[논문리뷰] Reference and Document Aware Semantic Evaluation Methods for Korean Language Summarization (1/2)
졸업작품

논문제목 : Reference and Document Aware Semantic Evaluation Methods for Korean Language Summarization (한국어요약을 위한 참고자료 및 문서인식 의미 평가 방법)
작성자 : 카카오, 고려대, 한신대. (Korea University이 어딘가 했더니 고려대였군요?)
영어를 잘 못하기 때문에 파파고로 번역해서 분석했습니다. 그렇기 때문에 글이 매끄럽지 못한 점 양해부탁드립니다. 이 글을 읽기 전에 저번시간에 사전지식에 대해 몇가지 정리한게 있으니 먼저 그 글을 읽고 이 글을 읽는 것을 추천드립니다.
👉 출처 : https://arxiv.org/abs/2005.03510
Abstract
텍스트 요약은 원본 문서로부터 중요한 정보를 보존하는 짧은 형식의 텍스트를 생성하는 과정을 말한다. 최근에는 텍스트 요약의 모델이 많이 제안되고 있다.
이들 모델은 대부분은 ROUGE(recall-oriented understudy for gisting evaluation) 점수를 사용해 평가된다. 그러나, ROUGE 점수는 n-gram 중복에 근거하여 계산되므로 생성된 요약과 참조 요약(=사람이 직접 요약한 것을 의미) 사이의 semantic 의미가 반영되지 않는다. 한국어는 다양한 형태소를 여러 의미를 표현하는 단어로 결합한 응집어이기 때문에 ROUGE는 한국어 요약본에 적합하지 않다.
본 논문에서는 참조 요약의 semantic 의미와 원본 문서를 반영하는 RDASS(Reference and Document Awareness Semantic Score) 평가 지표를 제안한다. 그런 다음 우리는 측정지표와 인간의 판단과의 상관관계를 개선하기 위한 방법을 제안한다. 평가 결과는 인간 판단과의 상관관계가 우리의 평가 지표에서 ROUGE 점수보다 훨씬 더 높다는 것을 보여준다.
1. Introduction
1.1 텍스트 요약 작업
텍스트 요약 작업은 원본 문서의 중요한 모든 정보를 전달하는 참조 요약을 생성하는 것이다. 이러한 유형의 요약에는 두 가지 전략이 있다.
추출적 접근법(extractive approach) 으로 가장 눈에 띄는 핵심 문장을 출처로부터 추출해 참고문헌으로 정리한다(Zhong et al., 2019; Wang et al., 2019; Xiao and Carenini, 2019).
두 번째 접근방식은 추상적(abstractive) 이며, 이 접근방식은 소스로부터 패러프레이드 요약이 생성된다(Jang et al., 2018; Guo et al., 2018; Wenbo et al., 2019). 생성된 요약은 원본 문서에 나타나는 단어와 동일한 단어를 포함하지 않을 수 있다. 따라서 생성된 요약과 출처 문서 간의 사실적 정렬을 측정하는 것이 중요하다(Kryscinski et al., 2019).
1.2 ROUGE의 문제점 🤔
대부분의 요약 모델은 생성된 요약과 참조 요약 사이의 n-gram 중첩을 측정하는 기존 평가(ROUGE)을 사용한다. 그러나 루이(2013년)는 참고요약을 하나만 제공했을 때 상관관계가 크게 감소했음을 증명했다. 또한, 개인이 문서를 수동으로 요약하는 과정을 고려할 때, ROUGE는 생성된 요약과 참조 요약 사이의 의미적 의미를 반영하지 않기 때문에 제한적이다.
예를 들어, 어떤 사람이 문서를 요약할 때, 그들은 항상 원본 문서의 명시적인 단어를 사용하지 않으면서 암시적인 단어를 사용하는 경향이 있다. ROUGE 점수는 n그램 중첩을 기준으로 계산하기 때문에 두 단어의 의미적 의미가 같더라도 점수가 낮을 수 있다.
표 1은 한국어 요약본에 적용되었을 때의 ROUGE 제한의 예를 보여준다. 이러한 경향은 특히 영어와 달리 다양한 형태소를 하나의 단어로 결합하여 여러 의미와 문법적 기능을 표현하는 한국어에 널리 퍼져 있다. 따라서, ROUGE 점수를 활용하면 부정확한 결과가 나온다.
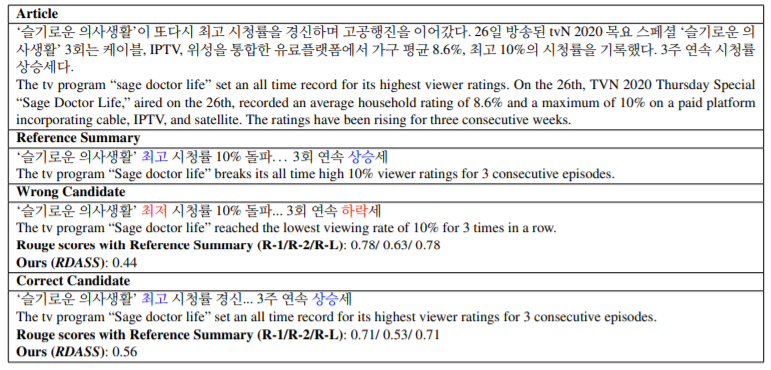
표1. 한국어 요약에서 ROUGE의 한계를 보여주는 예. 잘못 생성된 요약은 높은 ROUGE 점수를 가지지만, 정반대의 의미적 의미를 갖는다. 파란색과 빨간색으로 표시된 텍스트 영역은 표시된 메트릭스에 반영되는 의미 비교의 사실성을 구별하는 지표 역할을 한다.
이러한 한계를 극복하기 위해서는 생성된 요약과 참조 요약의 의미 정보를 모두 고려한 평가 방법이 필요하다. 생성된 요약은 거짓 정보를 포함할 수 있기 때문에 생성된 요약과 원본 문서 사이의 사실성을 검토하는 것이 중요하다.
사람마다 각기 다른 방식으로 정보를 요약하고 있으며, 교차 확인 후에도 동의하기 어렵다. 따라서 원본 문서는 생성 및 참조 요약과 함께 고려되어야 한다.
본 연구에서는 생성된 요약과 함께 소스 문서와 참조 요약 모두를 고려하는 요약 모델을 평가하기 위한 지표를 제안한다:
- 심층 의미 정보를 이용한 요약 모델에 적용할 수 있는 평가 지표를 제안한다.
- 제안된 평가 지표와 인간 판단 사이의 상관관계를 개선하기 위한 방법을 제안한다.
- 광범위한 평가를 통해, 우리는 인간 판단과의 상관관계가 ROUGE 점수보다 제안된 평가 지표에 대해 훨씬 더 높다는 것을 입증한다.
2. Related Work
2.1 기존의 텍스트 요약 평가 방법
텍스트 요약의 평가 방법은 수동과 자동의 두 가지 전략으로 나뉜다.
-
수동평가 (Manual evaluation) : 비용이 많이 들고 어렵다
-
자동평가 (Automatic evaluation) : 빠르고 저렴한 평가를 용이하게 하는 자동적인 방법을 개발하기 위해 여러 연구가 수행되었다.
-
extrinsic automatic method (외적방법) : 문서 관련성의 판단을 구성하는 작업의 완료에 어떻게 영향을 미치는지에 기초하여 요약 모델을 평가한다(?)
-
intrinsic automatic method (내적방법) : 속성 분석 또는 수동으로 생성된 요약과의 유사성을 계산하여 품질을 평가한다. pyramid method, basic-elements method, ROUGE 방법이 있다.
-
피라미드 방식은 인간이 만든 다양한 요약을 검사하고, 각각 점수 가중치를 갖는 요약 내용 단위를 만든다. 기본원소법은 피라미드법과 비슷하다. ROUGE는 후보자와 참조 요약 간의 어휘적 중첩의 유사성을 평가한다.
ROUGE 점수는 n-gram 중복에 근거해 계산되기 때문에 동의어나 구를 설명하지 않는다. 이러한 한계를 극복하기 위해 많은 접근법이 제안되었다. ParaEval (Jough et al., 2006), LUZ-WE (ng and Abrecht, 2015), ROUGE 2.0 (Ganesan, 2018), ROUGE-G (Shafieiebavani et al., 2018)는 동의어 구조를 지원하기 위해 ROUGE를 확장하는데 사용되었다.
2.2 차별화된 우리의 요약 평가 방법
우리의 연구는 그 점에서 다르다.
1) 참고요약뿐만 아니라 문서도 고려하여 생성된 요약을 평가하는 방법을 제안한다.
2) 또한, 우리의 평가 모델은 unsupervised leraning(비지도 학습) 으로부터 바이트 페어 인코딩(BPE) (Gage, 1994) 토큰화 방법에 근거한 사전 훈련된 신경 네트워크(SBERT)를 활용하기 때문에 out of vocabulary (OOV) 문제에 견고하다.
3) 마지막으로, 당사의 평가 모델은 참조 요약과 문서에 대한 보다 문맥화된 정보를 수집하도록 추가 교육을 받을 수 있다.
2.3 텍스트 요약 모델
abstractive, extractive, and hybrid 방식이 존재.
추상적 모델은 구문을 다시 단어화하고 원본 문서로 구성된 새로운 구문을 가진 요약을 만든다. 최근의 텍스트 요약 접근방식은 multi-task and multi-reward training(장, 밴살, 2018; Paulus et al., 2017; Pasunuru and Vansal, 2018; Guo et al., 2018), attention-with-copying mechanisms(Tan et al., 2017; 2017; Cohan et al., 2018), 그리고 unsupervised training strategies(슈만, 2018;) 이 존재한다.
추출 방법은 원본 문서에서 가장 적합한 문장(또는 단어)을 추출하여 요약에 직접 복사한다. 많은 연구자(Neto et al., 2002; Colmenares et al., 2015; Filipova 및 Altun, 2013)는 도메인 전문 지식을 활용하여 요약 본문을 다듬기 위한 휴리스틱스를 개발했다. 최근에는 텍스트의 범위를 요약에 포함시켜야 하는지를 예측하는 모델을 훈련시키기 위해 신경 기반 텍스트 요약 모델이 제안되고 있다(Nallapati et al., 2016; Narayan et al., 2017; Suh and Durret, 2019; Rui et al., 2019a). 모델을 직접 최적화하기 위한 강화 학습 기반 요약 모델도 제안되었다(Wu와 Hu, 2018; Dong et al., 2018; Narayan et al., 2018b).
하이브리드 접근법은 추상적 방법과 추출적 방법을 모두 사용한다. 이 접근방식으로 요약 프로세스는 내용 선택과 파라프라싱의 두 단계로 구분된다
3. Methodology(방법론)
표 1에서 요약 모델에 대한 적절한 평가를 위해 문서와 참조 요약을 함께 고려하는 것의 중요성을 관찰할 수 있었다.
3.1절에서는 생성된 요약본을 참조 요약과 함께 평가하여 깊은 의미적 의미를 반영하는 방법을 제안한다. 다음으로, 원본 문서와 참조 요약을 함께 사용하여 생성된 요약을 평가하는 방법을 제안한다.
참조 문서 인식 평가 메트릭 모델은 참조 요약과 문서 양쪽에서 보다 상황화된 정보를 캡처하도록 추가 교육될 수 있다(하위 섹션 3.2).
3.1 Reference and Document Aware Semantic Score(RDASS)
요약 모델에서 생성된 요약을 로 정의하고 참조 요약을 로 정의하자. 여기서 는 각 단어를 나타낸다. 그런 다음, 각 요약 표현인 와 을 sentence-embedding 방법을 사용하여 구성할 수 있다.
Neural-based sentence-embedding은 광범위하게 연구되어 왔다. Conneau(2017년)는 SNLI(Stanford Natural Language Inference) corpus와 multi-genre NLI(Williams et al., 2017) dataset에 대한 max-pooling 전략으로 long short-term memory(LSTM)모델을 훈련했다. Cer (2018)는 SNLI dataset에서 transformer 를 훈련시키는 범용 문장 인코더를 제안했다.
Reimers (2019)는 pre-trained BERT(Devlin et al., 2018)를 활용한 sentence-BERT(SBERT) 를 제안해 SNLI(Stanford Natural Language Inference)와 multi-genre NLI(Williams et al., 2017)의 조합으로 훈련하고, 최첨단 문장 내장 성능을 보여주었다. SBERT는 의미 유사성 검색에 적합하며, BERT, Roberta(Liu et al., 2019b), 범용문장 인코더 등 기존 첨단 접근법보다 빠른 추론 속도를 보였다.
👉 유일한... 한국어 자료 참고 : https://roomylee.github.io/sentence-bert/
계산과정
1단계. 우리는 미리 훈련된 SBERT를 활용하여 요약 표현을 구성한다. 각 단어 표현, e는 다음과 같이 SBERT로부터 얻어진다.
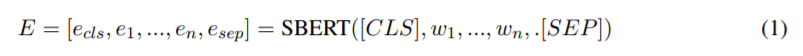
2단계. 이후 를 구성하기 위한 mean-pooling을 수행. 여기서 j는 word-embedding dimension의 지수를 나타내며, n은 E길이를 나타낸다. 도 같은 방법으로 얻을 수 있다.

3단계. 와 사이의 의미 유사성 점수 s(p, r)는 다음과 같이 얻을 수 있다.
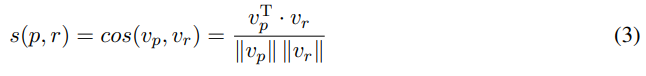
원본 문서와의 사실적 일관성을 고려하는 것이 중요하다는 점을 상기하고, 동일한 문서에 따라 중요한 정보를 요약하는 방법은 사람마다 다르다. 따라서 요약 모델을 평가할 때 생성된 요약과 함께 원본 문서도 고려해야 한다.
4단계. 문서 D = 인 경우 문서 표현 는 Eqs. (1)과 (2)를 사용하여 얻을 수 있다. 따라서 와 의 유사성 점수는 다음과 같이 정의할 수 있다.
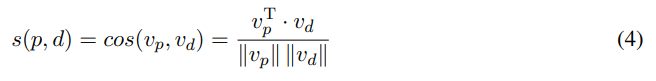
5단계. 참조 및 원본 문서가 주어진 경우 생성된 요약본의 참조 문서 인식 의미 점수(RDASS)는 s(p, r)와 s(p, d)를 평균하여 정의된다.

또한 s(p, r)와 s(p, d) 사이의 합, 최대, 최소 연산을 실험했지만, 두 점수의 평균을 계산하면 인간의 판단과 가장 높은 상관관계를 보고한다.
3.2 Fine-tuning SBERT with the Abstractive Summarization Model
SBERT는 훈련 가능한 metric 모델이다. 따라서 참조 요약 및 원본 문서에 대한 보다 상황화된 정보를 포착하도록 추가 교육을 실시할 수 있다. abstractive 요약 모델을 이용한 SBERT의 미세 조정 방법을 제안한다.
추상적 요약에 대한 대부분의 신경 접근법은 encoder–decoder 구조에 기초한다(See et al., 2017 참조).
정식으로, 문서 의 경우, 목표는 hidden representation 에서 요약 을 생성하는 것이다. hidden representation은 decoder의 출력 벡터다. 우리는 decoder의 hidden representation을 이용하여 SBERT를 미세 조정한다.
추상적 요약 모델이 있는 미세 조정된 SBERT를 "FWA-SBERT"라고 부른다.
마침
다음 편 이어서 있습니다.
References
