
chatGPT의 붐과 GPT-4의 출시로 AI에 대한 사람들의 관심이 높아지고 있다.
한편 미래 밥그릇이 뺏길까 하루하루 걱정하는 컴공생 본인은 적을 더 가까이 두자는 의미로 이와 관련된 프로젝트를 진행했다.
GPT 모델의 Voice_toText 기능과 Chat_completion 기능을 이용해 실시간 음성을 코드로 짜주는 파이썬 프로그램을 만들어 보자.
이와 관련된 기술은 이미 github copilot에서 제공하는 voice to code 라고 존재한다.
이걸로 스타트업을 차려 떼돈을 벌 수는 없겠지만
API Call, python에서의 음성파일 녹음, 저장을 다루는 방법에 대해 좋은 경험을 할 수 있을 것 같아서 진행했다.
◇ GPT API call
API Call에 대해서는 OpenAi 웹사이트에서 친절하게 설명해놓았으니 이를 사용해보자.
우선 API call을 위해서는 가장 먼저 고유 API Key가 필요하다. OpenAi 공식 웹사이트에서 회원가입을 하면 고유 Api Key와 18달러치의 무료 토큰을 받을 수 있다.
우리가 사용할 GPT-3.5의 API Call 가격은 0.002$/1000토큰 이다.
자그마치 9,000,000 무료 토큰.....흥청망청 써보자
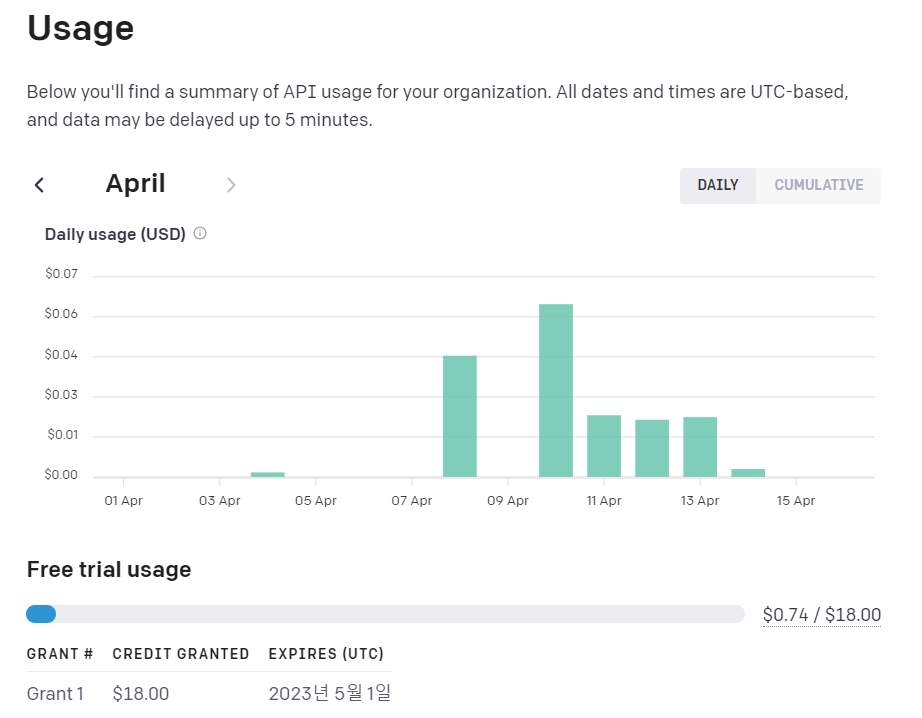
정말 흥청망청 썼는데 아직 1달러치도 못썼다. 조금 아쉬운 점은 이 무료 토큰이 일정 기간까지만 쓸 수 있고, 그 이후에는 구매해야 한다는 것이다.
위와 같이 OpenAi 웹사이트에서 발급받은 본인의 API Key를 코드에 넣으면 API Call을 할 수 있게 된다.
다음으로 API Call을 코드상에서 사용하기 위해서 pip install로 openai 패키지를 다음과 같이 설치하고, import 한다.
pip install openaiimport openai◇ GPT Voice_to_Text
Voice_to_Text 모듈에 대해서는 OpenAi API 웹사이트에서 친절히 설명해준다.
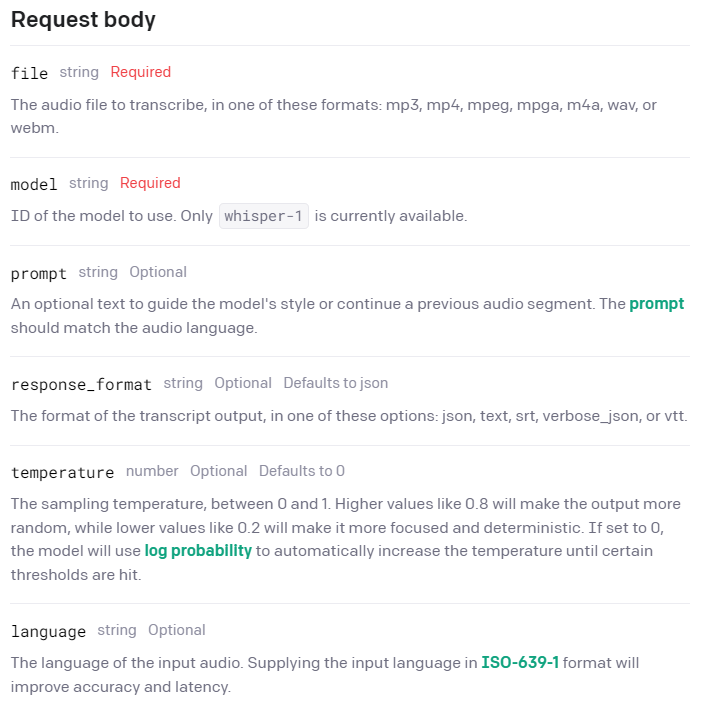
Voice_to_text 모듈은 위 사진과 같이 실제로 조정해야 하는 파라미터가 꽤 있지만, 필수인 file과 model, 또 응답을 deterministic 하게 만들어주는 낮은 temperature 값만 지정하여 다음과 같은 코드를 짰다.
def speech_to_text(param):
openai.api_key = '본인의 API Key'
response = openai.Audio.transcribe(
model = 'whisper-1',
file = param,
temperature = 0.2
)
return response['text']응답은 .json 포맷으로 온다. 그중에 ['text']만 추출하여 return해준다.
여기서 response_format을 'text'로 변경하여 함수에 추가하면 .json 포맷이 아직 낯선(나같은) 사람들은 더 간단하게 text로 응답을 받을 수 있다.
◇ GPT Chat_Completion
Chat_Completion 모듈에 대해서도 OpenAi API 웹사이트에서 친절히 설명해준다.
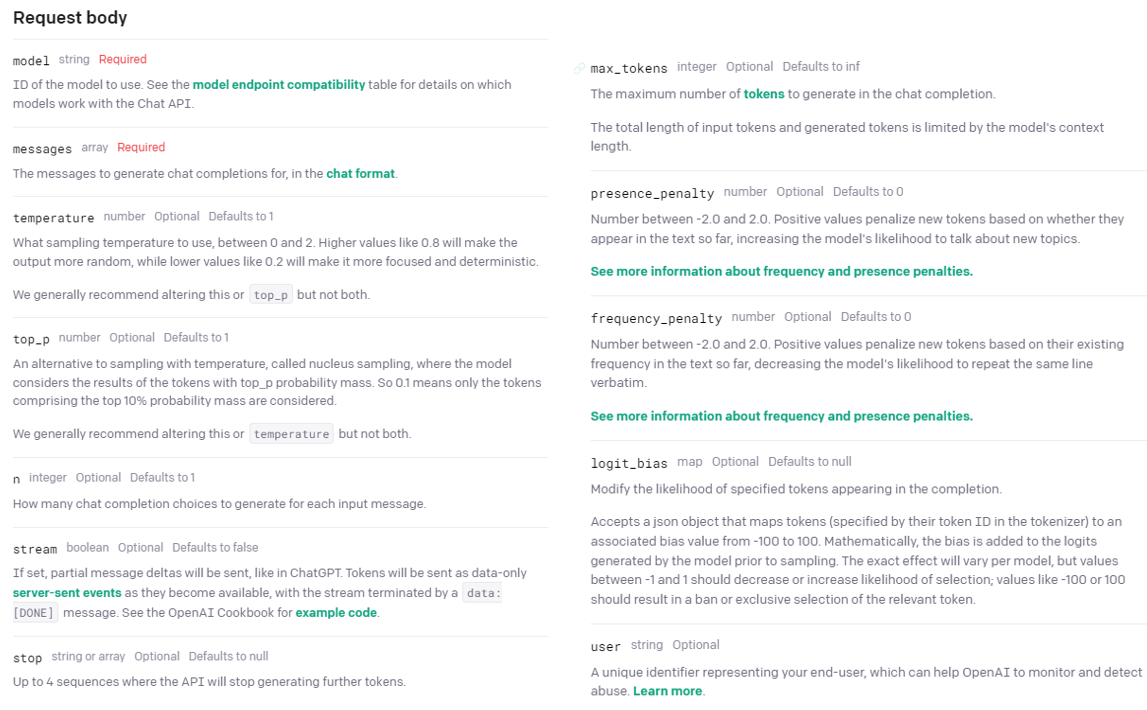
GPT의 꽃, Chat_Completion 답게 조정할 수 있는 파라미터가 아~~주 많다. top_p, presence_penalty, stream, logit_bias 등등 응답의 느낌을 미세하게 조절할 수 있는 기능이 많은 것 같다. 여기서 지금 너무 깊게 들어가려 하지는 않았고, 필수적인 요소들만 사용해봤다.
model과 messages를 지정하고, 응답의 더욱 deterministic하게 만드는 낮은 값의 temperature를 사용해 다음과 같은 코드를 짰다.
def chat_completion(param):
openai.api_key = '당신의 API 키'
response = openai.ChatCompletion.create(
model = 'gpt-3.5-turbo',
messages = [
{'role': 'system', 'content': ''},
{'role': 'user', 'content': 'convert the following text into fitting python syntax : '+param+', Give me only the code'}
],
temperature = 0.2
)
return response['choices'][0]['message']['content']
여기서 text 파라미터를 단순히 넘겨준 것이 아니라, 응답의 정확성을 높이기 위해 다음과 같은 line을 추가했다.
'convert the following text into fitting python syntax : '+param또한 그냥 저렇게 넘겨줬을 경우, 코드만 주는게 아니라 아래와 같은 이상한 주석을 달고 준다.
...python
(코드)
...그래서 param뒤에도 line을 추가해 코드만 저장되도록 만들었다.
'convert the following text into fitting python syntax : '+param+', Give me only the code'그 이후 전반적인 코드의 Overview는 녹음을 통해 오디오 파일을 생성하고, 우선 Voice_to_text으로 넘겨 text로 변환, 그 text를 Chat_Completion에 한번 더 거쳐 정확성이 높은 파이썬 코드로 변환 후, .py파일을 생성하는 것이다.
◇ Real-Time Audio Recording
이미 저장해놓은 음성 파일을 사용하는 것이 아닌, 노트북 마이크로 실시간 녹음을 해서 저장한 파일을 사용하는 코드를 구성했다.
내가 사용한 pyaudio의 음성 녹음은 원래 특정 시간을 지정하고 그 시간동안 microphone stream이 열려있는 형식이다. 하지만 그렇게 하면 진정한 Real-Time Audio의 의미를 잃을 것 같아서 다음과 같이 구성했다.
우선 아래 패키지들을 import한다.
import openai
import pyaudio
import signal
import wave
import os1) pyaudio 패키지로 microphone stream을 무한정 열어둔다.
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 44100
CHUNK = 1024
WAVE_OUTPUT_FILENAME = "output.wav"
audio = pyaudio.PyAudio()
# Open microphone stream
stream = audio.open(format=FORMAT, channels=CHANNELS,
rate=RATE, input=True,
frames_per_buffer=CHUNK)2) signal 패키지의 KeyboardInterrupt로 음성 녹음을 끝냈을 때 Ctrl+C를 눌러 음성 녹음을 멈춘다.
# Record audio until keyboard interrupt
frames = []
interrupted = False
def interrupt_handler(signal, frame):
global interrupted
interrupted = True
# Listen for keyboard interrupt
signal.signal(signal.SIGINT, interrupt_handler)
while not interrupted:
data = stream.read(CHUNK)
frames.append(data)
# Stop recording and close stream
stream.stop_stream()
stream.close()
audio.terminate()3) wave, os 패키지로 녹음본을 파일로 저장한다.
# Save recorded audio to WAV file
if os.path.exists(WAVE_OUTPUT_FILENAME):
os.remove(WAVE_OUTPUT_FILENAME)
waveFile = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
waveFile.setnchannels(CHANNELS)
waveFile.setsampwidth(audio.get_sample_size(FORMAT))
waveFile.setframerate(RATE)
waveFile.writeframes(b''.join(frames))
waveFile.close()4) 녹음 파일을 GPT로 넘겨 파이썬 코드를 생성, .py 파일을 생성한다.
audio2 = open("본인의 파일 디렉토리/output.wav", "rb")
with open('new.py', 'w') as file:
file.write(chat_completion(speech_to_text(audio2)))완성된 전체 코드 (Github Repo)
import openai
import pyaudio
import wave
import os
import signal
def speech_to_text(param):
openai.api_key = '본인의 API Key'
response = openai.Audio.transcribe(
model = 'whisper-1',
file = param,
temperature = 0.2
)
return response['text']
def chat_completion(param):
openai.api_key = '본인의 API Key'
response = openai.ChatCompletion.create(
model = 'gpt-3.5-turbo',
messages = [
{'role': 'system', 'content': ''},
{'role': 'user', 'content': 'convert the following text into fitting python syntax : '+param+', Give me only the code'}
],
temperature = 0.2
)
return response['choices'][0]['message']['content']
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 44100
CHUNK = 1024
WAVE_OUTPUT_FILENAME = "output.wav"
audio = pyaudio.PyAudio()
# Open microphone stream
stream = audio.open(format=FORMAT, channels=CHANNELS,
rate=RATE, input=True,
frames_per_buffer=CHUNK)
print("Recording started, \nCtrl+C to stop Recording")
# Record audio until keyboard interrupt
frames = []
interrupted = False
def interrupt_handler(signal, frame):
global interrupted
interrupted = True
# Listen for keyboard interrupt
signal.signal(signal.SIGINT, interrupt_handler)
while not interrupted:
data = stream.read(CHUNK)
frames.append(data)
print("Recording finished")
# Stop recording and close stream
stream.stop_stream()
stream.close()
audio.terminate()
# Save recorded audio to WAV file
if os.path.exists(WAVE_OUTPUT_FILENAME):
os.remove(WAVE_OUTPUT_FILENAME)
waveFile = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
waveFile.setnchannels(CHANNELS)
waveFile.setsampwidth(audio.get_sample_size(FORMAT))
waveFile.setframerate(RATE)
waveFile.writeframes(b''.join(frames))
waveFile.close()
audio2 = open("프로젝트 파일 디렉토리/output.wav", "rb")
with open('new.py', 'w') as file:
file.write(chat_completion(speech_to_text(audio2)))
print("Your .py file has been created.")이 프로그램은 GPT의 Chat_completion 의 도움을 받아 코드를 작성하기 때문에, 아주 정확하게 코드를 말하지 않아도 꽤나 높은 정확성으로 알아듣는다. 또한, 그저 원하는 알고리즘의 이름을 말하기만 해도 (i.e. "Code for Quicksort") 알아서 코드를 찍어낸다.
물론 GPT 모델의 코드 짜는 능력은 다른 기능에 비해 좀 아쉽다고 해도 과장이 아니므로, 직접 코드를 말하는 것을 추천한다.
프로그램 테스트
노트북에 이어폰을 연결해 이어폰 마이크에 대고 코드를 말하는 방식으로 녹음을 진행했다. KeyboardInterrupt로 녹음을 멈춰야 하기 때문에, 터미널에서 다음과 같이 입력하여 실행해야 한다.
cd C:/프로젝트 파일 디렉토리
python 프로그램 이름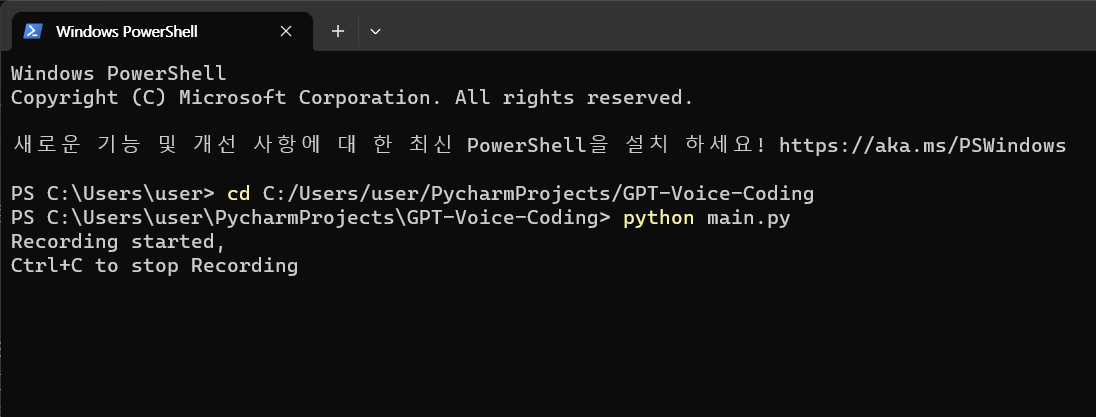
테스트로는 간단한 Bubble Sort 코드를 말해보았다.
직접 말한 코드 : Import sys input equals sys dot standardin dot readline. mylist equals list map int input split. for i in range length of mylist minus one comma zero comma minus one, for j in range i, if mylist j is greater than mylist j plus one, swap mylist j and mylist j plus one.
예상 output 코드 :
import sys
input = sys.stdin.readline
mylist = list(map(int,input().split()))
for i in range(len(mylist,0,-1):
for j in range(i):
if mylist[j] > mylist[j+1]:
mylist[j], mylist[j+1] = mylist[j+1], mylist[j]실제 output 코드 :
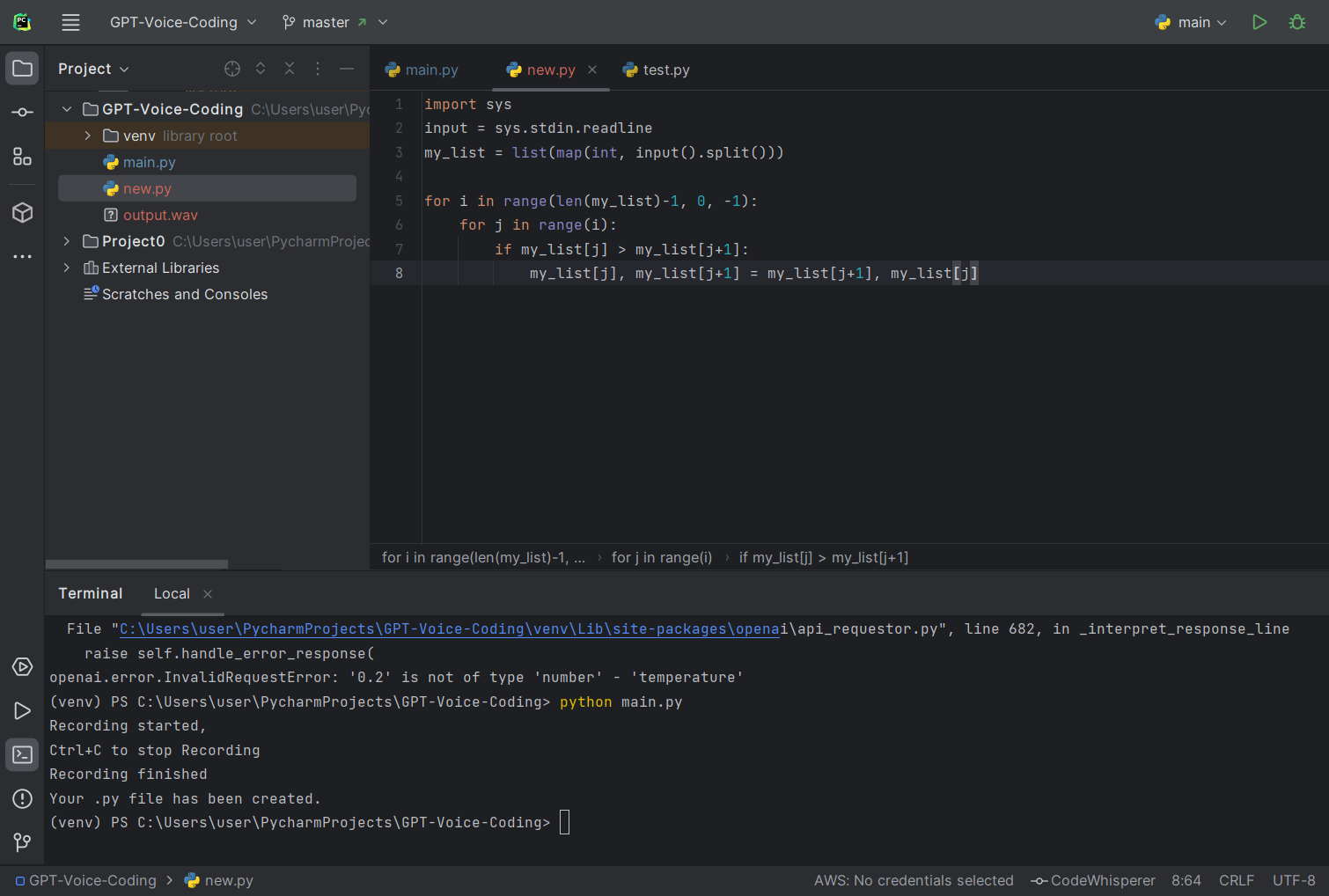
위 사진과 같이 말한 코드 그대로 new.py 파일이 생성되고, 녹음본 output.wav도 파일 디렉토리에 저장된다. 생성된 코드를 그대로 터미널에 실행해보니 아주 잘 돌아간다.
이렇게 음성으로 코딩을 하는 것이 엄청난 이점이 있다고 할 수는 없지만 (사실 이점이 거의 없긴 하다), 굳이 IDE를 실행해서 코드를 치기 귀찮을 때, 터미널에서 이 프로그램을 불러와 new.py를 만들고, 바로 터미널에서 new.py를 실행할 수 있는 것에 의의가 있다(?)고 본다.
아쉬운 점
Github Copilot처럼 Vscode나 Pycharm에서 원할 때 Extension처럼 바로 불러올 수 있도록 만들고 싶었지만,,, Extension을 만드는걸 공부하다 한계에 부딪혀서 일단 이정도 수준으로만 구현했다. (추후에 더 공부해 Extension으로 출시할 예정! Extension 이름 추천 받습니다)
또 다른 아쉬운 점은 실제로 이 프로그램은 GPT가 9.99할을 먹고 들어가기 때문에 별로 배울 점이 없었다는 것....? 요즘 핫한 GPT를 이용해 프로그램을 만들어 보니 재밌긴 했다.
