BeautifulSoup 예제2 - 위키백과 문서 정보 가져오기 - 여명의눈동자
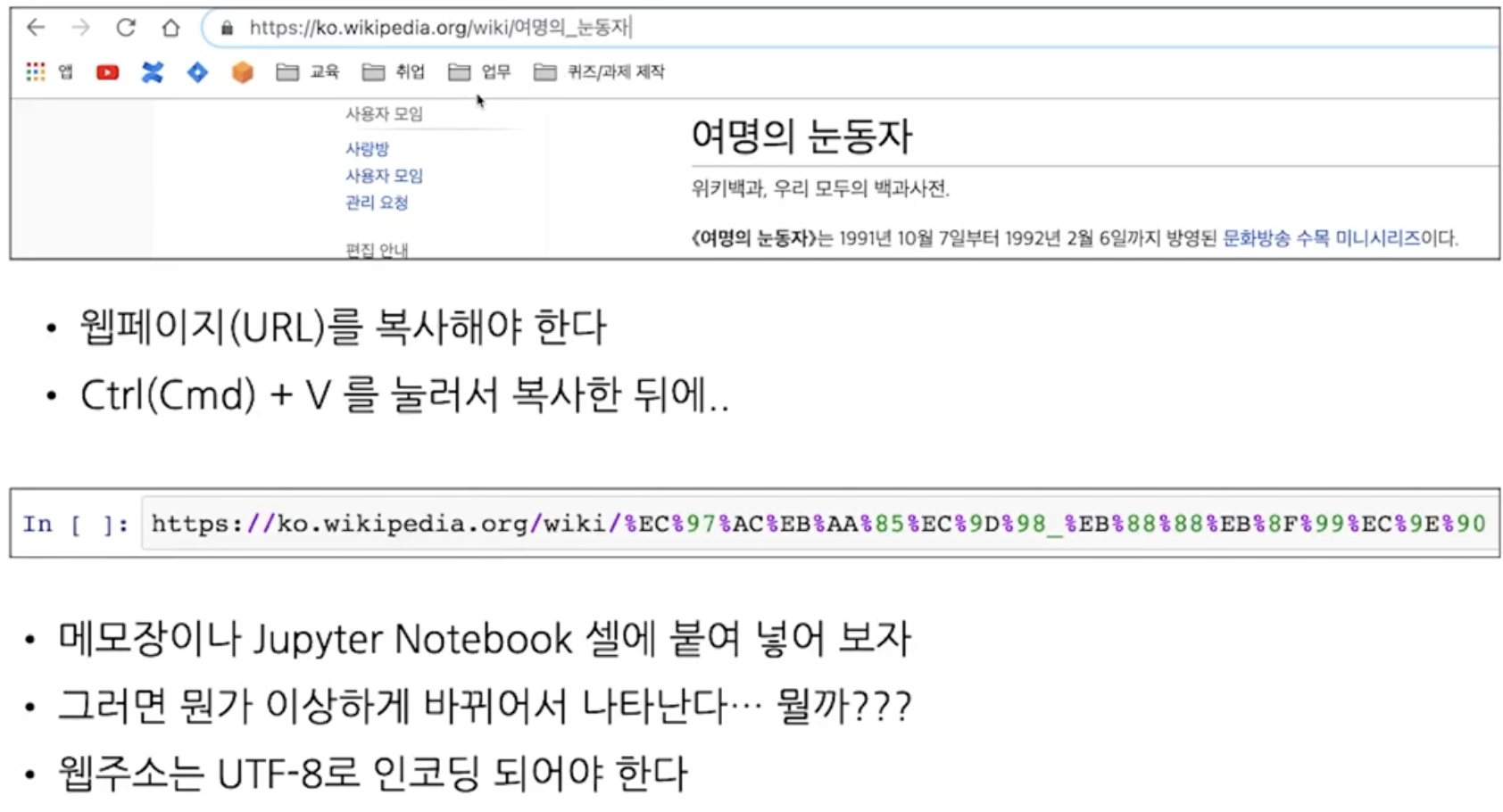
한글주소 변환 불러오기
-
URL Decoder / Vscode 오류잡기


url decoding사이트
URL Decoder/Encoder - meyerweb.com
-
import & url불러오기
# 포맷팅 : '{}'에 넣으면 string --> 변환가능한 변수가됨
html = "https://ko.wikipedia.org/wiki/{search_words}"
# https://ko.wikipedia.org/wiki/여명의_눈동자
req = Request(html.format(search_words=urllib.parse.quote("여명의_눈동자")))
# string변수.format()
# urllib : url라이브러리, parse : 모듈, quote : 함수
# quote : str을 utf-8파일로 변환시켜줌
# 바로 읽을수 없는 url의 경우, 포맷팅을 넣었을경우 요청단계를 한번더 넣어줌
response = urlopen(req)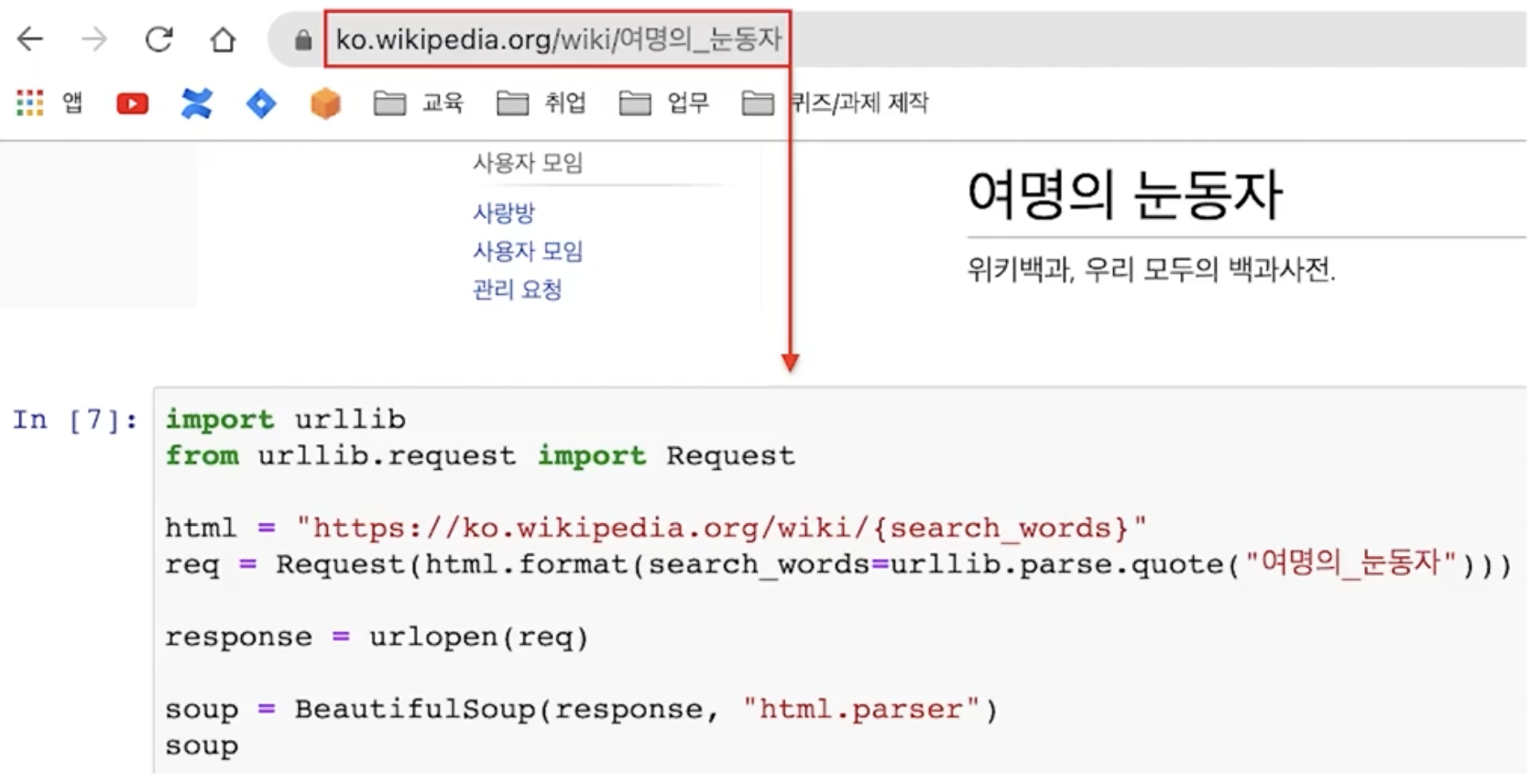
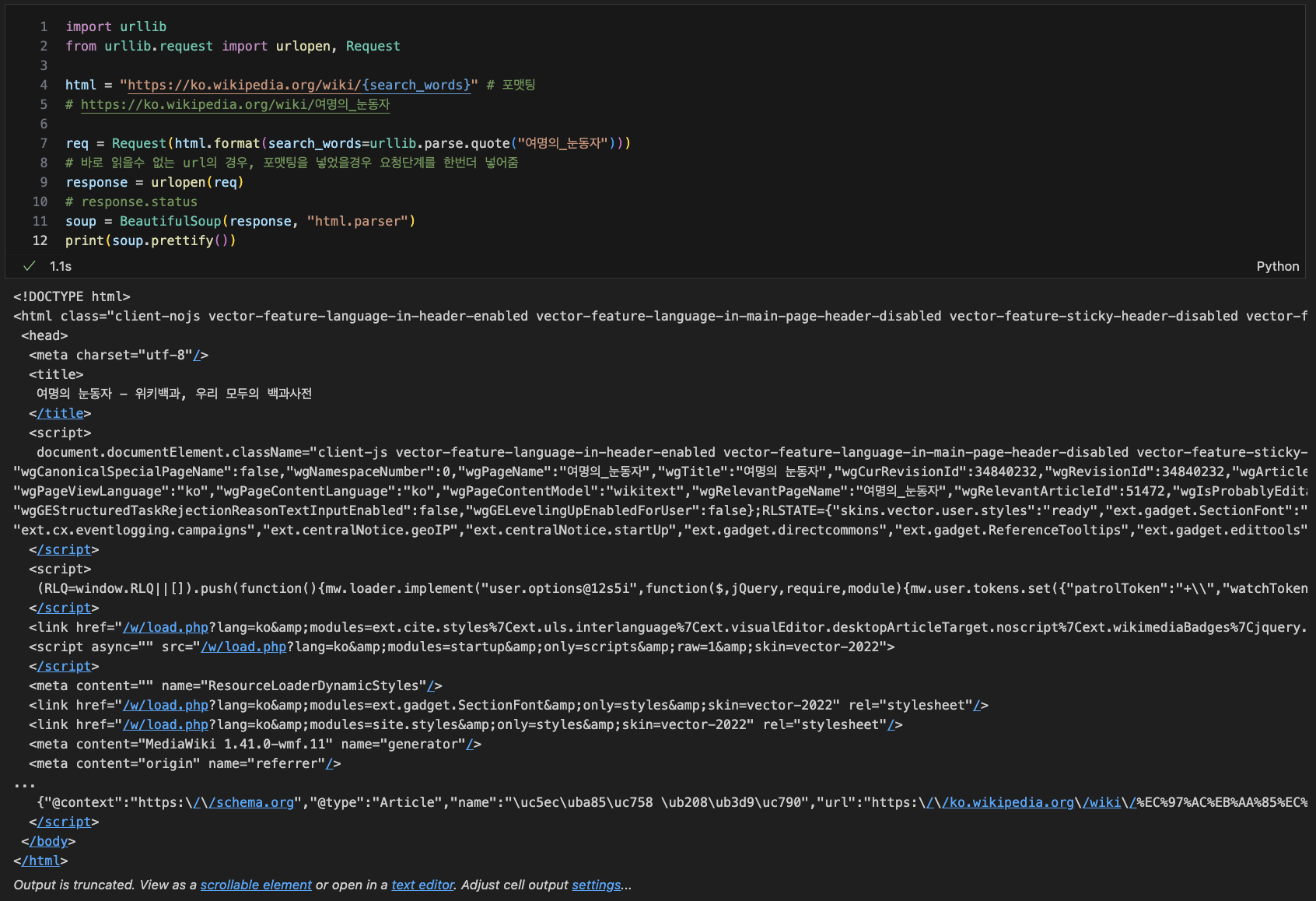
필요정보 위치 알아내기
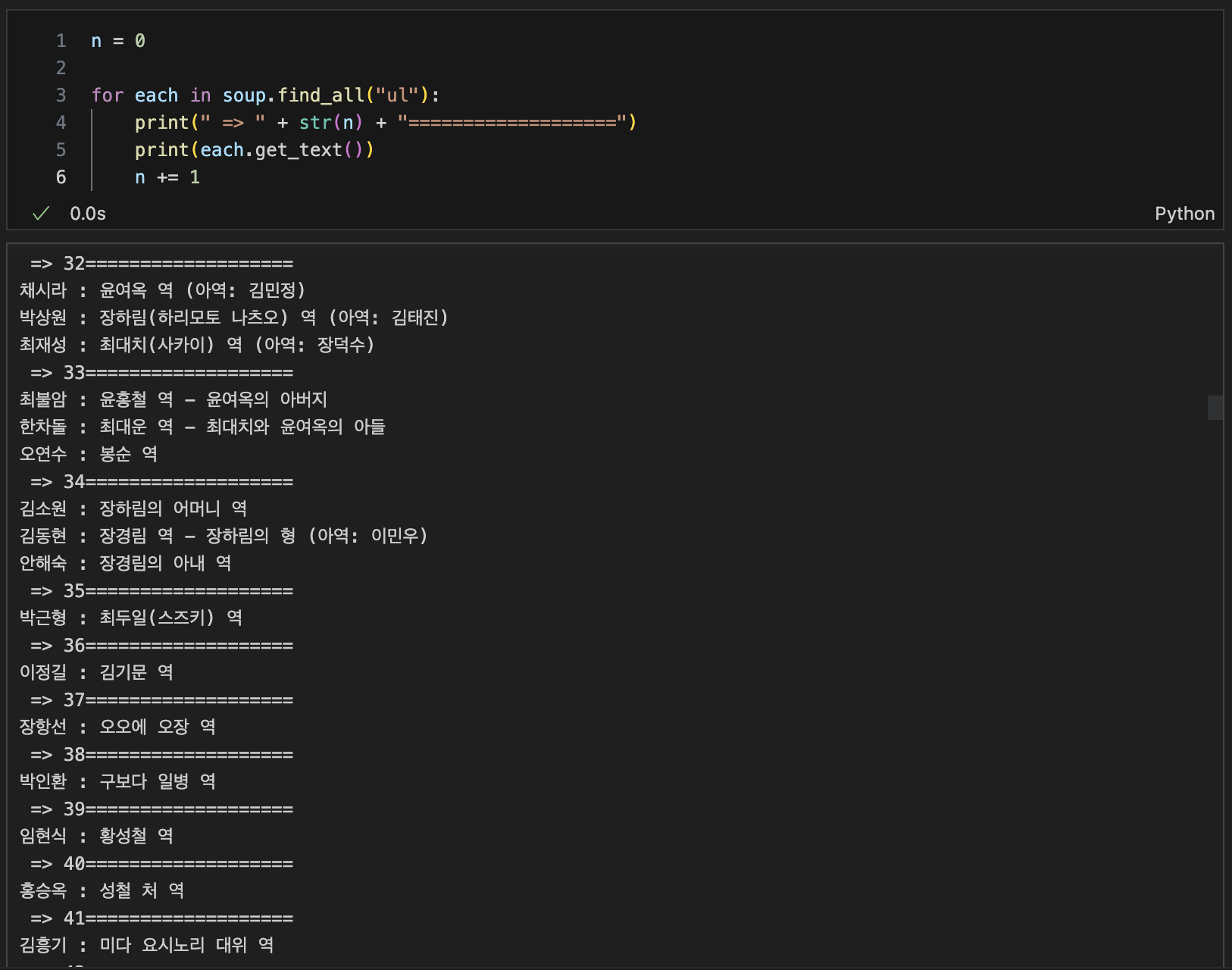
필요정보 정리
soup.find_all("ul")[32].text.strip().replace("\n", " ")
# --> 32번째 ul의 자료를 텍스트만 뽑아내고, 필요없는 문장은 공백으로 전환
strip([chars]) : 인자로 전달된 문자를 String의 왼쪽과 오른쪽에서 제거합니다.
lstrip([chars]) : 인자로 전달된 문자를 String의 왼쪽에서 제거합니다.
rstrip([chars]) : 인자로 전달된 문자를 String의 오른쪽에서 제거합니다.
python List 데이터형
-
list형은 대괄호로 생성

-
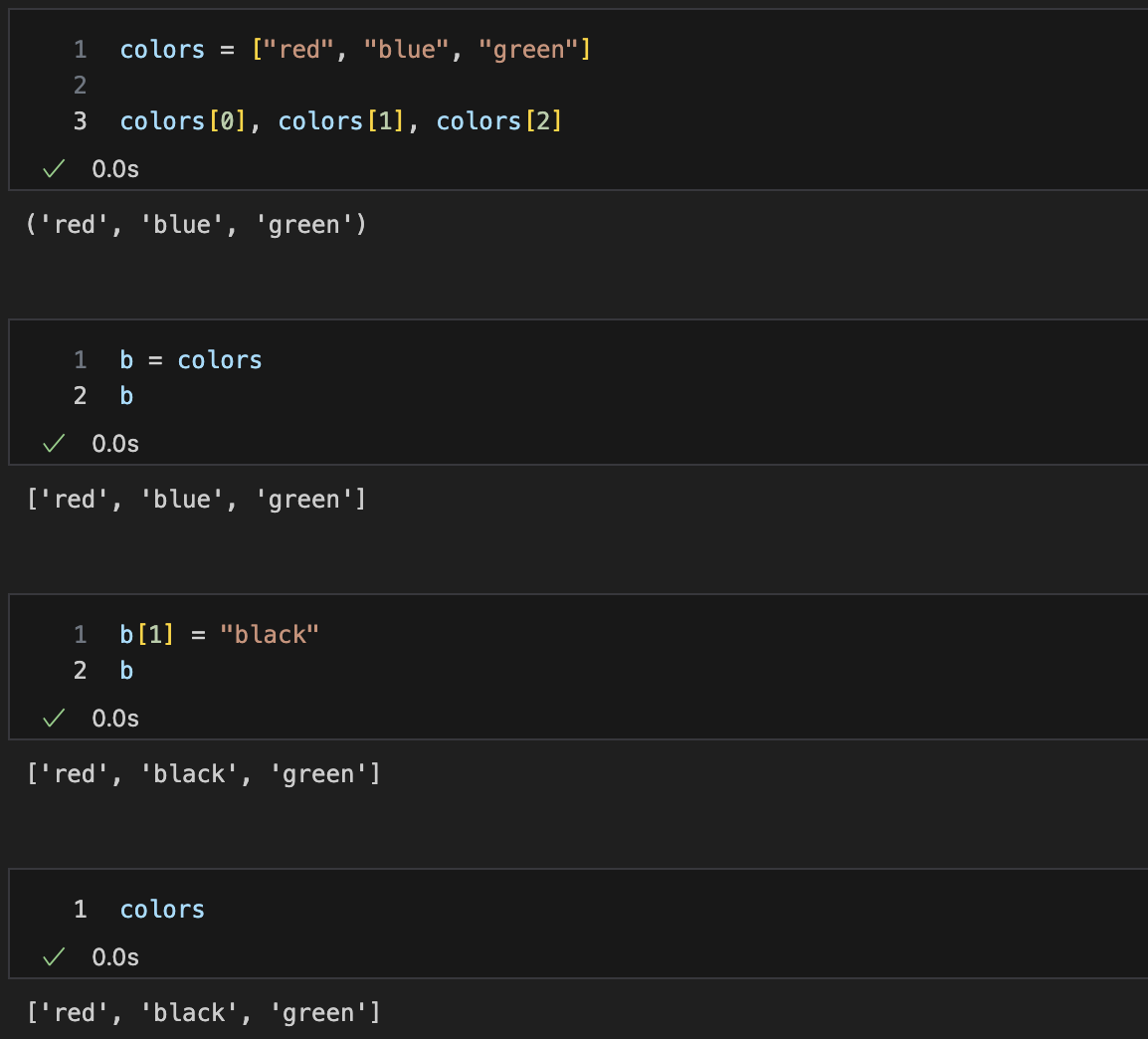
얕은복사
-
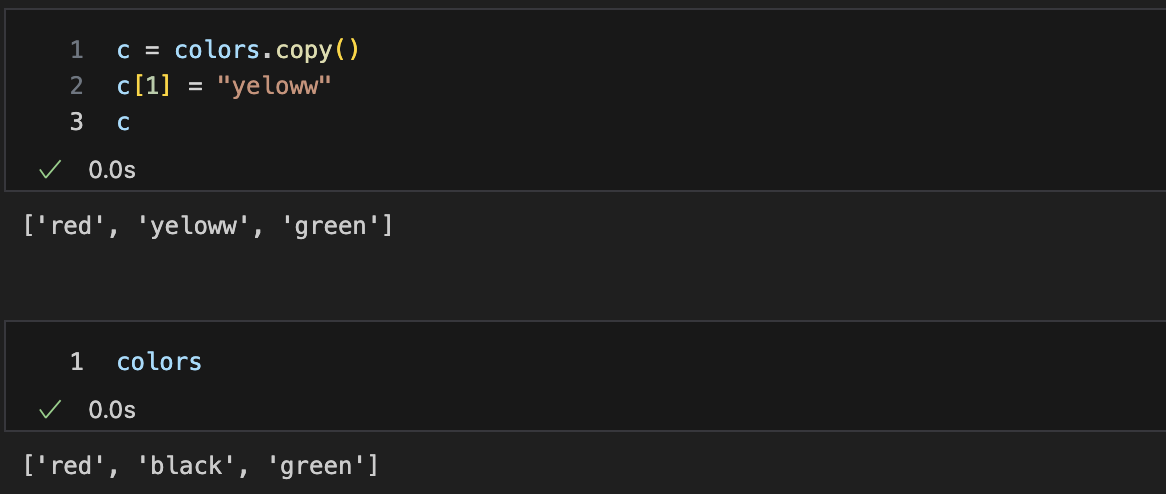
깊은복사
-
list형을 반복문에(for) 적용

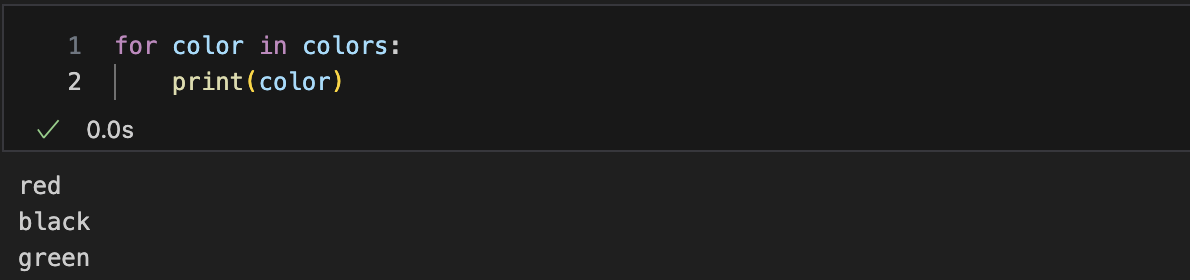
-
in 명령으로 조건문(if)에 적용
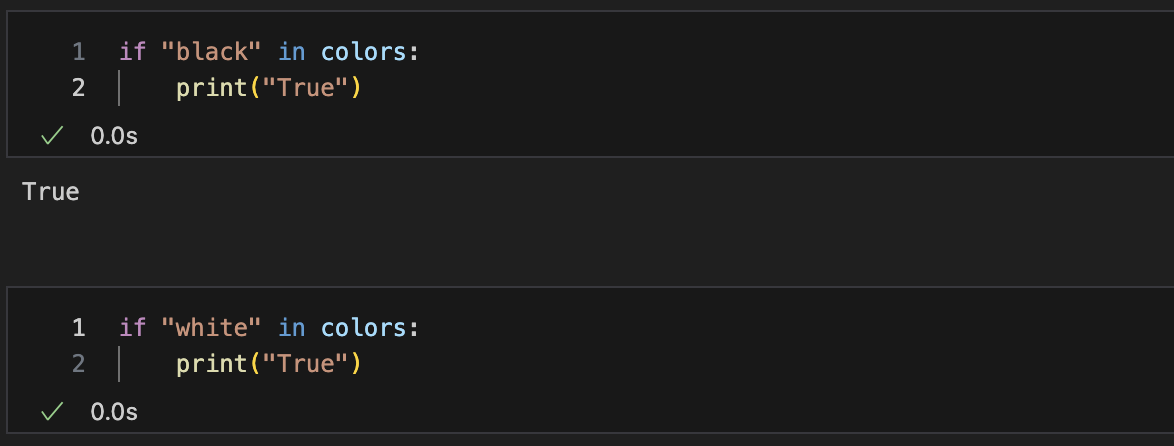
-
append : list 제일 뒤에 추가


-
pop : list 제일 뒤부터 자료를 하나씩 삭제
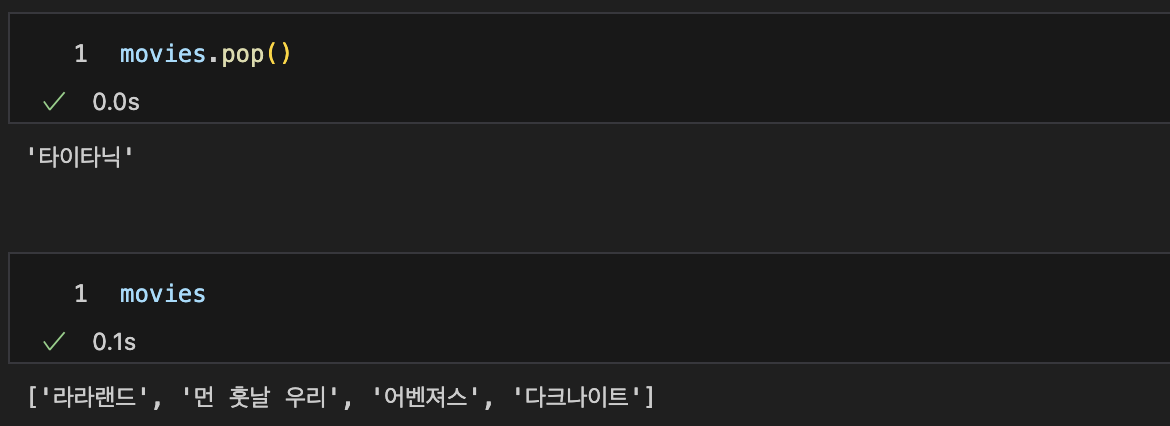
-
extend : 제일 뒤에 자료 추가

-
remove : 자료를 삭제

-
슬라이싱 : [n:m] n번째 부터 m-1까지
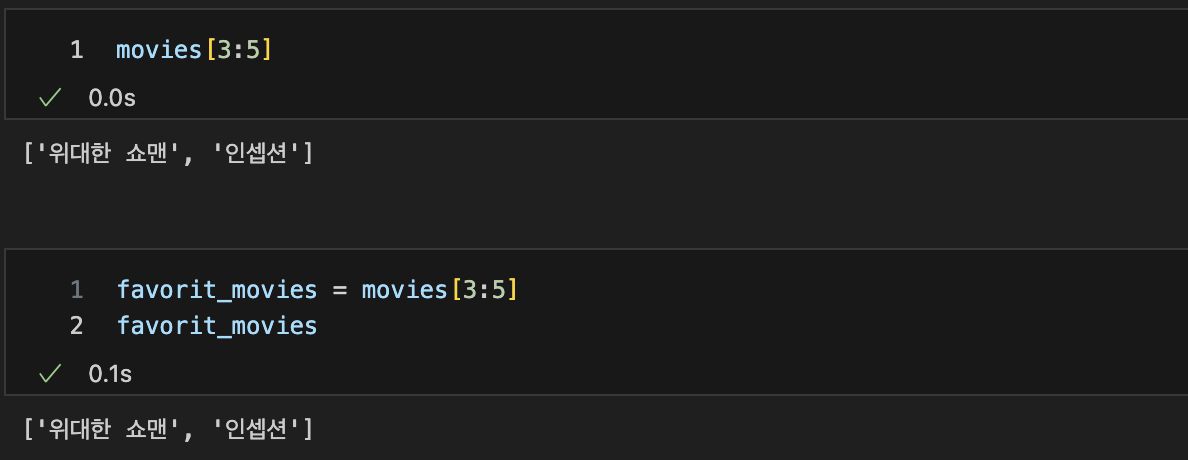
-
insert : 원하는 위치에 자료를 삽입
-
list안에 list
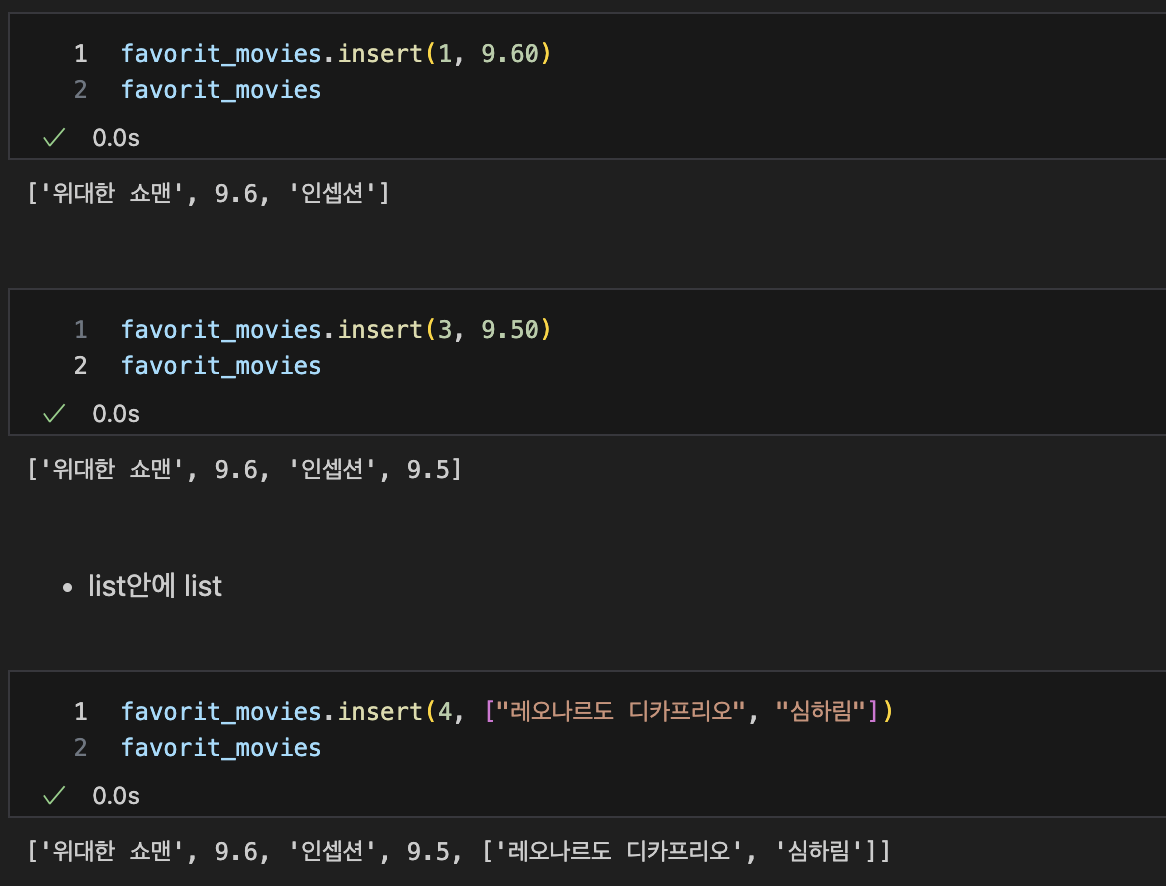
-
isinstance : 자료형 True/False
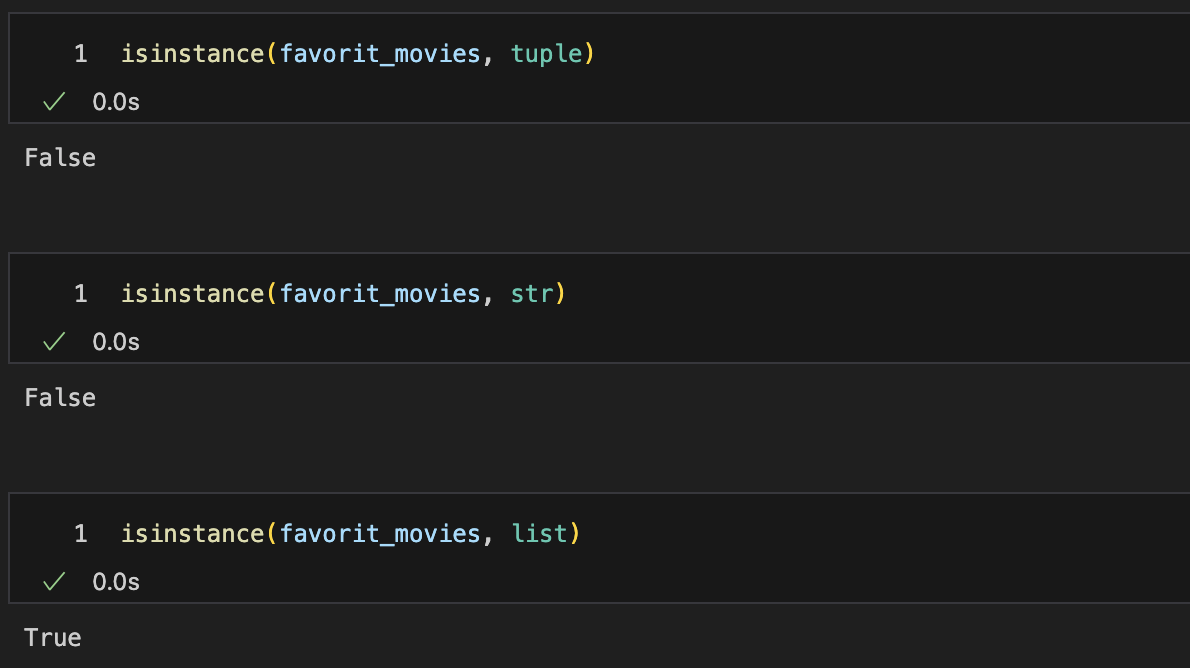
-
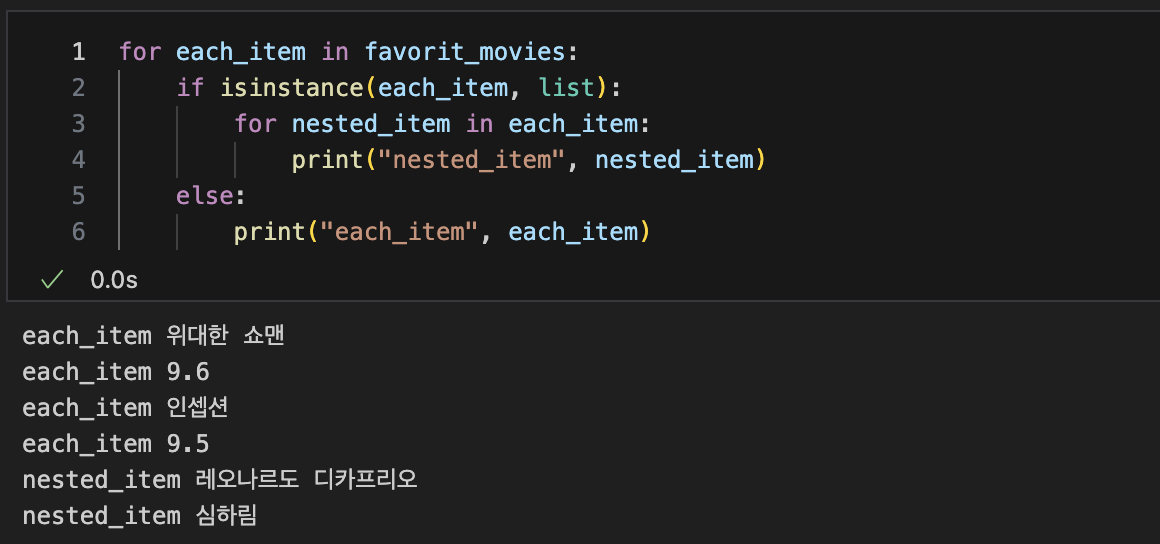
for문으로 list, list아닌파일 출력가능
2. 시카고 맛집 데이터 분석 - 개요
- https://www.chicagomag.com/chicago-magazine/november-2012/best-sandwiches-chicago/
- chicago magazine the 50 best sandwiches
최종목표
총 50개 페이지에서 각 가게의 정보를 가져온다
- 가게이름
- 대표메뉴
- 대표메뉴의 가격
- 가게주소3. 시카고 맛집 데이터 분석 - 메인페이지
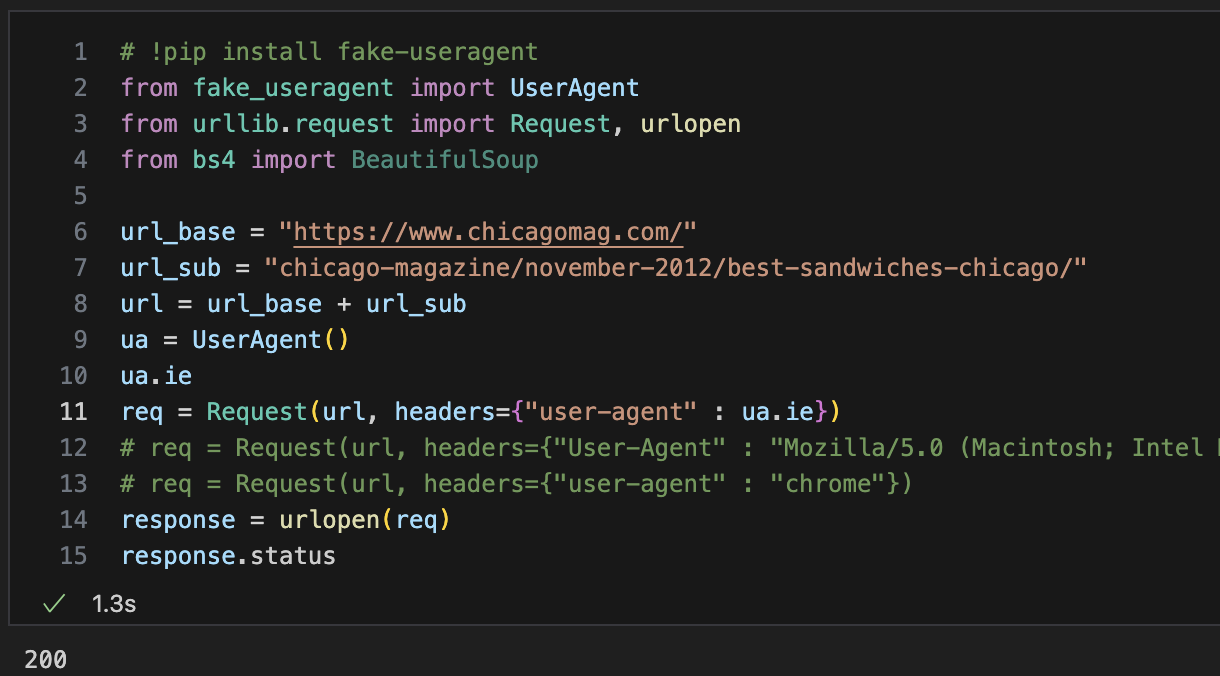
fake-useragent설치 & url 정리
# 설치전
req = Request(url, headers={"User-Agent" : "chrome})
response = urlopen(reg).read()
soup = BeautifulSoup(html, "html.parser")
--------------------------------------------
# fake-useragent 설치
!pip install fake-useragent
from fake_useragent import UserAgent
--------------------------------------------
ua = UserAgent()
ua.ie
--> 웹데이터 네트워크의 user-agent 환경을 랜덤하게 만들어주는 기능
req = Request(url, headers={"user-agent" : ua.ie})import, url불러오기
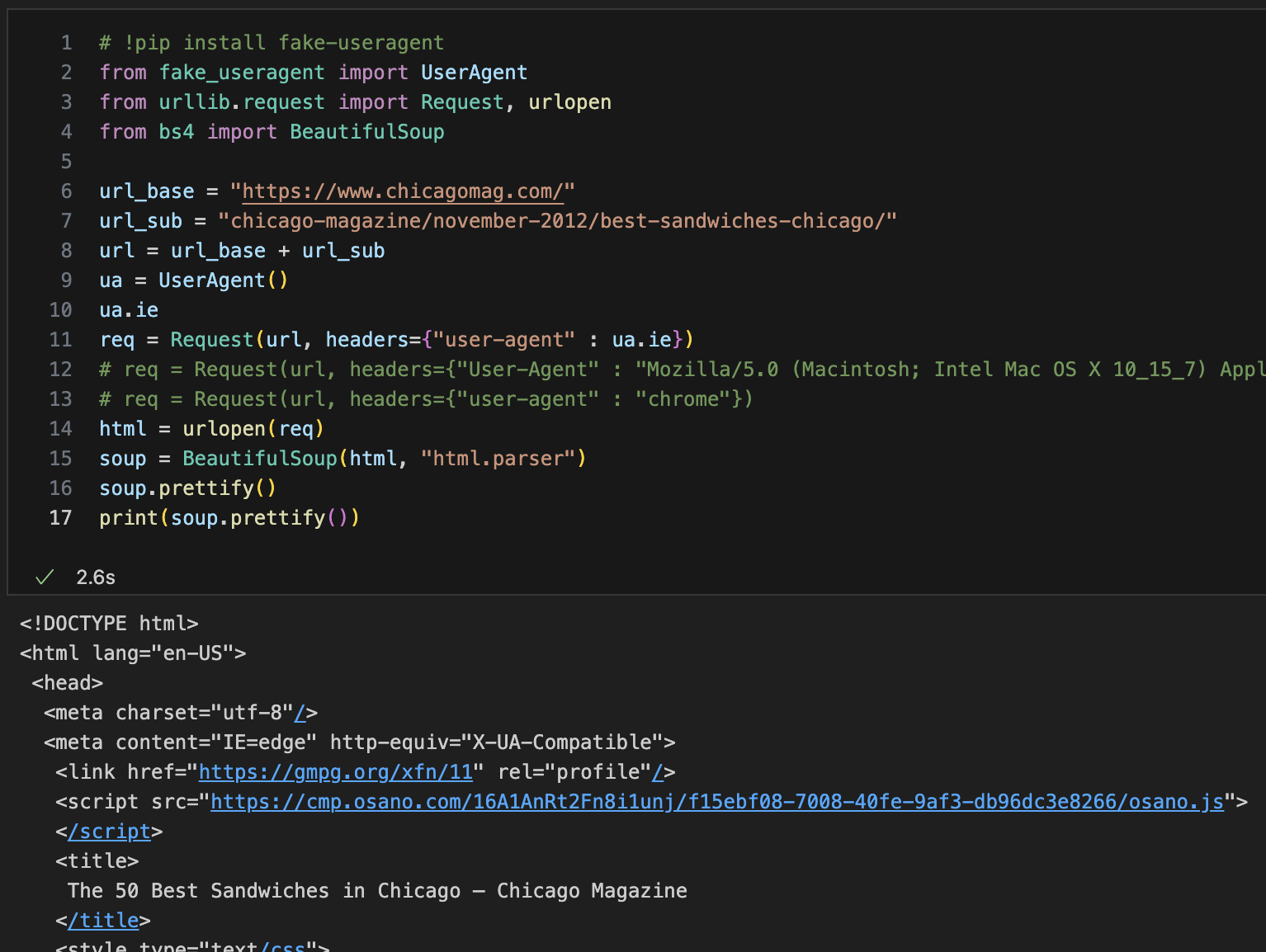
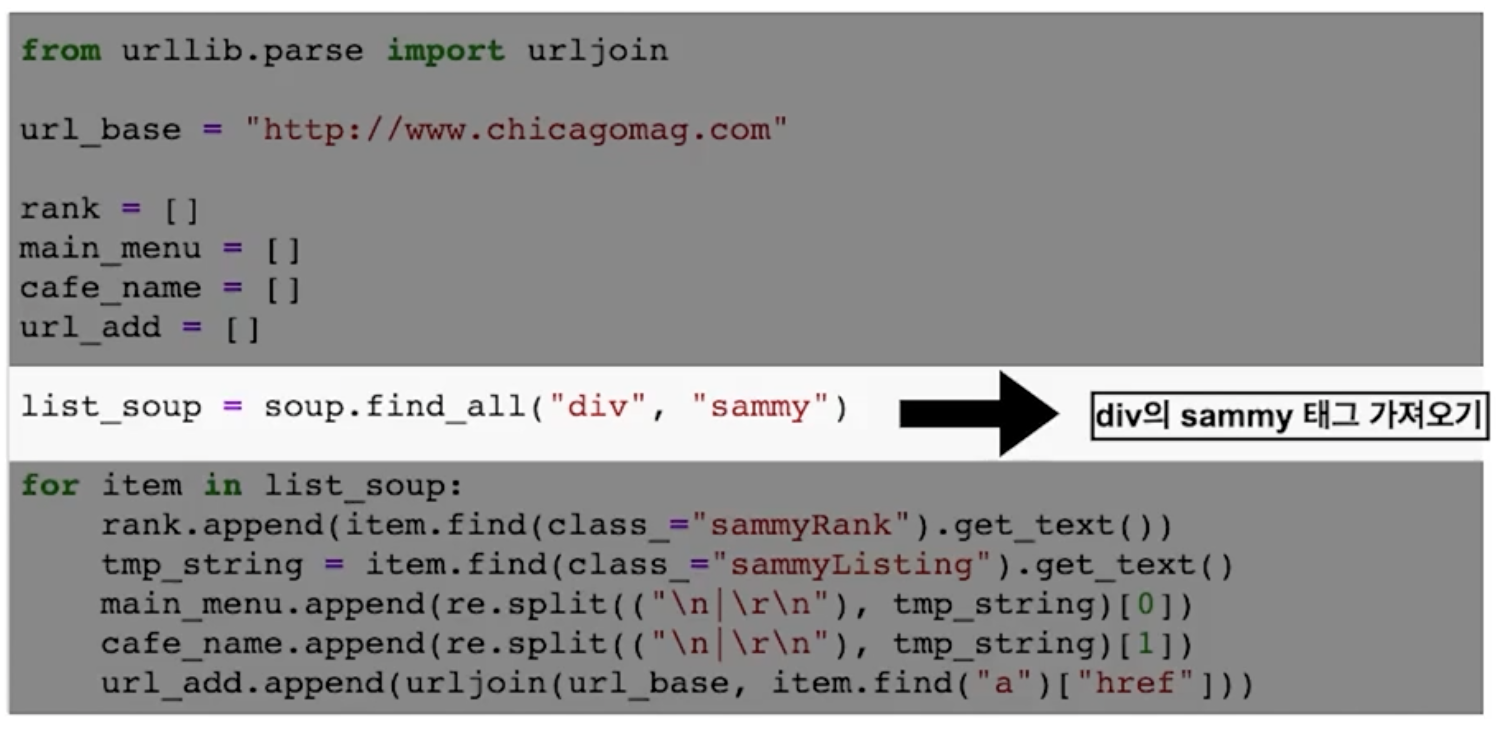
div 안에 sammy라는class 불러오기

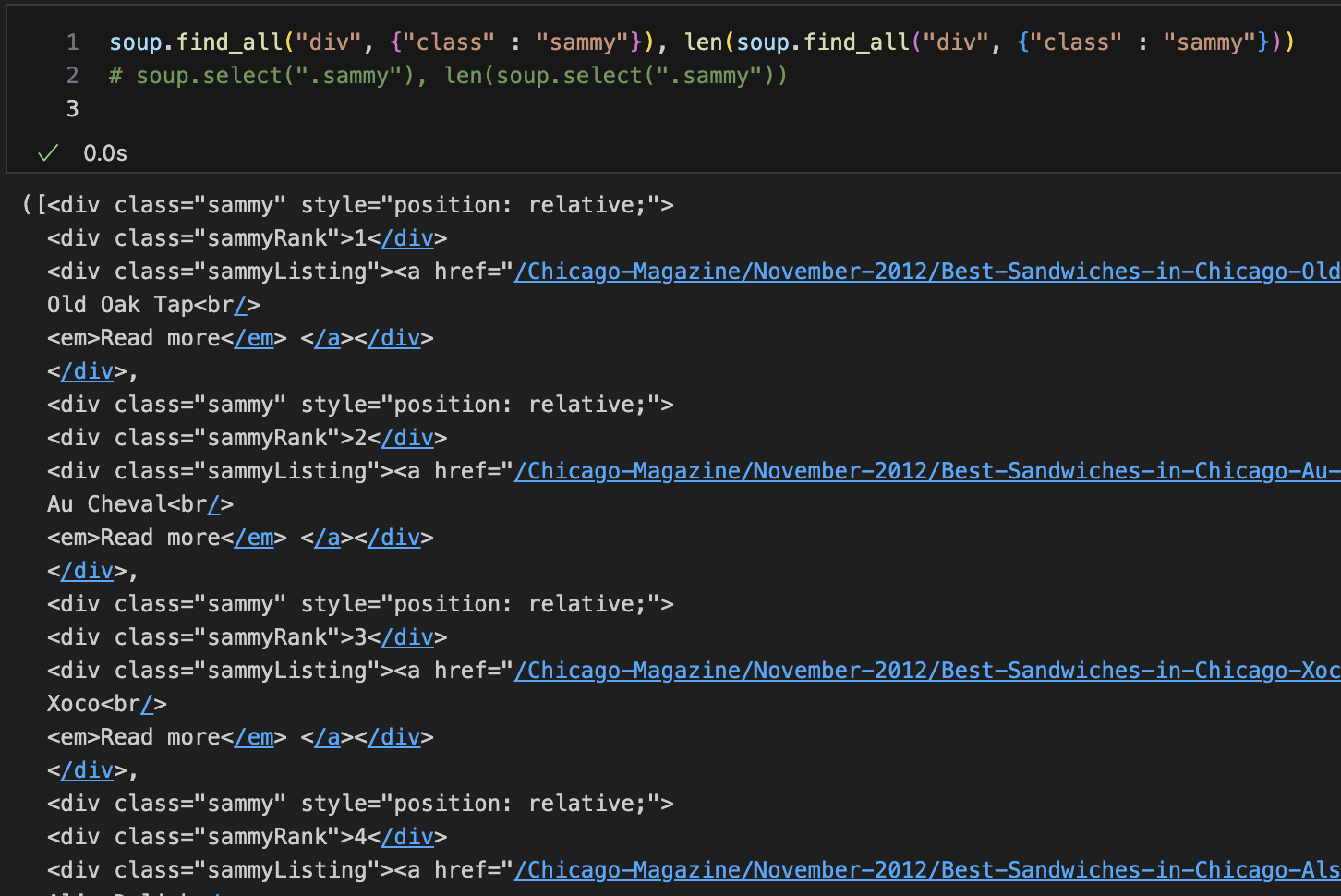
데이터출력을 위한 샘플예제
type(tmp_one) --> bs4.element.Tag
type이 bs4.element.Tag라는 것은 find명령을 사용할 수 있다는 뜻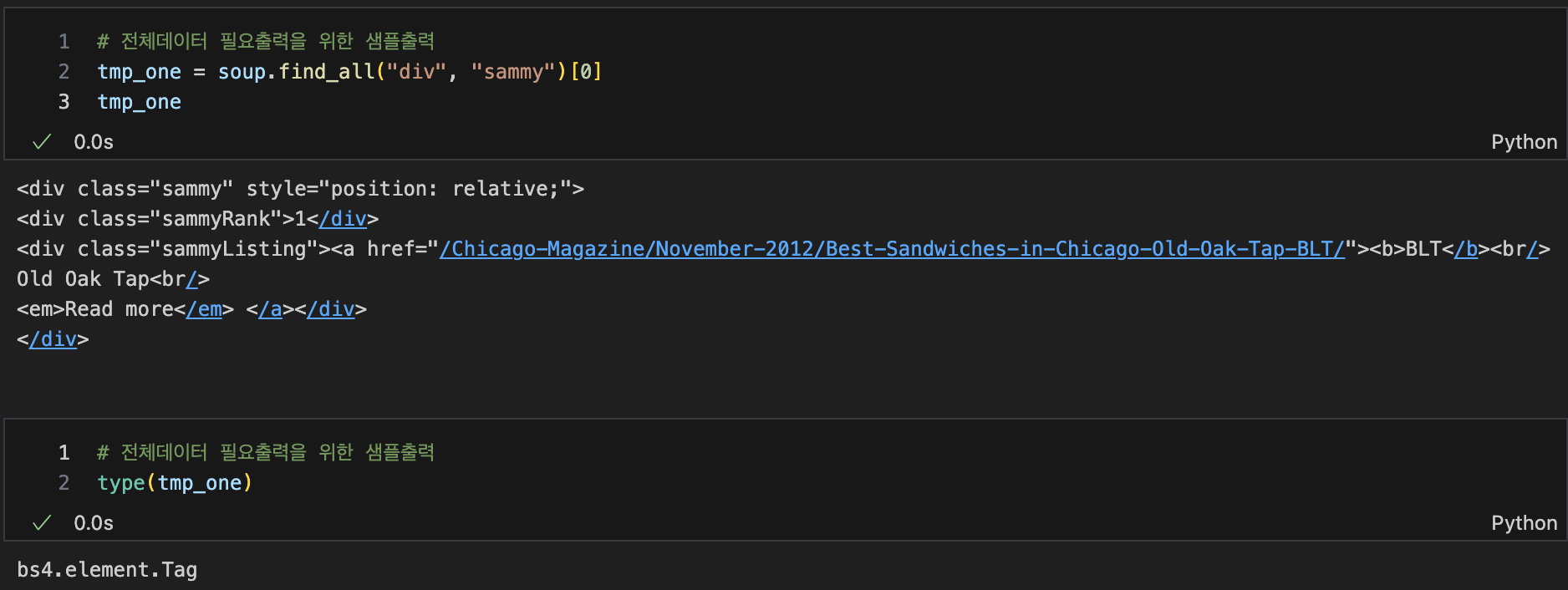
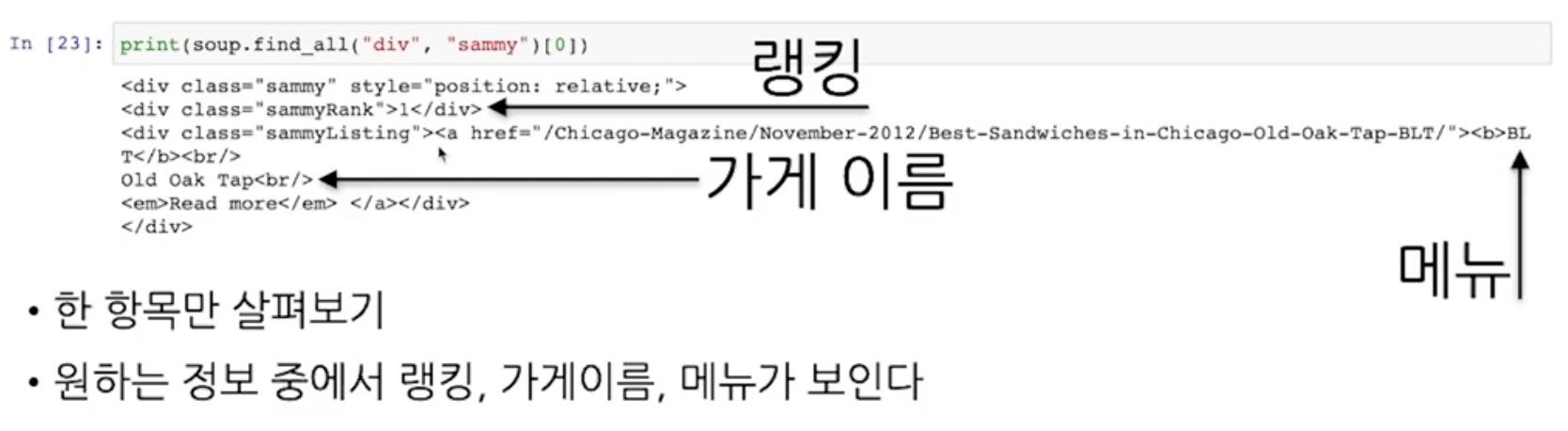
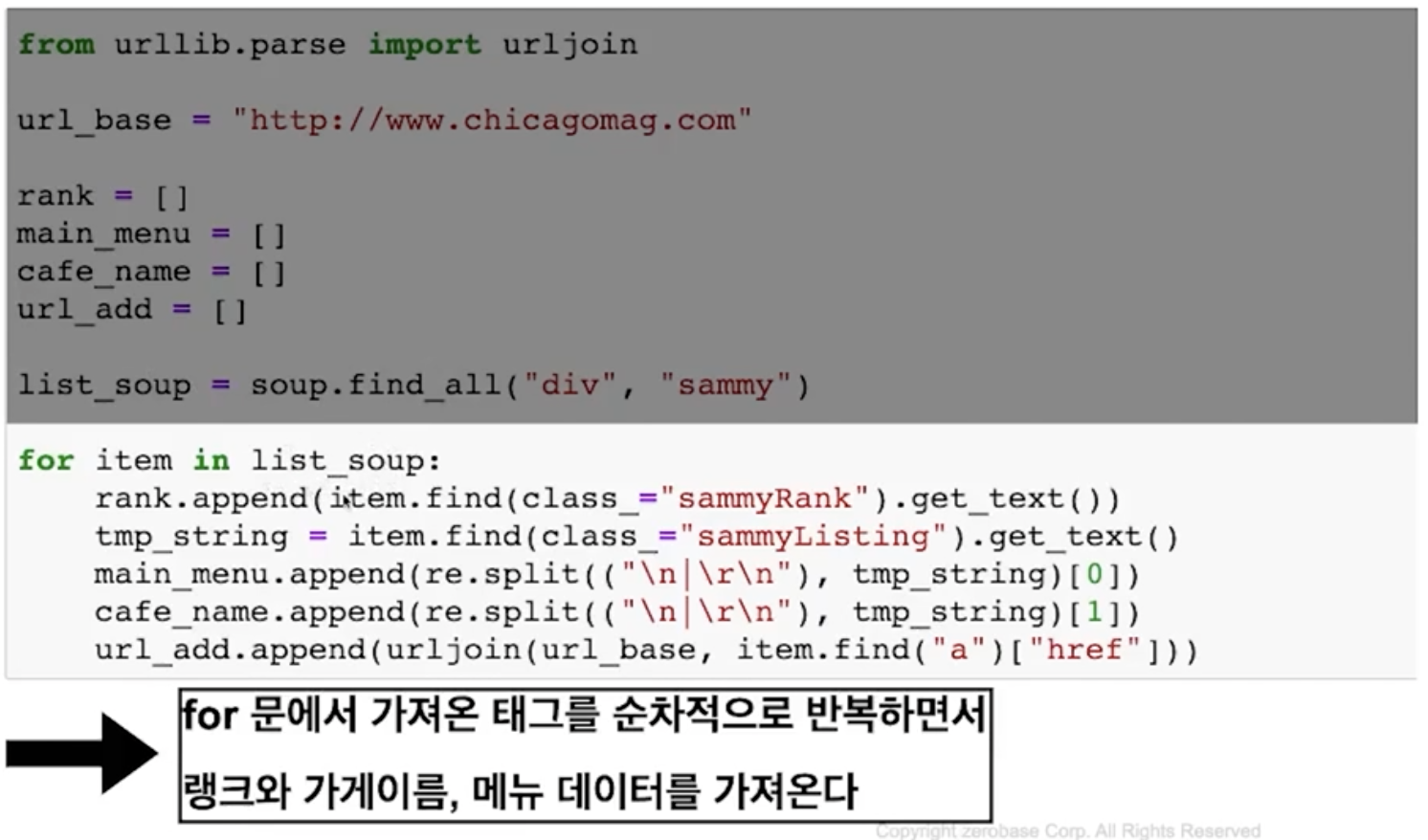
sammyRank값

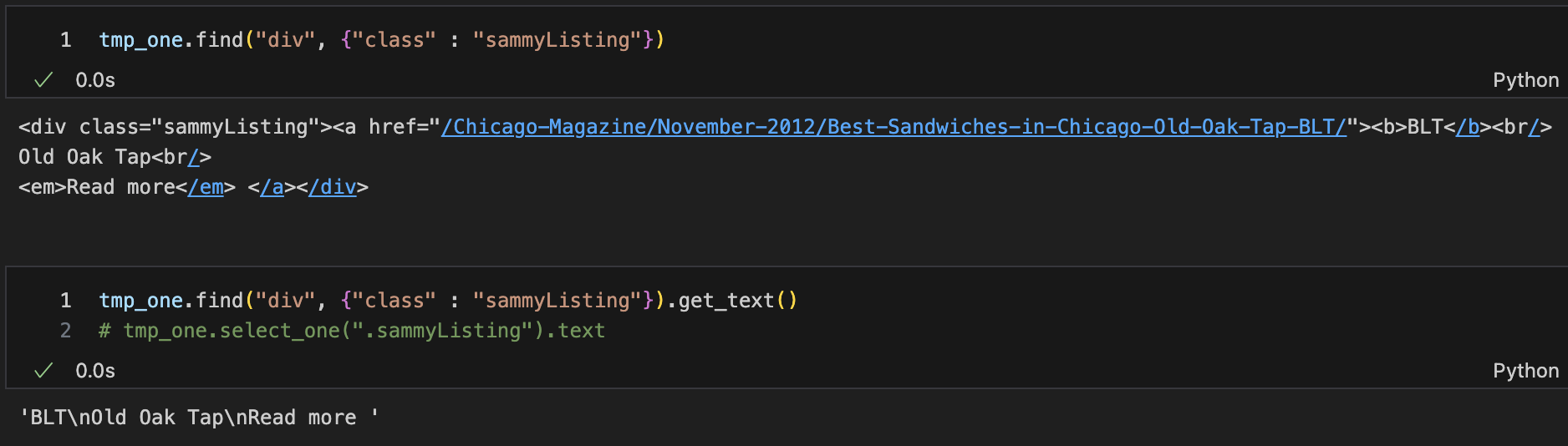
sammyListing값(menu, cafe_name)
url값
-- base주소가 상대경로로 되어있음 url_base꼭필요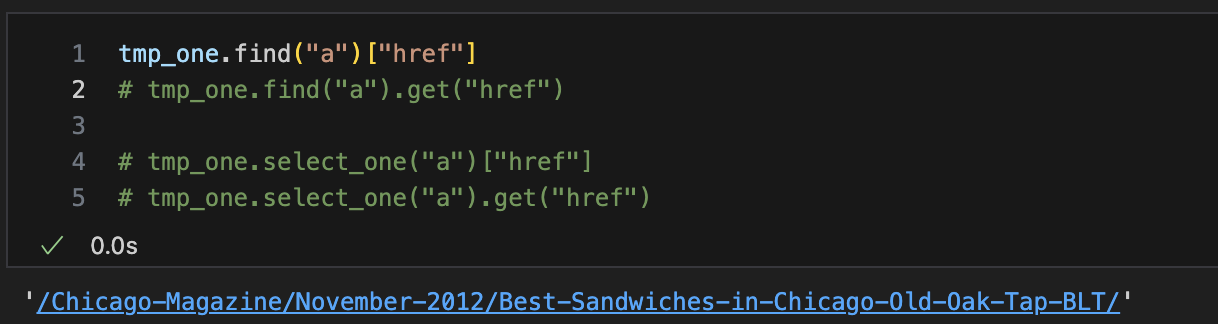
불필요한 내용삭제, 리스트담기
- import re
import re
tmp_string = tmp_one.find(class_="sammyListing").text
re.split("\n|\r\n"), tmp_string)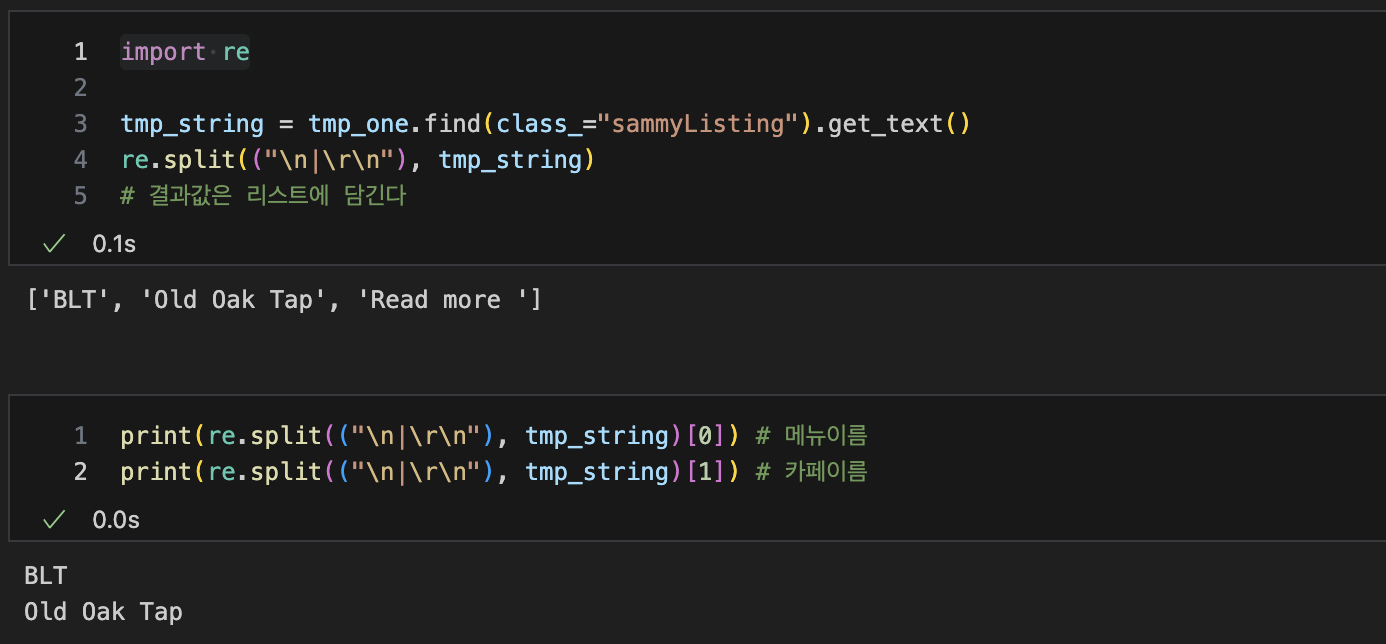
DataFrame 준비
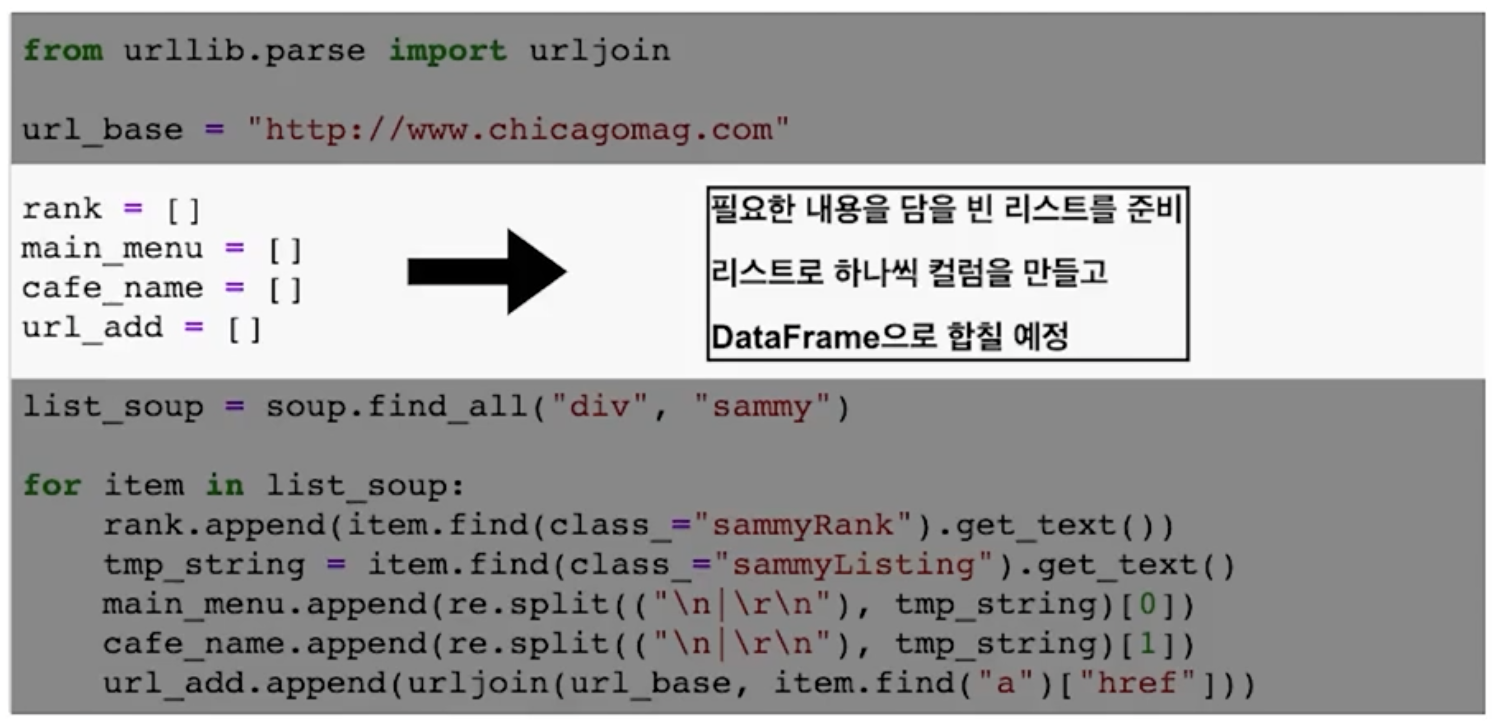
# urljoin : 변수에 담긴 주소가 있다면 그대로, 없다면 추가해서 추출
from urllib.parse import urljoin
url_add.append(urljoin(url_base, item.find("a")["href]))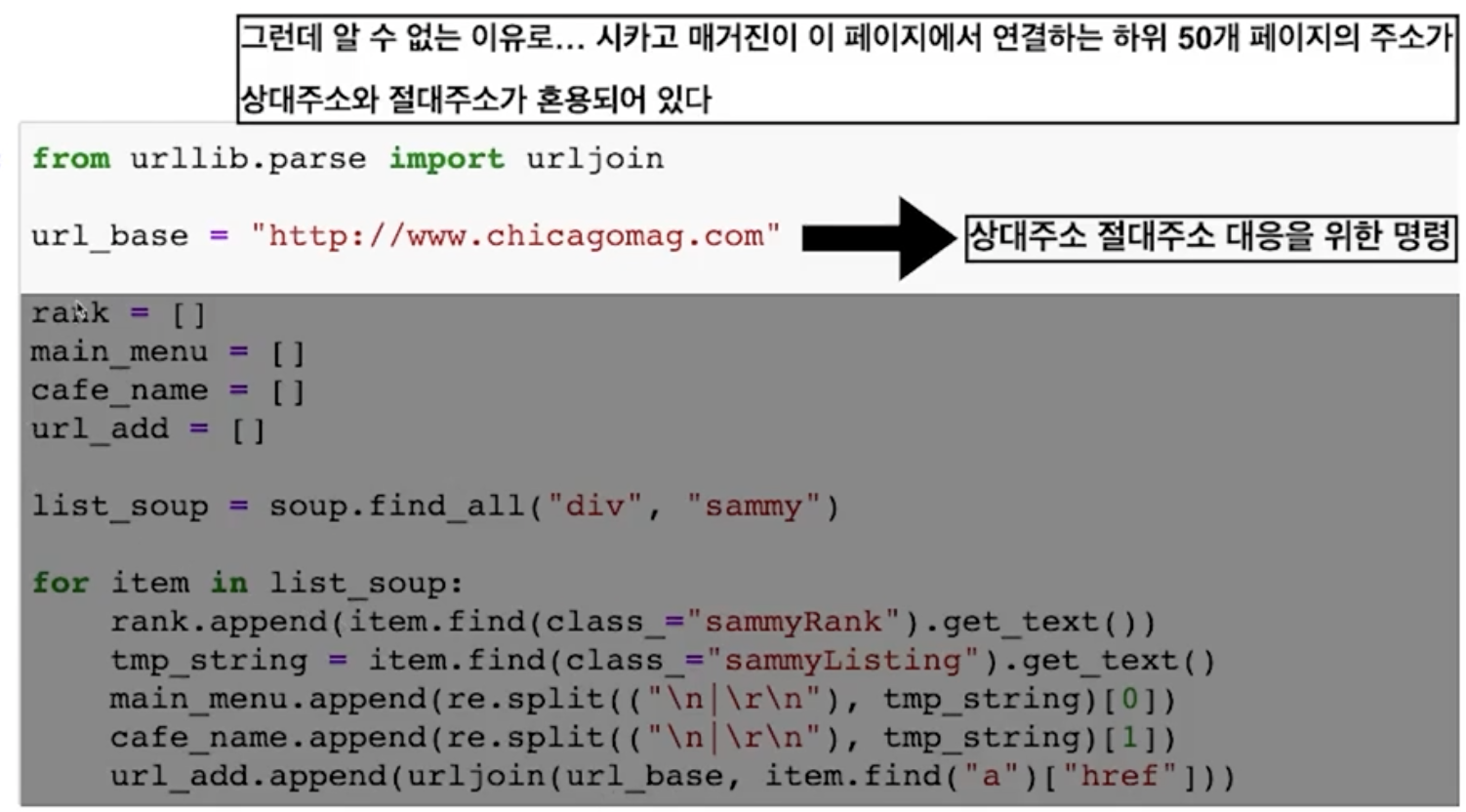
각 출력된 내용 확인
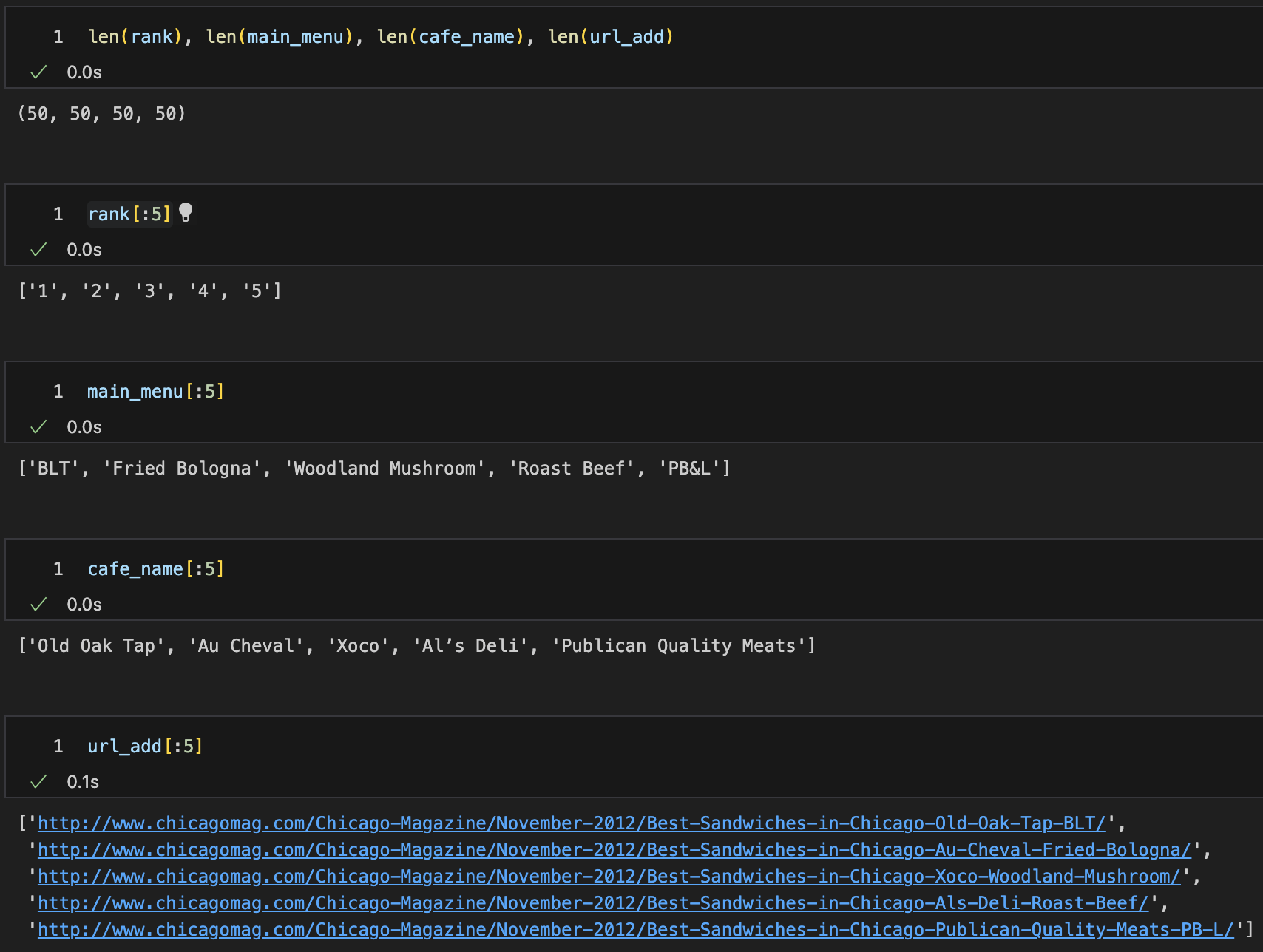
DateFrame으로 만들어내기
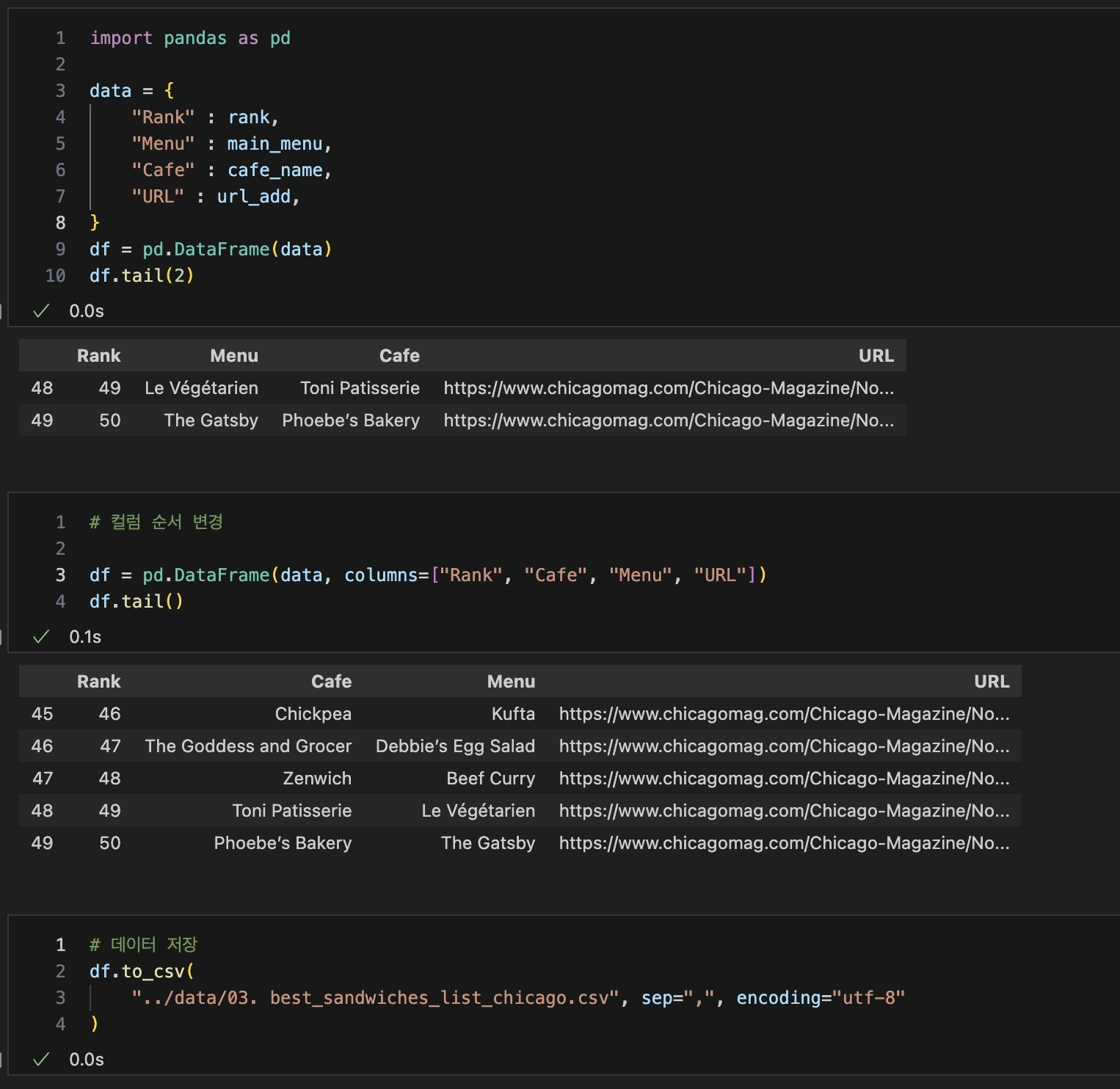
4. 시카고 맛집 데이터 분석 -하위페이지
-
import, pd.read_csv()
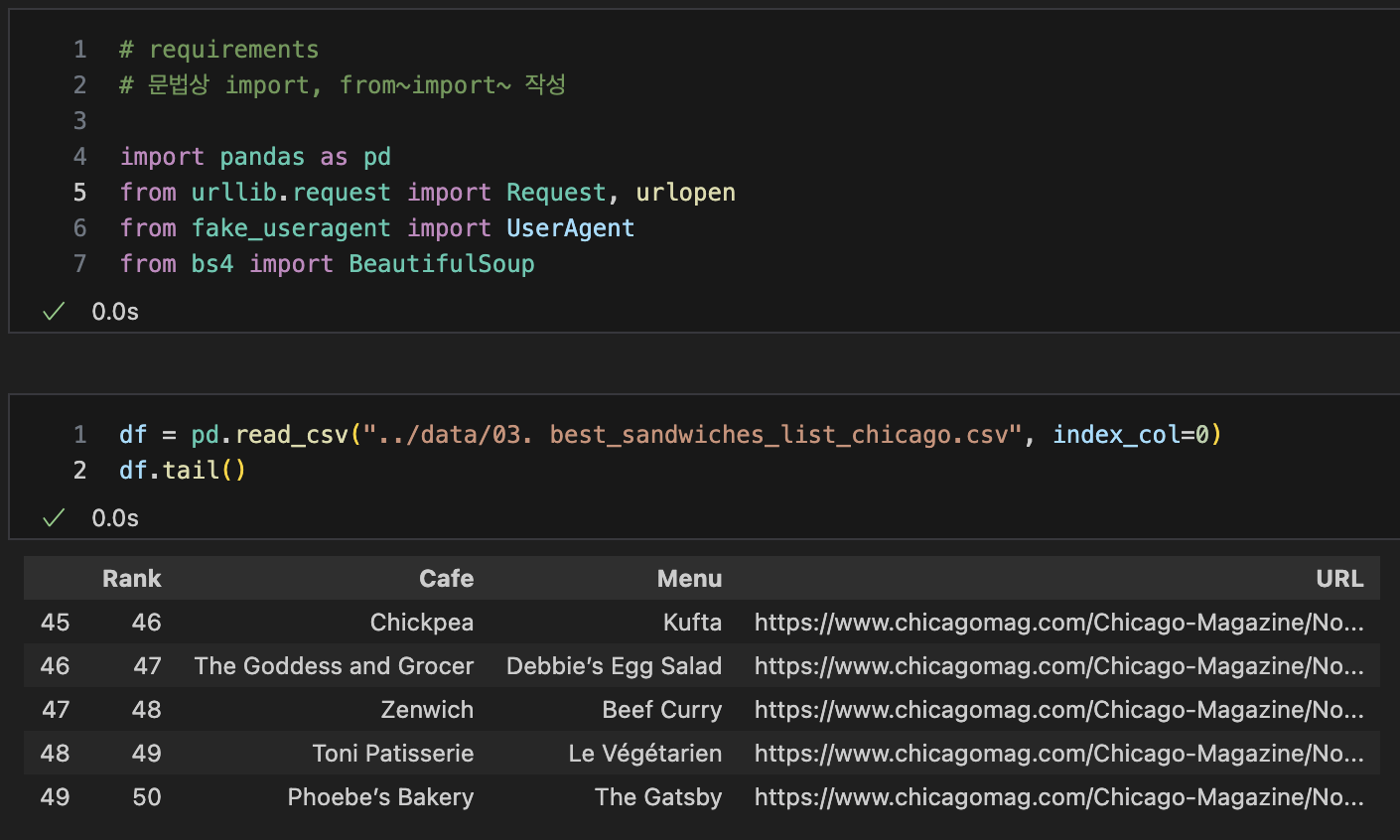
-
url(html)을 이용해 파일들을 불러와 정리할 예정
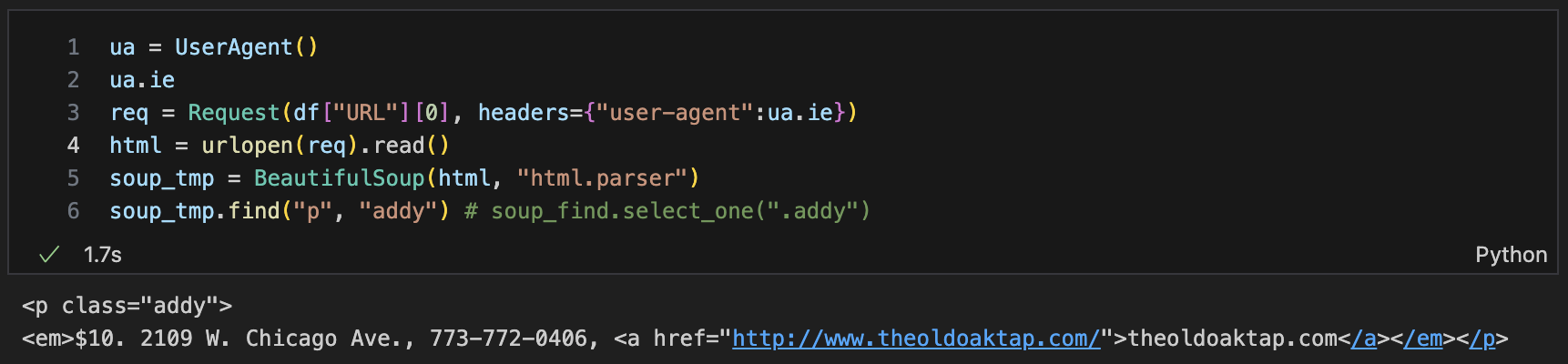
-
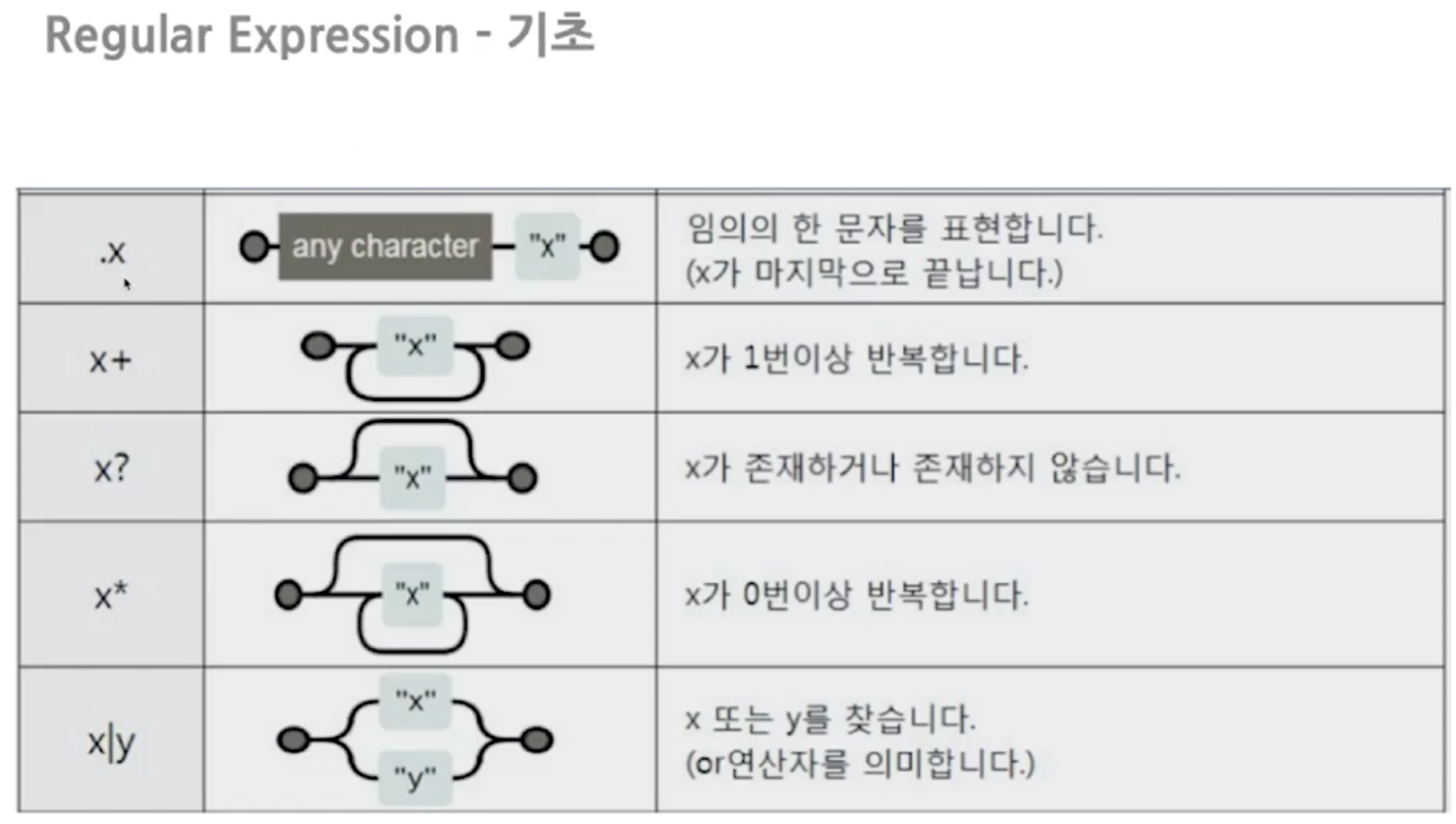
정규식(Regular Expression)

-
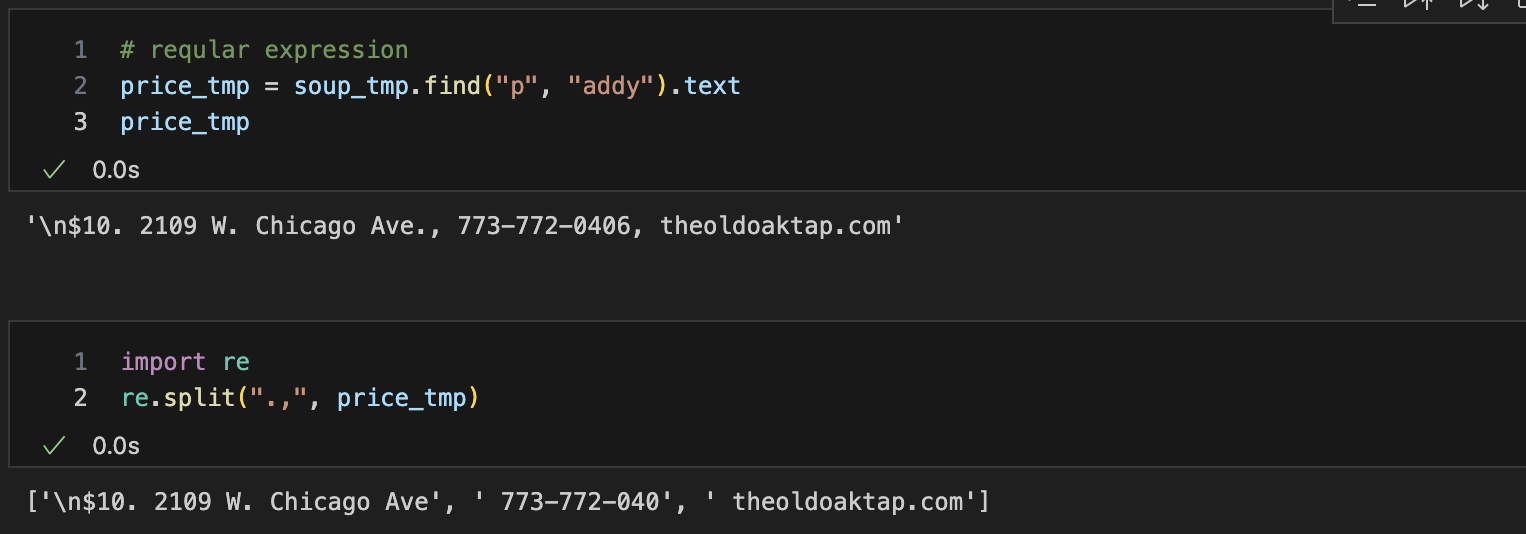
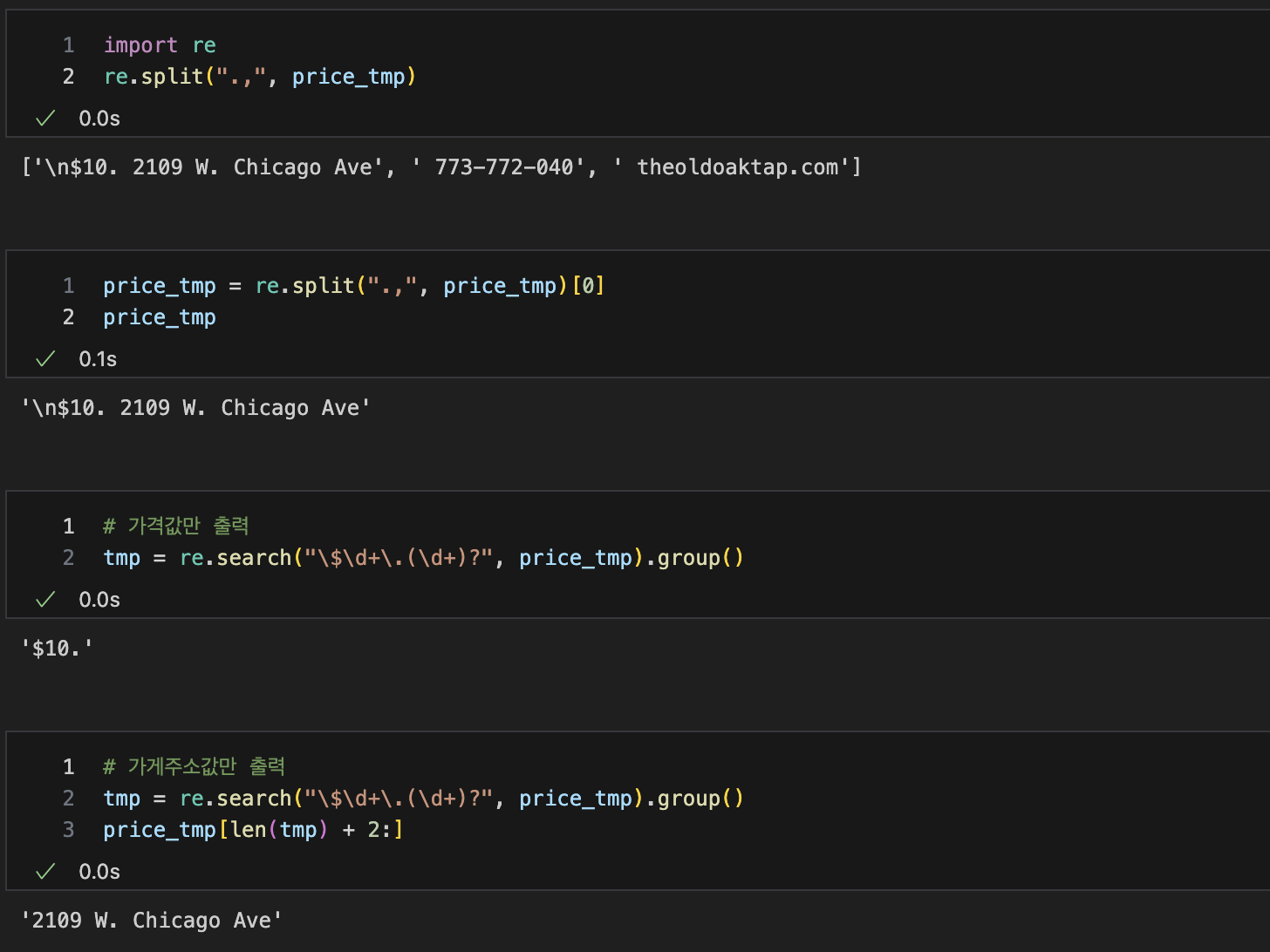
"p"태그안에 "addy"클래스 텍스트로 불러오기
-
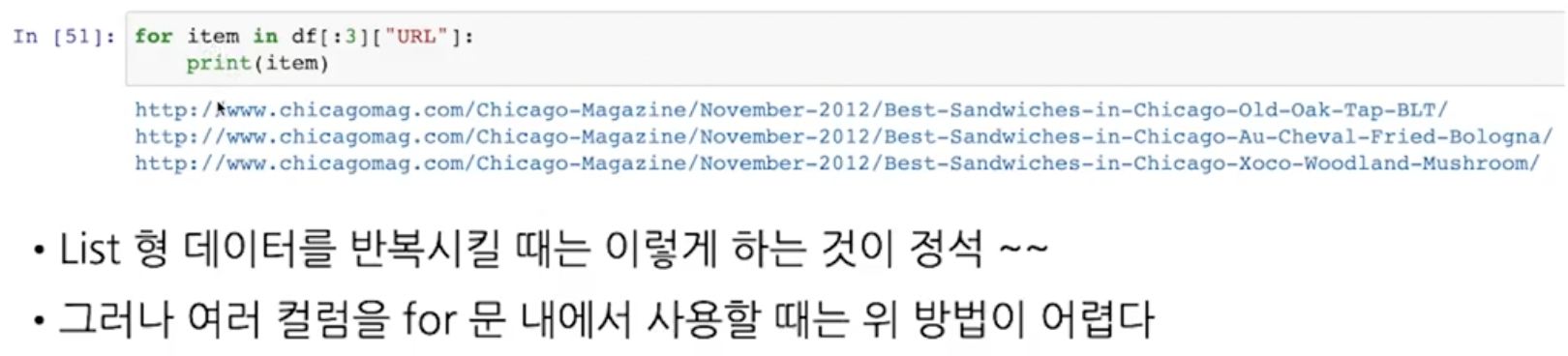
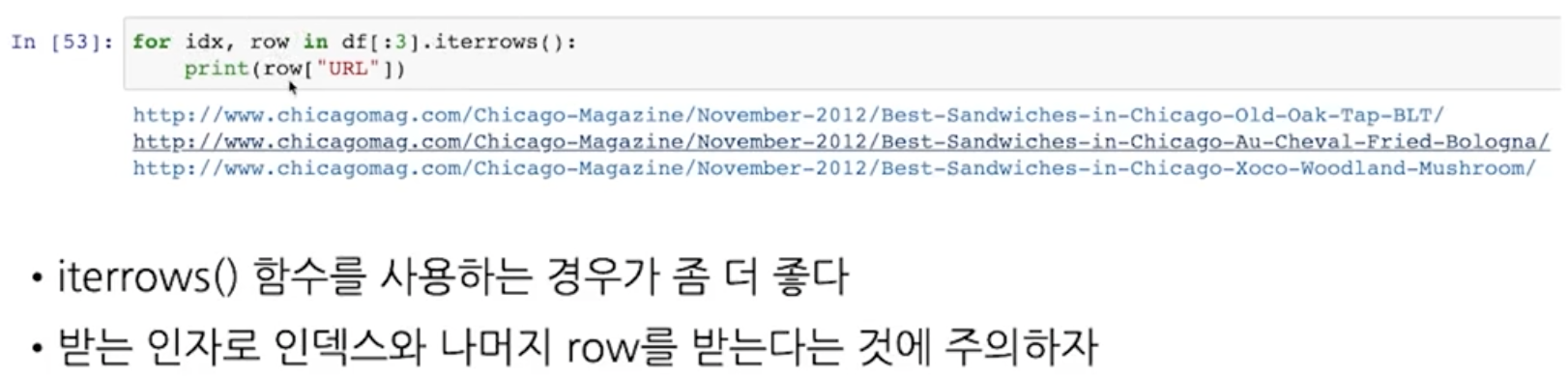
파이썬 스타일로 정리해주기
-
필요한 값들 찾아오기

-
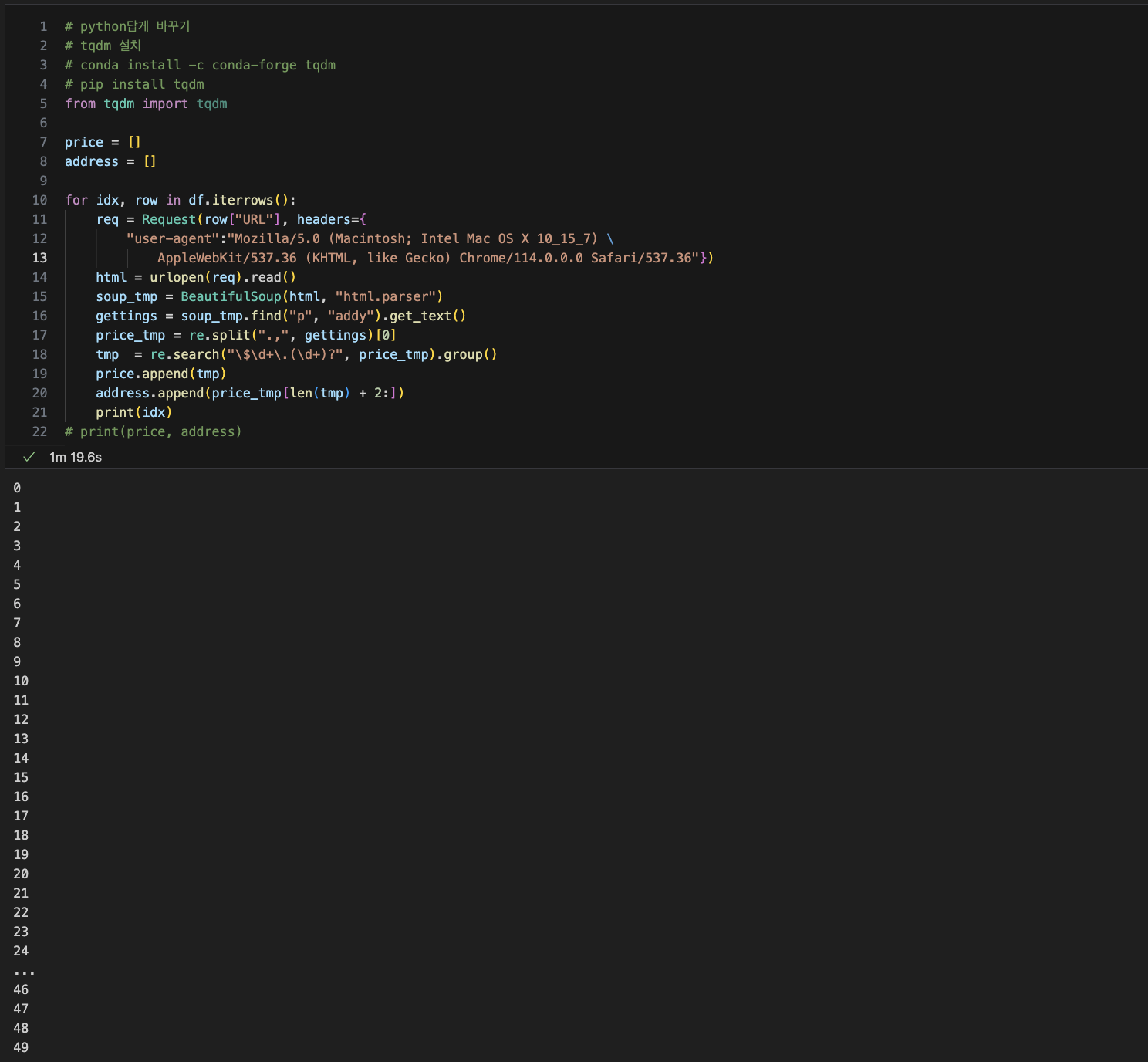
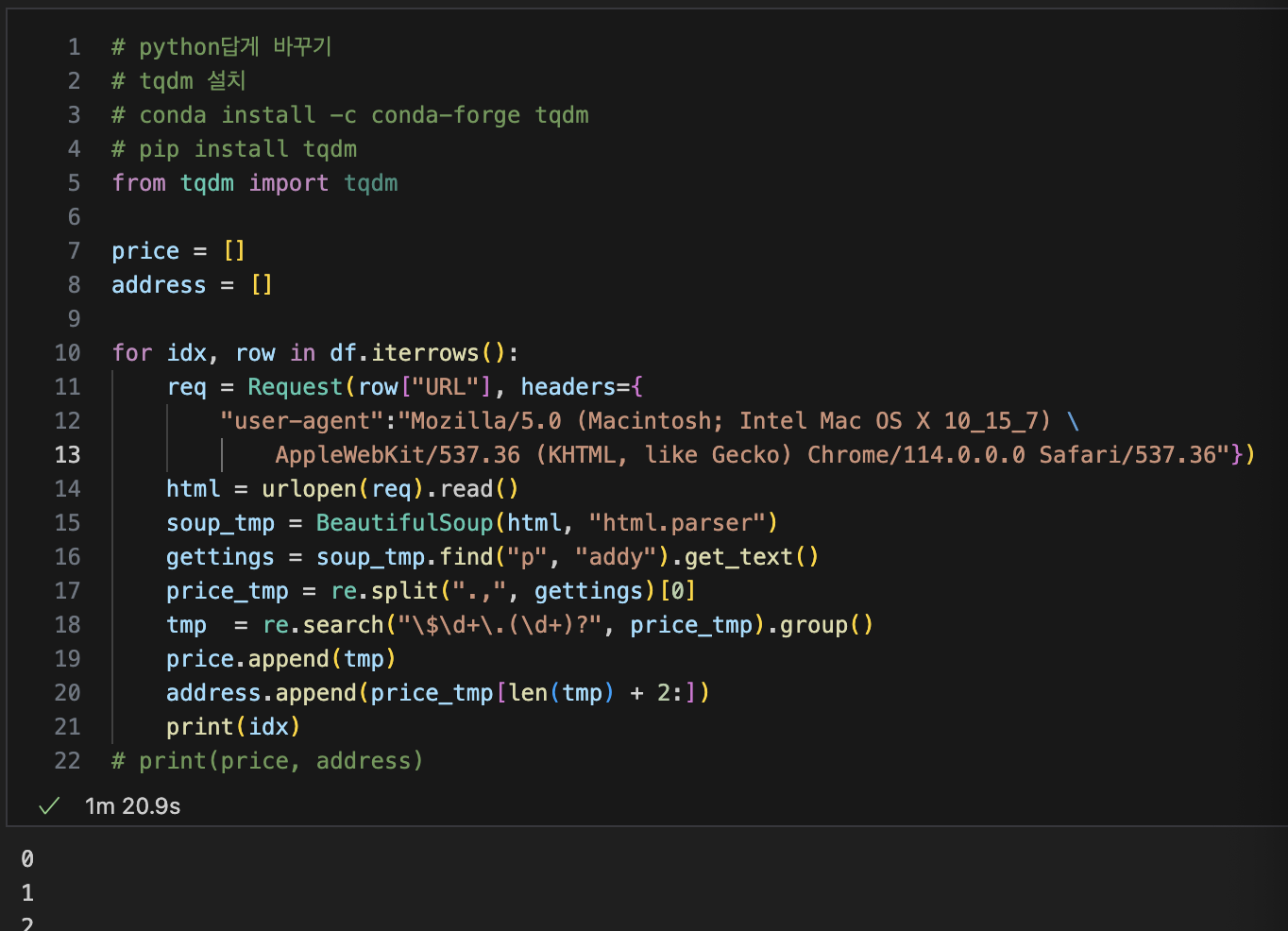
html을 이용해 가격, 주소 불러오기
-
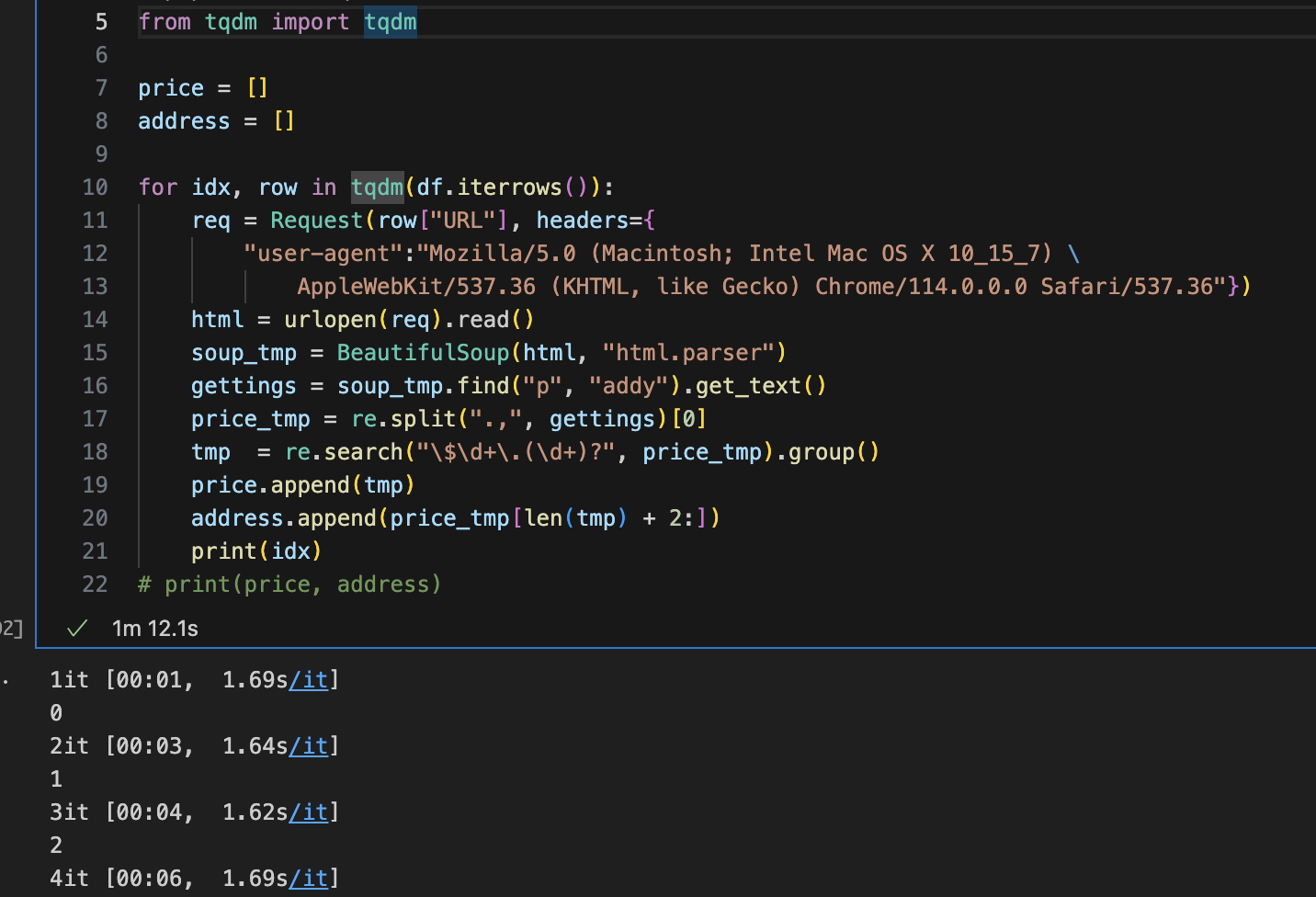
tqdm 사용
-
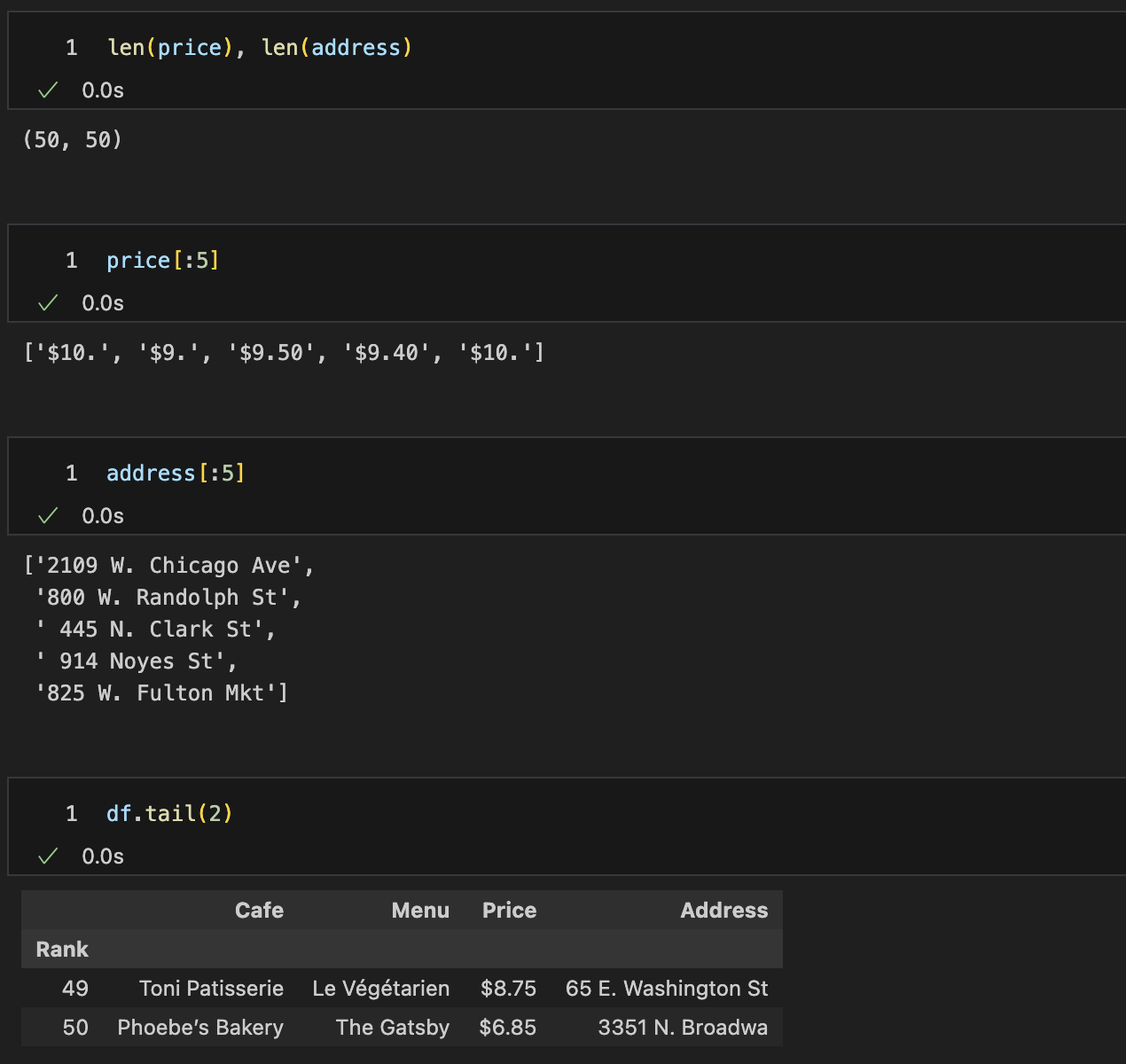
출력이 잘 되었는지 체크
-
price, address DataFrame으로 정리
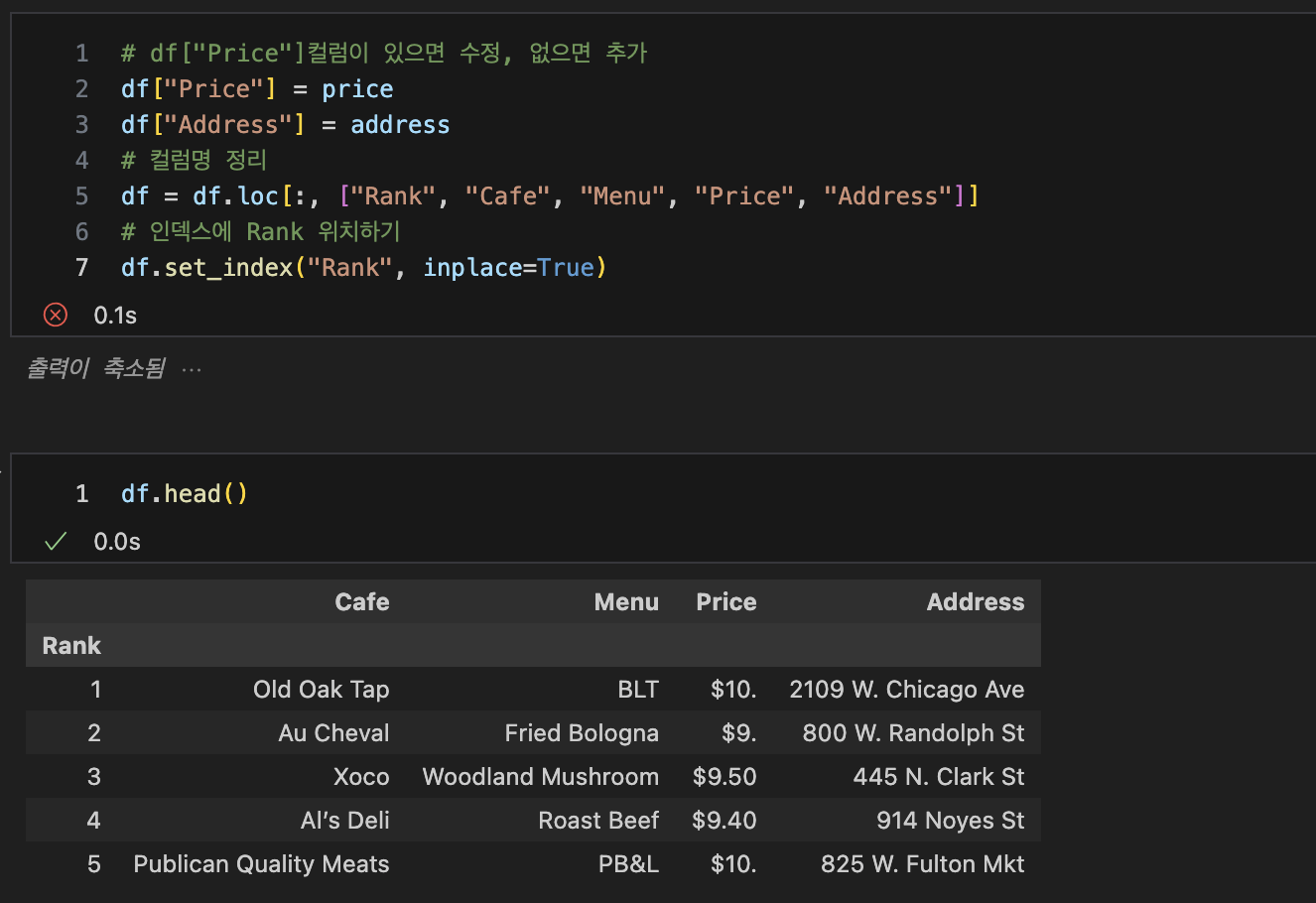
-
데이터저장, 읽기
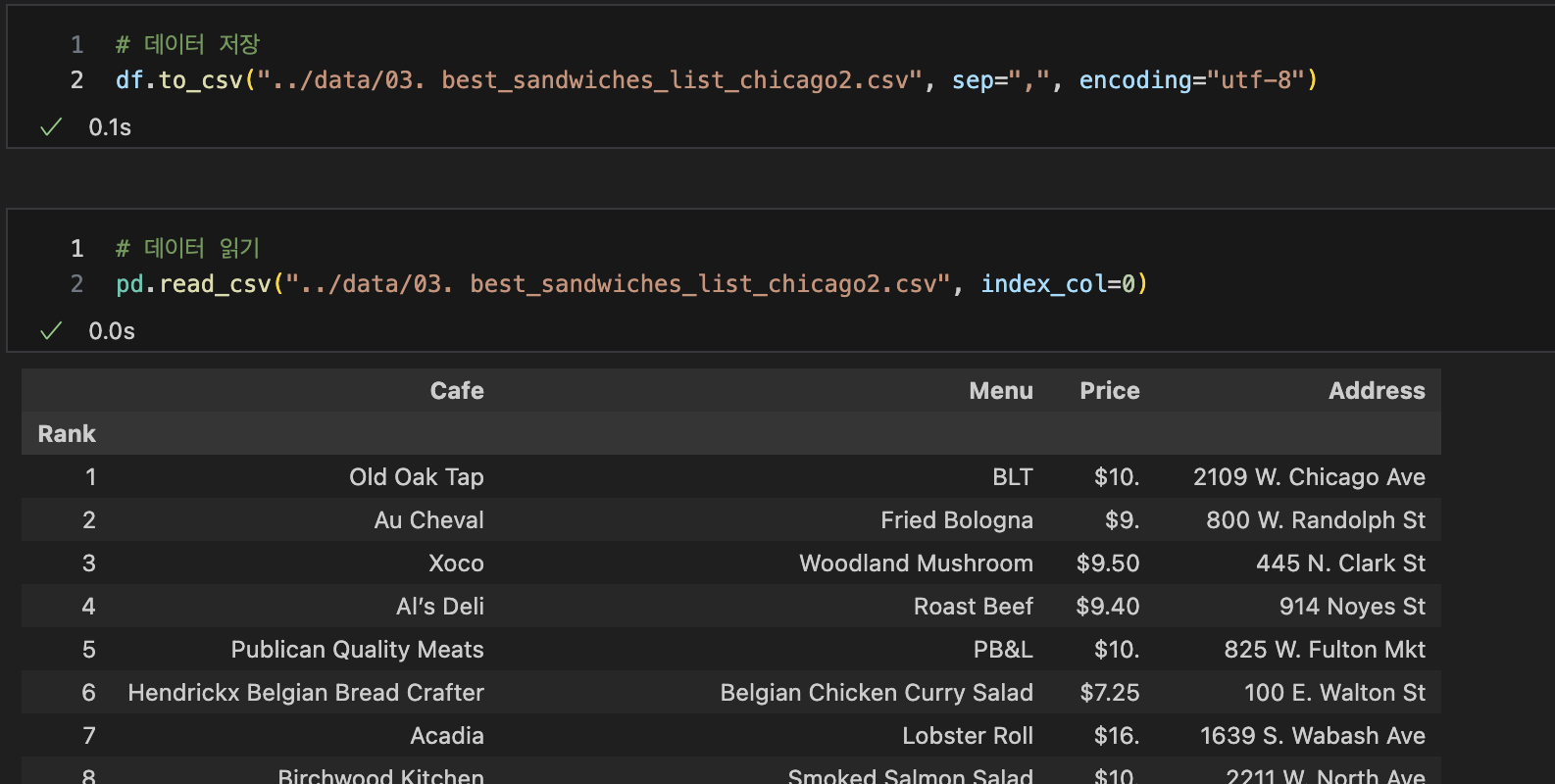
5. 시카고 맛집 데이터 지도 시각화
import, pd.read_csv()
key, gmap
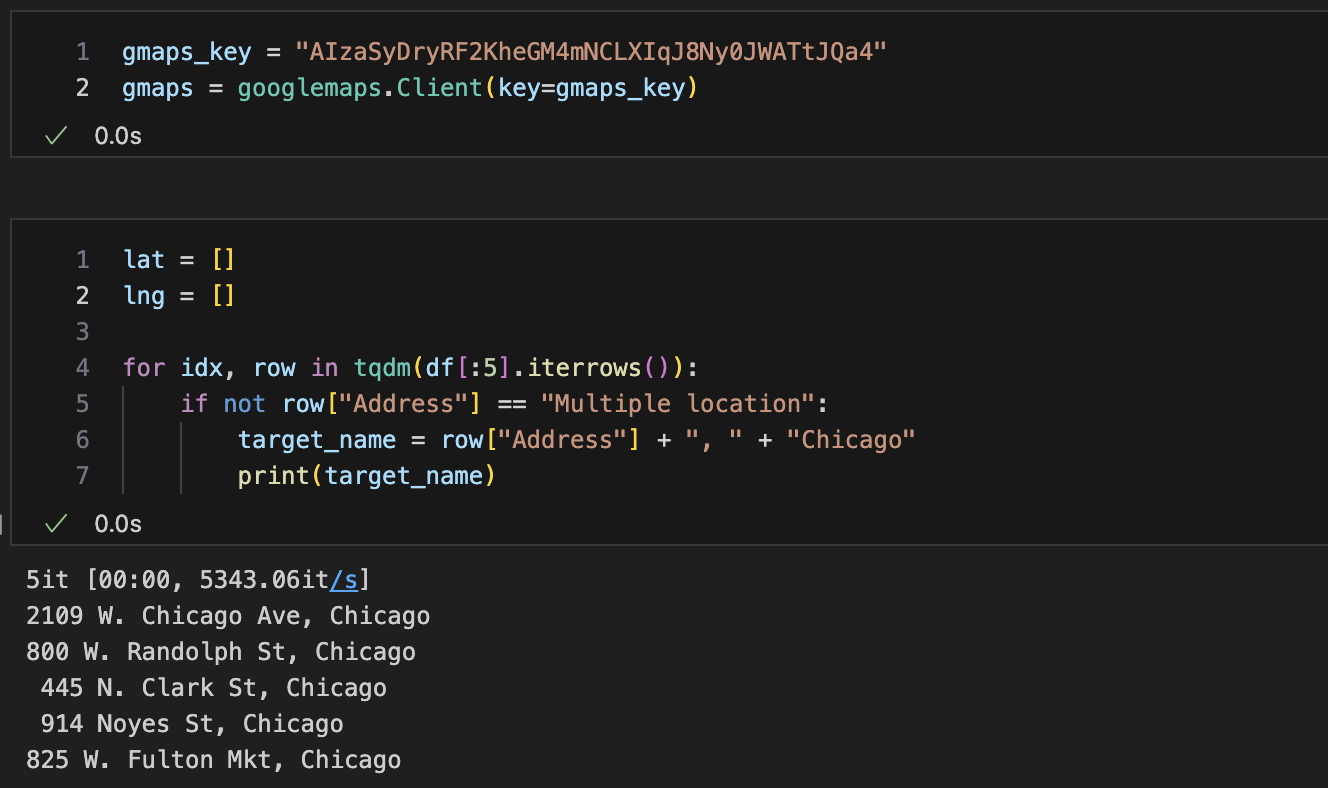
lat, lng 리스트 만들기
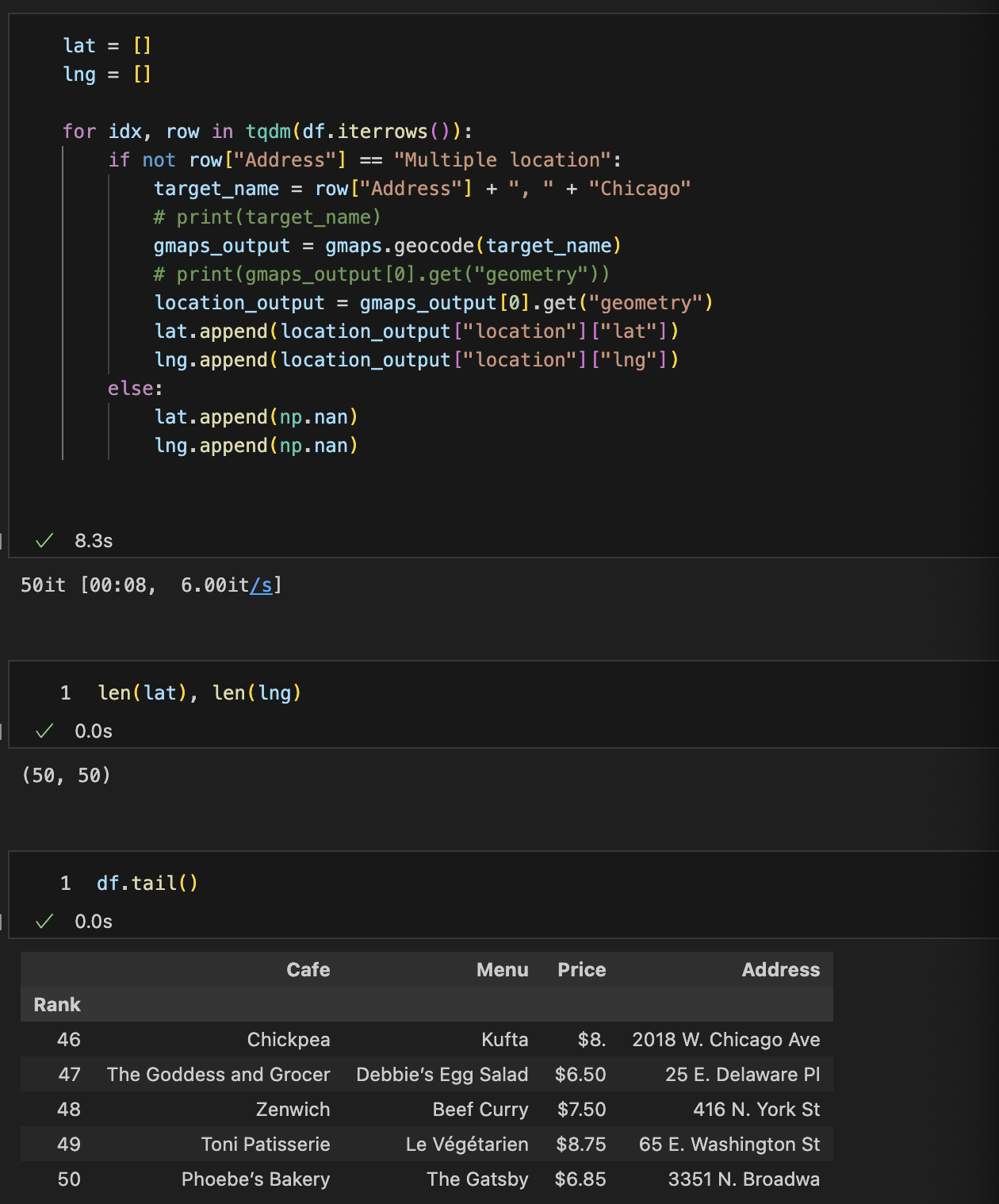
lat, lng DataFrame넣기
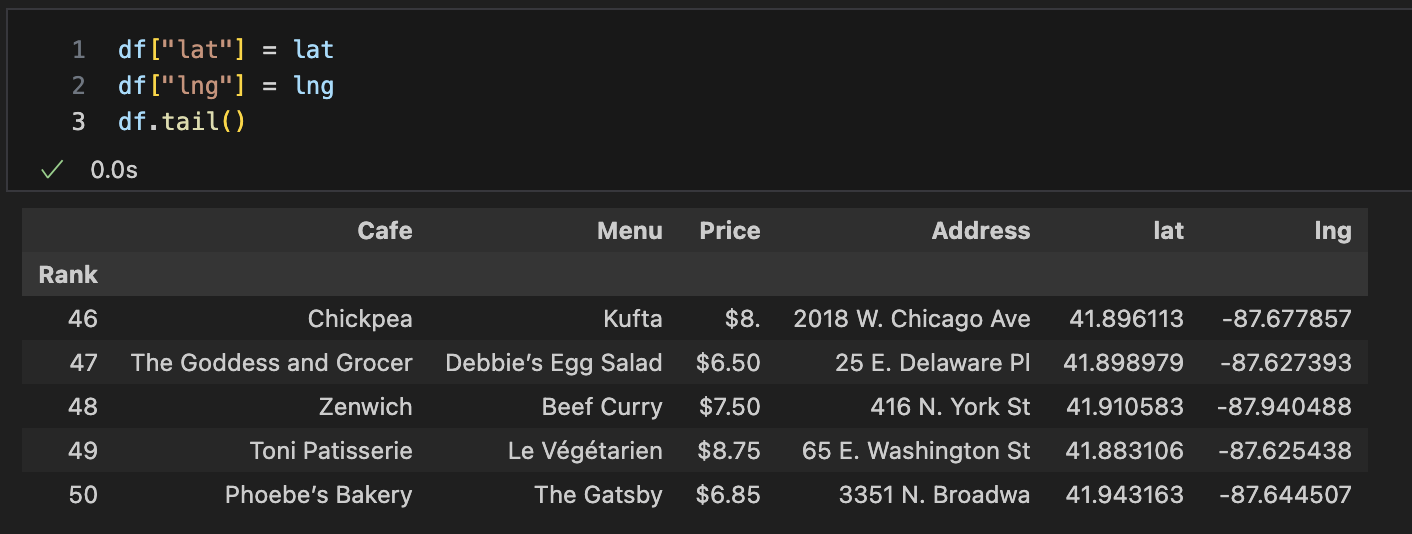
folium.Maker
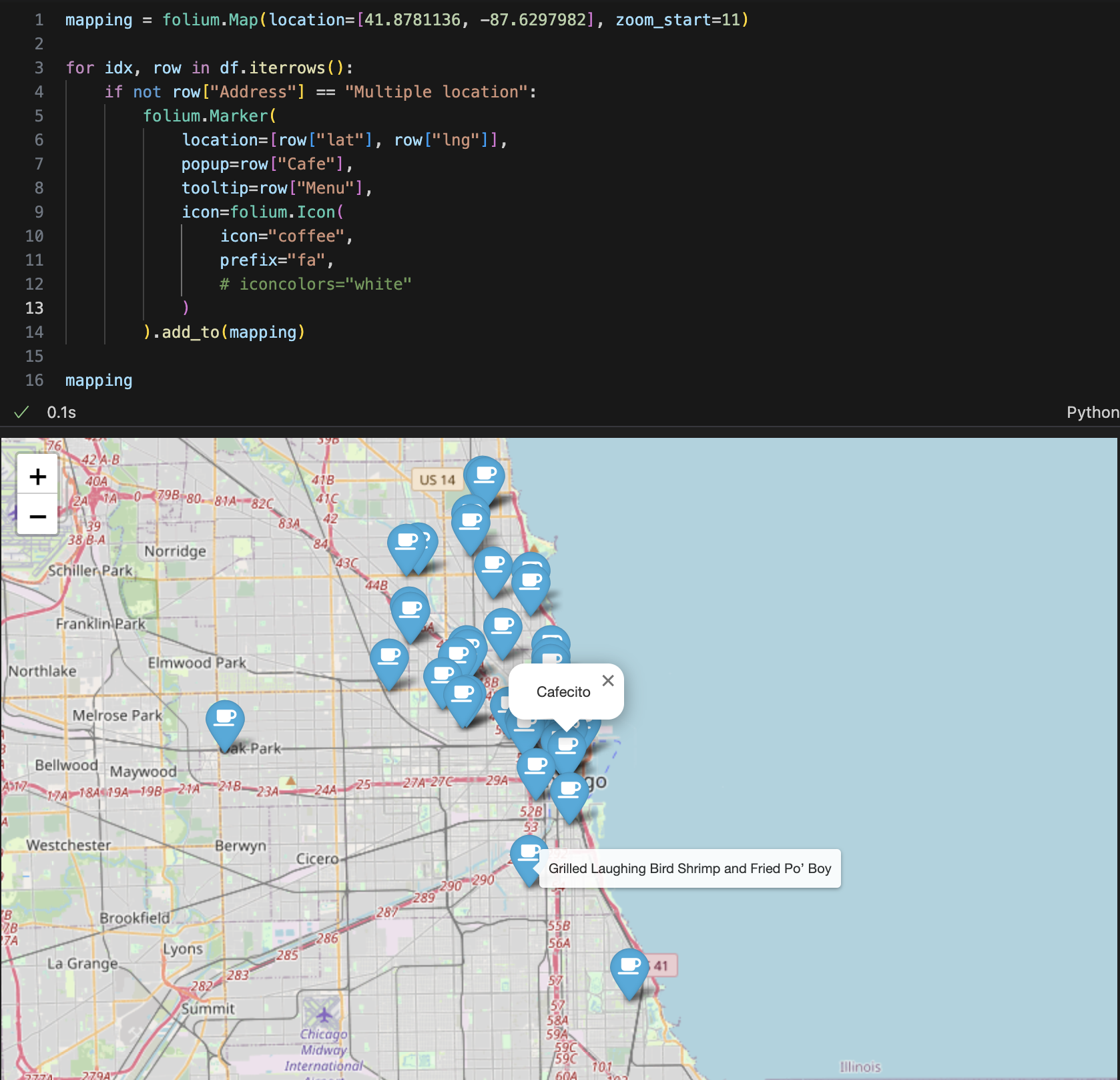
오류코드
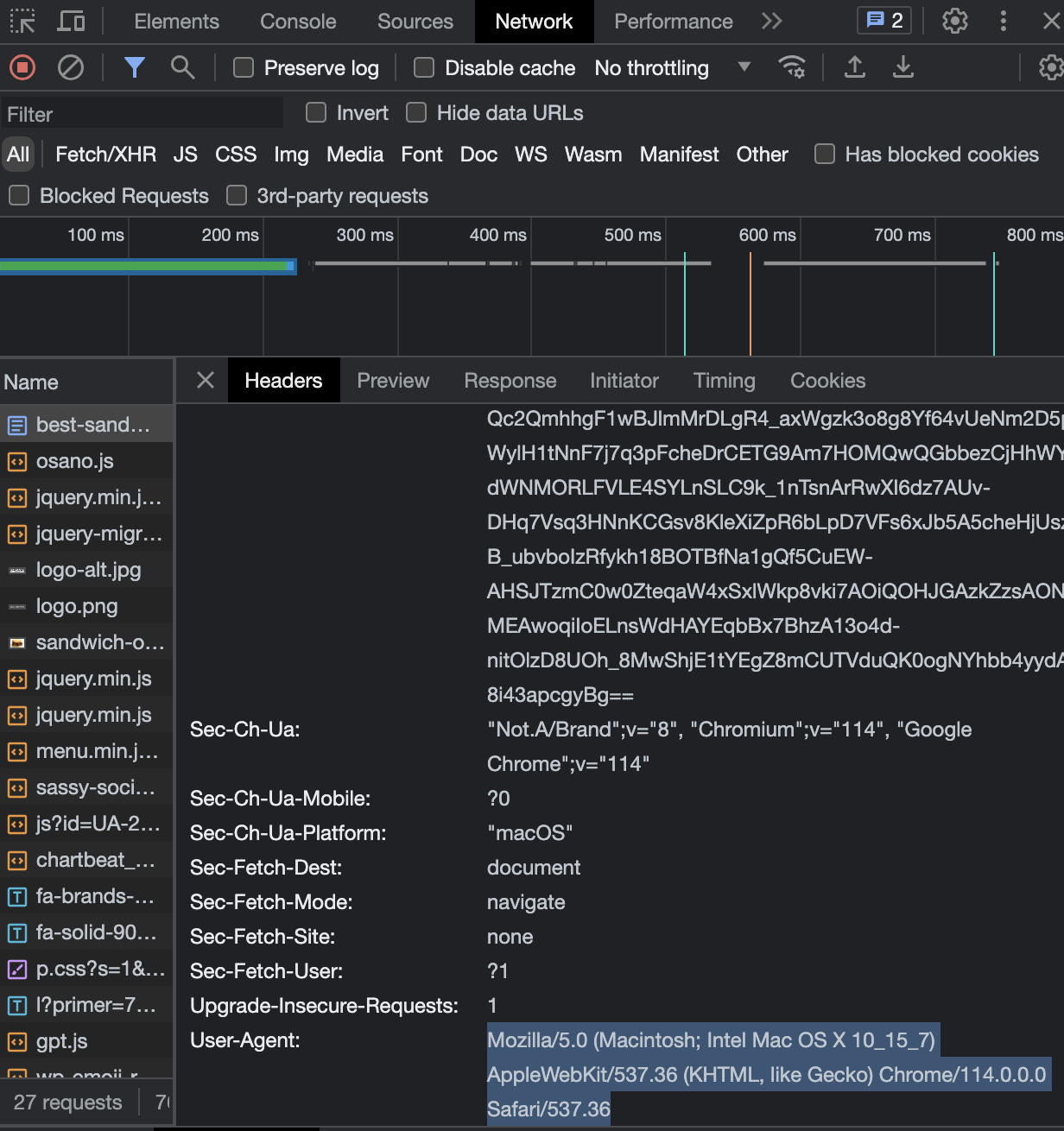
- HTTP Error 403: Forbidden
(아마도 불러오는 과정에서 작업환경에 대한 오류가 난 것 같다)
headers 오류 --> ua.ie 자리에 실제 내용으로 다 넣어줌 - 문제점

- 해결
사이트의 개발자도구에서 Network->Name에 들어가 User-Agent정보 확인