03. 웹 데이터 수집
1. Beautiful Soup for web data
Beautiful Soup Basic
- conda install -c anaconda beautifulsoup4
- pip install beatifulshop4-
data
- 03.zerobase.html
-
data_03.zerobase.html
-
Beautiful Soup import

-
html파일 읽기
-- open : "파일명"과함께 (읽기"r", 쓰기"w" )(.read(), .write()
-- html.parser : Beautiful Soup의 html읽는 엔진 중 하나
-- prettify() : html출력 이쁘게 만들어주는 기능
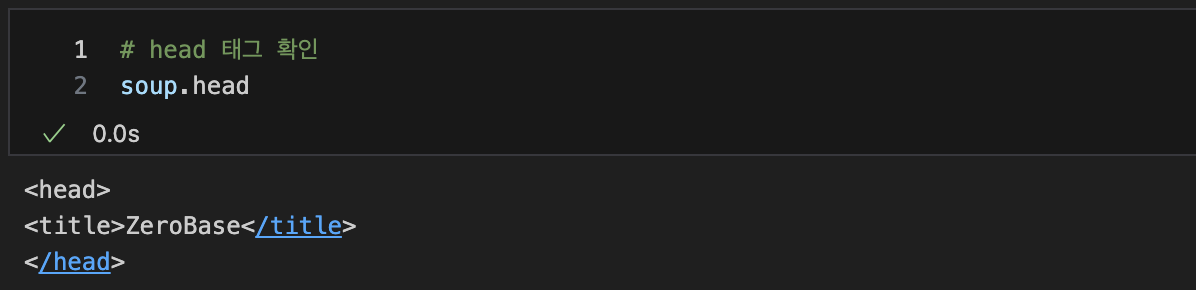
tag 확인
-
head 태그 확인
-
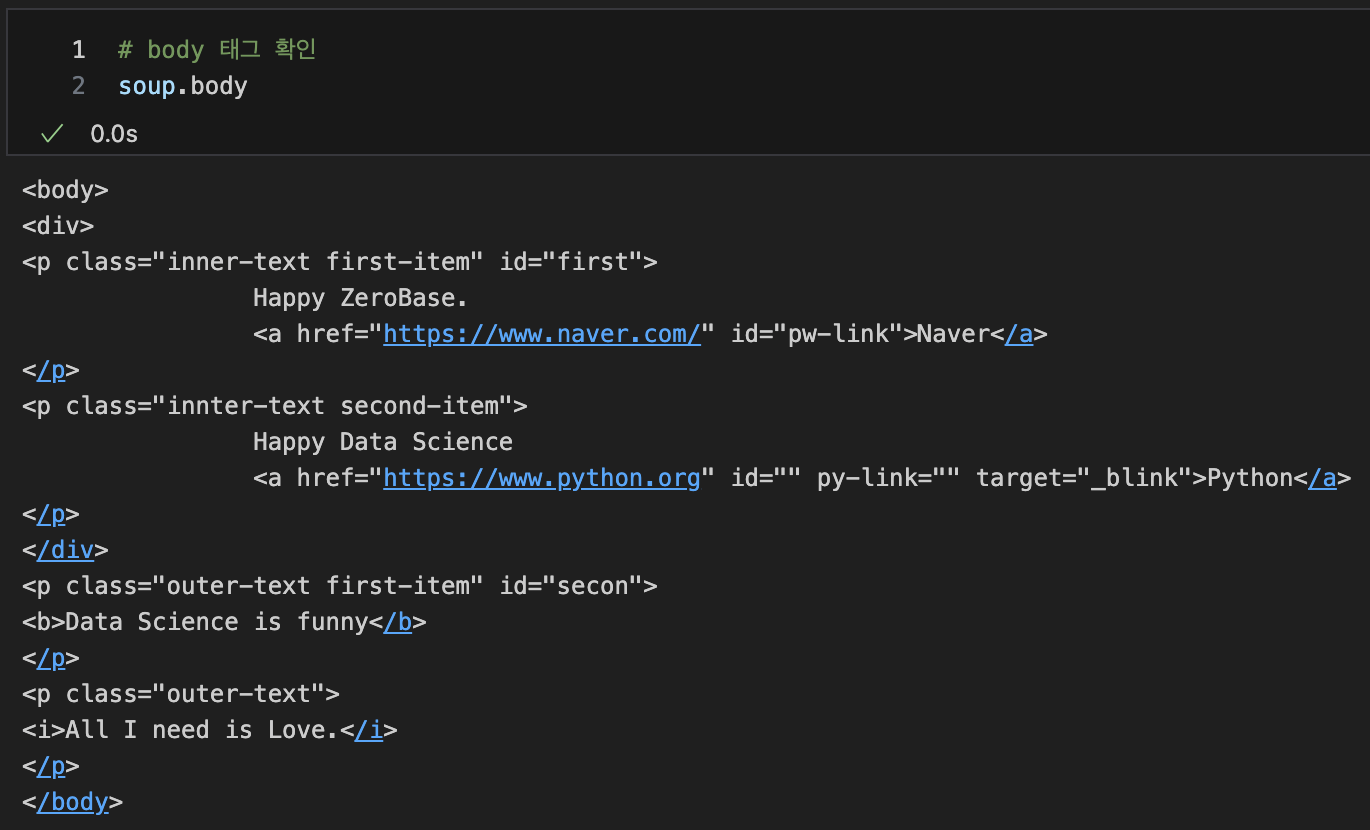
body 태그 확인
-
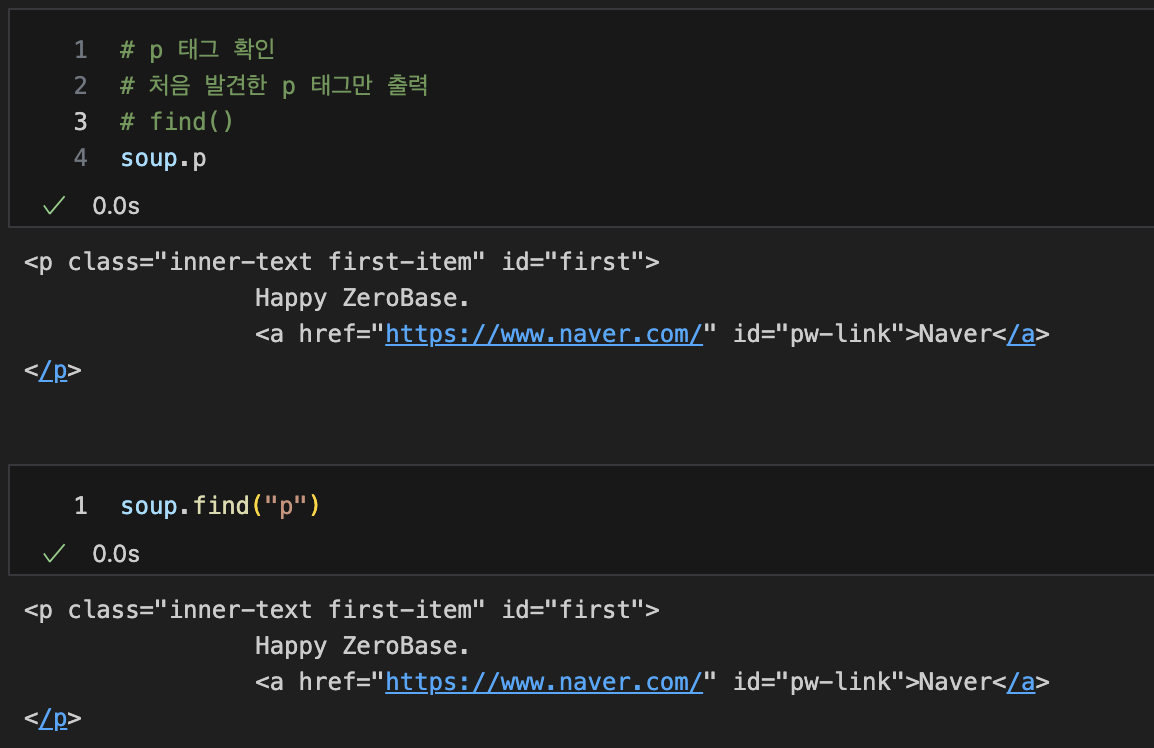
p 태그 확인
-- 처음 발견한 p 태그만 출력
-- find()
✔︎ 파이썬 예약어
✔︎ class, id, def, list, str, int, tuple...
✔︎ 사용어 겹치지 않게 사용
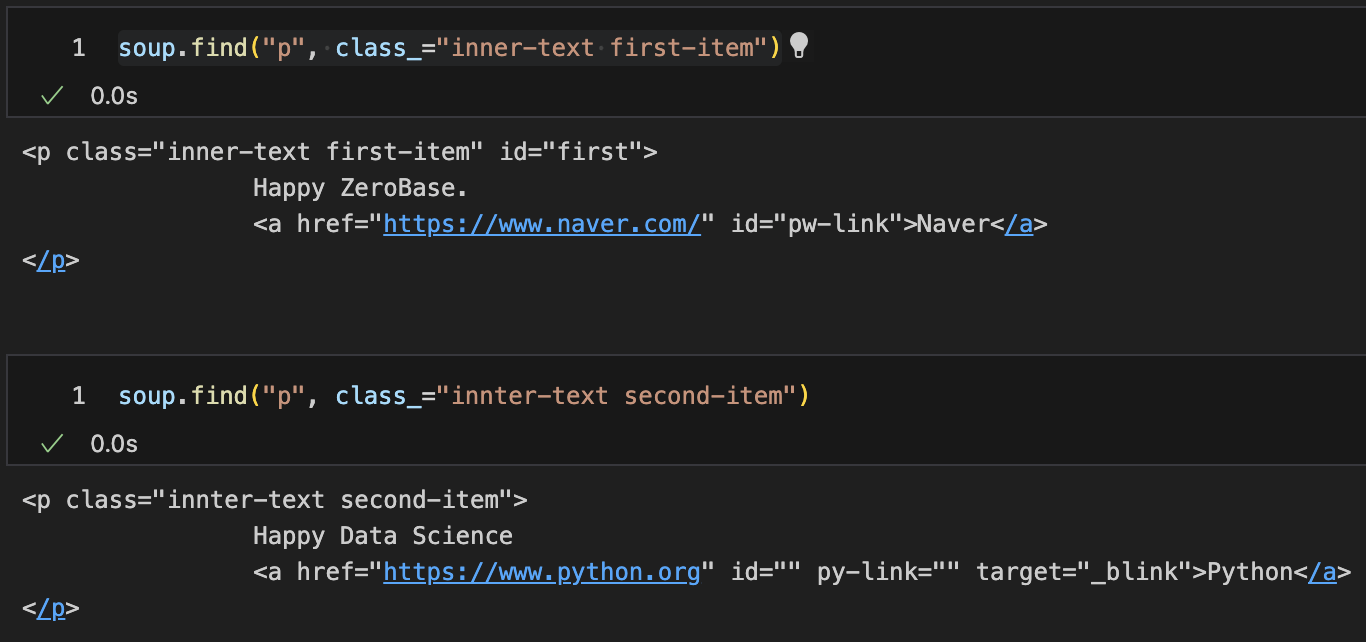
-
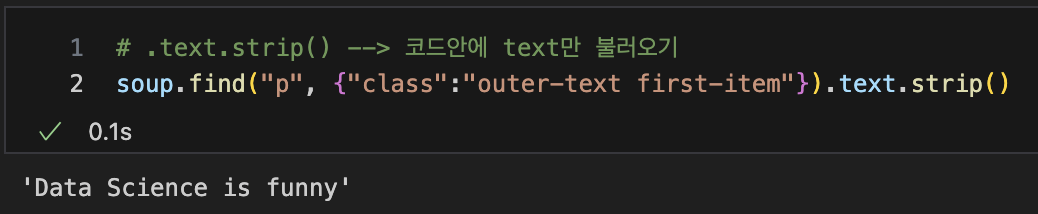
.text.strip() --> 코드안에 text만 불러오기
-
다중 조건
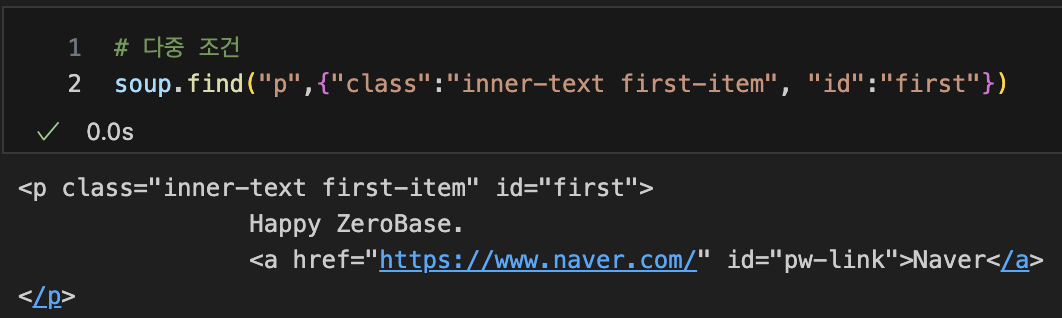
-
여러개, 두개이상의 태그 찾을때 사용
-- find_all() : 여러개의 태그를 반화
-- find_all = list 형태로 반환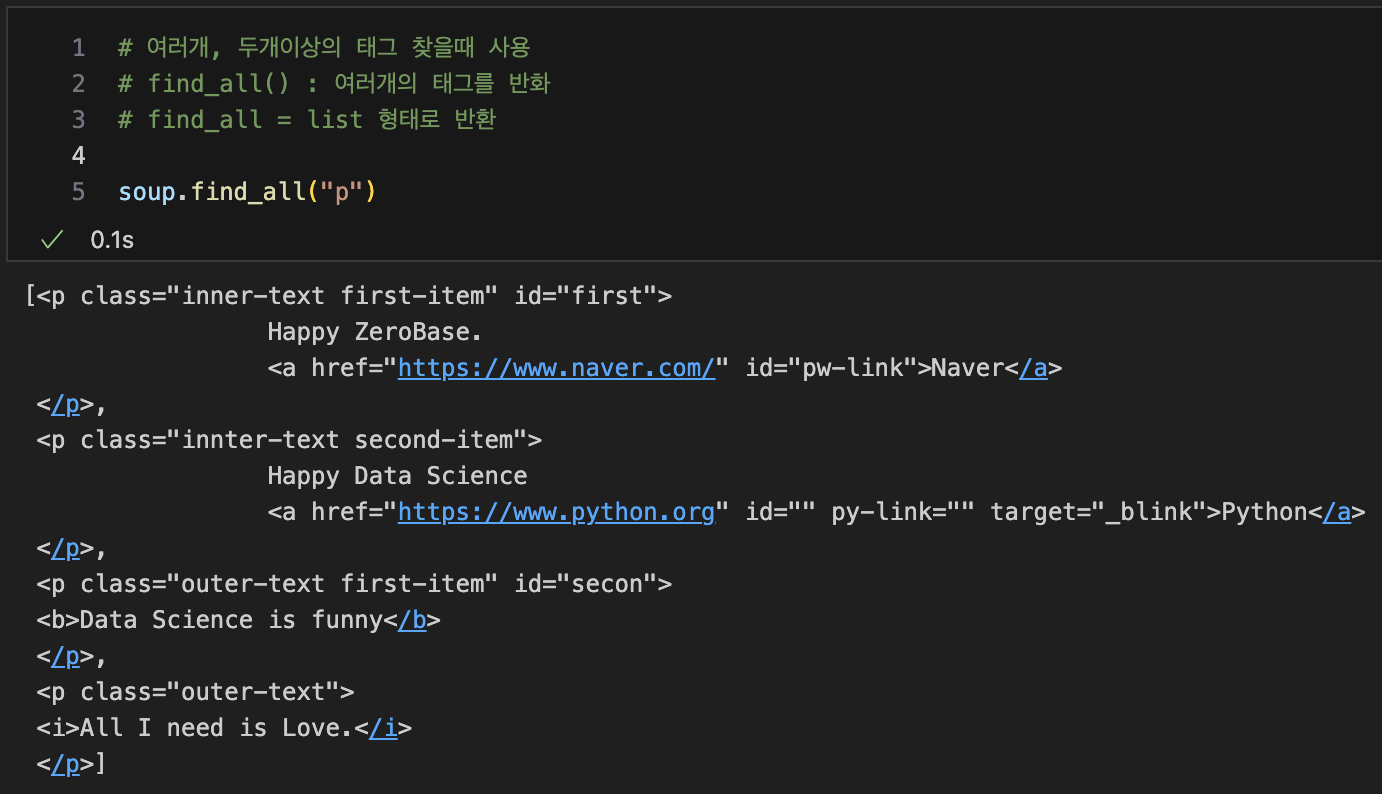
-
특정 태그 확인
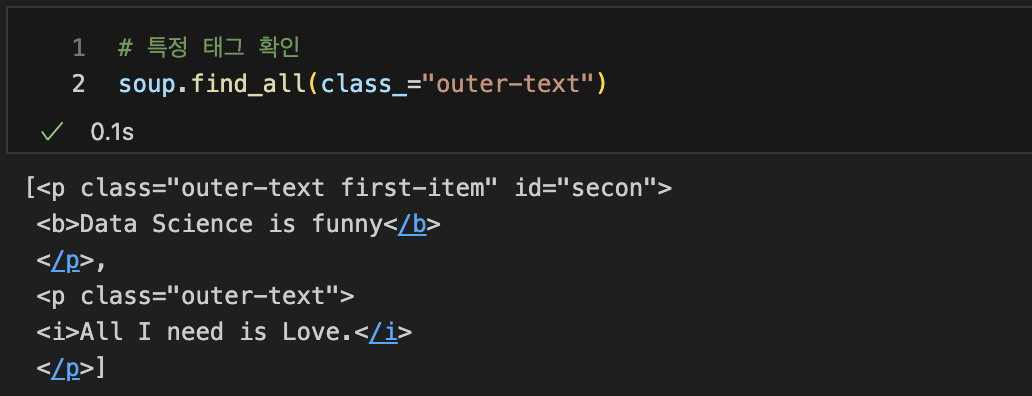
-
list 형태 데이터 text 뽑을때
-- [n].text

-
특정 태그 안에 특정 id 찾기
-- html내에서 속성 id는 한번만 나타남 find_all()함수는 의미가 없다
-- 단, 검색결과를 list로 받고 싶다면 id라도 find_all()함수 사용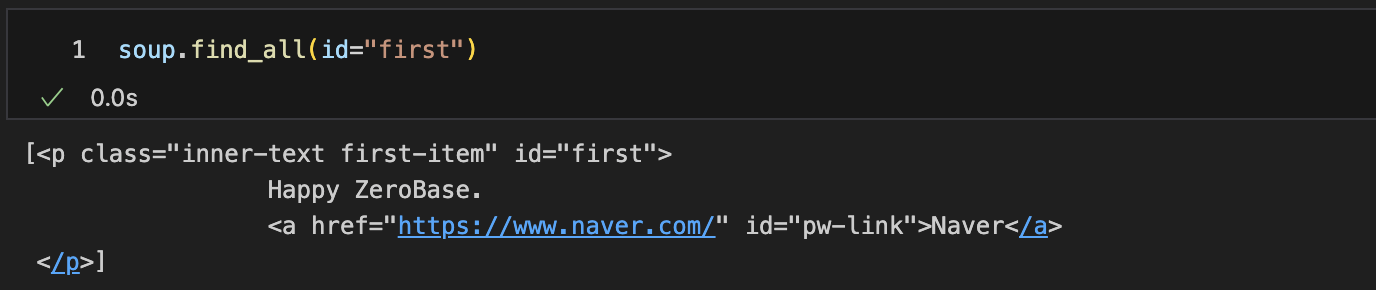
-
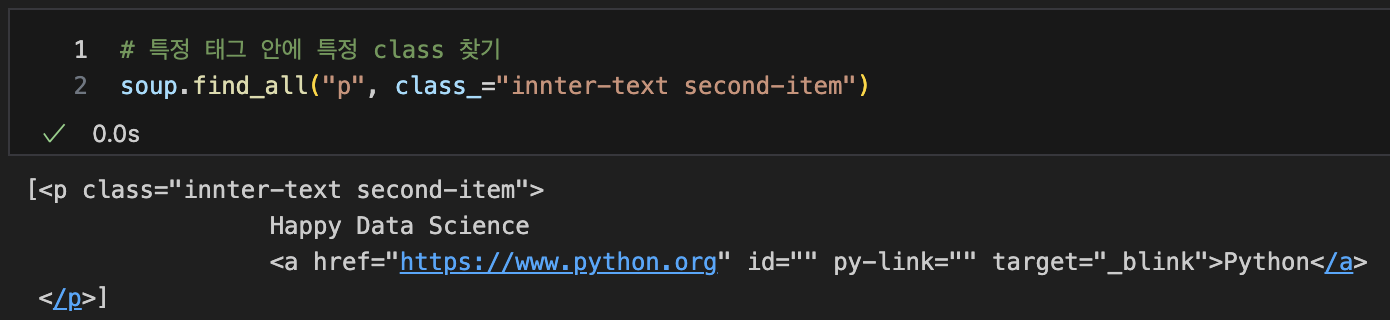
특정 태그 안에 특정 class 찾기
-
특정 태그 길이확인
-
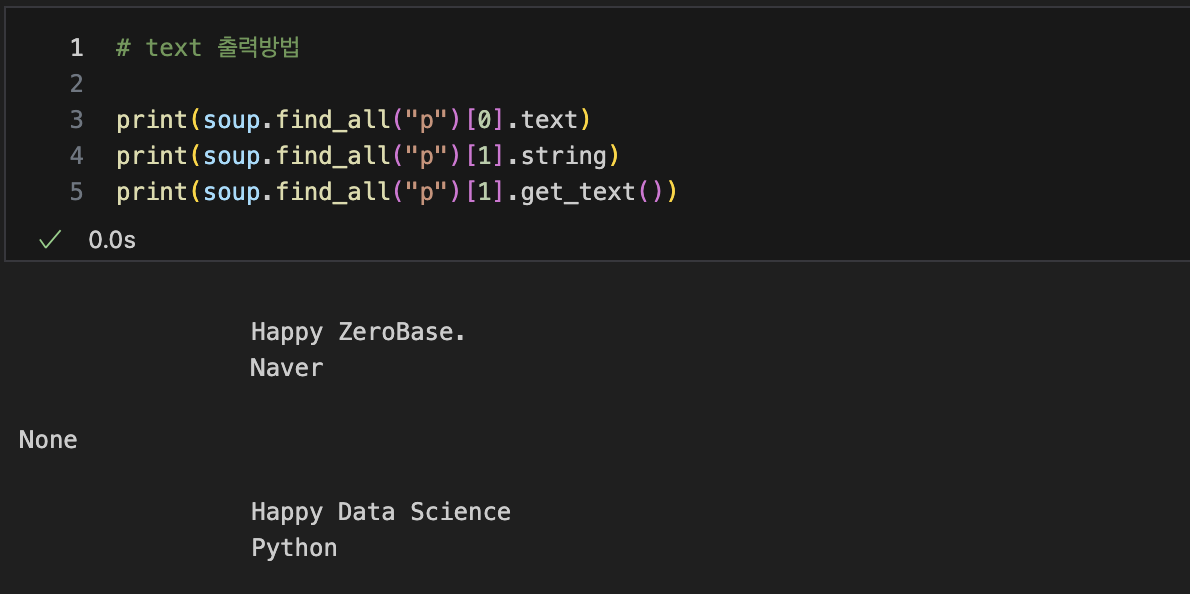
text 출력방법
-
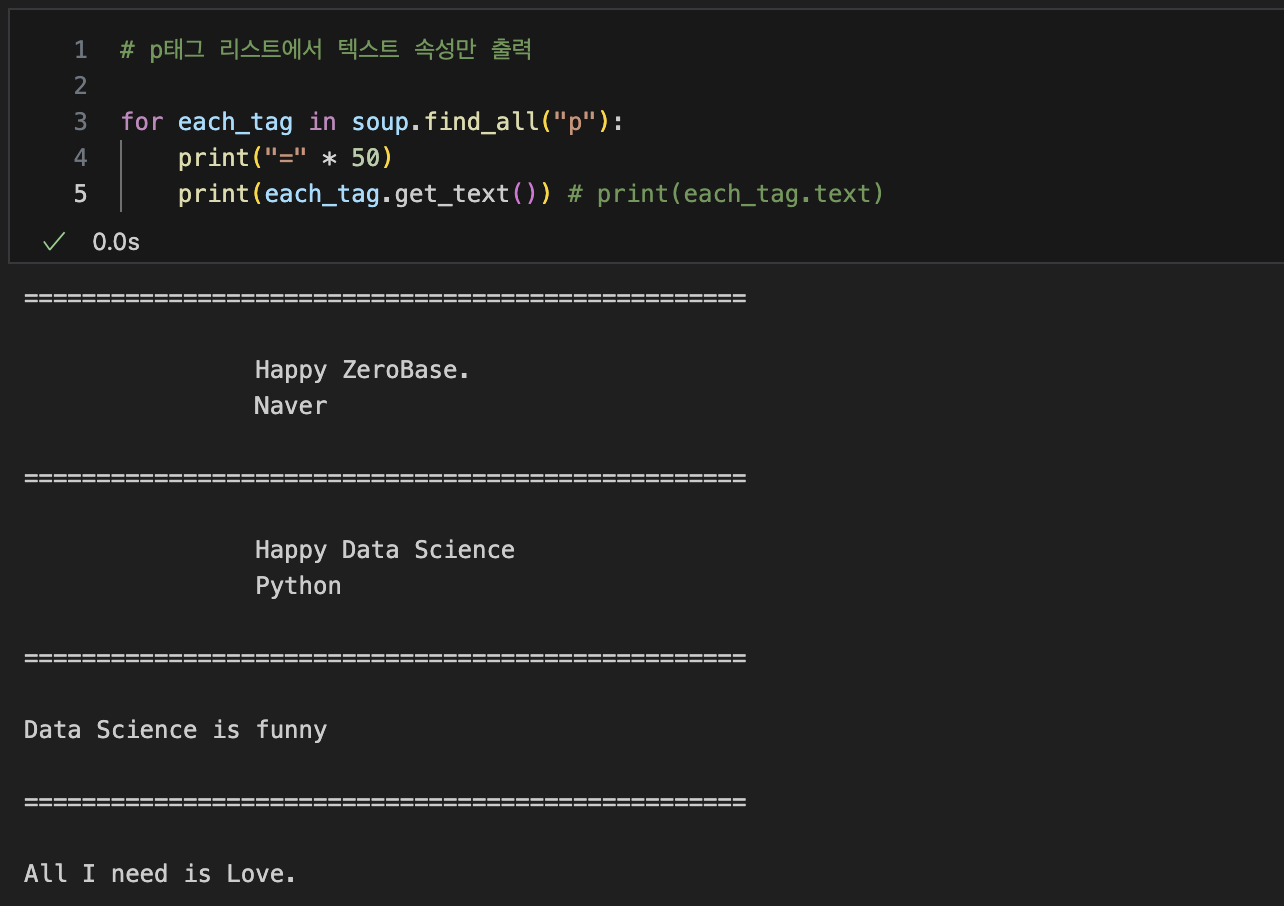
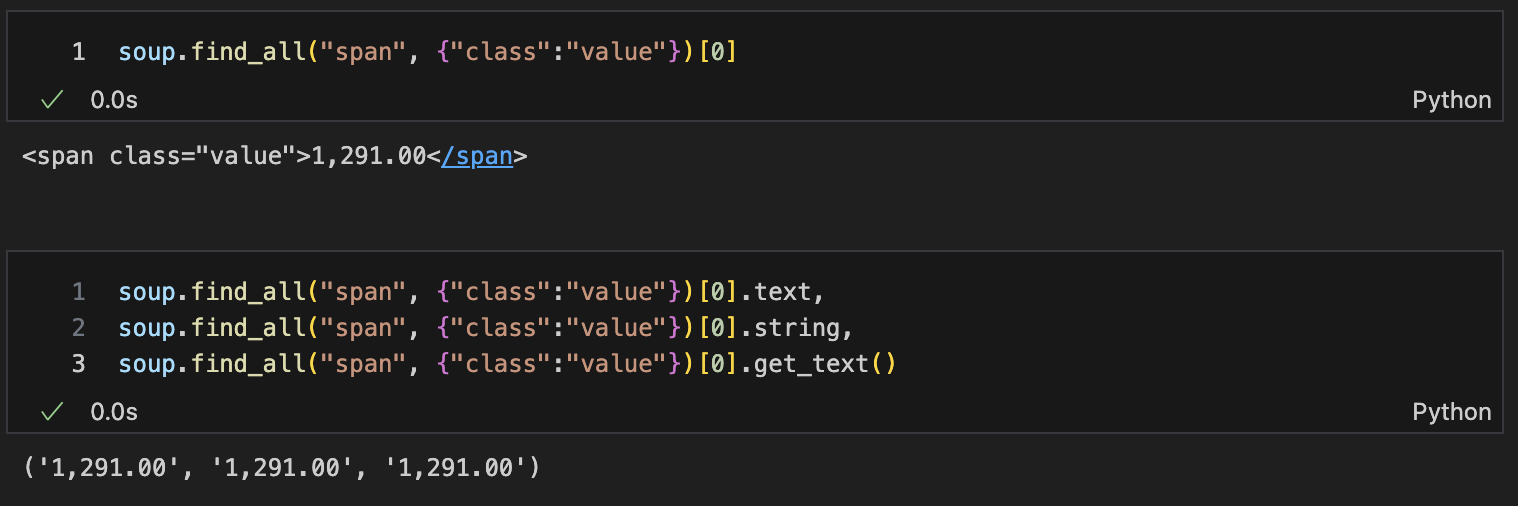
p태그 리스트에서 텍스트 속성만 출력
-- .get_text() : text만 출력
-
a 태그에 있는 href 속성값, 속성값의 text 추출
-- link의 제목(text)만 가져오고 싶다면 --> each.get_text() / each.string 사용
-- link의 주소(href)만 가져오고 싶다면 --> each.get("href) / each["href"] 사용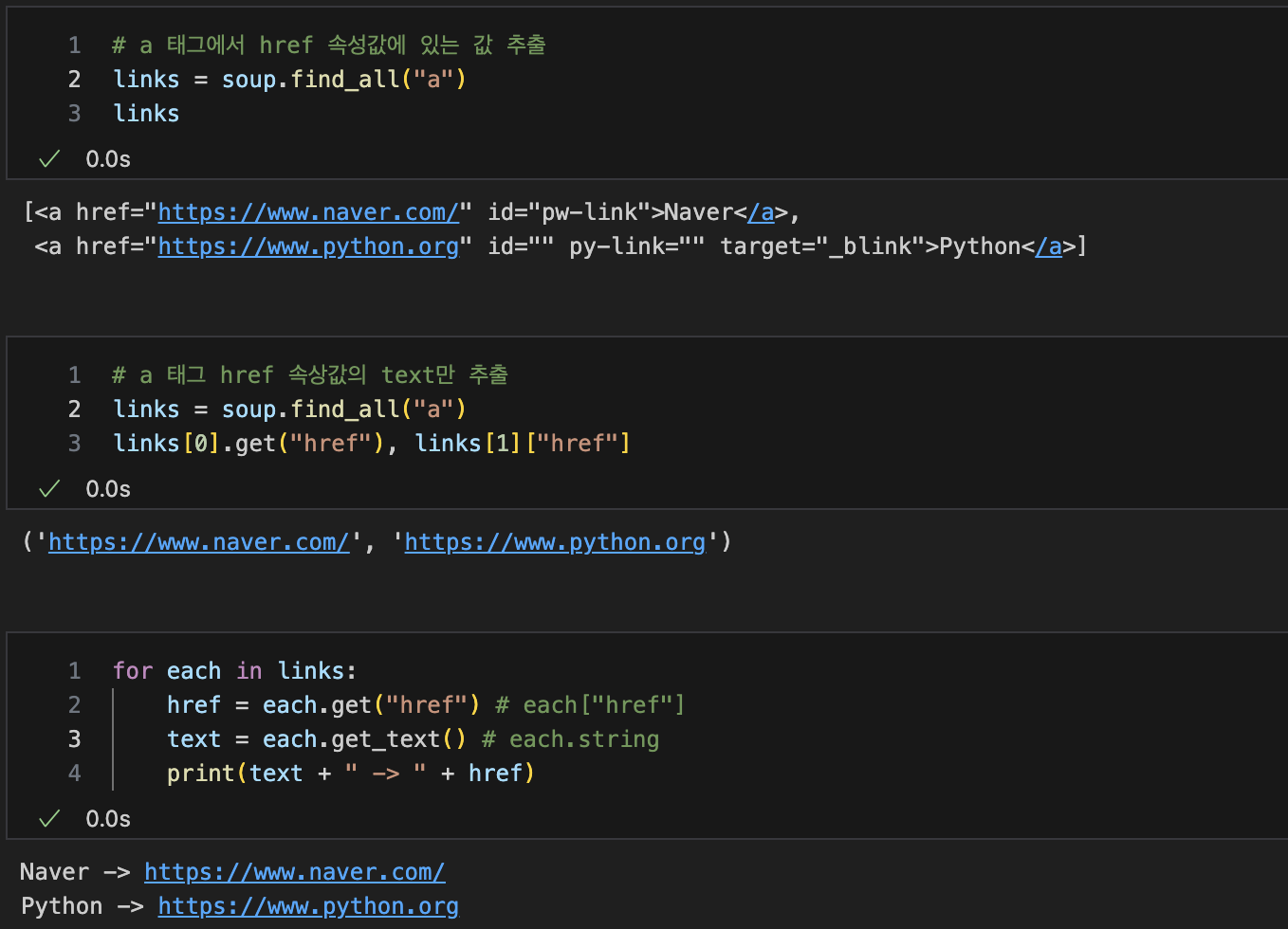
BeautifulSoup 예제 1-1 - 네이버 금융
사이트에서 html파일 구해오기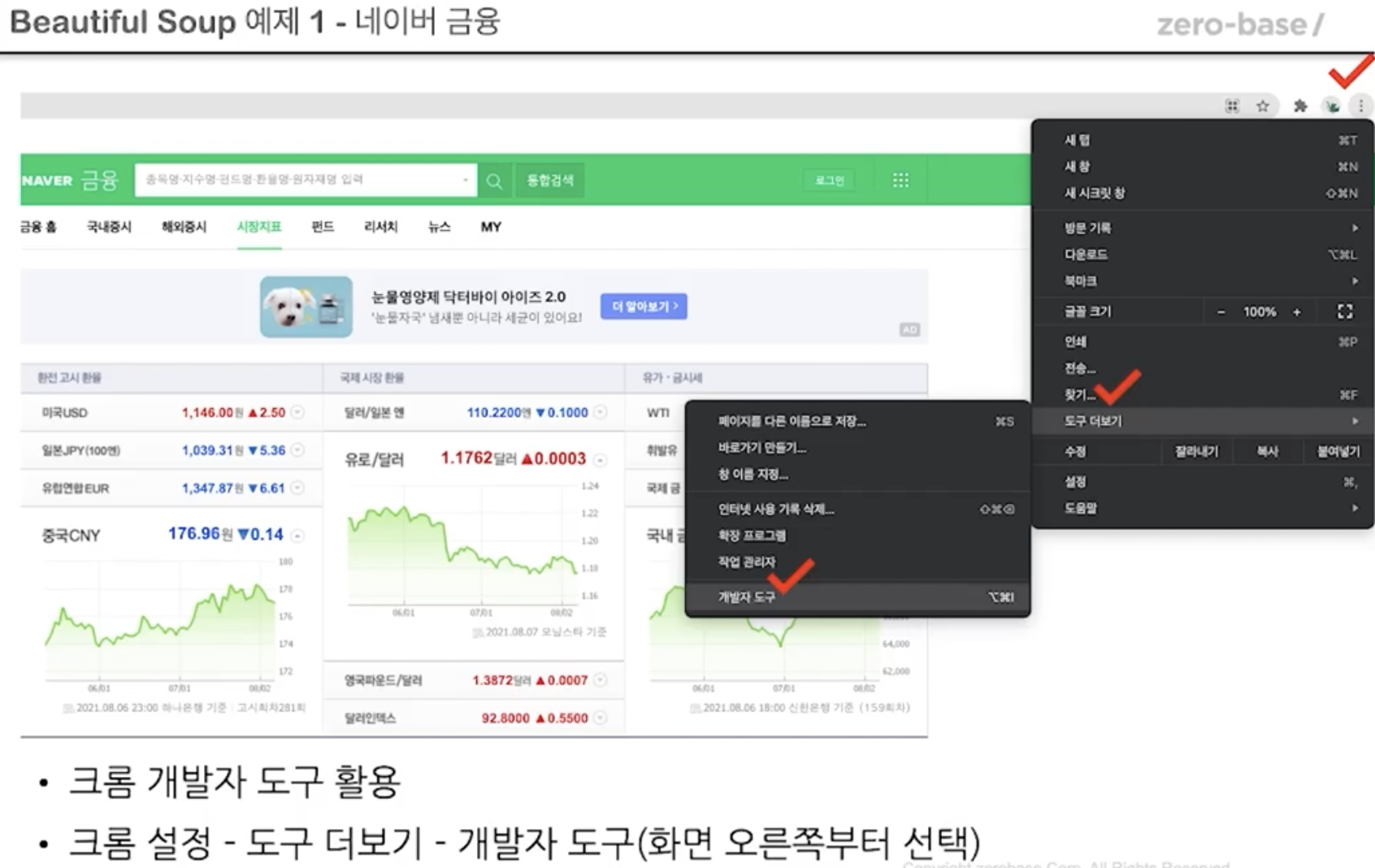
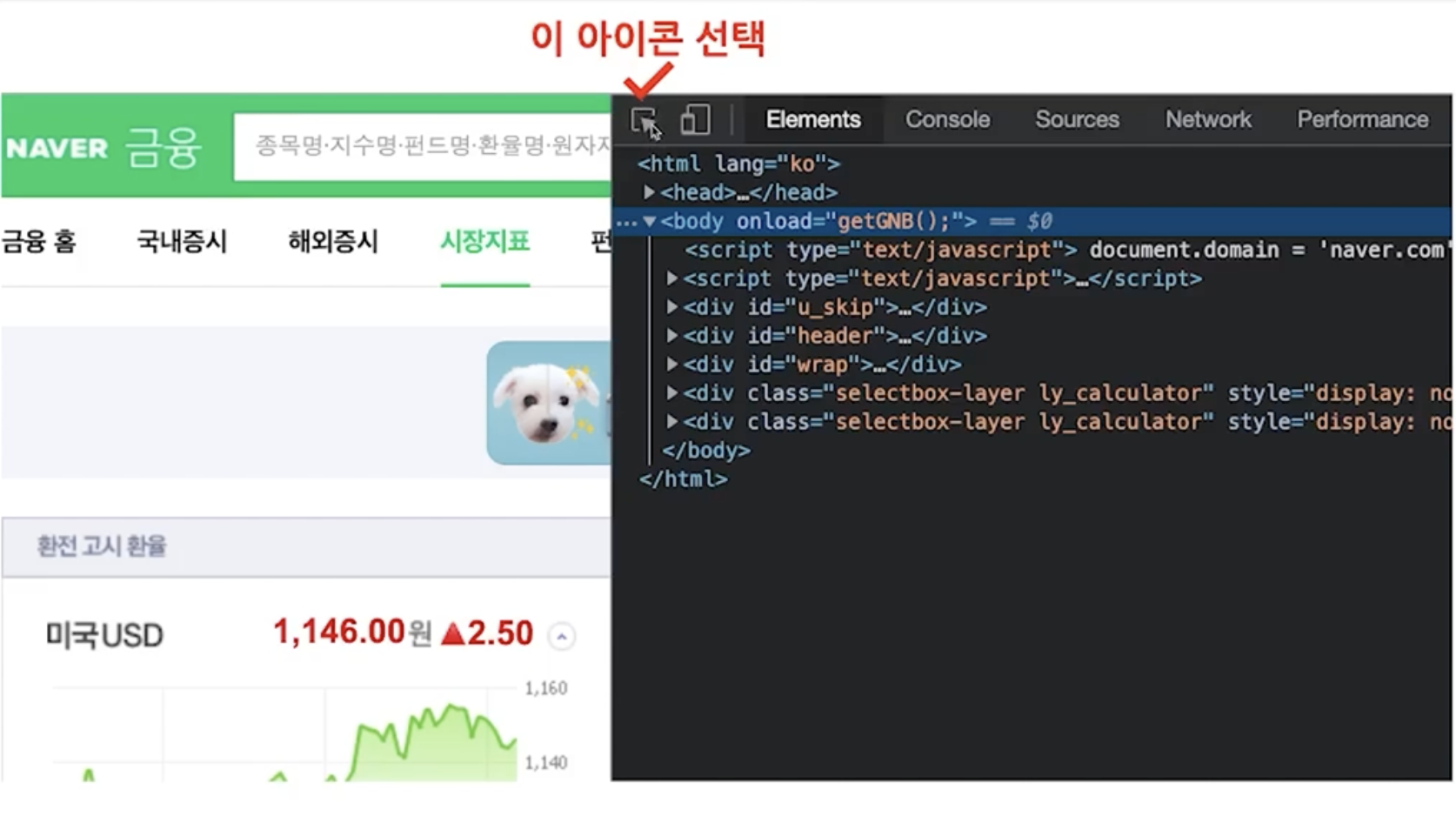
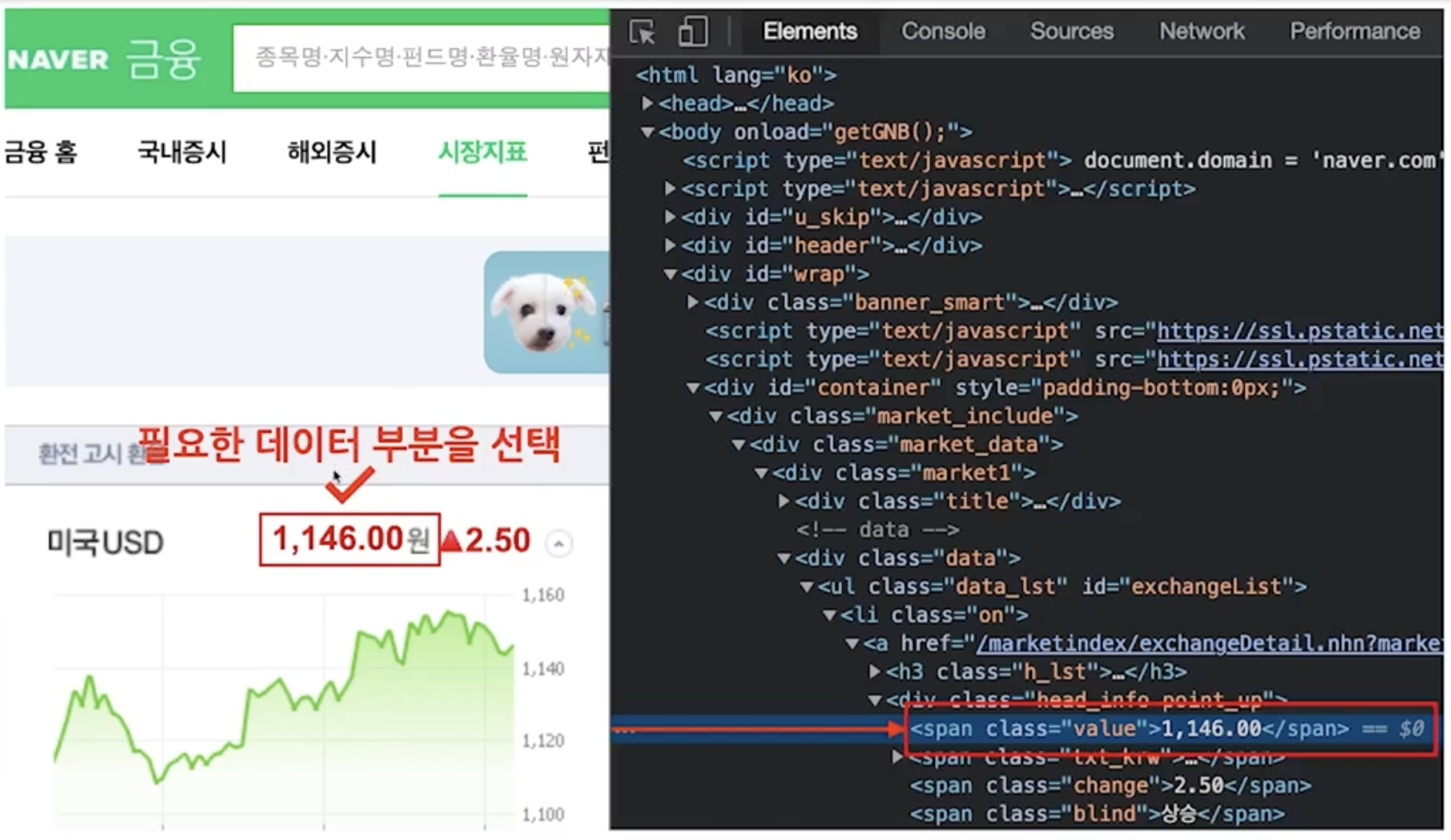

import

url 불러오기
from urllib.request import urlopen
url = "www.~~"
page = urlopen(url)
#response = urlopen(url)
soup = BeautifulSoup(page, "html.parser")
sou.prettiry()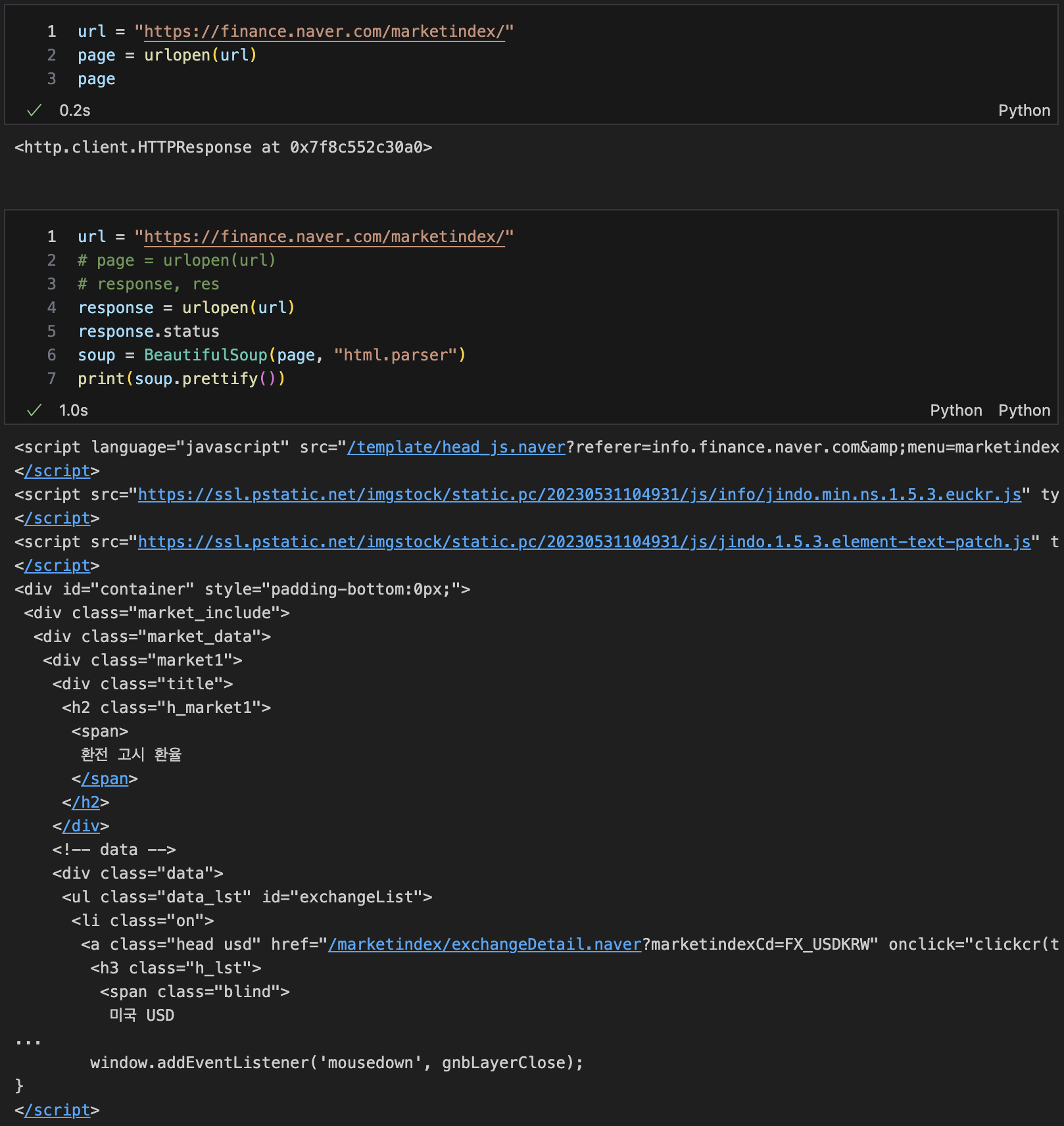
HTTP 상태코드
✔︎ .status --> HTTP 상태코드 확인
1xx(정보) : 요청을 받았으며 프로세스를 계속 진행합니다.
2xx(성공) : 요청을 성공적으로 받았으며 인식했고 수용하였습니다.
3xx(리다이렉션) : 요청 완료를 위해 추가 작업 조치가 필요합니다.
4xx(클라이언트 오류) : 요청의 문법이 잘못되었거나 요청을 처리할 수 없습니다.
5xx(서버 오류) : 서버가 명백히 유효한 요청에 대한 충족을 실패했습니다.참고 : https://ko.wikipedia.org/wiki/HTTP_%EC%83%81%ED%83%9C_%EC%BD%94%EB%93%9C
-
find_all() 결과값 전체출력 3가지
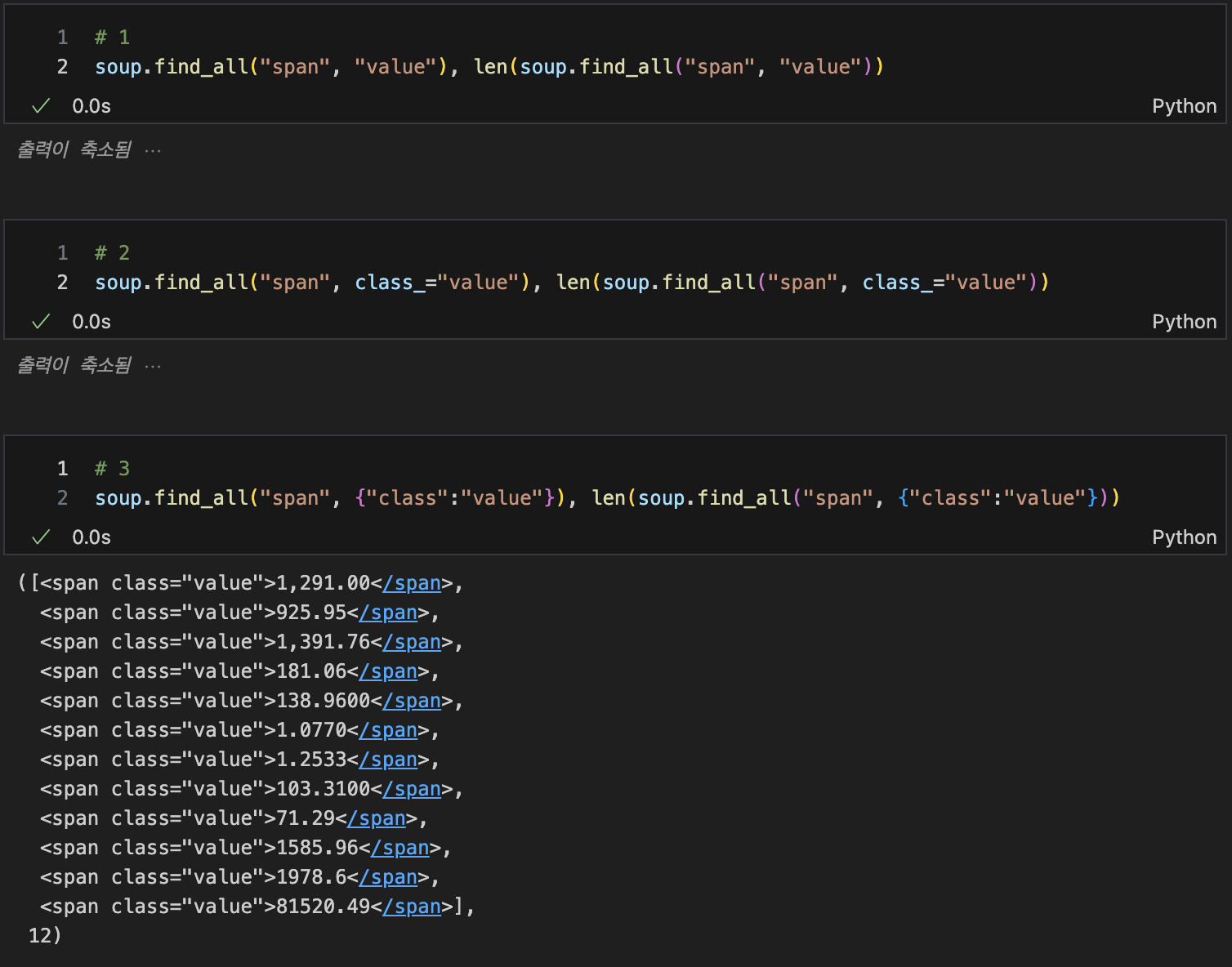
-
find_all() 결과값만 출력
# span안에 [0]번 value값 string 출력
soup.find_all("span", "value")[0].string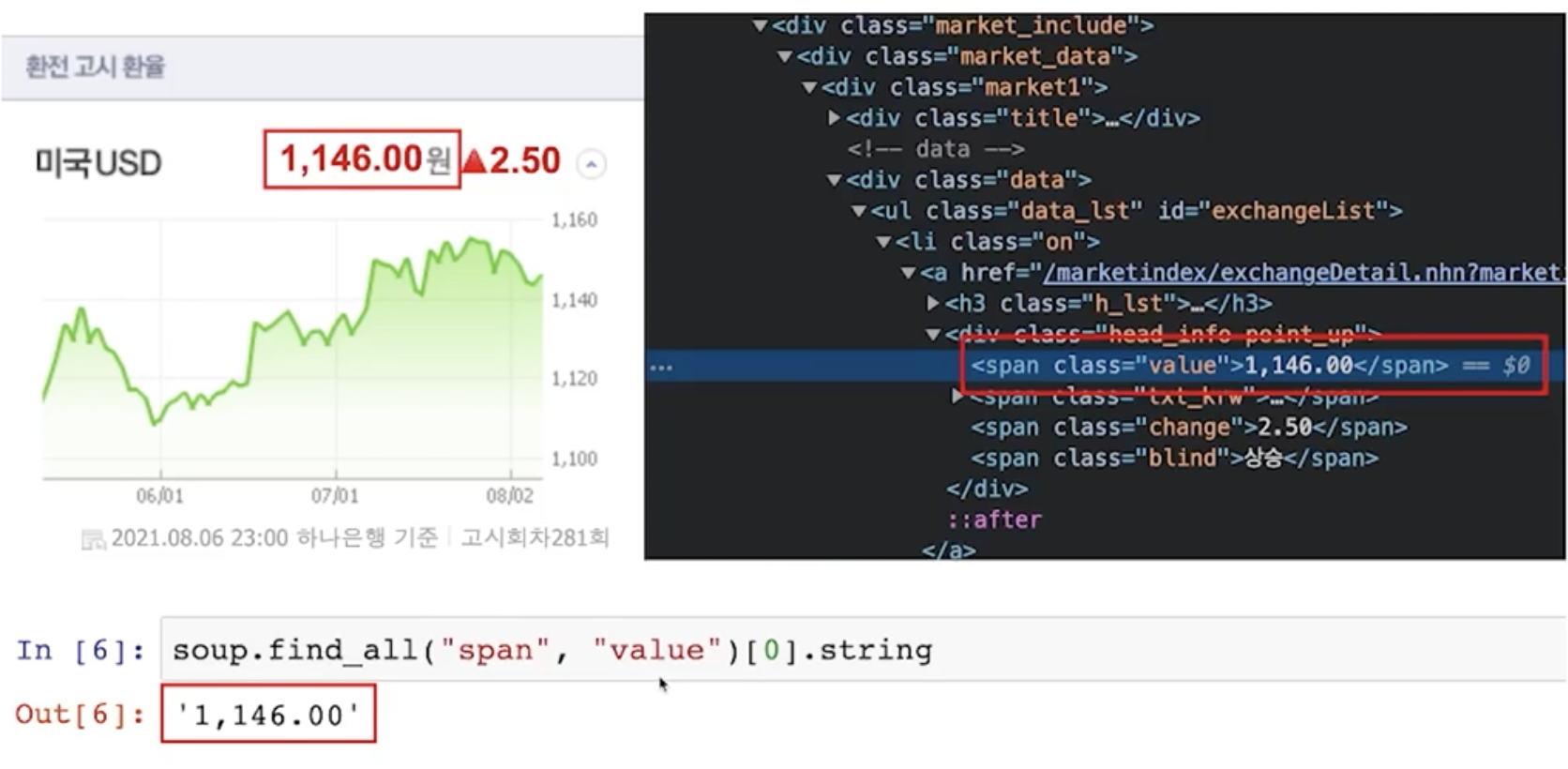
BeautifulSoup 예제 1-2 - 네이버 금융
-- !pip install requests / requests 설치
-- 1개 선택 : find, 여러개 선택 : find_all
-- 여러개 선택 : select, 1개 선택 : select_one
-- find, select_on : 단일 선택
-- find_all, select : 다중 선택
-
select
- 태그 = 태그명
- 클래스 = .클래스명
- 아이디 = #아이디명
- 하위태그 = 상위태그 > 하위태그 > 하위태그 -
import
-
url 불러오기
# url 불러오기
request.get() , requests.post()
response.text()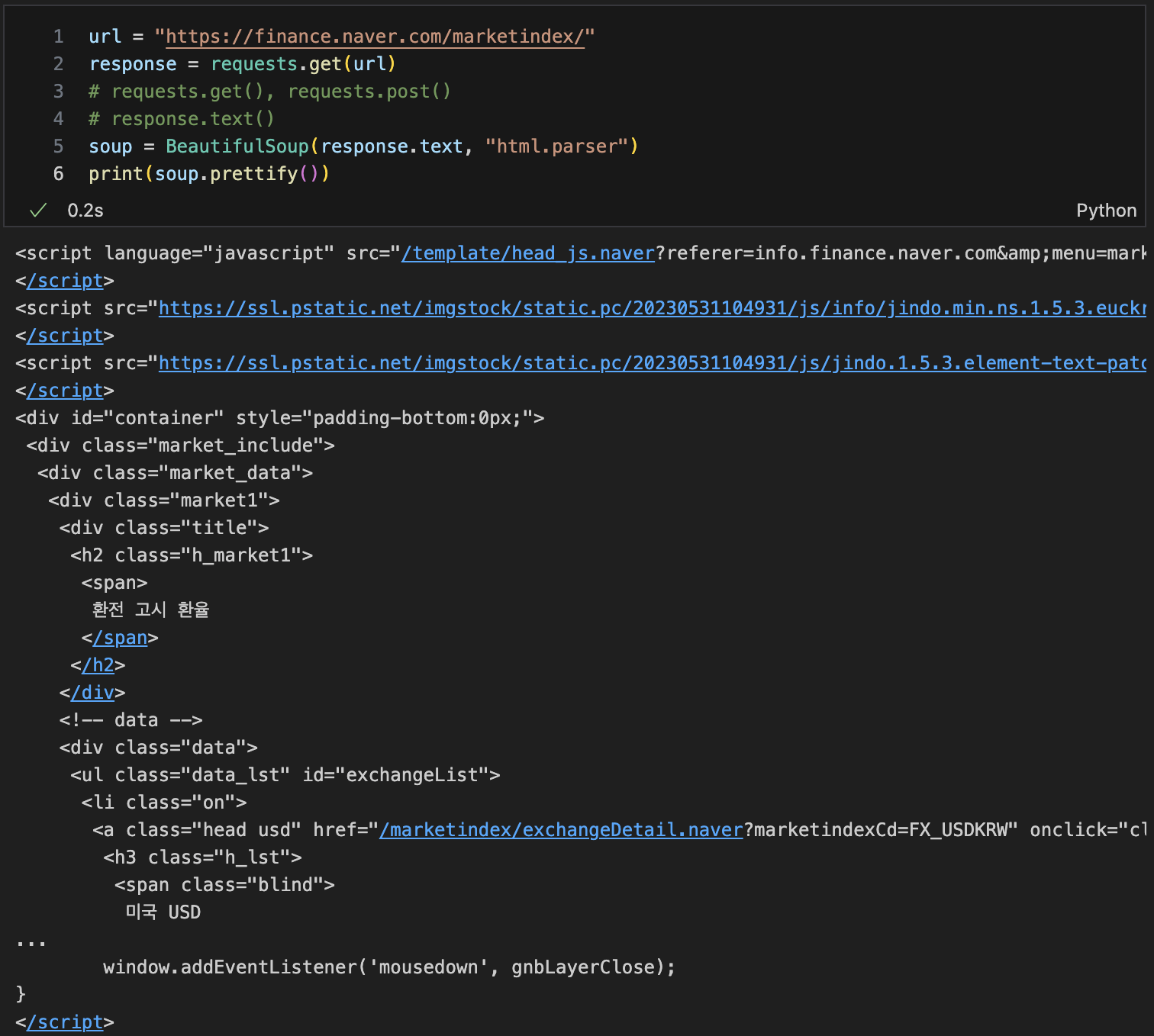
-
list로 만들기
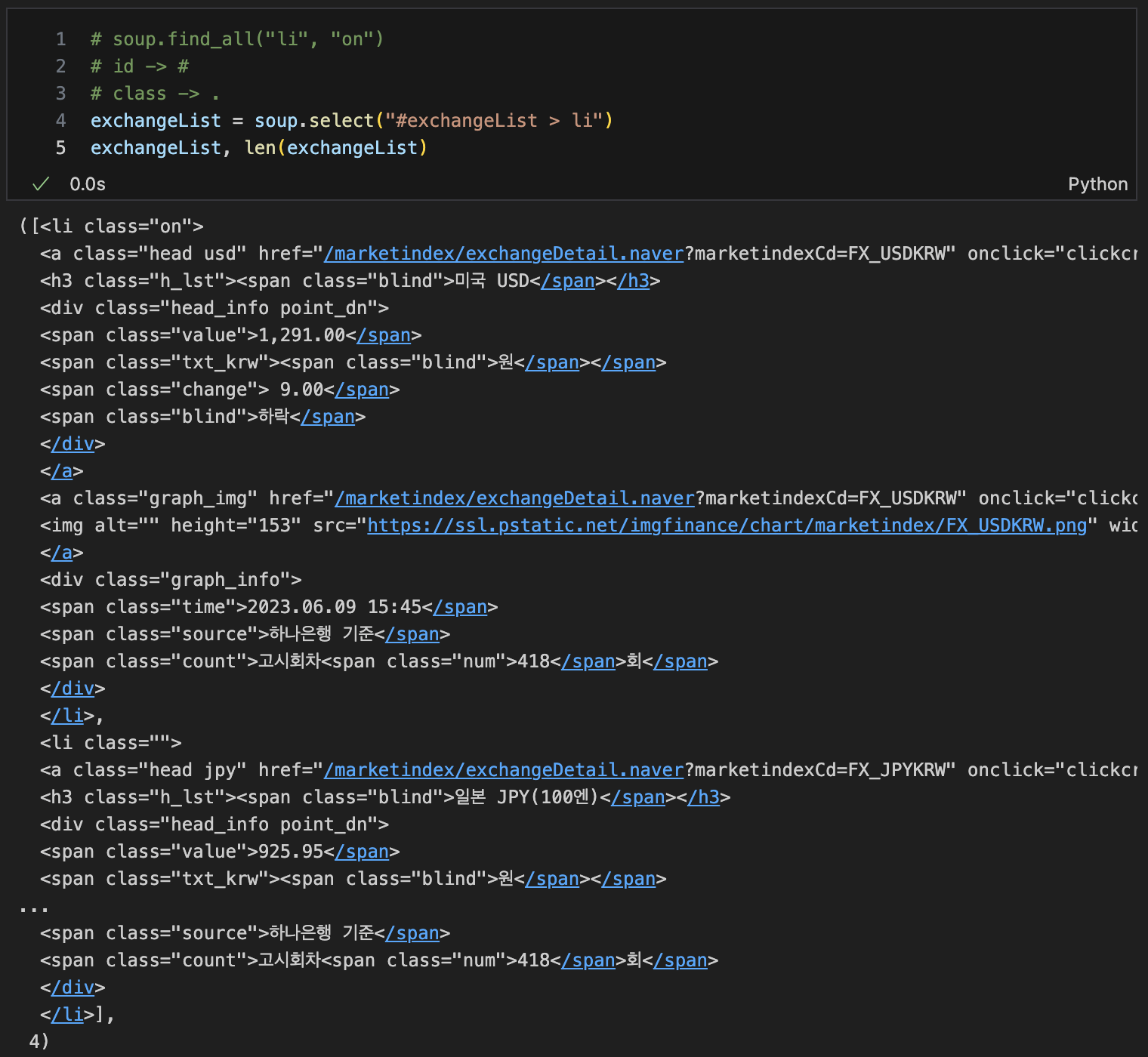
-
필요한 값들 확인
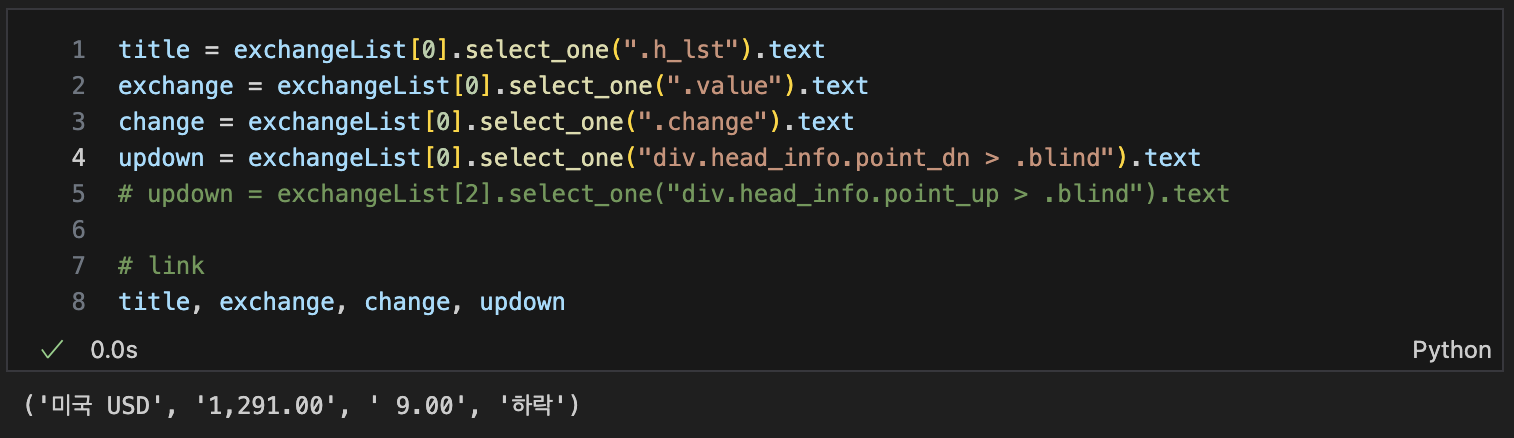
-
link 만들기

-
4개 데이터 수집
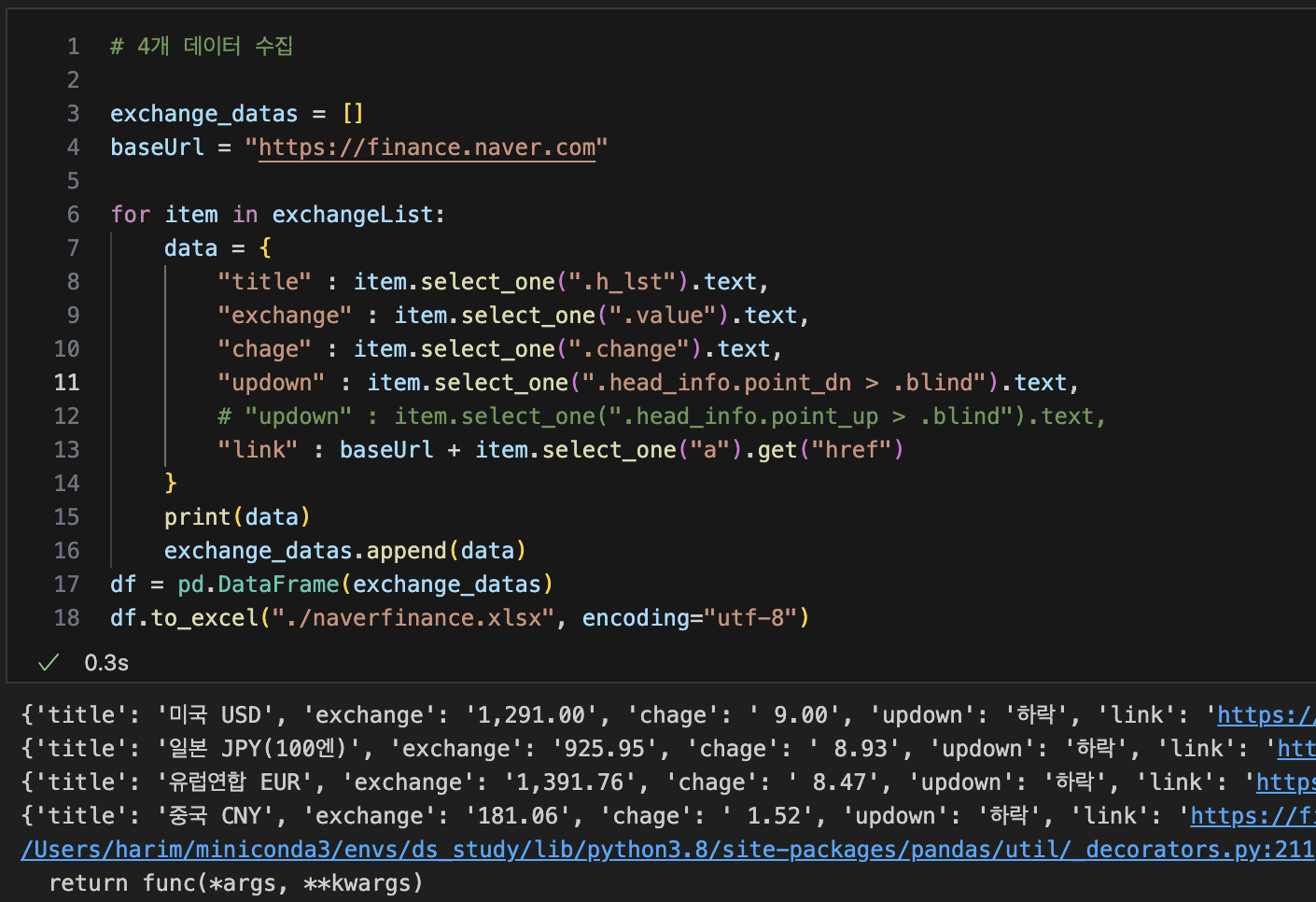
인터프리터 --> 컴파일러(.py)
-
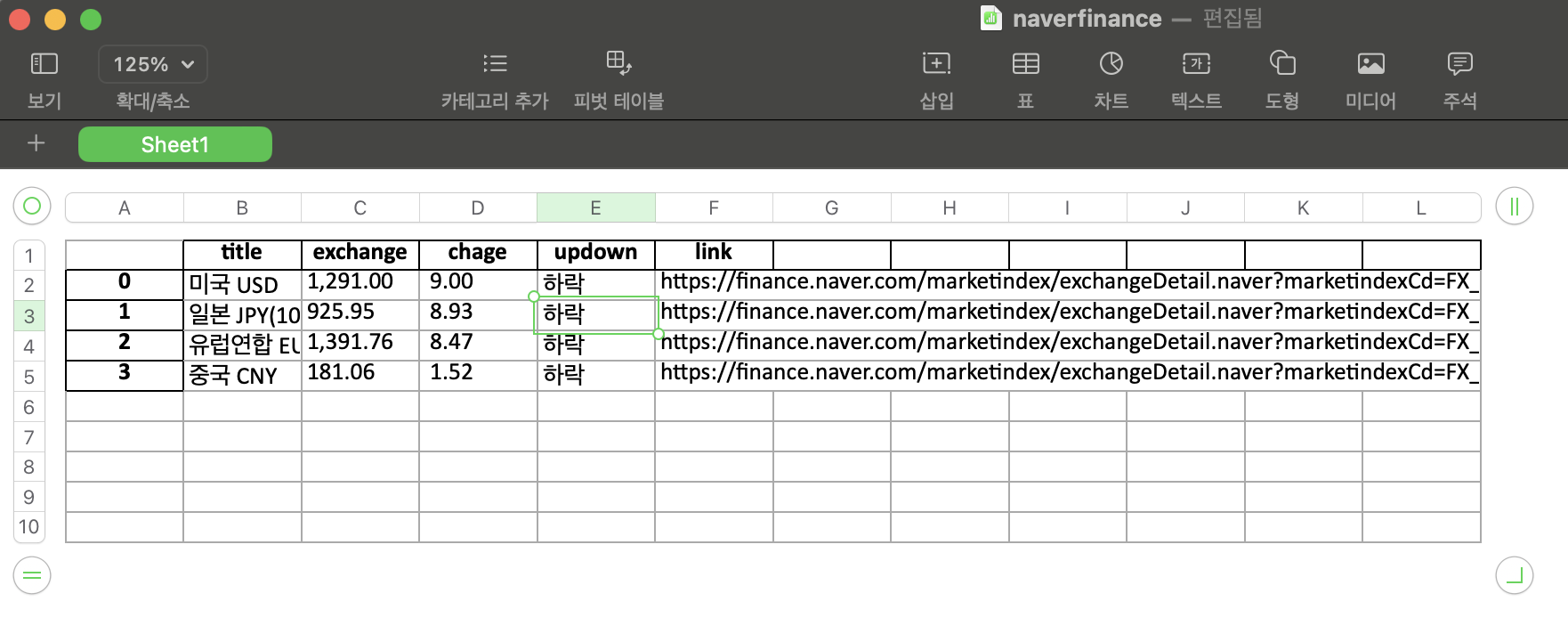
엑셀 생성
-
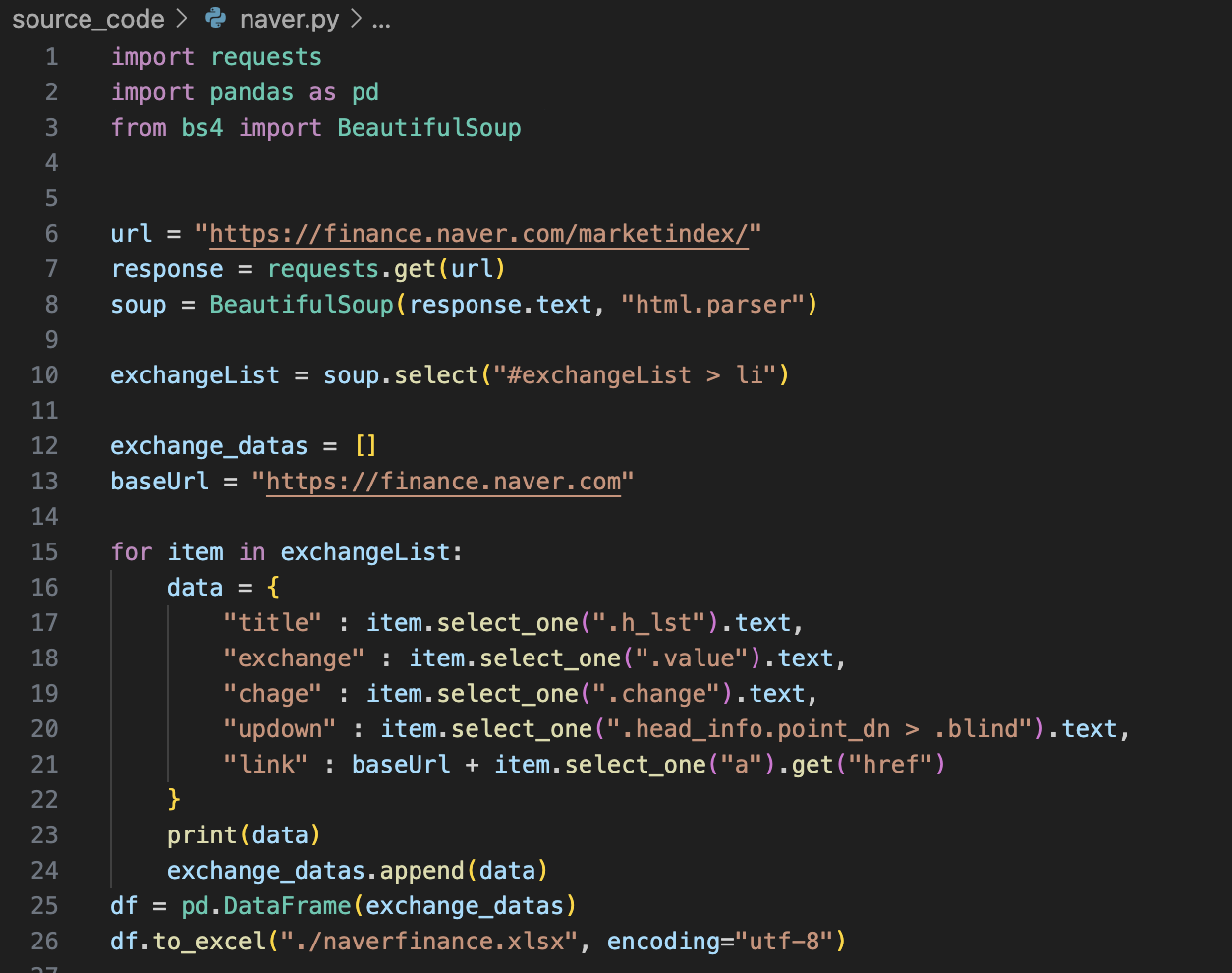
py 파일에 하나로 정리
오류코드
file <stdin> line 1 in <module> --> 껐다켜기, exit(), Ctrl+Z키 사용
