[논문리뷰] Reference and Document Aware Semantic Evaluation Methods for Korean Language Summarization (2/2)
졸업작품

논문제목 : Reference and Document Aware Semantic Evaluation Methods for Korean Language Summarization (한국어요약을 위한 참고자료 및 문서인식 의미 평가 방법)
작성자 : 카카오, 고려대, 한신대.
저번시간에 이어서 마저 논문에 대해 분석하는 시간을 갖도록 하겠습니다.
4. Experimental Setup
4.1 Dataset
우리는 정치, 경제, 국제, 문화, 정보 기술 등 10개 주제로 구성된 한국 다음/뉴스 데이터 세트을 사용하여 모델을 교육하고 평가하였다. 이로부터 300만 건의 뉴스 기사를 뽑아냈다. 교육용, 검증용, 시험용 물품은 각각 2.98M, 0.01M, 0.01M이었다. 우리는 이 데이터 세트를 "Daum/News"라고 부른다. 우리는 다음/뉴스를 이용하여 기사의 내용을 충분히 이해하고 적절한 평가를 실시하였다.
데이터 집합에는 143개 신문사의 기사가 수록되어 있으며, 각 신문마다 요약 스타일이 다르며, 제안된 방법의 효과성이 이를 사용하여 예시된다. 따라서 우리의 연구가 다른 언어에도 적용될 수 있을 것으로 기대한다.
4.2 Summarization Model
우리는 케이블 뉴스 네트워크/데일리메일(Hermann et al., 2015), 뉴욕 타임즈(Sandhaus, 2008), XS의 최첨단 결과를 보여주는 (Liu and Lapata, 2019) Liu (2019)의 추상적 요약 모델을 채택하여 pretrained BERT를 encoder로, six-layered transformer를 decoder,로 활용하였다.
영어-베르트-베이스-미스케이드 대신 한국어 데이터 세트(하위 4.3)에 대해 교육받은 사전 훈련된 BERT를 활용했다는 점을 제외하고는 (Liu and Lapata, 2019)에 따라 모든 환경을 설정했다. 우리는 한국의 다음/뉴스 데이터 집합에 대한 추상적 요약 모델을 훈련했다.
4.3 SBERT
SBERT를 활용하기 위해 먼저 Wiki, Sejong corpus, web documents 등 23M 문장과 1.6M 문서로 구성된 한국어 데이터 집합에 대해 BERT(Bert-Base-uncased)를 사전 교육했다.
다음으로, NLI(Bowman et al., 2015; Williams et al., 2017) 및 STS(Semantical Textual Afficience) 벤치마크(STSb)로부터 classification 및 regression 목표를 사용하여 SBERT를 훈련했다. NLI와 STSb 데이터세트가 영어로 되어 있기 때문에 Kakao Machine Translator에서 번역한 한국 NLI와 STS 데이터세트(Ham 등, 2020)를 활용했다.
STS 벤치마크 테스트 데이터세트에 대한 평가가 실시되어 80.52 Spearman’s rank correlation(스피어만 상관 계수) result를 보여주었다.
그 후, 사전 훈련된 SBERT 모델은 추상적 요약 모델로 세밀하게 조정되어 생성된 요약본과 함께 참조 요약본 및 소스 문서의 보다 문맥화된 정보를 포착하였다(섹션 3.2). 모든 교육은 카카오브레인클라우드에서 테슬라 V100 그래픽처리장치 4개로 진행됐다.
4.4 Human Judgment
참조 문서 인식 의미 메트릭의 효과를 입증하기 위해 인간 판단과의 상관관계를 평가하였다. 우리는 참여자에게 관련성, 일관성, 유창성 점수를 매기도록 했다.
관련성은 문서의 적절성 정도를 나타내고, 일관성은 사실성의 정도를 나타내며, 유창성은 생성된 요약의 품질 정도를 나타낸다. 또한 인간 평균은 세 가지 지표에 대한 점수의 평균값을 나타낸다. 문서, 참조 요약 및 생성된 요약에 따라 각 주석자는 평가 지표(즉, 관련성, 일관성, 유창성)에 대해 1~5점 범위에서 점수를 매겼다.
인간의 판단은 6명의 판사가 컴퓨터 공학 박사학위(3명)나 MS학위(3명)를 취득하는 방식으로 이뤄졌다. 다음/뉴스 시험 데이터 집합에서 200개의 요약본을 추출한 결과, 관련성 평균 점수는 3.8점, 일관성은 3.6점, 유창성은 3.9점이었다.
5. Results
이 섹션에서는 먼저 ROUGE 및 제안된 평가 metrics(섹션 3.1)를 사용하여 요약 모델의 성과를 보고한다. 다음으로, 제안된 평가 척도가 인간의 판단과 어떤 상관관계를 가지고 있는지 보고한다. 우리는 또한 제안된 평가 지표의 상관관계를 ROUGE에 보고하여 제안된 방법이 ROUGE를 보완한다는 것을 보여준다. 마지막으로 질적평가를 통해 ROUGE의 한계와 제안된 평가지표의 우월성을 입증한다.
5.1 Performance of the Summarization Model
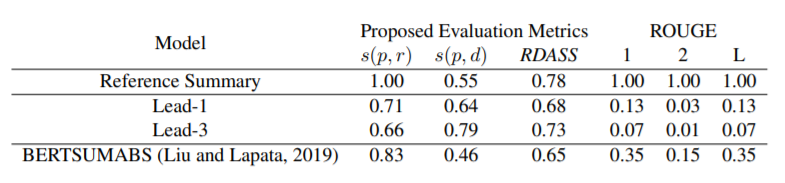
표2. 다음/NEWS 데이터 집합의 요약 모델 성능.
우리는 다음/뉴스 데이터 집합에 대한 요약 모델을 교육했다. 요약 모델을 평가하기 위해, 우리는 ROUGE와 제안된 평가 지표를 사용했다. 그런 다음 미세 조정된 FWA-SBERT를 사용하여 제안된 의미 점수(s(p, r), s(p, d), RDASS)를 평가하였다.
참조 요약의 경우, 리포터는 문서를 요약할 때 묵시적인 단어를 사용하는 경향이 있어 s(p, d) 점수는 리드 기준선에 비해 상대적으로 낮다. 단, s(p, r) 점수가 1.00이기 때문에 참조 요약에는 RDASS 점수가 가장 높은 것으로 나타난다.
리드-1의 경우 s(p, r)가 s(p, d)보다 높은 성능을 보이고, 리드-3의 경우 s(p, d)가 s(p, r)보다 더 높은 성능을 보인다. 이 수행의 이유는 리드-3가 문서에서 더 많은 문장을 포함하고 있기 때문에 참조 요약 s(p, r)와의 유사성은 낮지만 문서 s(p, d)와의 유사성은 증가하기 때문이다.
리드 베이스라인의 ROUGE 성능의 경우, 영어 데이터세트로 실시하는 다른 연구(Kryscinski et al., 2019)에 비해 상대적으로 낮은 성능을 확인할 수 있다. 그 이유는 우리말의 경우 같은 의미적 의미가 다른데, 그 이유는 교착 언어의 특성상 다르게 표현되기 때문이다.
5.2 Correlation with Human Judgment
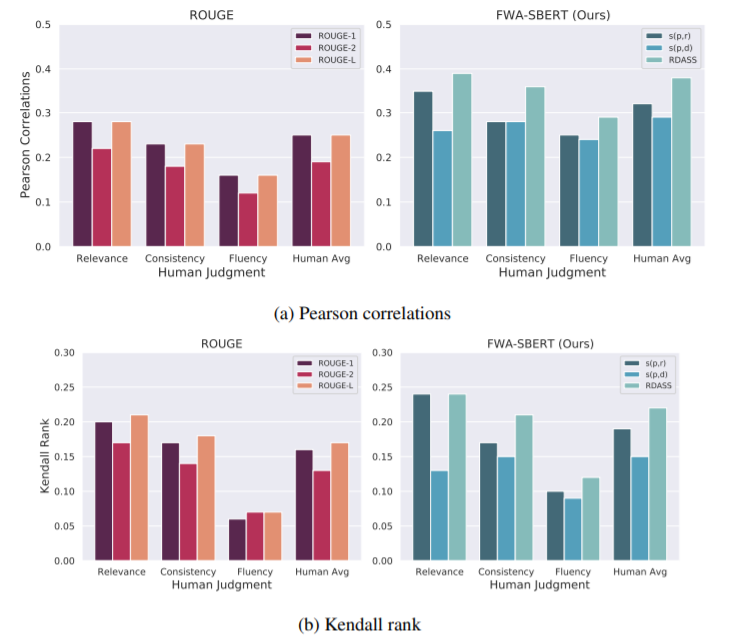
그림 1: Pearson 상관 관계 및 제안된 평가 지표의 Kendall 순위 사람 판단.
그림 (1a)와 (1b)는 각각 제안된 평가 지표의 Pearson 상관 관계와 Kendall rank를 200개의 표본 요약에 대한 인간 판단으로 보여준다.
Pearson 상관 계수는 두 변수가 선형적으로 연관되어 있는지 여부를 측정하는데, 여기서 1은 양의 선형 상관 관계를 나타내고 -1은 음의 선형 상관 관계를 나타낸다. 그리고 Kendall rank는 두 변수의 순위 상관 관계를 측정한다. 여기서 1은 두 변수가 비슷함을 나타내고 -1은 서로 다르다는 것을 나타낸다. 두 가지 상관관계 측정 방법은 모두 인간의 판단과의 상관관계를 분석하기 위해 요약 작업에 널리 사용된다.
Pearson 상관 행렬에서, 인간 판단과의 상관관계는 제안된 평가 지표에 대해 ROUGE 점수보다 훨씬 더 높았다. 또한 Kendall rank 매트릭스에서 제안된 평가 지표는 ROUGE 점수보다 인간 판단과 가장 높은 상관관계를 보였다. 제안된 평가 지표 중 s(p, r)는 s(p, d)보다 높은 성능을 보였으며 RDASS는 인간 판단과의 상관관계가 가장 높은 것으로 나타났다.
이러한 결과는 제안된 평가 지표들이 n-gram 중복에 기초한 ROUGE의 한계를 극복하는 깊은 의미적 의미를 반영할 수 있음을 나타낸다.
추상적 요약 모델을 사용하여 SBERT를 미세 조정하는 효과를 입증하기 위해 제안 방법(섹션 3.1)에 사용할 문장 표현 방법에 따라 다음과 같이 기준선 방법을 설정하였다.
- Multilingual Universal Sentence Encoder(MUSE): MUSE(Sang et al., 2019)는 다국어 문장 인코더로서 16개 언어의 텍스트를 멀티태스킹 학습을 이용하여 하나의 의미공간으로 내장하는 다국어 문장 인코더다. 이 모델은 10억 개 이상의 문답 쌍을 대상으로 교육을 받았으며, 의미론(길릭 외, 2018), 틱스트 리트라이어(Ziemski 외, 2016), 검색 질의응답(양 외, 2019) 등에서 경쟁력 있는 최첨단 결과를 보였다.
- Pre-trained SBERT : 우리는 미세 조정 없이 사전 훈련된 SBERT만 활용했다. 우리는 이것을 "P-SBERT"라고 부른다.
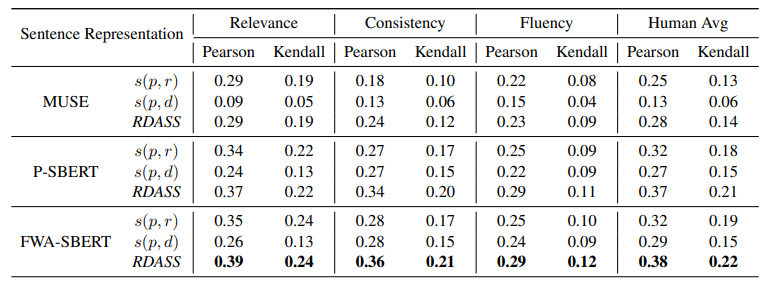
표 3: 성능 비교는 사용된 문장 표현에 따라 달라짐
표 3은 어떤 문장표현을 사용하느냐에 따라 수행비교가 달라졌음을 보여준다. PSBERT는 MUSE보다 인간과 높은 상관 계수를 보여준다. 전체적으로 FWA-SBERT를 사용했을 때 인간의 판단과 가장 가까운 상관관계를 보였다. quantitative 평가를 통해 제안된 평가지표가 인간 판단과 높은 상관관계를 가지고 있으며, SBERT를 미세 조정하는 방법(FWA-SBERT)이 제안된 평가지표의 성능을 향상시켰음을 입증했다.
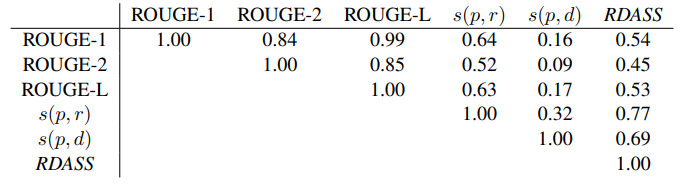
표 4: ROUGE와 제안된 평과 지표의 Pearson 상관관계
우리는 또한 각 평가 척도가 서로 어떻게 상관관계가 있는지 이해하기 위해 실험을 했다. 표 4와 같이, ROUGE 지표들 사이에 높은 상관관계가 있었다. 그러나 제안된 평가 지표는 ROUGE와의 상관관계가 상대적으로 낮았다. 이는 제안된 평가 지표들이 우리의 경우, ROUGE가 할 수 없었던 의미적 의미를 반영했음을 나타낸다. 따라서, 그것은 ROUGE 측정기준을 보완한다.
Qualitative Analysis
이 섹션에서는 qualitative(질적인) 분석을 통해 평가 지표의 효과를 입증한다. 표 5는 두 기사에 대해 생성된 요약에 대한 ROUGE, RDASS 및 인간 평가 결과를 보여준다.
article-1에서 생성된 요약본 'On the 30th birthday of Messi, he had a good time with his family'는 참조 요약본인 'Messi’s 30th birthday with his wife and son'과 같은 의미적 의미를 갖는다. 다만 의미적 의미가 같은 문장은 교착어 언어의 특성을 가진 한국어로 다양하게 표현할 수 있기 때문에 ROUGE 점수는 낮은 반면 인간 평가 점수는 높은 편이다.
마찬가지로 article-2의 'Samsung Electronics launches new ‘qled tv’ in Brazil'는 요약문은 '삼성전자가 중남미 최대 시장인 브라질에서 'Samsung Electronics launches ‘qled tv’ in Brazil, the largest market in Latin America'는 참고요약과 같은 의미적 의미를 갖는다.
두 글 모두 생성된 요약은 맞지만(correct), ROUGE 점수는 낮다. 반면 RDASS 점수는 더 높은 점수를 나타내며, 생성된 요약이 정답임을 나타낸다.

표 5: "DAUM/News" 테스트 데이터 집합의 예시 기사 생성된 요약에 대한 RDASS, 인간 평가 결과가 표시된다.
6. Conclusion
본 논문에서는 한국어 요약본을 채택할 때 널리 사용되는 루즈 평가 지표의 한계를 지적했다. 한국어는 교착어이기 때문에 참고요약과 같은 의미적 의미를 갖는 생성된 요약은 다양하게 표현할 수 있다. 따라서, 오직 RUZE 미터법을 활용해야만 부정확한 평가 결과를 산출할 수 있다.
이러한 한계를 극복하기 위해 RDASS(Reference and Document Awareness Simantic Score) 평가 지표를 제안했다. RDASS는 생성된 참조 요약 및 문서의 깊은 의미 관계를 반영할 수 있다. 광범위한 평가를 통해 RDASS(Resigned Evaluation Metric)가 루즈 점수보다 인간 판단과의 상관성이 더 높다는 것을 입증했다.
향후 작업에서는 영어 요약 데이터 집합에서 제안된 방법의 효과를 증명할 것이다.
