
필요 라이브러리 Import
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import xgboost as xgb
import shap
from sklearn import preprocessing
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
warnings.simplefilter(action='ignore')데이터 불러오기
Data Dictioncary
- survival : 생존 여부 (0 : 사망 / 1 : 생존)
- pclass : ticket에 따른 객실 등급
- sex : 성별
- Age : 나이
- sibsp : 동반한 형제자매와 배우자의 수
- parch : 동반한 부모 자식의 수
- ticket : ticket number
- fare : ticket의 요금
- cabin : 객실 번호
- embarked : 탑승 지역(항) (C : Cherbourg / Q : Queenstown / S : Southampton
train_data = pd.read_csv("./train.csv")
train_data
test_data = pd.read_csv("./test.csv")
test_data
train_data.info() #데이터 자료형 확인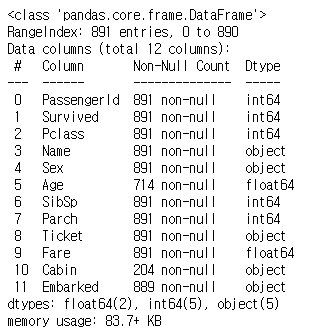
- 전체 891개의 data / 12개의 feature / float, int, object 자료형, 결측치 존재
train_data.isna().sum()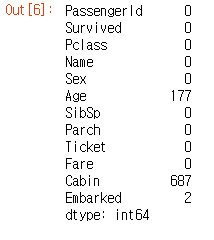
- 결측치의 개수 확인 : age 177개 / cabin 687개 / embarked 2개
train_data.describe()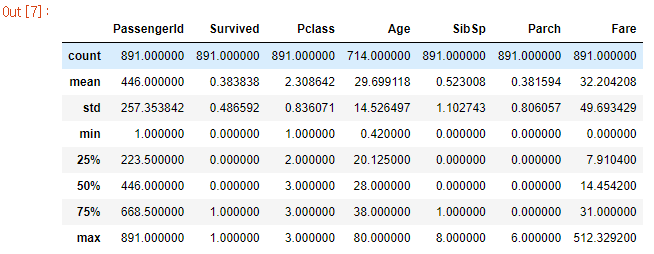
수치형 데이터 확인
- pclass가 1, 2, 3이 존재하는데, 평균이 2.3이고 50% 분위수가 3인 것을 보아 1보다 2, 3이 많이 존재할 것으로 확인
- age는 평균이 29.6세로, 백분위 수도 함께 확인하였을 때 고령자보다 40대 이하의 사람들이 많이 탔을 것으로 추측
- fare를 확인하면 pclass와 연관지어 생각할 수 있음.
train_data.describe(include=['O']) #범주형 데이터 확인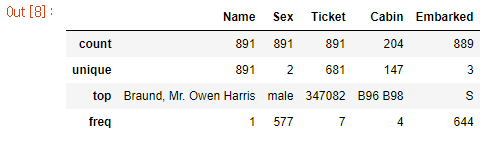
범주형 데이터 확인
- 성별은 남자가 더 많이 탔음.
- ticket, cabin 같은 경우 unique한 data의 개수가 많으므로 사용할 시 label encoding을 사용해야 할 것
- sex, embarked 같은 경우는 one-hot encoding을 사용 예정
train_data.hist(figsize = (16, 12))
plt.show()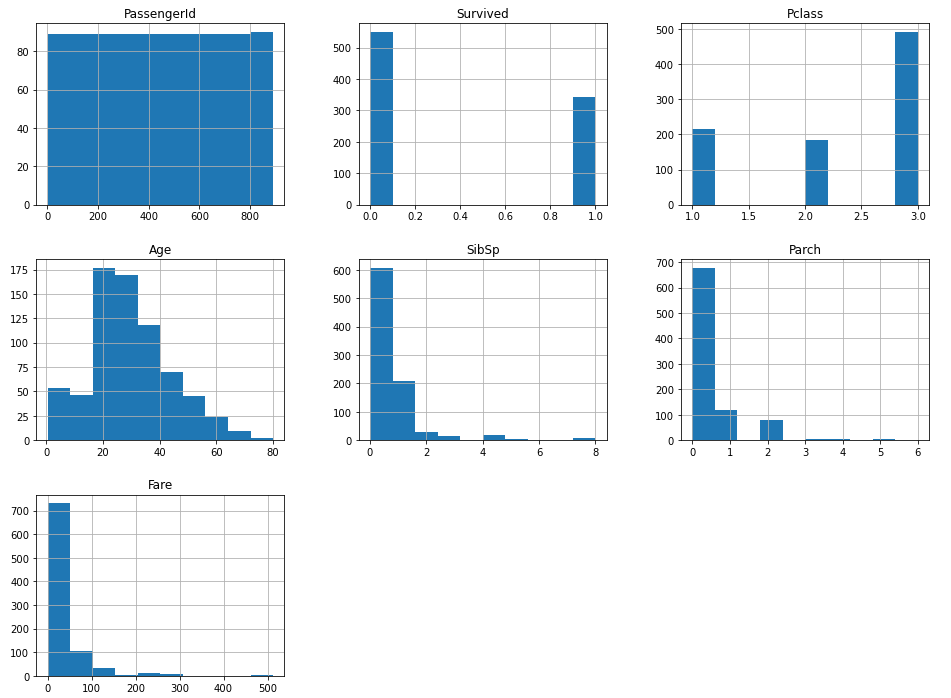
- 예상했던 것과 동일하게 pclass 3이 두배 이상 많은 것을 확인할 수 있음
- age도 고령자보다 40대까지의 나이대가 많음.
- parch, sibsp를 확인해보면 분포가 어느정도 비슷하니 가족단위로 온 사람은 대부분 자식이 1~2명 정도라고 생각.
- fare와 pclass가 현재까지는 관계가 있다고 보고, 정규화를 진행하지 않아도 가중치가 주어져도 괜찮다고 생각하지만 추후 문제를 없애기 위해 정규화를 진행해야할 수 있음.
데이터 분석 및 전처리
결측치 처리
train_data.dropna()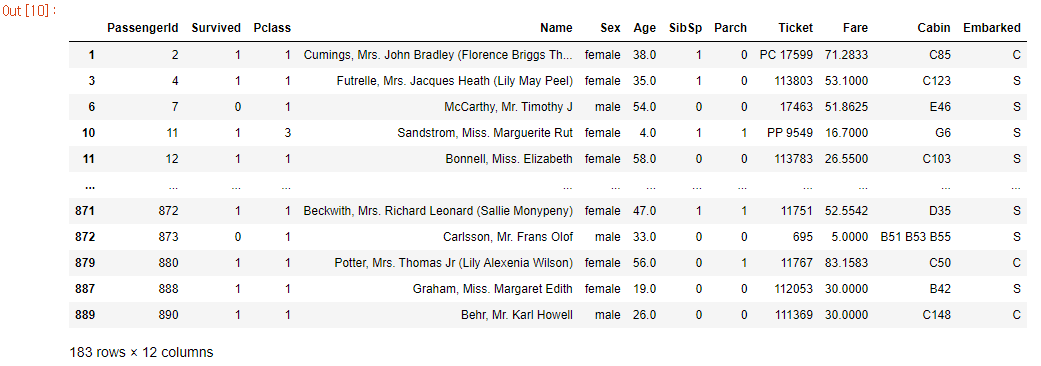
- train_data에서 결측치를 제거해보니 대부분의 데이터가 삭제되는 것을 확인하였으므로 결측치 제거 방식은 사용하지 않는다.
Cabin 결측치
cabin_only = train_data[["Cabin", "Pclass"]].copy()
cabin_only["Cabin"] = cabin_only['Cabin'].str[:1]
Pclass1 = cabin_only[cabin_only['Pclass']==1]['Cabin'].value_counts()
Pclass2 = cabin_only[cabin_only['Pclass']==2]['Cabin'].value_counts()
Pclass3 = cabin_only[cabin_only['Pclass']==3]['Cabin'].value_counts()
df = pd.DataFrame([Pclass1, Pclass2, Pclass3])
df.index = ['1st class','2nd class', '3rd class']
df.plot(kind='bar',stacked=True, figsize=(10,5))
plt.show()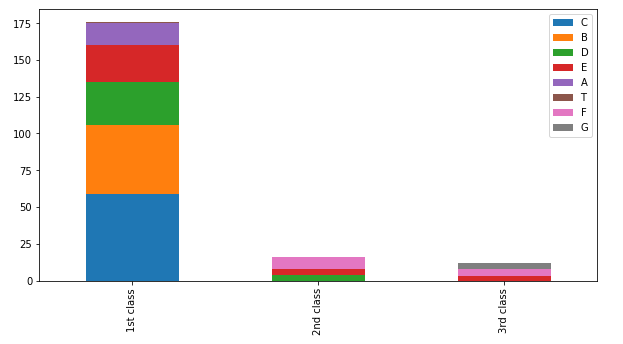
'Cabin' column을 살펴보면 Deck이 A, B, C, D, E, F, G, T가 존재하는 것을 볼 수 있다.
pclass = 1인 deck은 A, B, C, D, E, T가 존재하고
pclass = 2인 deck은 D, E, F
pclass = 3인 deck은 E, F, G가 있는 것을 확인할 수 있다.
이를 이용하여 Cabin의 결측치를 처리할 것이다.
train_data.loc[(train_data.Pclass==1)&(train_data.Cabin.isnull()),'Cabin']='B'
train_data.loc[(train_data.Pclass==2)&(train_data.Cabin.isnull()),'Cabin']='E'
train_data.loc[(train_data.Pclass==3)&(train_data.Cabin.isnull()),'Cabin']='F'
train_data["Cabin"] = train_data["Cabin"].str.slice(0,1)train_data['Cabin'].unique()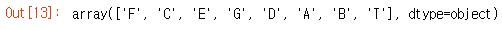
- 결측치 처리를 한 뒤 Cabin 항목들을 확인하였다.
Age 결측치
age_df = train_data[["Name", "Sex", "Age"]].copy()
age_df
for x in age_df:
age_df['Title'] = age_df['Name'].str.extract('([A-za-z]+)\.', expand=False)
train_data['Title'] = train_data['Name'].str.extract('([A-za-z]+)\.', expand=False)
print(age_df['Title'].value_counts())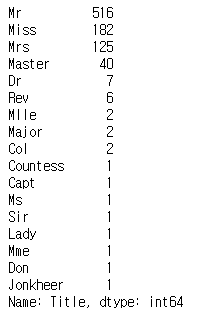
Capt = age_df.loc[age_df.Title == 'Capt', 'Age'].mean()
Col = age_df.loc[age_df.Title == 'Col', 'Age'].mean()
Countess = age_df.loc[age_df.Title == 'Countess', 'Age'].mean()
Don = age_df.loc[age_df.Title == 'Don', 'Age'].mean()
Dona = age_df.loc[age_df.Title == 'Dona', 'Age'].mean()
Dr = age_df.loc[age_df.Title == 'Dr', 'Age'].mean()
Jonkheer = age_df.loc[age_df.Title == 'Jonkheer', 'Age'].mean()
Lady = age_df.loc[age_df.Title == 'Lady', 'Age'].mean()
Major = age_df.loc[age_df.Title == 'Major', 'Age'].mean()
Master = age_df.loc[age_df.Title == 'Master', 'Age'].mean()
Miss = age_df.loc[age_df.Title == 'Miss', 'Age'].mean()
Mlle = age_df.loc[age_df.Title == 'Mlle', 'Age'].mean()
Mme = age_df.loc[age_df.Title == 'Mme', 'Age'].mean()
Mr = age_df.loc[age_df.Title == 'Mr', 'Age'].mean()
Mrs = age_df.loc[age_df.Title == 'Mrs', 'Age'].mean()
Ms = age_df.loc[age_df.Title == 'Ms', 'Age'].mean()
Rev = age_df.loc[age_df.Title == 'Rev', 'Age'].mean()
Sir = age_df.loc[age_df.Title == 'Sir', 'Age'].mean()
df = pd.DataFrame({'Mean Age' : [Capt, Col, Countess, Don, Dona, Dr, Jonkheer, Lady
, Major, Master, Miss, Mlle, Mme, Mr, Mrs, Ms, Rev, Sir]})
df.index = ['Capt.', 'Col.', 'Countess.', 'Don.', 'Dona.', 'Dr.', 'Jonkheer.',
'Lady.', 'Major.', 'Master.', 'Miss.', 'Mlle.', 'Mme.',
'Mr.', 'Mrs.', 'Ms.', 'Rev.', 'Sir.']
ax = df.plot(kind = 'bar', figsize=(6,4))
ax.set_xlabel("name")
plt.show()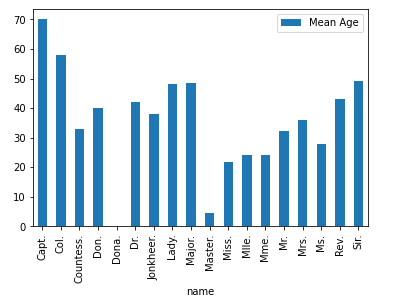
Age 결측치같은 경우 Name의 title을 이용하여 추측할 수 있다.
각 name의 title만 추출해서 column을 만든 뒤 평균을 비교해보았다.
이를 이용하여 age의 결측치를 채웠다.
train_data.loc[(train_data.Title=='Capt')&(train_data.Age.isnull()),'Age'] = Capt
train_data.loc[(train_data.Title=='Col')&(train_data.Age.isnull()),'Age'] = Col
train_data.loc[(train_data.Title=='Countess')&(train_data.Age.isnull()),'Age'] = Countess
train_data.loc[(train_data.Title=='Don')&(train_data.Age.isnull()),'Age'] = Don
train_data.loc[(train_data.Title=='Dona')&(train_data.Age.isnull()),'Age'] = Dona
train_data.loc[(train_data.Title=='Dr')&(train_data.Age.isnull()),'Age'] = Dr
train_data.loc[(train_data.Title=='Jonkheer')&(train_data.Age.isnull()),'Age'] = Jonkheer
train_data.loc[(train_data.Title=='Lady')&(train_data.Age.isnull()),'Age'] = Lady
train_data.loc[(train_data.Title=='Major')&(train_data.Age.isnull()),'Age'] = Major
train_data.loc[(train_data.Title=='Master')&(train_data.Age.isnull()),'Age'] = Master
train_data.loc[(train_data.Title=='Miss')&(train_data.Age.isnull()),'Age'] = Miss
train_data.loc[(train_data.Title=='Mlle')&(train_data.Age.isnull()),'Age'] = Mlle
train_data.loc[(train_data.Title=='Mme')&(train_data.Age.isnull()),'Age'] = Mme
train_data.loc[(train_data.Title=='Mr')&(train_data.Age.isnull()),'Age'] = Mr
train_data.loc[(train_data.Title=='Mrs')&(train_data.Age.isnull()),'Age'] = Mrs
train_data.loc[(train_data.Title=='Ms')&(train_data.Age.isnull()),'Age'] = Ms
train_data.loc[(train_data.Title=='Rev')&(train_data.Age.isnull()),'Age'] = Rev
train_data.loc[(train_data.Title=='Sir')&(train_data.Age.isnull()),'Age'] = SirEmbarked 결측치
train_data[train_data['Embarked'].isnull()]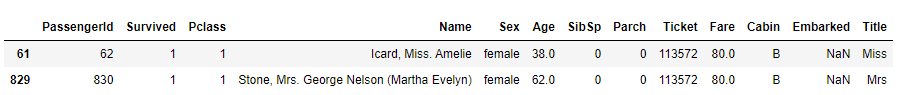
- 전체 데이터 약 900개 중 결측치가 2개만 존재하고, 특별히 다른 column과의 연관성을 찾지 못하여 최빈값으로 결측치 처리를 하였다.
train_data['Embarked'] = train_data['Embarked'].fillna(train_data['Embarked'].mode()[0])train_data.isna().sum()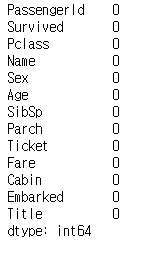
- 마지막으로 결측치 처리가 완료된 것을 확인할 수 있다.
데이터 전처리(범주형 데이터)
train_data.drop(['PassengerId', 'Name'], axis = 1, inplace = True)
train_data
- passengerID같은 경우 주어진 정보 내에서 특별히 연관성이 있지 않을 것으로 판단하였다.
- Name은 이름 중 유용한 정보로 추측되는 title을 추출하였기 때문에 ID와 함께 drop하였다.
lab_enc = LabelEncoder()
train_data['Ticket'] = lab_enc.fit_transform(train_data['Ticket'])
train_data['Title'] = lab_enc.fit_transform(train_data['Title'])
train_data['Cabin'] = lab_enc.fit_transform(train_data['Cabin'])
train_data
- 먼저 Ticket같은 경우 약 660개의 data가 존재하고, cabin도 8개라 one-hot encoding을 해도 되지만 column이 많아질 수 있기 때문에 각 feature에 label encoding을 진행하였다. 추가로 Title같은 경우도 label encoding을 진행하였다.
train_data = pd.get_dummies(train_data)- 이 외의 sex, embarked는 one-hot encoding을 진행하였다.
train_data
plt.figure(figsize = (20, 16))
x = sns.heatmap(train_data.corr(), cmap = 'Blues', linewidths = '0.1',annot = True)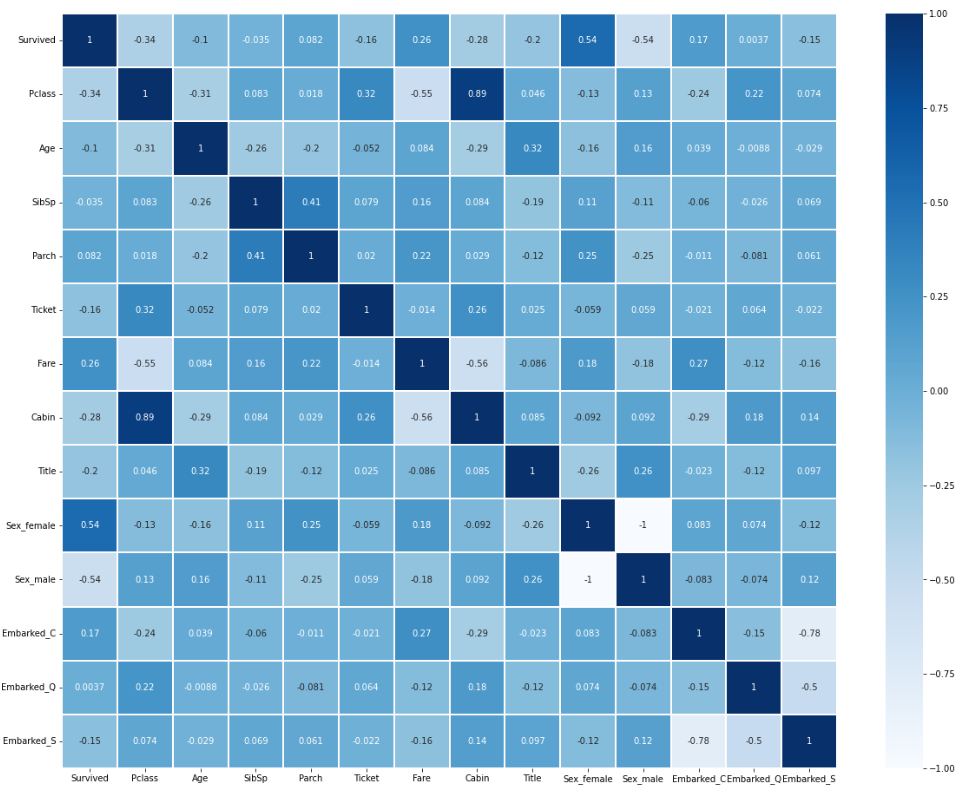
각 column들의 상관계수를 heatmap을 이용하여 한눈에 보기 편하게 시각화하였다.
- cabin과 pclass는 0.89의 높은 상관관계를 가지고 있다.
- embarked끼리도 어느정도 관계가 존재한다.
- Sex male과 female의 경우 상관관계가 1인데, 이는 한 column을 확정을 했을 때 다른 column이 필요하지 않게 되는 경우이므로 추후 feature를 제거할 것이다.
- target value인 survived와의 관계를 확인해보면 sex가 연관성이 많은 것으로 확인된다.
sns.pairplot(train_data[['Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare',
'Cabin', 'Title', 'Sex_female', 'Sex_male', 'Embarked_C', 'Embarked_Q',
'Embarked_S']] ,hue='Survived', palette='husl', markers=['o','s'])
plt.show()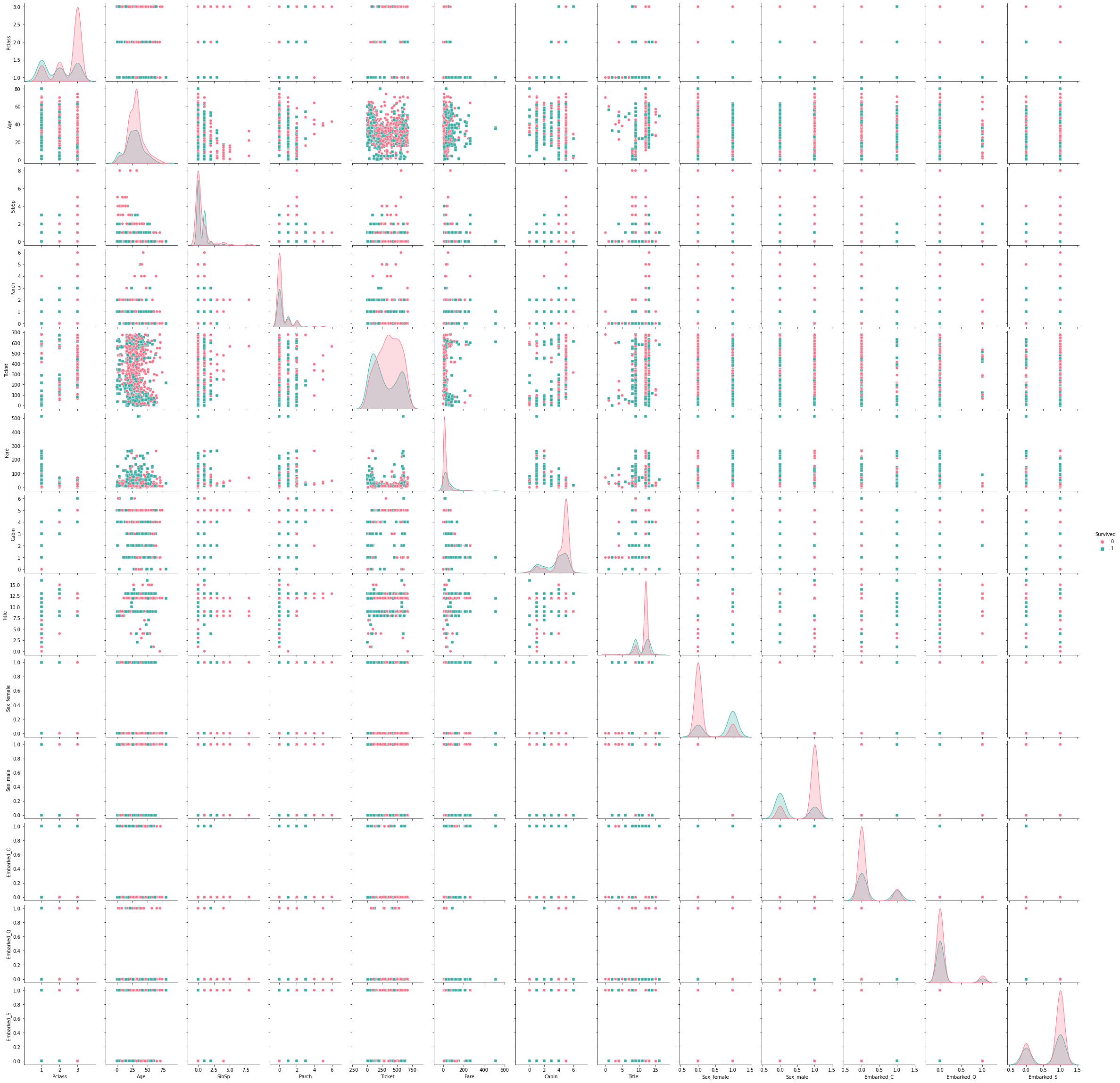
pairplot을 이용하여 Survived와 각 column들의 관계를 확인하였다.
- 남자가 여자보다 생존률이 현저히 낮음
- 청년층(2~30대) 생존률이 낮은 편
- pclass 3이 생존률이 제일 낮음
- ticket 중반 부분이 생존률이 낮은편
- fare이 낮은 사람들이 생존률이 낮음
- 특정 title이 생존률이 현저히 낮음
- 탑승 장소에 대해서도 약 2배가량 생존률 차이가 있음을 확인 가능
scaler = preprocessing.MinMaxScaler()
normalized_data = scaler.fit_transform(train_data)
col = ['Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Title', 'Sex_female', 'Sex_male', 'Embarked_C', 'Embarked_Q', 'Embarked_S']
normalized_df = pd.DataFrame(normalized_data, columns = col)
normalized_df
- model 과정에서 속도를 높이기 위하여 MinMaxScaler를 이용하여 Feature Scaling을 진행하였다.
모델 학습
y_target = normalized_df['Survived']
x_data = normalized_df.drop(['Sex_male', 'Embarked_Q', 'Survived'], axis = 1)x_train, x_test, y_train, y_test = train_test_split(x_data, y_target, test_size = 0.2, random_state = 4)params = {
'max_depth':[4, 6, 8, 10, 12],
'min_child_weight':[4, 6, 8, 10],
'gamma' : [0, 1, 2],
'colsample_bytree':[0.7, 0.8, 0.9],
'n_estimators':[10, 50, 100, 200, 300],
'eta' : [0.1, 0.15, 0.2, 0.3]
}
grid_xgb_clf = xgb.XGBClassifier(random_state = 4, n_jobs = -1)
grid_cv = GridSearchCV(grid_xgb_clf, param_grid = params, cv = 5, n_jobs = -1)
grid_cv.fit(x_train, y_train)
print('최적 하이퍼 파라미터: ', grid_cv.best_params_)
print('최고 예측 정확도: {:.4f}'.format(grid_cv.best_score_))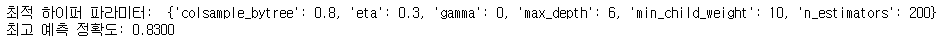
- train_data를 train_test_split을 이용하여 분할하고, xgb모델의 최적 하이퍼 파라미터를 GridSearchCV를 이용하여 찾아내었다.
xgb_model = xgb.XGBClassifier(eta = 0.3, gamma = 0, max_depth = 6, min_child_weight = 10, n_estimators = 200, colsample_bytree = 0.8)
xgb_model.fit(x_train,y_train)
prediction = xgb_model.predict(x_test)
xgb_score = xgb_model.score(x_test, y_test)
xgb_score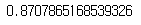
# feature importance
ftr_importances_values = xgb_model.feature_importances_
ftr_importances = pd.Series(ftr_importances_values, index = x_train.columns)
ftr_sort = ftr_importances.sort_values(ascending=False)
plt.figure(figsize=(12,10))
plt.title('Feature Importances')
sns.barplot(x=ftr_sort, y=ftr_sort.index)
plt.show()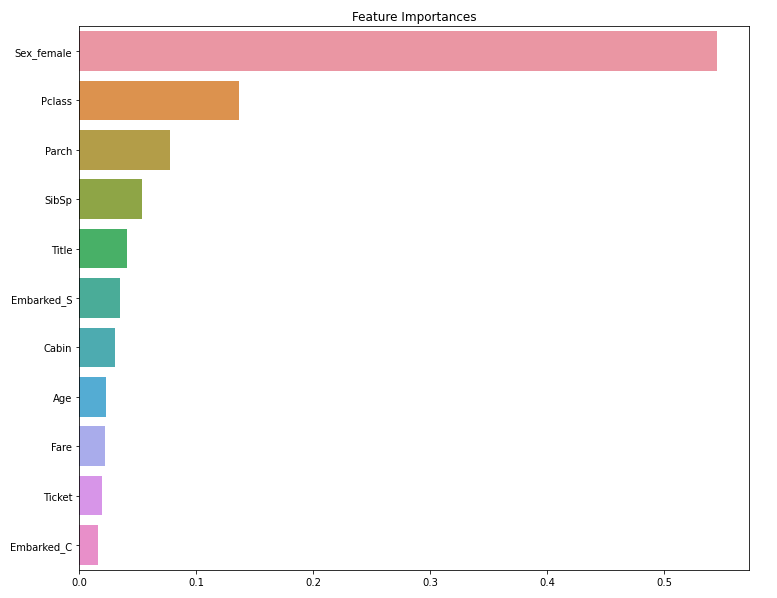
explainer = shap.TreeExplainer(xgb_model) # 트리 모델 Shap Value 계산 객체 지정
shap_values = explainer.shap_values(x_train)shap.initjs() # 자바스크립트 초기화 (그래프 초기화)
shap.force_plot(explainer.expected_value, shap_values[1,:], x_train.iloc[1,:])
# 첫 번째 검증 데이터 인스턴스에 대해 Shap Value를 적용하여 시각화
# 빨간색이 영향도가 높으며, 파란색이 영향도가 낮음
shap.summary_plot(shap_values, x_train)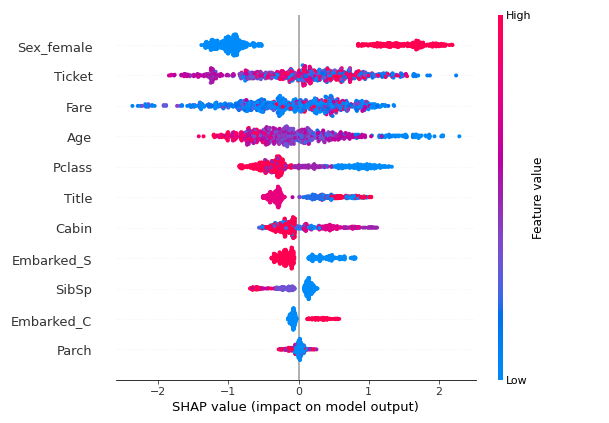
shap.summary_plot(shap_values, x_train, plot_type = "bar") # 각 변수에 대한 Shap Values의 절대값으로 중요도 파악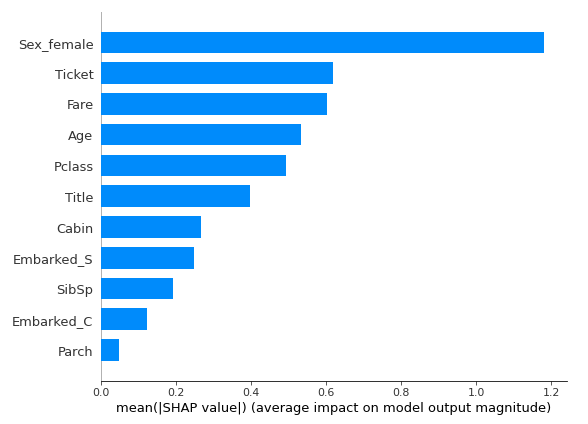
- Feature importance와 shap value를 이용하여 각 속성의 중요도를 확인하고 추가적으로 column을 수정하였다.
Test data 적용
test_data.isna().sum()test_data.loc[(test_data.Pclass==1)&(test_data.Cabin.isnull()),'Cabin']='B'
test_data.loc[(test_data.Pclass==2)&(test_data.Cabin.isnull()),'Cabin']='E'
test_data.loc[(test_data.Pclass==3)&(test_data.Cabin.isnull()),'Cabin']='F'
test_data["Cabin"] = test_data["Cabin"].str.slice(0,1)age_df = test_data[["Name", "Sex", "Age"]].copy()
for x in age_df:
age_df['Title'] = age_df['Name'].str.extract('([A-za-z]+)\.', expand=False)
test_data['Title'] = test_data['Name'].str.extract('([A-za-z]+)\.', expand=False)
Col = age_df.loc[age_df.Title == 'Col', 'Age'].mean()
Dona = age_df.loc[age_df.Title == 'Dona', 'Age'].mean()
Dr = age_df.loc[age_df.Title == 'Dr', 'Age'].mean()
Master = age_df.loc[age_df.Title == 'Master', 'Age'].mean()
Miss = age_df.loc[age_df.Title == 'Miss', 'Age'].mean()
Mr = age_df.loc[age_df.Title == 'Mr', 'Age'].mean()
Mrs = age_df.loc[age_df.Title == 'Mrs', 'Age'].mean()
Ms = age_df.loc[age_df.Title == 'Ms', 'Age'].mean()
Rev = age_df.loc[age_df.Title == 'Rev', 'Age'].mean()
test_data.loc[(test_data.Title=='Col')&(test_data.Age.isnull()),'Age'] = Col
test_data.loc[(test_data.Title=='Dona')&(test_data.Age.isnull()),'Age'] = Dona
test_data.loc[(test_data.Title=='Dr')&(test_data.Age.isnull()),'Age'] = Dr
test_data.loc[(test_data.Title=='Master')&(test_data.Age.isnull()),'Age'] = Master
test_data.loc[(test_data.Title=='Miss')&(test_data.Age.isnull()),'Age'] = Miss
test_data.loc[(test_data.Title=='Mr')&(test_data.Age.isnull()),'Age'] = Mr
test_data.loc[(test_data.Title=='Mrs')&(test_data.Age.isnull()),'Age'] = Mrs
test_data.loc[(test_data.Title=='Ms')&(test_data.Age.isnull()),'Age'] = Ms
test_data.loc[(test_data.Title=='Rev')&(test_data.Age.isnull()),'Age'] = Rev
test_data['Fare'] = test_data['Fare'].fillna(0)- Cabin과 Age 결측치를 처리한 뒤 Fare도 결측치가 1개 존재하여 이는 0으로 대체하였다.
test_data.drop(['PassengerId', 'Name'], axis = 1, inplace = True)
lab_enc = LabelEncoder()
test_data['Ticket'] = lab_enc.fit_transform(test_data['Ticket'])
test_data['Title'] = lab_enc.fit_transform(test_data['Title'])
test_data['Cabin'] = lab_enc.fit_transform(test_data['Cabin'])
test_data = pd.get_dummies(test_data)
scaler = preprocessing.MinMaxScaler()
normalized_test_data = scaler.fit_transform(test_data)
col = ['Pclass', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Title', 'Sex_female', 'Sex_male', 'Embarked_C', 'Embarked_Q', 'Embarked_S']
test_normalized_df = pd.DataFrame(normalized_test_data, columns = col)
test_normalized_df
test_normalized_df = test_normalized_df.drop(['Sex_male', 'Embarked_Q', 'Embarked_C'], axis = 1)test_data = test_data.drop(['Sex_male', 'Embarked_Q'], axis = 1)
xgb_pred = xgb_model.predict(test_normalized_df)
sample_submission = pd.read_csv('./gender_submission.csv')
sample_submission['Survived'] = xgb_pred
sample_submission.to_csv('submission.csv',index = False)
sample_submission.head()

- train_data에서는 점수가 조금 높은 편이었지만 test_data에 적용한 뒤 제출을 하니 정확도가 상대적으로 떨어졌다. 앞으로도 지속적으로, 그리고 추가적으로 데이터 분석을 하고 수정을 해야할 것 같다.

안녕하세요 :) Data/AI 공부 중인 한국외대 컴퓨터공학부 조권휘입니다.