 업무 도메인과 상황에 따라 다르고, 애매하기 때문이다.
데이터 모델링에서 분류의 핵심적인 기준은 정규화이다. 업무 도메인을 정규화하여 변하는 것과 변하지 않는 것으로 나눠야 한다. 특히, 변하지 않는 것에 집중하고 이를 가장 앞에 내세워야 한다. 은행의 예를 들자면, 은행에는 각양각색의 예금 상품을 만들어 판다. 어떤 상품은 특정 조건을 달성한 고객들에게 상품을 거는 이벤트를 진행되기도 한다. 어떤 예금 상품은 특정 고객군만이 신청할 수 있다. 그러나 어떤 예금이든 정해진 만기일이 있고, 이자를 지급해야 한다는 사실은 변하지 않는다. 따라서 모델링에 가장 중심이 되어야 하는 부분은 만기와 이자여야 한다.
요약하자면, 데이터 모델링에서는 결국 분류와 묶음의 과정이 필요하다는 것이다.
서브타입(부분집합)
서브타입은 분류의 결과물이다. 분류의 결과로 나뉜 유형, 즉 전체와 부분을 명시적으로 구분하여 표현하는 방식이다. 기준과 규칙을 가지고 복잡한 대상을 분류함으로써, 그 대상을 구성하는 요소의 실체와 요소 사이의 차이점이나 동질성 등을 이해할 수 있게 되는 것이다. 따라서, 서브타입을 보면 요소 간의 차이점을 알기 쉽다.
서브타입이 잘 도출되면 전체집합과 부분집합의 관계를 명확히 알 수 있을 뿐 만 아니라, 서브타입 주변의 관계도 명확히 표현할 수 있다.
서브타입과 E-R 패턴
E-R 패턴은 서브타입을 중심으로 집합을 나누거나 묶는 데이터 모델 유형이다. 여기서 E와 R은 엔티티(Entiity)와 엔티티들 사이의 관계(Relation)를 의미한다.
패턴 1: 집합의 배타적 나눔
집합의 요소가 갖는 값의 범위를 배타적(exclusive)으로 나눈다. 직원의 직급이 부장, 과장, 사원 3가지 유형이 존재한다는 가정 하에 데이터 집합을 값의 범주를 기준으로 나눠 보자. 논리적으로, 직급이 부장이면서 과장이거나, 사원이면서 부장인 경우는 존재할 수 없으니 값의 범위를 배타적으로 정할 수 있다. 이를 표현하면 다음과 같다.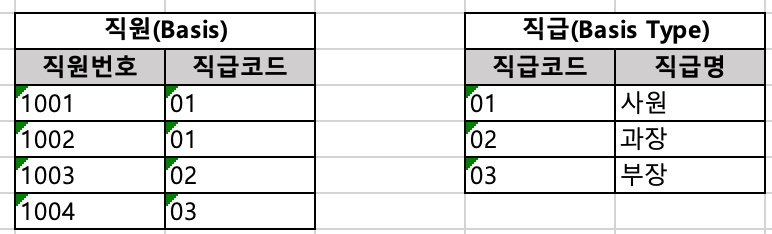
위에서 직급과 같이 코드 형태로 표현되는 속성은 서브타입 이다. 이와 같은 배타적인 속성값 유형을 기준으로 집합을 나눌 수 있다.
배타성은 같은 차원에서만 고려 대상이며, 서로 차원이 다르면 이러한 배타성을 따질 수 없다. 예를 들어, 부장이 보직간부와 비보직간부로 나뉜다면, 이는 부장 직급에 종속된 것으로 이해해야지 직원에 종속된 것으로 이해하면 안 된다. 직급과 보직은 서로 완전히 다른 차원이다.
패턴 2: 집합의 중첩(비배타적) 나눔
집합 간이 중첩적(inclusive)인 나눔에 의해 만들어지는 두 번째 E-R패턴이 있다.
패턴 1의 직급과 달리, 역할에 따라 분류해보면 나뉜 집합 간에 중첨이 생기는 경우가 있다. 예를 들어 프로젝트 이해관계자의 역할을 PM, PL, 설계/개발자로 간단히 나눌 경우 PL 중 설계/개발을 함께 수행하는 경우가 있다. 이러한 분류 데이터는 다음과 같은 구조료 표현되어야 한다.

패턴 3: 배열 형태(컬럼의 중복)의 값
특정 속성이 여러 개의 값을 가질 때, 그 속성을 분리하여 하위 엔티티로 분리하여 관리하는 패턴이다. 이는 제1 정규화의 결과물에 해당한다. 물리적으로는 한 속성에 하나의 값만 관리하지만 논리적으로는 같은 성격의 데이터를 여러 속성으로 관리하는 경우 이러한 형태로 관리해야 한다. 일반적으로, 다중값 관리를 위해 분리된 엔티티의 주 식별자는 부모 엔티티로부터 상속받은 식별자에 일련번호를 추가한 형태를 보인다.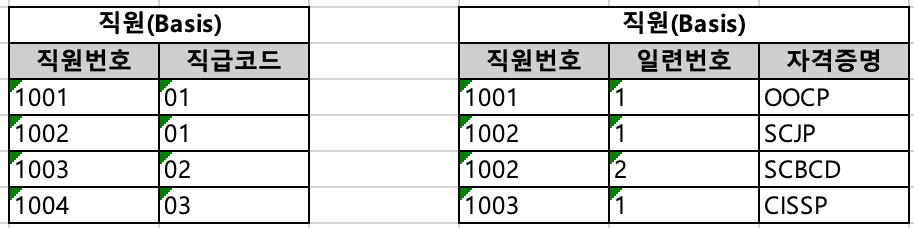
패턴 4: 계층적 형태의 값
값에 상/하위관계가 존재하는 패턴이다. 대표적인 것이 직원의 소속 부서 정보다. 이 경우, 부서 정보 값을 인스턴스로 관리하는 부서 엔티티를 분리하여 상위로 두고, 부서의 계층구조를 표현할 수 있도록 순환(recursive)관계를 설정한다.

패턴 5: 롤업 형태의 값
속성값에 양방향 관계가 존재하는 경우다. 양방향을 풀면 기준(Parent)과 대상(Child)의 2개의 관계가 있는 모델로 표현되어, 결국 값이 롤업(통합, rollup)된 형태의 모델이 된다.

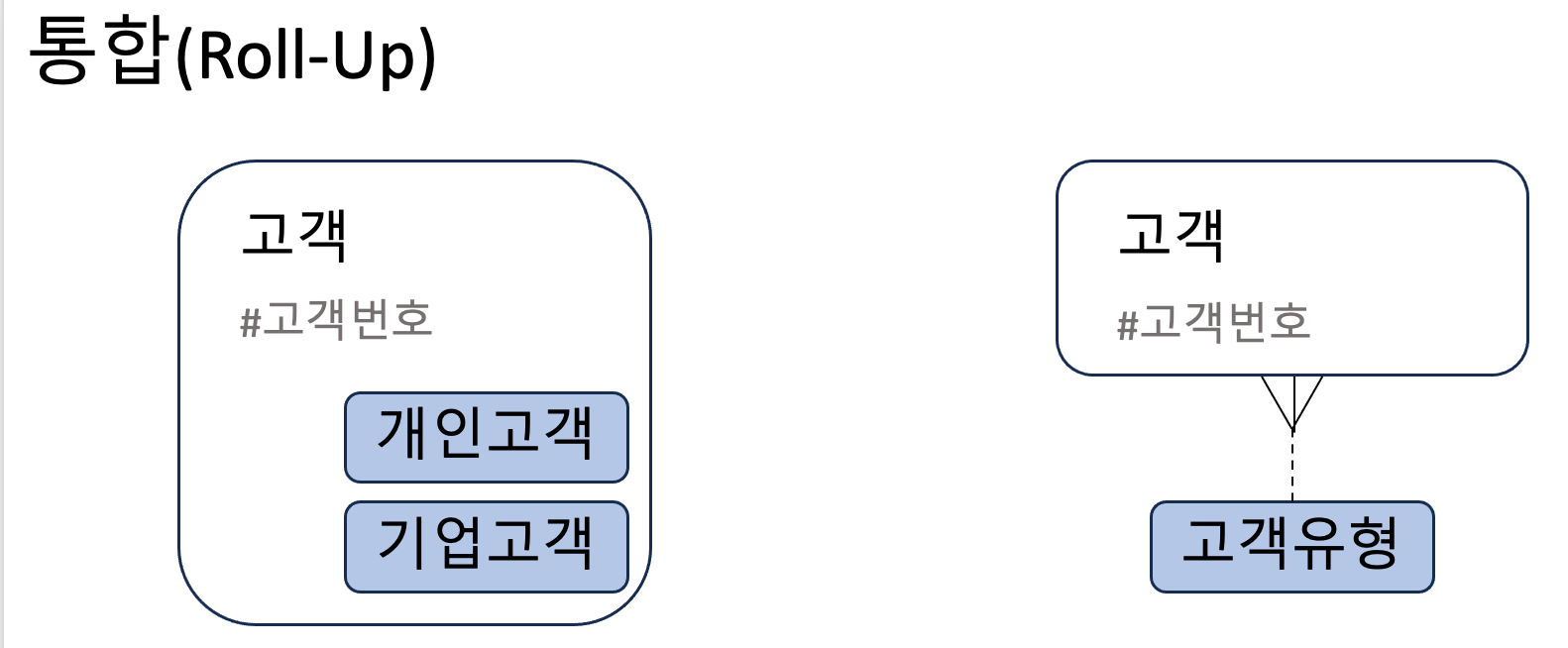
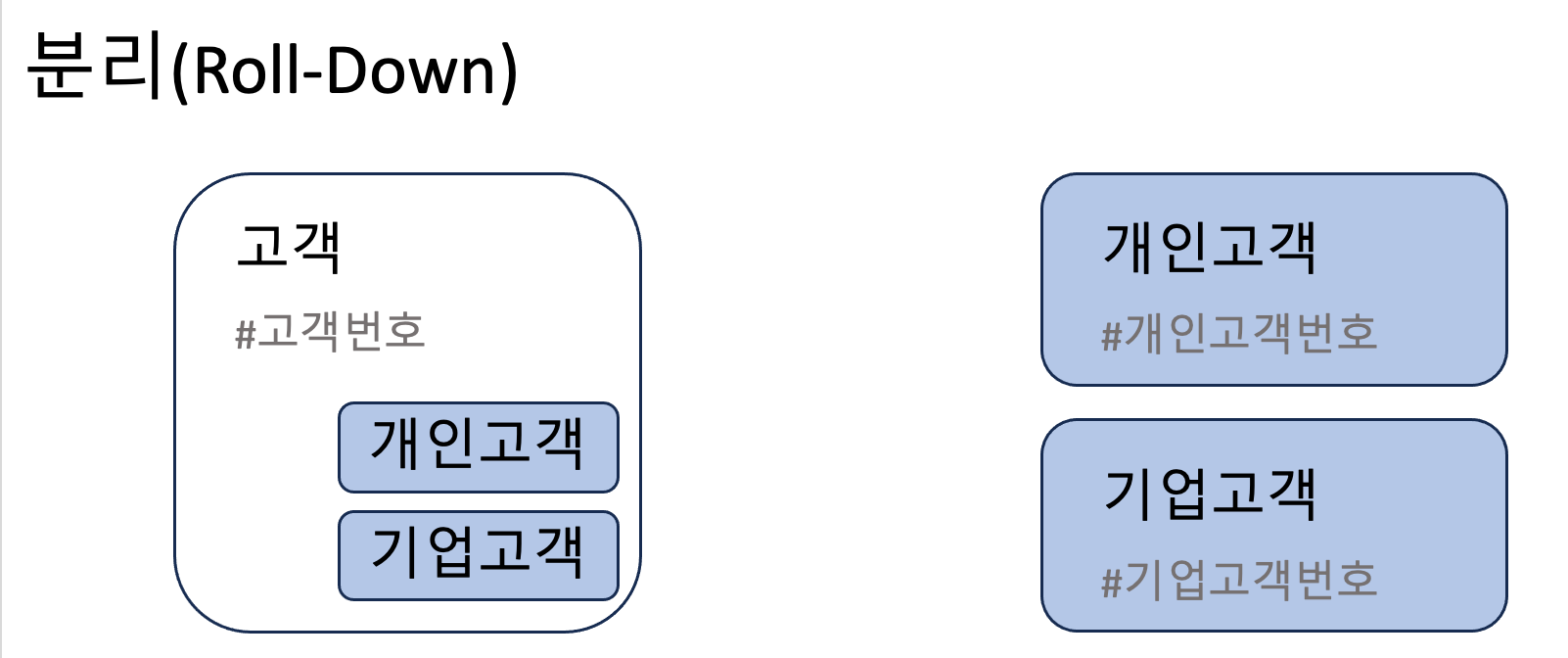
하나의 엔티티에 여러 개의 서브타입이 존재할 경우
하나의 엔티티에 서브타입셋(관점, 차원)이 2개 이상인 경우 서브타입을 어떻게 바라보아야 할까? 이 서브타입셋들을 통합(Rollup)해야 할까, 분리(Rolldown)해야 할까?
통합이 필요한 이유는 동일한 체계를 가질 필요가 있고, 동일한 형태의 처리가 발생하기 때문이다. 공통으로 사용할 속성들은 통합 엔티티에 두고, 자신만이 가지는 고유 속성들을 모아서 별도의 엔티티에 분리하여 유연성과 확장성을 얻을 수 있다. 하지만, 무리한 일반화와 통합은 집합이 모호해지고 개체들의 본질을 희석시킬 수 있다.
집합을 일반화하여 대상을 확장할 수 있게 해 두고 구분자를 통해 정의하는 방식은 동질성에 저촉되지 않는다면 얼마든지 기존 체계를 준수하면서 새로운 집합을 추가할 수 있게 해 준다.
서브타입을 테이블로 전환하는 기준
서브타입의 구현은 테이블의 용량과 트랜잭션의 발생 유형으로 구분하여 다음과 같이 크게 3가지 형태로 물리 설계할 수 있다.
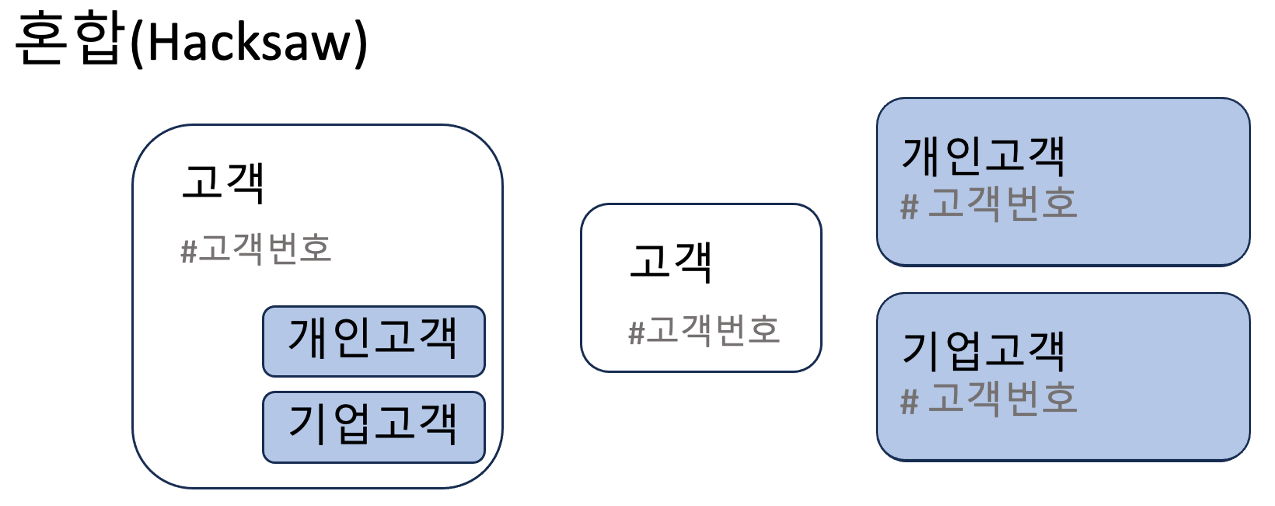
테이블 용량이 작은 경우에는 혼합 구성이 유연성 측면에서 유리하며, 대용량 데이터를 담는다면 아래 기준에 따라 구성한다.
- 통합(Roll-up): 트랜잭션이 슈퍼타입과 서브타입 전체를 대상으로 발생하는 경우
- 분리(Roll-down): 트랜잭션이 서브타입별로 발생하는 경우
- 혼합(Hacksaw): 트랜잭션이 슈퍼타입과 서브타입에서 개별적으로 발생하는 경우(통합도 무방)
