설계 방법론: 사용자 수에 따른 규모 확장성(1) 에서는 단일 서버 형태의 시스템과 그로부터 데이터베이스를 독립시켜 별도의 계층으로 두는 시스템을 살펴 보았다. 이어서 조금 더 많은 사용자 수를 수용할 수 있는 시스템을 살펴볼 것이다.
수직적 규모 확장 vs 수평적 규모 확장
스케일 업(Scale up)
수직적 규모 확장(vertical scaling)을 의미하는 스케일 업은 서버에 고사양 자원을 추가하는 행위(CPU나 RAM 증설)를 말한다.
서버로 유입되는 트래픽의 양이 적을 때는 단순하게 스케일 업 함으로써 어느 정도 부하를 해결할 수 있지만, 아래와 같은 단점으로 인해 만병통치약은 아니다.
- 수직적 규모 확장에 한계가 있다. 한 대의 서버에 무한대의 CP나 메모리를 증설할 수 없다.
- 장애에 대한 자동복구(failover) 방안이나 다중화(redubdancy) 방안을 제시하지 않는다. 서버에 장애가 발생하면, 서비스는 완전히 중단된다.
이러한 단점 떄문에, 대규모 서비스를 지원하는 데는 수평적 규모 확장법이 보다 적절하다.
스케일 아웃(Scale out)
수평적 규모 확장을 의미하는 스케일 아웃은 더 많은 서버를 추가하여 성능을 개선하는 행위를 말한다.
너무 많은 사용자가 접속하여 웹 서버가 한계 상황에 도달하게 되면 응답 속도가 느려지거나 서버 접속이 불가능해질 수도 있다. 이런 문제를 해결하는 데는 부하 분산기 또는 로드밸런서(load balancer)를 도입하는 것이 최선이다.
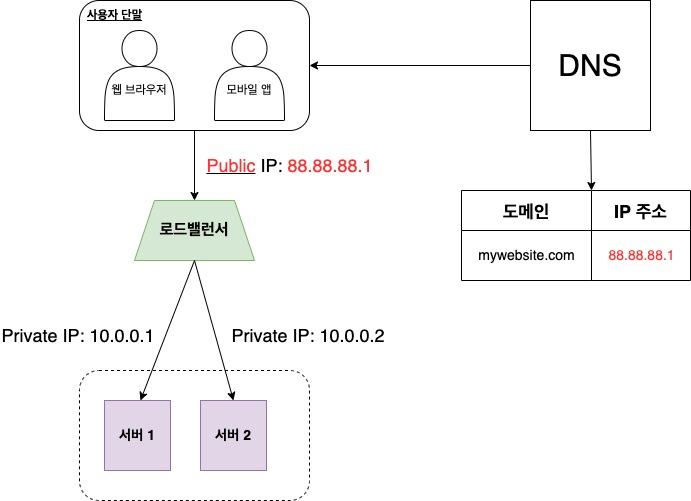
사용자는 로드밸런서의 공개 IP 주소로 접속한다. 따라서, 서버가 클라이언트의 접속을 직접 처리하지 않는다. 로드밸런서는 웹 서버와 통신하기 위해 사설 IP주소를 이용하는데, 사설 IP는 같은 네트워크에 속한 서버 사이의 통신만 허용하고 인터넷을 통한 접속을 차단하여 더 나은 보안을 제공한다.
로드밸런서는 다음과 같이 작동한다.
- 서버 1이 다운되면 모든 트래픽은 서버 2로 전송된다. 따라서 웹 사이트 전체가 다운되는 일이 방지된다.
- 만약 두 대의 서버만으로 감당할 수 없을 정도로 트래픽이 급증하면, 웹 서버 계층에 더 많은 서버를 추가하기만 하면 된다. 그러면 로드밸런서가 자동적으로 트래픽을 분산할 것이다.
이처럼 부하 분산 집합에 여러 개의 웹 서버를 두면 장애를 자동복구하지 못하는 문제(no failover)가 해소되며, 웹 계층의 가용성(availability)은 향상된다.
이제 웹 계층은 어느 정도 괜찮아진 것 같다. 하지만, 아직 이 설계 안에서는 하나의 데이터베이스만을 사용하고 있다.
데이터베이스 다중화
데이터베이스 다중화는 데이터베이스 장애의 자동복구를 지원하는 보편적인 방법이다. 보통은 서버 사이에 주(master) - 부(slave) 관계를 설정하고 데이터 원본은 주 서버에, 사본은 부 서버에 저장하는 방식이다.
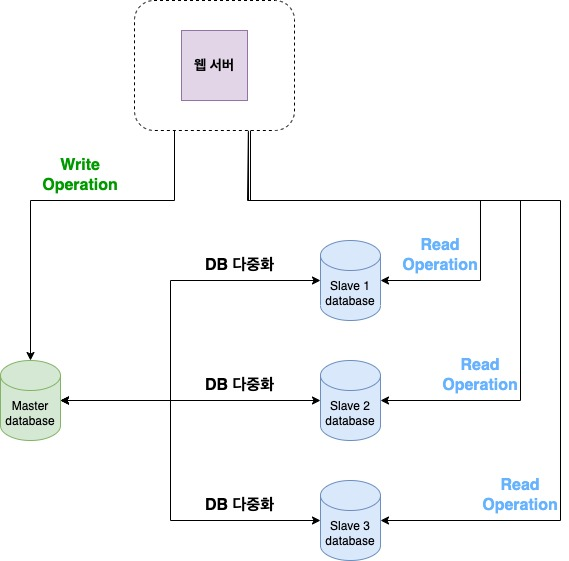
부 데이터베이스는 주 데이터베이스로부터 그 사본을 전달받고, 읽기 연산만을 지원한다. 주 데이터베이스는 데이터베이스를 변경하는 명령어인 INSERT, DELETE, UPDATE 등의 처리를 담당한다. 대부분의 애플리케이션은 읽기 연산의 비중이 쓰기 연산보다 훨씬 많으므로, 통상 부 데이터베이스의 수가 주 데이터베이스보다 더 많다.
데이터베이스를 다중화하면 다음과 같은 이득이 있다.
- 더 나은 성능: 데이터 변경 연산은 주 데이터베이스에만 전달되고, 읽기 연산은 부 데이터베이스 서버들로 분산되어, 병렬로 처리될 수 있는 질의(query)의 수가 늘어남.
- 안정성(reliability): 데이터를 지역적으로 떨어진 여러 장소에 다중화 시켜 놓을 수 있으므로, 데이터베이스 서버 일부가 파괴되어도 데이터는 보존될 수 있음.
- 가용성(availability): 데이터를 여러 지역에 복제해 둠으로써, 하나의 데이터베이스 서버에 장애가 발생하더라도 다른 서버에 있는 데이터를 가져와 계속 서비스할 수 있게 됨.
앞에서 로드밸런서가 웹 서버의 가용성을 높이는 것을 확인했는데, 이를 데이터베이스에 적용하면 어떤 이점이 있을까?
- 부 데이터베이스 서버가 다운되는 경우
- 한 대 뿐인데 다운된 경우라면, 새로운 부 데이터베이스 서버를 가동하기 전까지 읽기 연산을 한시적으로 주 데이터베이스로 전달할 수 있다.
- 여러 대인 경우, 새로운 부 데이터베이스 서버를 가동하기 전까지 읽기 연산은 나머지 부 데이터베이스 서버들로 분산된다.
- 주 데이터베이스 서버가 다운되는 경우
- 부 데이터베이스가 한 대 뿐이라면, 그 데이터베이스가 새로운 주 서버로 교체되며 새로운 부 데이터베이스 서버를 띄울 때까지 모든 연산을 일시적으로 수행한다.
- 부 서버에 보관된 데이터가 최신 상태가 아니라면, 복구 스크립트(recovery script)를 돌려 없는 데이터를 추가해야 한다. 다중 마스터(multi-masters)나 원형 다중와(circular replication) 방식은 이런 상황에 도움이 되긴 하나 구성이 상당히 복잡하다.
데이터베이스 다중화와 로드밸런서를 고려한 설계안은 아래와 같으며, 다음과 같이 동작한다.
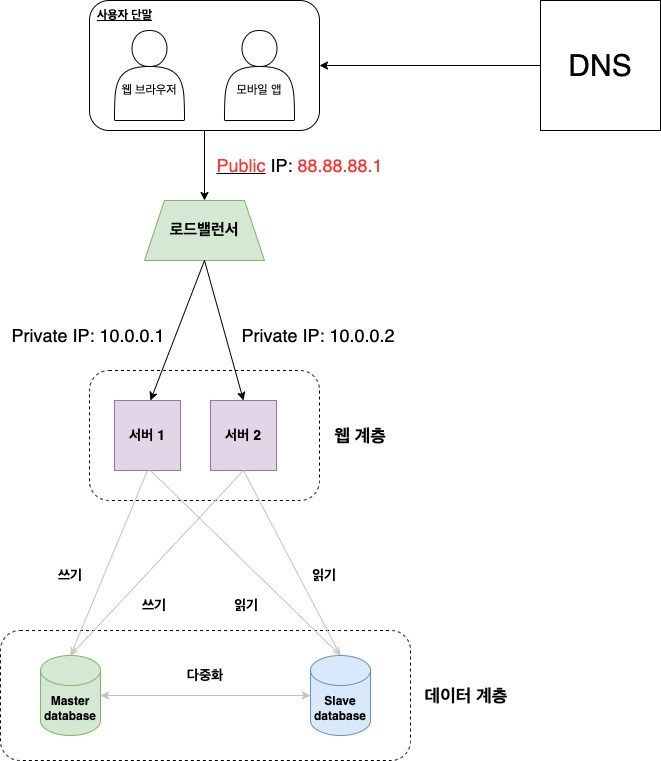
- 사용자는 DNS로부터 로드밸런서의 공개 IP 주소를 받는다.
- 사용자는 해당 IP 주소를 사용해 로드밸런서에 접속한다.
- HTTP 요청은 서버 1 또는 서버 2로 전달된다.
- 웹 서버는 사용자의 데이터를 Slave database 서버에서 읽는다.
- 웹 서버는 데이터 추가, 삭제, 갱신 연산 등의 데이터 변경 연산을 Master database 서버로 전달한다.
